1.本发明涉及虚拟场景构建技术领域,特别是涉及一种涉及多人员的虚拟场景的构建方法和系统。
背景技术:
2.目前,涉及多人员的虚拟场景构建一般采用视觉定位结合惯性动作捕捉的方案。具体的,首先,采用视觉摄像头对空间内的多个人员进行识别,从而获取多个人员的空间坐标数据;然后,通过每个人员身上佩戴的惯性传感器建立该人员的人体虚拟模型;最后,将各个人体虚拟模型定位到虚拟场景中,完成虚拟场景的构建。然而,由于空间内存在多个人员,当摄像头拍摄的人员画面重叠时,或者受到障碍物阻挡时,无法进行人体识别,因此无法准确获取其空间坐标数据,从而影响虚拟场景的构建。
技术实现要素:
3.鉴于上述问题,提出了本发明实施例以便提供一种克服上述问题或者至少部分地解决上述问题的一种涉及多人员的虚拟场景的构建方法和相应的一种涉及多人员的虚拟场景的构建系统。
4.为了解决上述问题,本发明实施例公开了一种涉及多人员的虚拟场景的构建方法,所述方法包括:
5.在同一空间内的多个不同位置发生频谱各不相同的多组声波;
6.当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标;
7.重复上述步骤得到多个人员的实时空间坐标;
8.分别采集所述多个人员的实时动作数据;
9.采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐标,构建涉及多个人员的虚拟场景。
10.可选地,当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标的步骤包括:
11.从所述多组声波中解析得到多组声波信息;
12.确定与所述多组声波对应的多组声波接收时间;
13.采用所述多组声波信息以及多组声波接收时间,计算得到所述人员的实时空间坐标。
14.可选地,采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐标,构建涉及多个人员的虚拟场景的步骤包括:
15.构建初始虚拟场景;
16.采用多个人员的实时动作数据构建多个独立虚拟人体模型;
17.根据所述多个人员的实时空间坐标,将所述多个独立虚拟人体模型定位到所述初
始虚拟场景中,得到涉及多个人员的虚拟场景。
18.可选地,根据所述多个人员的实时空间坐标,将所述多个独立虚拟人体模型定位到所述初始虚拟场景中,得到多个人员的虚拟场景的步骤包括:
19.在所述虚拟场景中建立虚拟空间坐标系;
20.根据人员的实时空间坐标,确定所述人员在所述虚拟空间坐标系中的虚拟位置;
21.在所述虚拟位置上显示所述人员对应的独立虚拟人体模型;
22.重复上述步骤,得到涉及多个人员的虚拟场景。
23.可选地,所述声波信息包括声波发生时间以及所述声波发生坐标。
24.本发明实施例还公开了一种涉及多人员的虚拟场景的构建系统,所述系统包括:
25.声波发生模块,用于在同一空间内的多个不同位置发生频谱各不相同的多组声波;
26.实时空间坐标计算模块,用于当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标;
27.多人员实时空间坐标获取模块,重复上述步骤得到多个人员的实时空间坐标;
28.实时动作数据采集模块,用于分别采集所述多个人员的实时动作数据;虚拟场景构建模块,用于采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐标,构建涉及多个人员的虚拟场景。
29.可选地,所述实时空间坐标计算模块包括:
30.声波信息解析子模块,用于从所述多组声波中解析得到多组声波信息;
31.声波接收时间确定子模块,用于确定与所述多组声波对应的多组声波接收时间;
32.实时空间坐标计算子模块,用于采用所述多组声波信息以及多组声波接收时间,计算得到所述人员的实时空间坐标。
33.可选地,所述虚拟场景构建模块包括:
34.初始虚拟场景构建子模块,用于构建初始虚拟场景;
35.独立虚拟人体模型构建子模块,用于采用多个人员的实时动作数据构建多个独立虚拟人体模型;
36.独立虚拟人体模型定位子模块,用于根据所述多个人员的实时空间坐标,将所述多个独立虚拟人体模型定位到所述初始虚拟场景中,得到涉及多个人员的虚拟场景。
37.可选地,所述独立虚拟人体模型定位子模块包括:
38.虚拟空间坐标系建立单元,用于在所述虚拟场景中建立虚拟空间坐标系;
39.虚拟位置确定单元,用于根据人员的实时空间坐标,确定所述人员在所述虚拟空间坐标系中的虚拟位置;
40.独立虚拟人体模型现实单元,用于在所述虚拟位置上显示所述人员对应的独立虚拟人体模型;
41.虚拟场景构建单元,用于重复上述步骤,得到涉及多个人员的虚拟场景。
42.本发明实施例包括以下优点:在同一空间内的多个不同位置发生频谱各不相同的多组声波,当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标,重复上述步骤得到多个人员的实时空间坐标,分别采集所述多个人员的实时动作数据,采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐
标,构建涉及多个人员的虚拟场景,采用本技术的技术方案,当空间内存在障碍物,或者人员聚集重叠,也不影响涉及多人员的虚拟场景的构建。
附图说明
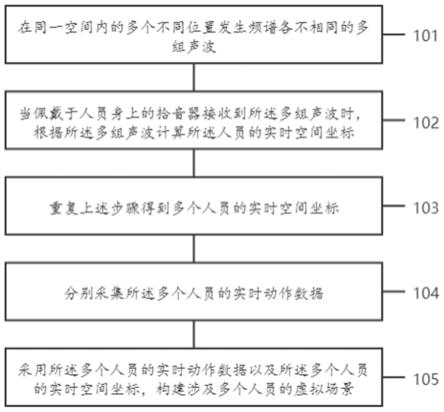
43.图1是本发明的一种涉及多人员的虚拟场景的构建方法实施例一的步骤流程图。
44.图2是本发明的一种涉及多人员的虚拟场景的构建系统实施例一的结构框图。
具体实施方式
45.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
46.参照图1,示出了本发明的一种涉及多人员的虚拟场景的构建方法实施例一的步骤流程图,具体可以包括如下步骤:
47.步骤101,在同一空间内的多个不同位置发生频谱各不相同的多组声波;
48.所述多组频谱各不相同声波可以由多个声波发生器产生,每个声波发生器产生一种频谱的声波,不同的声波发生器产生的声波的频谱各不相同。所述多个声波发生器可以安装于同一空间中的不同的位置,所述空间可以为开放空间,也可以为密闭空间,例如房间、展厅等等。例如,四个声波发生器位于房间的天花板的不同位置上,能够产生四组频谱各不相同的声波。设置越多的声波发生器,获取人员的空间坐标越精准,需要说明的是,本技术实施例并不对声波发生器的数量以及设置位置进行限制,技术人员可根据实际情况自行设置。
49.步骤102,当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标;
50.空间内若存在多个人员,每个人员身上佩戴一个拾音器,所述拾音器可以佩戴于身上的任何位置。每个拾音器具有其唯一编号。
51.当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标的步骤包括:
52.子步骤1021,从所述多组声波中解析得到多组声波信息;
53.在本发明实施例中,每组声波携带着不同的声波信息,所述声波信息包括声波发生时间以及所述声波发生坐标,可以根据多组声波的频谱解析出多组声波发生时间以及所述声波发生坐标。所述声波发生时间为声波在拾音器产生的时间,例如,拾音器在5分13秒产生a声波,那么a声波的声波发生时间为5分13秒。所述声波发生坐标为声波发生器的空间坐标。
54.子步骤1022,确定与所述多组声波对应的多组声波接收时间;
55.由于声波发生器的位置不同,因此,多个声波发生器产生的多组声波到达人员身上的拾音器经过的时间不同,所以需要确定每一组声波对应的声波接收时间,例如,a声波的声波接收时间为5分15秒,b声波的接收时间为5分14秒。
56.子步骤1023,采用所述多组声波信息以及多组声波接收时间,计算得到所述人员的实时空间坐标。
57.首先,利用声波的发生时间以及声波接收时间可以计算得到声波的传播时间。
58.假设,在四个不同的位置产生频谱各不相同的声波a、声波b、声波c、声波d,四组声波在空中进行传播,到达位于空间内某个人员,人员甲身上的拾音器,a声波的传播时间为t1,a声波的声波发生坐标为(x1,y1,z1);b声波的传播时间为t2,b声波的声波发生坐标为(x2,y2,z2);c声波的传播时间为t3,c声波的声波发生坐标为(x3,y3,z3);d声波的传播时间为t4,d声波的声波发生坐标为(x4,y4,z4)。已知声波的传播时间t,声音在空气中的传播速度c,那么便可以计算得到声波发生器与拾音器的距离r=t*c,因此,利用以下空间方程,便可计算出该人员甲的实时空间坐标(x,y,z)。
[0059][0060][0061][0062][0063]
其中,
[0064]
c为声波在空气中的传播速度;
[0065]
(x,y,z)为人员的实时空间坐标;
[0066]
(x1,y1,z1)为a声波的声波发生坐标;
[0067]
(x2,y2,z2)为b声波的声波发生坐标;
[0068]
(x3,y3,z3)为c声波的声波发生坐标;
[0069]
(x4,y4,z4)为d声波的声波发生坐标;
[0070]
t1为a声波的传播时间;
[0071]
t2为b声波的传播时间;
[0072]
t3为c声波的传播时间;
[0073]
t4为d声波的传播时间。
[0074]
步骤103,重复上述步骤得到多个人员的实时空间坐标;
[0075]
根据上述步骤,可以计算得到人员甲的实时空间坐标,同理,若空间中还存在人员乙、人员丙以及人员丁,多次重复上述步骤后,便可以得到空间内所有人员甲乙丙丁的实时空间坐标。
[0076]
步骤104,分别采集所述多个人员的实时动作数据;
[0077]
在本发明的一种实施例中,可以分别在每个人员身上的不同部位佩戴惯性传感器来实现该人员的实时动作数据的采集。
[0078]
步骤105,采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐标,构建涉及多个人员的虚拟场景。
[0079]
采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐标,构建涉及多个人员的虚拟场景的步骤包括:
[0080]
子步骤1051,构建初始虚拟场景;
[0081]
首先,构建初始虚拟场景,具体的可以通过布置虚拟元素构建初始虚拟场景,所述初始虚拟场景可以为丛林虚拟场景,沙漠虚拟场景,草原虚拟场景等等,本发明实施例对此
不作进一步的限制。
[0082]
子步骤1052,采用多个人员的实时动作数据构建多个独立虚拟人体模型;
[0083]
在本发明的实施例中,每个人员的实时动作数据都可以构建其独立的虚拟模型,
[0084]
子步骤1053,根据所述多个人员的实时空间坐标,将所述多个独立虚拟人体模型定位到所述初始虚拟场景中,得到涉及多个人员的虚拟场景。
[0085]
根据所述多个人员的实时空间坐标,将所述多个独立虚拟人体模型定位到所述初始虚拟场景中,得到多个人员的虚拟场景的步骤包括:
[0086]
在所述虚拟场景中建立虚拟空间坐标系;
[0087]
根据人员的实时空间坐标,确定所述人员在所述虚拟空间坐标系中的虚拟位置;
[0088]
在所述虚拟位置上显示所述人员对应的独立虚拟人体模型;
[0089]
例如,在虚拟场景中建立虚拟空间坐标系后,若人员甲的实时空间坐标为(2,3,1),那么确定虚拟空间坐标系中的虚拟坐标(2,3,1)为人员甲的虚拟位置,然后在虚拟坐标(2,3,1)的虚拟位置上,显示人员甲对应的独立虚拟人体模型。
[0090]
重复上述步骤,得到涉及多个人员的虚拟场景。
[0091]
同理,重复上述步骤,将空间内人员乙、人员丙等所有人员对应的独立虚拟人体模型显示于各自的虚拟位置上,得到涉及多个人员的虚拟场景。
[0092]
在本发明实施例中,在同一空间内的多个不同位置发生频谱各不相同的多组声波,当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标,重复上述步骤得到多个人员的实时空间坐标,分别采集所述多个人员的实时动作数据,采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐标,构建涉及多个人员的虚拟场景,采用本技术的技术方案,当空间内存在障碍物,或者人员聚集重叠,也不影响涉及多人员的虚拟场景的构建。
[0093]
需要说明的是,对于方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本发明实施例所必须的。
[0094]
参照图2,示出了本发明的一种涉及多人员的虚拟场景的构建系统实施例一的结构框图,具体可以包括如下模块:
[0095]
声波发生模块201,用于在同一空间内的多个不同位置发生频谱各不相同的多组声波;
[0096]
实时空间坐标计算模块202,用于当佩戴于人员身上的拾音器接收到所述多组声波时,根据所述多组声波计算所述人员的实时空间坐标;
[0097]
多人员实时空间坐标获取模块203,重复上述步骤得到多个人员的实时空间坐标;
[0098]
实时动作数据采集模块204,用于分别采集所述多个人员的实时动作数据;
[0099]
虚拟场景构建模块205,用于采用所述多个人员的实时动作数据以及所述多个人员的实时空间坐标,构建涉及多个人员的虚拟场景。
[0100]
在本发明实施例中,所述实时空间坐标计算模块包括:
[0101]
声波信息解析子模块,用于从所述多组声波中解析得到多组声波信息;
[0102]
声波接收时间确定子模块,用于确定与所述多组声波对应的多组声波接收时间;
[0103]
实时空间坐标计算子模块,用于采用所述多组声波信息以及多组声波接收时间,计算得到所述人员的实时空间坐标。
[0104]
在本发明实施例中,所述虚拟场景构建模块包括:
[0105]
初始虚拟场景构建子模块,用于构建初始虚拟场景;
[0106]
独立虚拟人体模型构建子模块,用于采用多个人员的实时动作数据构建多个独立虚拟人体模型;
[0107]
独立虚拟人体模型定位子模块,用于根据所述多个人员的实时空间坐标,将所述多个独立虚拟人体模型定位到所述初始虚拟场景中,得到涉及多个人员的虚拟场景。
[0108]
在本发明实施例中,所述独立虚拟人体模型定位子模块包括:
[0109]
虚拟空间坐标系建立单元,用于在所述虚拟场景中建立虚拟空间坐标系;
[0110]
虚拟位置确定单元,用于根据人员的实时空间坐标,确定所述人员在所述虚拟空间坐标系中的虚拟位置;
[0111]
独立虚拟人体模型现实单元,用于在所述虚拟位置上显示所述人员对应的独立虚拟人体模型;
[0112]
虚拟场景构建单元,用于重复上述步骤,得到涉及多个人员的虚拟场景。
[0113]
对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0114]
本发明实施例还提供了一种装置,包括:
[0115]
包括处理器、存储器及存储在所述存储器上并能够在所述处理器上运行的计算机程序,该计算机程序被处理器执行时实现上述一种涉及多人员的虚拟场景的构建方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
[0116]
本发明实施例还提供了一种计算机可读存储介质,计算机可读存储介质上存储计算机程序,计算机程序被处理器执行时实现上述一种涉及多人员的虚拟场景的构建方法实施例的各个过程,且能达到相同的技术效果,为避免重复,这里不再赘述。
[0117]
本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
[0118]
本领域内的技术人员应明白,本发明实施例的实施例可提供为方法、装置、或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0119]
本发明实施例是参照根据本发明实施例的方法、终端设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0120]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0121]
这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0122]
尽管已描述了本发明实施例的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明实施例范围的所有变更和修改。
[0123]
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的相同要素。
[0124]
以上对本发明所提供的一种涉及多人员的虚拟场景的构建方法和一种涉及多人员的虚拟场景的构建系统,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。