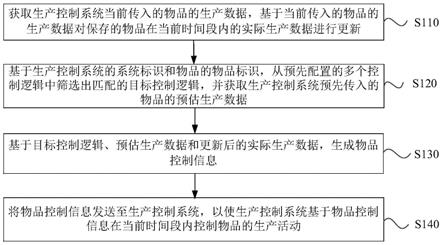
1.本发明涉及自然语言处理技术领域,尤其涉及一种基于多头自注意力机制的多任务篇章级事件抽取方法。
背景技术:
2.当今时代数据信息呈几何级别爆炸式增长,依托互联网技术的发展,每时每刻都有大量的数据产生,新闻数据的迅猛增加,娱乐数据的急剧增多,广告数据的飞速攀升,科技数据的剧猛增长
……
现如今,我们已全面进入大数据时代。如此众多的数据信息,形式多样,错综复杂,难以挖掘和处理,难以利用和分析。为了从新闻数据中提取出更多有价值的信息,关键的就是对新闻文本中包含的实体,关系以及事件进行抽取,对他们之间的作用关系进行分析和预测,以将提取的信息展现的更加系统化规范化。当前已知的知识资源(例如,维基百科等),其所描述的实体及实体之间存在的关系绝大多数都是静态的,而事件更能描述动态的知识。事件,作为信息的表现形式之一,主要描述特定时间、地点、人和物相互作用的客观事实。事件抽取主要是从描述事件信息的文本中抽取出什么人,什么时间,在什么地点,做了什么事,以更加结构化的方式呈现出来。事件抽取作为一种主流的自然语言处理任务,包括一系列的抽取任务,如:事件触发词的发现,事件类型的识别,事件论元以及论元角色的提取。相比于关系抽取任务,事件抽取同样需要从文本中抽取出元素和参数,但与关系抽取不同的是,关系抽取的元素和参数大都存在于同一个句子中,而事件抽取的难点在于,同一个事件会有多个参数和事件触发词,可能分布在多个句子中,而且有些参数还可能不是必需的,这些都加大了事件抽取的难度。目前的事件抽取主要分为句子级别的抽取和篇章级别的事件抽取。事件抽取的第一步即是事件触发词的发现。事件触发词就是最能体现事件发生的动词或者名词。句子级别的事件抽取主要考虑从同一个句子中抽取出一个或者多个事件触发词,进而通过对事件触发词进行分类,从而找到该事件所属的类别。然而句子级别的事件抽取忽略了不同句子间的相互关系,忽略了事件元素和论元可能存在于不同句子中的情况。因此,如何高效地进行篇章级的事件抽取具有重要的研究价值。
3.目前的事件抽取方法主要包括中文事件抽取、开放域事件抽取、事件数据生成、跨语言事件抽取、小样本事件抽取、零样本事件抽取等,涉及模式匹配,机器学习,深度学习等众多方法。这些方法在事件抽取领域取得了巨大的成功,其中预训练语言模型的出现使得事件抽取能力得到了进一步的提升。基于预训练模型的句子级事件抽取模型能捕捉到同一句子中不同单词上下文相关的双向特征表示,多头自注意力机制通过attention mask动态编码变长序列,解决了长距离依赖问题,但是基于预训练模型bert的语言模型,没有考虑mask之间的相关性,是对语言模型联合概率的有偏估计,而且输入噪声mask会造成预训练和微调两阶段之间的差异,并且只适合于句子和段落级别的任务。
技术实现要素:
4.本发明为解决现有事件抽取技术大多停留在单句子事件抽取阶段,无法跨子句捕
捉细节特征,且没有充分考虑篇章中上下文的相互关系,基于预训练模型的事件抽取只适用于句子和段落之间的任务等问题,提供了一种基于多头自注意力机制的多任务篇章级事件抽取方法,解决了现有句子级别的事件抽取大多停留在单据单一事件抽取,忽略了句内多触发词,忽略了不同句子间的相互关系,忽略了事件元素和论元可能存在于不同句子中的情况,实现了将序列标注问题转换为机器阅读理解问题的突破。本发明可用于篇章级事件抽取任务。
5.一种基于多头自注意力机制的多任务篇章级事件抽取方法,具体包括如下步骤:
6.步骤1、利用框架网络进行事件类型的建模,将框架网络与事件类型进行相应映射,根据框架得到标注数据集,并对触发词进行上下位词的发现和同义词的扩充,生成扩充触发词后的标注数据集;
7.步骤2、利用预训练的语言模型进行词嵌入表示;对单句中所有单词嵌入和位置嵌入作为输入,利用卷积神经网络模型进行编码,结合分段最大池策略,将特征图根据事件触发词划分为两段,分段提取每个句子段中单词的最大特征,全连接后得到单一句子的语义特征表示;
8.步骤3、利用假设:如果一个文本中含有某个事件类型,那么该文档中至少有一个句子可以完全概括该事件类型,将同一篇文本中的句子打包为一个句子包;句子包中含有步骤2得到的单一句子的语义特征表示,将句子包中的所有单一句子的语义特征表示输入到多头自注意力模型中,获得每个句子在整个文本中的融合了全文语义信息后的增强向量表示,即文本的篇章级语义特征表示;
9.步骤4、输入步骤3得到的篇章级语义特征表示,利用分类器函数进行分类,进而得到最终的事件类型;
10.步骤5、利用步骤4预测出的事件类型作为先验信息,链接到事件元素提取的输入序列中,构造基于微调的bert模型的规范输入序列,并结合机器阅读理解方法进行序列标注;
11.步骤6、基于步骤5预测实体开始索引和结束索引的概率分布,利用二分类策略提取所有可能的参数实体。
12.优选地,所述对触发词进行上下位词的发现和同义词的扩充是利用基于认知学的英语词汇词典对框架网络中事件类型涉及的触发词进行的。
13.优选地,所述步骤2前,还包括步骤200:将扩充后的标注数据集进行数据预处理,获得符合预训练的语言模型的输入格式的规范数据。
14.优选地,所述步骤2,具体包括如下步骤:
15.步骤201、对各个篇章中的句子进行处理,将篇章划分为每个最大长度为500个单词的句子,对句子进行分词处理;
16.步骤202、利用预训练的语言模型bert进行词嵌入表示,用word表示通过查找词嵌入转换而成的每个单词标记向量,将每个单词映射到一个维向量中;
17.步骤203、用position表示当前词到触发词的距离嵌入,通过查找位置嵌入矩阵,将当前词到触发词的相对距离转换为实值向量;
18.步骤204、将词嵌入和位置嵌入输入到卷积神经网络模型的卷积层得到句子特征矩阵;将特征矩阵输入到池化层获取细粒度特征,最后利用全连接层得到单个句子的特征
表示。
19.优选地,所述池化层为了进一步获取更加细粒度的句子表示特征,利用触发词将每个特征映射依据是否包含事件触发词划分为两个部分{c
i1
,c
i2
},使用分段最大池策略对每个部分分别捕获最大值特征:
20.p
ij
=max(c
ij
) 1≤i≤n,1≤j≤2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
21.p
ij
表示取两部分句子特征的最大值,因此,每个卷积核输出得到一个二维向量p
i
={p
i1
,p
i2
},因此,每个卷积核输出得到一个二维向量p
i
={p
i1
,p
i2
},利用非线性函数如双曲正切函数tanh(
·
)连接所有输出向量p
1:n
,得到分段最大池的输出向量如下:
22.g=tanh(p
1:n
)∈r
2n
ꢀꢀꢀꢀꢀꢀ
(6)
23.则可得到单个句子的向量表示,其中g
i
为文本中第i个句子的向量表示。
24.优选地,所述步骤3,具体包括如下步骤:
25.步骤301、假设:每篇文本至少有一个句子可以完整的表述该文本所提及的事件,通过多头自注意力机制多场景多层面融合句子特征,以得到文本的篇章级表示,采用乘法注意力机制的策略来实现高度优化的矩阵乘法的运行;输入一个句子包,句子包中有m个句子,其句子包表示为:
26.g=[g1,g2,
…
,g
m
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)其中,g
i
为文本中第i个句子的向量表示,g是整个句子包的表示,
[0027]
步骤302、将得到的句子包中的所有单一句子的语义特征表示输入到多头自注意力模型,计算单头的self
‑
attention,用r作为该层最终输出值的表示,过程如下:
[0028][0029][0030]
其中,d
g
是隐藏层的节点数,a是一个权重参数向量,softmax(
·
)函数用来归一化单头计算的结果,经过一次单头的self
‑
attention计算,得到的单次attention输出特征值如下:
[0031]
g*=tanh(r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0032]
多头的注意力机制multi
‑
head self
‑
attention计算过程则为多次计算单头的self
‑
attention,假设多头的注意力模型头数为h,即进行h次单头的self
‑
attention计算,再把输出合并起来,计算过程如下:
[0033]
式(8)每次使用句子包表示矩阵g前,为压缩单次self
‑
attention计算的g的维度以及为达到单多头attention并行执行的目的,需先对g做一次线性变换:其中
[0034]
步骤303、每次使用不同的权重a,用式(8)~(10)进行h次计算,将得到的每个self
‑
attention结果g*合并起来并进行线性映射可得最终的multi
‑
head self
‑
attention计算结果g
c
:
[0035][0036]
其中,表示逐个元素进行点乘运算,a
c
表示权重矩阵,维度为h
×
d
g
,表示h个self
‑
attention结果g*进行全连接,g
c
则为全连接层的输出,
即融合了全文语义信息的增强的篇章级语义特征表示。
[0037]
优选地,所述步骤5,具体包括如下步骤:
[0038]
步骤501、将每个文本划分为最大为500词的语段,对于语段进行分句、分词等预处理操作;
[0039]
步骤502、将每个句子作为一个给定的输入序列,记为x={x1,x2,
…
,x
n
},其中n为输入序列的长度,为抽取出事件中的所有元素,即找到x中的每个实体,然后给它分配一个预定义的实体标签t∈t,t是一个预定义的实际标签集合,如人名(per),地名(loc),时间(time),组织(org)等,对于每个t与一个长度为k的query问题序列相对应,记为q
t
={q1,q2,...,q
k
};
[0040]
步骤503、利用基于模板的方法为不同的事件类型中的事件元素构造查询三元组(q,a,c),其中q为查询问题question,a为查询结果answer,c为查询内容content,将标注实体表示为x
s2e
={x
s
,x
s 1
,...,x
e
‑1,x
e
}(s<e),其中s表示start,e表示end,x
s2e
表示输入序列x起始到结束的连续标注的span,因此,三元组(q
t
,x
s2e
,x)对应于查询三元组(q,a,c);
[0041]
步骤504、利用事件类型和预标注的实体序列作为先验信息,构造输入序列:
[0042]
{[cls],e
t
,[sep],q1,q2,...,q
k
,[sep],x1,x2,...,x
n
,[sep]}
ꢀꢀꢀꢀꢀꢀꢀ
(15)
[0043]
其中e
t
为事件类型,[cls]和[sep]为特殊的标记,q1,q2,...,q
k
为问题序列,x1,x2,...,x
n
为标注的实体序列,利用预训练的语言模型bert接收合并后的输入序列,并输出一个上下文表示矩阵e∈r
h
×2,h是输入序列的隐藏大小。
[0044]
本发明最为突出的特点和显著的有益效果是:本发明将单一句子级事件抽取转换为打包句子集合的篇章级事件抽取;利用预训练的语言模型bert模型进行词嵌入表示,以获取语义增强的词向量表示;对单句中所有单词嵌入和位置嵌入作为输入,利用卷积神经网络(cnn)模型进行编码,结合分段最大池策略捕获句子内部的最有价值的特征;利用多头自注意力(multi
‑
head self
‑
attention)模型,获得融合全文语义信息的篇章表示和注意力权重,不但考虑了句子内部单词间的语义关联程度,还考虑了整个篇章中不同句子间的上下文关系,使得语义增强的篇章向量表示更好的融合了全文信息;利用分类器得到预测的事件类型,具有优越的识别效果;利用事件类型作为先验信息,链接到事件元素提取的输入序列中,利用预训练模型结合机器阅读理解方法提取序列中所有相关元素,具有良好的识别提取性能,取得了将序列标注问题转换为机器阅读理解问题的突破。
附图说明
[0045]
图1为本发明一种基于多头自注意力机制的多任务篇章级事件抽取方法流程图;
[0046]
图2为本发明进行篇章级事件检测任务的整体结构示意图;
[0047]
图3为利用卷积神经网络和分段最大池获取句子表示的示意图;
[0048]
图4为利用多头自注意力机制获得篇章级向量表示的示意图;
[0049]
图5为本发明中利用事件类型作为先验信息进行利用机器阅读理解方法进行事件元素提取任务的示意图;
具体实施方式
[0050]
应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0051]
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
[0052]
为了更好说明本实施例,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。
[0053]
如图1、2所示,本实施例提供一种基于预训练语言模型的多任务篇章级事件抽取方法,具体包括如下步骤:
[0054]
步骤101、根据专家设计将通用领域事件类型分为5大类(action、change、possession、scenario、sentiment),168小类(如:attack、bringing、cost、departing
……
)
[0055]
步骤102、使用framenet工具对168小类事件类型进行与framenet的映射与分类。以attack攻击事件类型为例,对应于framenet框架网络中的counterattack(反击),attack(攻击),invading(入侵),suicide attack(自杀式袭击)四种不同框架描述,每种描述代表一种词汇单元,不同词汇单元包含不同的框架元素,framenet框架的词汇单元的详细目录包括内容和功能词,即引起事件发生的触发词,例如,attack攻击事件可能由触发词“fire(开火)”,“died(死亡)”等触发;箭头表示事件元素之间的关系,包括inheritance(继承关系)、using(子框架以父框架为背景)、subframe(子框架是父框架描述的一复杂事件的子事件)、perspective_on(子框架提供了未透视的父框架上的特定透视图);同理,将所有类别的事件进行framenet框架网络的映射,触发词对应的事件类别即为对应的framenet框架网络类别。
[0056]
步骤103、基于认知学的英语词汇词典(wordnet),扩充触发词的上下位词和同义词,生成扩充触发词后的标注数据集。训练数据集包括3000篇文本,涉及事件提及78000条(包含40%的负例),囊括168个事件类型,70000个事件。
[0057]
步骤200:将扩充后的标注数据集进行数据预处理,获得符合预训练的语言模型的输入格式的规范数据;
[0058]
步骤201、结合图3进行说明利用piece
‑
max
‑
pooling cnn模型获取句子级特征表示。分段最大池
‑
卷积神经网络模型(piece
‑
max
‑
pooling
‑
cnn模型)包括5层:分别为输入层,卷积层,池化层,全连接层和输出层;其中,卷积层由多个滤波器(fliters)和特征图(feature maps)组成,池化层由分段最大池(piece
‑
max
‑
pooling)组成。首先对各个篇章中的句子进行处理,将篇章划分为每个最大长度为500个单词的句子,对句子进行分词处理;
[0059]
步骤202、利用预训练的语言模型bert进行词嵌入表示,用word表示通过查找词嵌入转换而成的每个单词标记向量,将每个单词映射到一个d
w
维向量中;
[0060]
步骤203、用position表示当前词到触发词的距离嵌入,将当前词到触发词的相对距离转换为实值向量;如在图3中,假设词嵌入大小为d
w
=4,位置嵌入的大小为d
p
=1d
p
=1,因此一个句子中第i个词对应的d维向量表示记作:
[0061]
d=d
w
d
p
*2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0062]
长度为s的句子可用序列{q1,q2,
…
q
s
}表示为:
[0063][0064]
其中q
i
∈r
d
,表示连接操作,通常用q
i:j
表示从q
i
到q
j
的连接;
[0065]
步骤204、将词嵌入和位置嵌入共同组成实例的向量表示部分,转化为矩阵s∈r
s
×
d
,s则作为卷积操作的输入。
[0066]
卷积操作目的是提取整个句子的组合语义特征,并将这些语义特征压缩为特征映射。卷积是权重向量w和输入序列q之间的运算,卷积操作涉及一个卷积核ω,如图3所示,假设ω=3,则表示为上下文每3个词的滑动窗口生成一个新特征,则w∈r
ω*d
;用序列q中的每个ω元字串(ω
‑
gram)与权重矩阵w的点积运算得到特征序列(特征图)c∈r
s ω
‑1,其中第j个特征c
j
的计算公式为:
[0067]
c
j
=f(w
·
q
j
‑
ω 1:j
b)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0068]
其中,b是偏置项,b∈r,f(
·
)是一个非线性函数,j的取值范围是(1,s ω
‑
1)。为了提取多个特征,我们假设使用n个卷积核进行特征提取,则权重矩阵可用序列表示为w={w1,w2,
…
,w
n
},即提取n个特征可用公式表示为:
[0069]
c
ij
=f(w
i
·
q
j
‑
ω 1:j
b
i
)1≤i≤n 1≤i≤n
ꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0070]
卷积操作输出特征矩阵c={c1,c2,
…
,c
n
}∈r
n
×
(s ω
‑
1)
。
[0071]
将特征层提取的特征组合起来才能应用后续各层,通常使用最大池化操作来捕捉每个特征图中的最重要特征(最大值),单个最大池无法获得更细粒度的特征。而考虑到多触发词的事件情况,为了动态捕捉每个特征图中最重要的特征,我们使用分段最大池策略,利用触发词将每个特征映射划分为两个部分,分段最大池返回每段的最大值,而不是单个最大池。如图3所示,“attack”将句子分为两段{c
i1
,c
i2
},分段最大池操作过程如下:
[0072]
p
ij
=max(c
ij
) 1≤i≤n,1≤j≤2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0073]
因此,每个卷积核输出得到一个二维向量p
i
={p
i1
,p
i2
},利用非线性函数如双曲正切函数tanh(
·
)连接所有输出向量p
1:n
,得到分段最大池的输出向量如下:
[0074]
g=tanh(p
1:n
)∈r
2n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0075]
则可得到单个句子的向量表示,其中g
i
为文本中第i个句子的向量表示。
[0076]
步骤301、假设一个句子包中有m个句子,得到句子包的表示为:
[0077]
g=[g1,g2,
…
,g
m
]
ꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0078]
结合图4对引入的多头自注意力机制进行篇章级特征提取加以说明。根据假设:每篇文本至少有一个句子可以完整的表述该文本所提及的事件,我们将进一步通过多头自注意力机制(multi
‑
head self
‑
attention)融合句子特征,以得到文本的篇章级表示。multi
‑
head self
‑
attention的本质就是进行多次的self
‑
attention运算,如此不但可以使模型从不同表征子空间获取到更多场景更多层面下的特征,从而捕获更多的句子间的上下文特征。本方法采用乘法注意力机制的策略来实现高度优化的矩阵乘法的运行,如此不但可以提高模型的特征表达能力而且可以降低整体计算的计算成本。
[0079]
步骤302、如图4所示,将步骤301获取到的句子包的表示g=[g1,g2,
…
,g
m
]作为输入到multi
‑
head self
‑
attention模型中,单头的self
‑
attention计算过程如下,用r作为该层最终输出值的表示:
[0080][0081][0082]
其中,d
g
是隐藏层的节点数,a是一个权重参数向量,softmax(
·
)函数用来归一化单头计算的结果。经过一次单头的self
‑
attention计算,得到的单次attention输出特征值如下:
[0083]
g*=tanh(r)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0084]
多头的注意力机制multi
‑
head self
‑
attention计算过程则为多次计算单头的self
‑
attention,假设多头的注意力模型头数为h,即进行h次单头的self
‑
attention计算,再把输出合并起来,计算过程如下:
[0085]
式(8)每次使用句子包表示矩阵g前,为压缩单次self
‑
attention计算的g的维度以及为达到单多头attention并行执行的目的,需先对g做一次线性变换:其中
[0086]
步骤303、每次使用不同的权重a,用式(8)~(10)进行h次计算,将得到的每个self
‑
attention结果g*合并起来并进行线性映射可得最终的multi
‑
head self
‑
attention计算结果g
c
:
[0087][0088]
其中,表示逐个元素进行点乘运算,a
c
的维度为h
×
d
g
,g
c
则为融合了全文语义信息的增强的篇章向量表示。
[0089]
步骤4、事件检测即事件触发词的多分类问题,因此,我们在输出层使用softmax(
·
)函数作为分类器,计算每一个类别的条件概率,然后选取条件概率的最大值所对应的类别作为事件检测输出的事件类别。以下是具体的计算过程:
[0090]
p(y'|s)=softmax(a
c
g
c
b
c
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(12)
[0091][0092]
其中,e为事件类型个数。目标函数是具有l2正则化的类别y的负对数似然函数,如式子(14)所示:
[0093][0094]
其中,k是样本的个数,t
i
∈r
k
是关于类别的one
‑
hot向量,λ是l2的正则化因子,y
i
'是softmax(
·
)函数输出的概率向量,最大的概率所对应的类别就是事件检测出的事件类别。
[0095]
本实施方式提出的基于卷积神经网络cnn,结合分段最大池策略和多头自注意力机制(multi
‑
head self
‑
attention)的篇章级事件检测的方法,不但考虑到句子内各个词之间的上下文关系,而且融合了句子间的上下文语义关系,生成增强的篇章级文本向量表示,通过分类器计算的条件概率最大值所对应的类别作为最终的事件检测出来的事件类别,在篇章级事件抽取中取得了一定的成效。
[0096]
如图5所示,本实施方式给出的一种利用事件类型作为先验信息,链接到事件元素提取的输入序列中,利用机器阅读理解方法(mrc)进行参数提取的方法,具体包括以下步骤:
[0097]
步骤501、将每个文本划分为最大为500词的语段,对于语段进行分句,分词等预处理操作。
[0098]
步骤502、将每个句子作为一个给定的输入序列,记为x={x1,x2,...,x
n
},其中n为输入序列的长度,为抽取出事件中的所有元素,即找到x中的每个实体,然后给它分配一个
预定义的实体标签t∈t,t是一个预定义的实际标签集合,如人名(per),地名(loc),时间(time),组织(org)等,对于每个t与一个长度为k的query问题序列相对应,记为q
t
={q1,q2,
…
,q
k
}。
[0099]
步骤503、利用基于模板的方法为不同的事件类型中的事件元素构造一些查询问题query,构造查询三元组(q,a,c),其中q为查询问题question,a为查询结果answer,c为查询内容content,例如,对于attack事件,相应的查询可能有“who is under attack?”等等。将标注实体表示为x
s2e
={x
s
,x
s 1
,
…
,x
e
‑1,x
e
}(s<e),其中s表示start,e表示end,x
s2e
表示输入序列x起始到结束的连续标注的span。因此,三元组(q
t
,x
s2e
,x)对应于查询三元组(q,a,c)。
[0100]
步骤504、利用事件类型作为先验信息,构造输入序列:
[0101]
{[cls],e
t
,[sep],q1,q2,
…
,q
k
,[sep],x1,x2,
…
,x
n
,[sep]}
ꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0102]
其中e
t
为事件类型,[cls]和[sep]为特殊的标记。利用预训练的语言模型bert接收合并后的输入序列,并输出一个上下文表示矩阵e∈r
h
×2,h是输入序列的隐藏大小。
[0103]
步骤601、将矩阵e输入到mrc模型中,利用两个二分类器策略,分别预测每个标记作为开始索引和结束索引的概率,用p表示,计算公式如下:
[0104]
p
s
=softmax(w
s
e b
s
)∈r
h
×2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0105]
p
e
=softmax(w
e
e b
e
)∈r
h
×2ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(17)其中,p
s
表示每个标记作为开始索引的概率,p
e
表示每个标记作为结束索引的概率,w
s
和w
e
表示每个标记作为开始索引和结束索引待学习的权重,b
s
和b
e
表示偏置项。使用softmax(
·
)函数的二分类策略是指,如果标记是开始索引或者结束索引,则用1表示,否则用0表示。
[0106]
步骤602、考虑到实体重叠问题,使用argmax(
·
)函数对预测的开始索引和结束索引进行匹配,得到可能是开始索引或者是结束索引,用公式表示如下:
[0107][0108][0109]
其中(i)表示矩阵的第i行,(j)表示矩阵的第j行。
[0110]
步骤603、步骤602得到的两个矩阵,开始索引矩阵和结束索引矩阵给定任意的开始索引和结束索引用一个二分类模型来训练开始索引和结束索引的匹配概率,用如下公式表示:
[0111][0112]
其中,w∈r1×
2d
是要学习的匹配权重,d是bert模型最后一层的维度。
[0113]
步骤604、分别预测实体的开始位置、结束位置、从开始到结束位置是实体的概率,损失函数由三部分构成:
[0114]
l
s
=ce(p
s
,t
s
)
[0115]
l
e
=ce(p
e
,t
e
)
[0116]
l
span
=ce(p
s2e
,t
s2e
)
[0117]
其中,l
s
表示每个标记的二分类ce之和(答案answer开始),l
e
表示每个标记的二分
类ce之和(答案answer结束),l
span
用二维矩阵来记录真实实体在句子中从开始到结束(start,end)的位置。
[0118]
则整体损失函数为:
[0119]
l=αl
s
βl
e
γl
span
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21)其中,α,β,γ∈[0,1]是损失函数的超参数。在预训练语言模型bert层三个损失函数进行端到端的训练,测试时将匹配的开始索引和结束索引利用匹配模型进行匹配对齐,得到提取的参数结果。
[0120]
通过上述方案,充分利用事件类型的先验信息,在编码前链接了句子和对应事件类型的表示,使得来自同一文本的所有句子都共享事件检测模块所预测的相同事件类型,使得事件元素抽取的精度和性能得以提升。
[0121]
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。