1.本发明涉及信息处理技术领域,特别涉及一种基于主题标签的跨域推荐方法。
背景技术:
2.近些年计算机技术的迅猛发展和在线社交媒体数据信息的海量化,使人们逐渐开始关注使用计算机手段对跨域用户的兴趣特征进行追踪与识别。在跨域场景中去检测及跟踪处理多个目标的兴趣特征信息,这在线社交媒体等地方具有重要实际意义,不光可以为社交平台提供有效的特征信息结果集,还能为跨多域的用户提供可靠的物品推荐。为此本发明提出了一种基于主题标签的跨域推荐方法及系统,以主题建模的方式,对物品标签中所包涵的语义信息进行提取,实现跨域场景下的兴趣推荐算法模型。通过引入标签的语义信息,该模型解决了多域中缺乏共享用户信息的情景下,仍然可以利用辅助域的标签及评分属性信息来完成跨域的用户兴趣关联与推荐,提升了对目标域用户物品评分预测的效果,增加了跨域场景下用户兴趣特征信息识别的使用价值。
3.朱全银等人已有的研究基础包括:quanyin zhu,sunqun cao.a novel classifier
‑
independent feature selection algorithm for imbalanced datasets.2009,p:77
‑
82;李翔,朱全银.联合聚类和评分矩阵共享的协同过滤推荐[j].计算机科学与探索,2014,8(6):751
‑
759;quanyin zhu,yunyang yan,jin ding,jin qian.the case study for price extracting of mobile phone sell online.2011,p:282
‑
285;quanyin zhu,suqun cao,pei zhou,yunyang yan,hong zhou.integrated price forecast based on dichotomy backfilling and disturbance factor algorithm.international review on computers and software,2011,vol.6(6):10891093;ma s,cao m,li j,et al.a face sequence recognition method based on deep convolutional neural network[c]//2019 18th international symposium on distributed computing and applications for business engineering and science(dcabes).ieee,2019:104
‑
107;朱全银等人申请、公开与授权的相关专利:朱全银,刘涛,严云洋,高尚兵等.一种基于opencv的建筑图纸标签信息检测方法.中国专利公开号:cn109002824a,2018.12.14;朱全银,许康,宗慧,冯万利等.一种基于faster
‑
rcnn模型的建筑构件提取方法.中国专利公开号:cn109002841a,2018.12.14;冯万利,严云洋,杨茂灿,朱全银等人.一种身份认证系统的智能终端ic卡授权与管理方法.中国专利公开号:cn107016310b,2019.12.10;朱全银,于柿民,胡荣林,冯万利等.一种基于知识图谱的专家组合推荐方法.中国专利公开号:cn109062961a,2018.12.21;朱全银,马思伟,曹猛,李佳冬等.一种多目标跟踪及面部特征信息识别方法.中国专利公开号:cn111914613a,2020.11.10;肖绍章,倪金霆,朱全银,陈小艺,马思伟等.一种基于区块链互证和卷积神经网络的凭证式记账方法.中国专利公开号:cn110188787b,2020.11.03.
[0004]
基于近邻的协同过滤:
[0005]
基于近邻的策略是一种最常见到的协同过滤方法,它依赖于“志同道合的用户”观
点,对人们生活中选择物品的习性进行了特性抽取,即假设如果用户关系相近的朋友喜欢对某物品展现出了兴趣,那么该用户也存在着较高概率对该物品感兴趣,进而对当系统推荐时,用户会进行选择。
[0006]
基于潜在特征的协同过滤:
[0007]
与基于近邻的方法不同,基于潜在特征的策略从偏好度矩阵入手,抛弃了前者直接通过相关联对象之间已有的评分来进行新对象组合的评分推断,它是以系统中的组合对象的偏好度矩阵为依据,以系统中用户对物品的偏好度矩阵在低维下的特征向量低维度映射来进行推断。
[0008]
基于迁移学习的模型:
[0009]
迁移学习主要通过已有解决问题的模型,在其他不同但相关的地方进行利用,即是在具体的多个有关联性的任务中,通过已经完成训练和优化的模型,将其参数进行迁移用以辅助新任务模型的训练。迁移学习的关键点在于把握好迁移学习过程中的桥梁,通过一定的方法,对不同领域共有的知识进行提取和迁移,本质上其实是知识的迁移与再利用。在这个框架下,对于模型的训练与迭代就可以分为切分为两个阶段:首先需要对单域中的参数进行更新;其次是对映射函数的参数进行调整。
[0010]
相似性权重计算:
[0011]
相似性权重是作为推荐评估关键因素,影响着推荐结果评价最为重要的两个指标,即是系统的推荐性能以及推荐结果的准确率。
[0012]
相似性的计算同样基于一个假设的条件作为前提,即是相似的用户群体间具有相似的物品兴趣倾向,另一个侧面来说,相似的物品样本也总是会被有限个相似的系统中的用户群体所感兴趣。相似性的计算中,常用的手段之一是计算系统中用户或物品的特征向量的余弦夹角,通过其数值评估系统中不同对象间的相似性。
[0013]
在多目标兴趣特征信息跟踪和检测方面,目前多数研究主要面向单域场景下等问题的单方面处理,缺乏对具有标签属性的跨域场景中多目标兴趣特征自适应分类方法的研究,信息融合较为单一,且对具有跨域属性的数据下多目标兴趣特征信息跟踪及分析效率也有限。
[0014]
如:王新华等人提出一种基于图卷积矩阵分解的社交兴趣推荐方法及系统,根据用户潜在特征矩阵和项目潜在特征矩阵,将潜在的项目推荐给待推荐用户,中国专利公开号:cn111523051a 2020.02.24;刘方爱等人提出了一种基于用户序列点击行为的兴趣推荐方法及系统,有效弥补现存序列推荐方法忽略用户序列行为的内在结构和忽略项目之间转换关系等问题,中国专利公开号:cn110807156a,2019.10.23;魏哲巍等人提出了一种基于单源simrank的协同过滤推荐方法,能够在有效时间内计算出大图的单源simrank的结果,满足实时推荐、交互查询的需求,中国专利公开号:cn110287424a,2019.06.28;张雨柔等人提出一种基于深度学习的主题标签推荐方法,利用支持向量机svm模型对提取的特征进行主题标签的特征分类,同时利用结合词嵌入模型word2vec和k近邻算法对预测主题标签进行扩展,使得标注结果更为可靠,中国专利公开号:cn110297933a,2019.07.01。
技术实现要素:
[0015]
发明目的:针对现有技术中存在的问题,本发明提出一种基于主题标签的跨域推
荐方法,目的在于解决跨域场景下用户推荐的问题。
[0016]
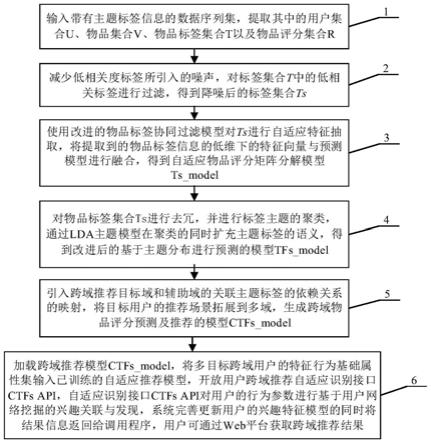
技术方案:为解决上述技术问题,本发明提供一种基于主题标签的跨域推荐方法,包括如下步骤:
[0017]
(1)输入带有主题标签信息的数据序列集,提取其中的用户集合u、物品集合v、物品标签集合t以及物品评分集合r;
[0018]
(2)减少低相关度标签所引入的噪声,对物品标签集合t中的低相关标签进行过滤,得到降噪后的物品标签集合ts;
[0019]
(3)使用改进的物品标签协同过滤模型对物品标签集合ts进行自适应特征抽取,将提取到的物品标签信息的低维下的特征向量与预测模型进行融合,得到自适应物品评分矩阵分解模型ts_model;
[0020]
(4)对物品标签集合ts进行去冗,并进行标签主题的聚类,通过lda主题模型在聚类的同时扩充主题标签的语义,得到改进后的基于主题分布进行预测的模型tfs_model;
[0021]
(5)引入跨域推荐目标域和辅助域的关联主题标签的依赖关系的映射,将目标用户的推荐场景拓展到多域,生成跨域物品评分预测及推荐模型ctfs_model;
[0022]
(6)加载跨域物品评分预测及推荐模型ctfs_model,将多目标跨域用户的特征行为基础属性集输入已训练的跨域物品评分预测及推荐模型ctfs_model中,开放用户跨域推荐自适应识别接口ctfs api,所述跨域推荐自适应识别接口ctfs api对用户的行为参数进行基于用户网络挖掘的兴趣关联与发现,完善更新用户的兴趣特征模型的同时将结果信息返回给调用程序,用户通过web平台获取跨域推荐结果。
[0023]
进一步的,步骤(1)具体包括如下内容:
[0024]
(1.1)输入带有主题标签信息的数据集s,定义函数len(s)表示数据集s的长度,令s={s1,s2,s3,
…
,s
i
},其中,s
i
表示s中第i项数据,i∈[1,len(s)];
[0025]
(1.2)定义循环变量i1,用于遍历s,i1∈[1,len(s)],i1赋初值为1;
[0026]
(1.3)如果i1≤len(s)则进入步骤(1.4),否则进入步骤(1.10);
[0027]
(1.4)提取数据项s
i
中的用户u并入用户集合u中,u={u1,u2,u3,
…
,u
i
},其中,i表示提取到的用户的数目;
[0028]
(1.5)提取数据项s
i
中的物品v并入物品集合v中,v={v1,v2,v3,..,v
j
},其中,j表示提取到的物品的数目;
[0029]
(1.6)提取数据项s
i
中的标签t并入物品标签集合t中,t={t1,t2,t3,
…
,t
n
},其中,n表示提取到的物品标签的数目;
[0030]
(1.7)提取数据项s
i
中的评分r并入物品评分集合r中,r={r1,r2,r3,
…
,r
o
},其中,o表示提取到的物品评分的数目;
[0031]
(1.8)建立组合集uvtr,用户集合u中用户u通过一组物品标签集合t和物品评分集合r标记物品集合v中物品v,“用户
‑
物品
‑
标签
‑
评分”的四元组数据记为(u,v,t
ij
,r
ij
),其中,u∈u,v∈v,r
ij
∈r,t
ij
表示用户u
i
对物品v
j
所标记的标签集合,r
ij
表示u
i
对v
j
的项目评分;
[0032]
(1.9)i1=i1 1,进入步骤(1.3);
[0033]
(1.10)训练数据集的预处理流程结束。
[0034]
进一步的,所述步骤(2)具体包括如下内容:
[0035]
(2.1)输入物品标签集合t及组合集uvtr;
[0036]
(2.2)根据标签数据基于powerlaw分布的原理,分析标签流行度k与流行度为k的标签总的样本数量n(k)的数据信息;
[0037]
(2.3)定义循环变量i2用于遍历t,定义函数len(t)表示物品标签集合t的长度,i2∈[1,len(t)],i2赋初值为1,t i2
为t中的第i2个物品标签;
[0038]
(2.4)如果i2≤len(t)则进入步骤(2.5),否则进入步骤(2.11);
[0039]
(2.5)使用秩和检验的方法,通过参数调优在置信区间ci中确定置信度xci,通过置信度xci评估物品标签与评分的相关性数据值;
[0040]
(2.6)分析标签流行度的长尾分布;
[0041]
(2.7)分析出现标签频率并过滤剔除低于设定阈值的标签,定义低于设定阈值的标签为低相关度标签;
[0042]
(2.8)分析并优化处理所述低相关度标签的噪声;
[0043]
(2.9)评估保留标签及去除标签后评分样本的分布秩和检验的结果,对剔除低相关标签后的结果集进行验证评估;
[0044]
(2.10)i2=i2 1,进入步骤(2.4);
[0045]
(2.11)得到降噪后的物品标签集合ts。
[0046]
进一步的,所述步骤(3)具体包括如下内容:
[0047]
(3.1)输入物品标签集合ts以及组合集uvtr,定义函数len(ts)表示物品标签集合ts的长度,定义循环变量i3用于遍历ts,i3∈[1,len(ts)],i3赋初值为1;
[0048]
(3.2)如果i3≤len(ts),则进入步骤(3.3),否则进入步骤(3.17);
[0049]
(3.3)分析与物品i相关的标签全集,计算标签t于物品i上所关联的数目,得到关键物品标签信息;
[0050]
(3.4)将提取到关键物品标签信息的低维下的特征向量与预测模型进行融合,分析给定用户u和物品i的关联性并进行评分预测;
[0051]
(3.5)定义len(uvtr)为数据集uvtr的长度,定义循环变量j3用于遍历uvtr,j3∈[1,len(uvtr)],j3赋初值为1;
[0052]
(3.6)如果j3≤len(uvtr),则进入步骤(3.7);
[0053]
(3.7)分析用户u、物品i以及标签t的潜在特征向量并提取;
[0054]
(3.8)分析并评估用户u和物品i的偏移量;
[0055]
(3.9)分析并使用随机梯度下降最小化误差;
[0056]
(3.10)遍历评分项中该物品的所有标签,更新标签域信息;
[0057]
(3.11)j3=j3 1,进入步骤(3.6);
[0058]
(3.12)将标签信息的特征向量进行低维度下的映射;
[0059]
(3.13)将提取到关键物品标签信息的低维下的特征向量与预测模型进行融合;
[0060]
(3.14)分析给定用户u和物品i的关联性并进行评分预测;
[0061]
(3.15)获得遍历迭代后的参数,调优模型信息;
[0062]
(3.16)i3=i3 1,进入步骤(3.2);
[0063]
(3.17)模型训练完毕,得到自适应物品评分矩阵分解模型ts_model。
[0064]
进一步的,所述步骤(4)具体包括如下内容:
[0065]
(4.1)输入物品标签集合ts;
[0066]
(4.2)将物品标签集合ts进行标签主题的聚类;
[0067]
(4.3)定义len(ts)为ts的长度,定义循环变量i4用于遍历ts,i4∈[1,len(ts)],i4赋初值为1;
[0068]
(4.4)遍历ts,如果i4≤len(ts),则跳转到步骤(4.5),否则结束遍历ts,跳转到步骤(4.19);
[0069]
(4.5)对物品标签集合ts中的元素进行去冗;
[0070]
(4.6)通过lda主题模型在聚类的同时扩充主题标签的语义;
[0071]
(4.7)定义用户状态flag,其中,flag为1时表示进入新的用户;
[0072]
(4.8)如果flag值为1,则跳转步骤(4.9),否则跳转步骤(4.17);
[0073]
(4.9)分析提取用户的兴趣偏向的行为特征;
[0074]
(4.10)如果进入新用户已被辅助域记载,则跳转步骤(4.11),否则跳转步骤(4.18);
[0075]
(4.11)通过模型提取每个用户的行为特征并进行用户兴趣模型参数的更新,完善用户模型;
[0076]
(4.12)计算用户特征向量在多个维度上的兴趣偏好值;
[0077]
(4.13)根据聚合特征及用户模型,更新用户信息;
[0078]
(4.14)如果flag值为1,则跳转步骤(4.17),否则跳转步骤(4.15);
[0079]
(4.15)创建新用户的行为分析模型;
[0080]
(4.16)如果用户兴趣特征已被记录,则跳转步骤(4.18),否则跳转步骤(4.19);
[0081]
(4.17)计算物品主题特征的权值与物品主题分布在主题区间上的概率;
[0082]
(4.18)采用随机梯度下降最小化正则均方误差对模型的参数进行迭代更新与模型自适应参数学习;
[0083]
(4.19)i4=i4 1,进入步骤(4.4);
[0084]
(4.20)得到改进后的基于主题分布进行预测的模型tfs_model。
[0085]
进一步的,所述步骤(5)具体包括如下内容:
[0086]
(5.1)引入跨域推荐目标域和辅助域的关联主题标签,定义跨域主题标签集合cts,其中,cts={t1,t2,t3,
…
,t
ctn
},ctn表示所提取不同域中交叉重叠主题标签集合的数目;
[0087]
(5.2)进行目标域和辅助域的关联主题标签的依赖关系的映射,将目标用户的推荐场景拓展到多域,分析不同域间的用户以及物品的联系,利用辅助域的特征属性信息来解决跨域中遇到的数据稀疏性和系统冷启动问题;
[0088]
(5.3)加载自适应物品评分矩阵分解模型ts_model,定义len(cts)为跨域主题标签集合cts的长度,定义循环变量i5用于遍历跨域主题标签集合cts,i5∈[1,len(cts)],i5赋初值为1;
[0089]
(5.4)如果i5≤len(cts)则进入步骤(5.5),否则进入步骤(5.12);
[0090]
(5.5)利用标签的影响权度进行跨域的引入;
[0091]
(5.6)通过辅助域来对目标域的评分与标签的关联程度进行学习;
[0092]
(5.7)利用关联标签语义信息的域间传递进行目标域的处理;
[0093]
(5.8)分析推荐域的用户以及物品的潜在特征向量;
[0094]
(5.9)分析推荐域标签的主题分布情况,获取主题的特征矩阵;
[0095]
(5.10)通过随机梯度下降的最小化正则误差进行模型的迭代更新与参数的自适应学习;
[0096]
(5.11)i5=i5 1,进入步骤(5.4);
[0097]
(5.12)将自适应物品评分矩阵分解模型ts_model拓展到多域的场景下进行跨域层面的用户网络的兴趣预测和跨域物品的推荐;
[0098]
(5.13)获得跨域物品评分预测及推荐模型ctfs_model。
[0099]
进一步的,所述步骤(6)具体包括如下内容:
[0100]
(6.1)开放跨域推荐自适应识别接口ctfs api;
[0101]
(6.2)创建线程池ctfs thread pool;
[0102]
(6.3)判断线程池ctfs thread pool所有任务是否执行完毕,如果所有任务执行完毕,则进入步骤(6.9),否则进入步骤(6.4);
[0103]
(6.4)接收来自终端的数据处理请求;
[0104]
(6.5)子线程ctfs child thread获取任务处理;
[0105]
(6.6)跨域推荐自适应识别接口ctfs api对用户的行为参数进行基于用户网络挖掘的兴趣关联与发现,完善更新用户的兴趣特征模型;
[0106]
(6.7)将结果信息返回给调用程序,用户通过web平台获取跨域推荐结果;
[0107]
(6.8)结束该子进程ctfs child thread,进入步骤(6.3);
[0108]
(6.9)关闭线程池ctfs thread pool;
[0109]
(6.10)自适应多目标用户网络跨域兴趣关联及推荐结束。
[0110]
和现有技术相比,本发明具有以下显著进步:
[0111]
本方法改变了传统协同过滤模型方法的局限性,结合改进的跨域场景下用户以及物品的属性特征信息识别技术,可有效获取一种准确度最高的目标用户对物品评分预测的结果集,使在跨域场景下通过引入主题标签的算法模型对目标对象物品评分的预测及推荐结果更加准确,增加了对目标用户跨域推荐的使用价值。
附图说明
[0112]
图1为基于主题标签的跨域推荐方法的总体流程图;
[0113]
图2为图1中的训练数据预处理流程图;
[0114]
图3为图1中的对标签集合进行相关性降噪处理流程图;
[0115]
图4为图1中的训练物品评分矩阵分解模型流程图。
[0116]
图5为图1中的训练改进后的基于主题分布预测模型的流程图。
[0117]
图6为图1中的训练跨域物品评分预测模型的流程图。
[0118]
图7为图1中的通过模型自适应识别接口进行用户跨域推荐的流程图。
具体实施方式
[0119]
下面结合附图和具体实施例,进一步阐明本发明的技术方案。
[0120]
如图1
‑
图7所示,本发明所述的一种基于主题标签的跨域推荐方法,包括如下步
骤:
[0121]
步骤1:输入带有主题标签信息的数据序列集,提取其中的用户集合u、物品集合v、物品标签集合t以及物品评分集合r;具体步骤如下:
[0122]
步骤1.1:输入带有主题标签信息的数据集s,定义函数len(s)表示集合s的长度,令s={s1,s2,s3,
…
,s
i
},其中,s
i
表示s中第i项数据,i∈[1,len(s)];
[0123]
步骤1.2:定义循环变量i1,用于遍历s,i1∈[1,len(s)],i1赋初值为1;
[0124]
步骤1.3:如果i1≤len(s)则进入步骤1.4,否则进入步骤1.10;
[0125]
步骤1.4:提取数据项s
i
中的用户u并入用户集合u中,u={u1,u2,u3,
…
,u
i
},其中,i表示提取到的用户的数目;
[0126]
步骤1.5:提取数据项s
i
中的物品v并入物品集合v中,v={v1,v2,v3,..,v
j
},其中,j表示提取到的物品的数目;
[0127]
步骤1.6:提取数据项s
i
中的标签t并入物品标签集合t中,t={t1,t2,t3,
…
,t
n
},其中,n表示提取到的物品标签的数目;
[0128]
步骤1.7:提取数据项s
i
中的评分r并入物品评分集合r中,r={r1,r2,r3,
…
,r
o
},其中,o表示提取到的物品评分的数目;
[0129]
步骤1.8:建立组合集uvtr,用户集合u中用户u通过一组标签集合t和评分集合r标记物品集合v中物品v,“用户
‑
物品
‑
标签
‑
评分”的四元组数据记为(u,v,t
ij
,r
ij
),其中,u∈u,v∈v,r
ij
∈r,t
ij
表示用户u
i
对物品v
j
所标记的标签集合,r
ij
表示系统中u
i
对v
j
的项目评分;
[0130]
步骤1.9:i1=i1 1,进入步骤1.3;
[0131]
步骤1.10:训练数据集的预处理流程结束。
[0132]
步骤2:减少低相关度标签所引入的噪声,对物品标签集合t中的低相关标签进行过滤,得到降噪后的标签集合ts;具体步骤如下:
[0133]
步骤2.1:输入物品标签集合t及组合集uvtr;
[0134]
步骤2.2:分析组合集uvtr中标签的出现频率和标签的流行度,通过保留标签及去除标签后系统评分样本的分布情况来评估物品标签与评分的关联评价,其中,关联评价采用wilcoxon秩和检验的方法;具体内容见步骤2.3~步骤2.12:
[0135]
步骤2.3:根据标签数据基于powerlaw分布的原理,分析标签流行度k与流行度为k的标签总的样本数量n(k)的数据信息;
[0136]
步骤2.4:定义循环变量i2用于遍历t,定义函数len(t)表示物品标签集合t的长度,i2∈[1,len(t)],i2赋初值为1,t
i2
为t中的第i2个物品标签;
[0137]
步骤2.5:如果i2≤len(t)则进入步骤2.6,否则进入步骤2.12;
[0138]
步骤2.6:使用秩和检验的方法,通过参数调优在置信区间ci中确定置信度xci为95%,通过置信度xci评估物品标签与评分的相关性数据值;
[0139]
步骤2.7:分析标签流行度的长尾分布;
[0140]
步骤2.8:分析出现标签频率并过滤剔除低于设定阈值的标签,定义低于设定阈值的标签为低相关度标签;
[0141]
步骤2.9:分析并优化处理低相关度标签的噪声;
[0142]
步骤2.10:评估保留标签及去除标签后评分样本的分布秩和检验的结果,对剔除
低相关标签后的结果集进行验证评估;
[0143]
步骤2.11:i2=i2 1,进入到步骤2.5;
[0144]
步骤2.12:得到降噪后的标签集合ts。
[0145]
步骤3:使用改进的物品标签协同过滤模型对ts进行自适应特征抽取,将提取到的物品标签信息的低维下的特征向量与预测模型进行融合,得到自适应物品评分矩阵分解模型ts_model;具体步骤如下:
[0146]
步骤3.1:输入标签集合ts以及组合集uvtr,定义函数len(ts)表示物品标签集合ts的长度,定义循环变量i3用于遍历ts,i3∈[1,len(ts)],i3赋初值为1;
[0147]
步骤3.2:如果i3≤len(ts),则进入步骤3.3,否则进入步骤3.17;
[0148]
步骤3.3:分析与物品i相关的标签全集,计算标签t于物品i上所关联的数目,得到关键物品标签信息;
[0149]
步骤3.4:将提取到关键物品标签信息的低维下的特征向量与预测模型进行融合,分析给定用户u和物品i的关联性并进行评分预测;
[0150]
步骤3.5:定义len(uvtr)为数据集uvtr的长度,定义循环变量j3用于遍历uvtr,j3∈[1,len(uvtr)],j3赋初值为1;
[0151]
步骤3.6:如果j3≤len(uvtr),则进入步骤3.7;
[0152]
步骤3.7:分析用户u、物品i以及标签t的潜在特征向量并提取;
[0153]
步骤3.8:分析并评估用户u和物品i的偏移量;
[0154]
步骤3.9:分析并使用随机梯度下降最小化误差;
[0155]
步骤3.10:遍历评分项中该物品的所有标签,更新标签域信息;
[0156]
步骤3.11:j3=j3 1,进入步骤3.6;
[0157]
步骤3.12:将标签信息的特征向量进行低维度下的映射;
[0158]
步骤3.13:将提取到关键物品标签信息的低维下的特征向量与预测模型进行融合;
[0159]
步骤3.14:分析给定用户u和物品i的关联性并进行评分预测;
[0160]
步骤3.15:获得遍历迭代后的参数,调优模型信息;
[0161]
步骤3.16:i3=i3 1,进入步骤3.2;
[0162]
步骤3.17:模型训练完毕,得到自适应物品评分矩阵分解模型ts_model。
[0163]
步骤4:对物品标签集合ts进行去冗,并进行标签主题的聚类,通过lda主题模型在聚类的同时扩充主题标签的语义,得到改进后的基于主题分布进行预测模型tfs_model;具体步骤如下:
[0164]
步骤4.1:输入物品标签集合ts;
[0165]
步骤4.2:将物品标签集合ts进行标签主题的聚类;
[0166]
步骤4.3:定义len(ts)为ts的长度,定义循环变量i4用于遍历ts,i4∈[1,len(ts)],i4赋初值为1;
[0167]
步骤4.4:遍历ts,如果i4≤len(ts),则跳转到步骤4.5,否则结束遍历ts,跳转到步骤4.19;
[0168]
步骤4.5:对物品标签集合ts中的元素进行去冗;
[0169]
步骤4.6:通过lda主题模型在聚类的同时扩充主题标签的语义;
[0170]
步骤4.7:定义用户状态flag,其中,flag为1时表示进入新的用户;
[0171]
步骤4.8:如果flag值为1,则跳转步骤4.9,否则跳转步骤4.17;
[0172]
步骤4.9:分析提取用户的兴趣偏向的行为特征;
[0173]
步骤4.10:如果进入新用户已被辅助域记载,则跳转步骤4.11,否则跳转步骤4.18;
[0174]
步骤4.11:通过模型提取每个用户的行为特征并进行用户兴趣模型参数的更新,完善用户模型;
[0175]
步骤4.12:计算用户特征向量在多个维度上的兴趣偏好值;
[0176]
步骤4.13:根据聚合特征及用户模型,更新用户信息;
[0177]
步骤4.14:如果flag值为1,则跳转步骤4.17,否则跳转步骤4.15;
[0178]
步骤4.15:创建新用户的行为分析模型;
[0179]
步骤4.16:如果用户兴趣特征已被记录,则跳转步骤4.18,否则跳转步骤4.19;
[0180]
步骤4.17:计算物品主题特征的权值与物品主题分布在主题区间上的概率;
[0181]
步骤4.18:采用随机梯度下降最小化正则均方误差对模型的参数进行迭代更新与模型自适应参数学习;
[0182]
步骤4.19:i4=i4 1,进入步骤4.4;
[0183]
步骤4.20:得到改进后的基于主题分布进行预测模型tfs_model。
[0184]
步骤5:引入跨域推荐目标域和辅助域的关联主题标签的依赖关系的映射,将目标用户的推荐场景拓展到多域,生成跨域物品评分预测及推荐的模型ctfs_model;
[0185]
步骤5.1:引入跨域推荐目标域和辅助域的关联主题标签,定义跨域主题标签集合cts,其中,cts={t1,t2,t3,
…
,t
ctn
},ctn表示所提取不同域中交叉重叠主题标签集合的数目;
[0186]
步骤5.2:进行目标域和辅助域的关联主题标签的依赖关系的映射,将目标用户的推荐场景拓展到多域,分析不同域间的用户以及物品的联系,利用辅助域的特征属性信息来解决了跨域中遇到的数据稀疏性和系统冷启动问题;
[0187]
步骤5.3:加载单域模型(即自适应物品评分矩阵分解模型ts_model),定义len(cts)为跨域主题标签集合cts的长度,定义循环变量i5用于遍历跨域主题标签集合cts,i5∈[1,len(cts)],i5赋初值为1;
[0188]
步骤5.4:如果i5≤len(cts)则进入步骤5.5,否则进入步骤5.12;
[0189]
步骤5.5:利用标签的影响权度进行跨域的引入;
[0190]
步骤5.6:通过辅助域来对目标域的评分与标签的关联程度进行学习;
[0191]
步骤5.7:利用关联标签语义信息的域间传递进行目标域的处理;
[0192]
步骤5.8:分析推荐域的用户以及物品的潜在特征向量;
[0193]
步骤5.9:分析推荐域标签的主题分布情况,获取主题的特征矩阵;
[0194]
步骤5.10:通过随机梯度下降的最小化正则误差进行模型的迭代更新与参数的自适应学习;
[0195]
步骤5.11:i5=i5 1,进入到步骤5.4;
[0196]
步骤5.12:将自适应物品评分矩阵分解模型ts_model拓展到多域的场景下进行跨域层面的用户网络的兴趣预测和跨域物品的推荐;
[0197]
步骤5.13:获得跨域物品评分预测及推荐模型ctfs_model。
[0198]
步骤6:加载跨域物品评分预测及推荐模型ctfs_model,将多目标跨域用户的特征行为基础属性集输入已训练的自适应推荐模型ctfs_model中,开放用户跨域推荐自适应识别接口ctfs api,自适应识别接口ctfs api对用户的行为参数进行基于用户网络挖掘的兴趣关联与发现,完善更新用户的兴趣特征模型的同时将结果信息返回给调用程序,用户可通过web平台获取跨域推荐结果;
[0199]
步骤6.1:开放跨域推荐自适应接口ctfs api;
[0200]
步骤6.2:创建线程池ctfs thread pool;
[0201]
步骤6.3:判断线程池ctfs thread pool所有任务是否执行完毕,如果所有任务执行完毕,则进入步骤6.9,否则进入步骤6.4;
[0202]
步骤6.4:接收来自终端的数据处理请求;
[0203]
步骤6.5:子线程ctfs child thread获取任务处理;
[0204]
步骤6.6:自适应识别接口ctfs api对用户的行为参数进行基于用户网络挖掘的兴趣关联与发现,完善更新用户的兴趣特征模型;
[0205]
步骤6.7:将结果信息返回给调用程序,用户可通过web平台获取跨域推荐结果;
[0206]
步骤6.8:结束该子进程ctfs child thread,进入步骤6.3;
[0207]
步骤6.9:关闭线程池ctfs thread pool;
[0208]
步骤6.10:自适应多目标用户网络跨域兴趣关联及推荐结束。
[0209]
为了更好的说明本方法的有效性,通过多个公共数据集及自建数据集中截取的20000条具有标签的评分下的多组对比实验结果显示,本模型在评价函数预测误差rmse下,相较于传统的svd模型平均降低了4.27%,获得了跨域场景下用户兴趣推荐及预测效果的提升。
[0210]
下表为上述步骤中所涉及的所有变量的详细说明。
[0211]
[0212]
[0213][0214]
本发明可与计算机系统结合,从而完成多目标用户兴趣的预测与推荐。
[0215]
本发明创造性的提出了一种基于主题标签的跨域推荐方法,经过多次实验,得到用户物品评分的最佳预测结果。
[0216]
本发明提出的一种基于主题标签的跨域推荐方法,可以用于如影视评分和书籍评分这一跨域场景下用户物品评分预测处理过程的评分标签序列中多目标社交领域中用户兴趣特征的跟踪与分类,也可以用于三个以及三个以上的多域异质数据的跟踪与分类。
[0217]
本发明实施例公开一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法实施例所提供的方法,例如包括:
[0218]
输入用户标签数据集并提取所需集合;过滤标签集合t中低相关标签得到ts;将标签信息进行低维下特征向量的融合得到ts_model;通过lda主题模型聚类ts得到tfs_model;引入多域标签的依赖关系映射,生成跨域模型ctfs_model;加载ctfs_model,开放接口ctfs api处理终端请求,得到跨域行为特征处理结果集存于web服务器并将相关推荐预测信息返回给调用终端。
[0219]
本发明实施例提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行上述各方法实施例所提供的方法,例如包括:
[0220]
输入用户标签数据集并提取所需集合;过滤标签集合t中低相关标签得到ts;将标签信息进行低维下特征向量的融合得到ts_model;通过lda主题模型聚类ts得到tfs_model;引入多域标签的依赖关系映射,生成跨域模型ctfs_model;加载ctfs_model,开放接口ctfs api处理终端请求,得到跨域行为特征处理结果集存于web服务器并将相关推荐预测信息返回给调用终端。
[0221]
此外,存储器中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read
‑
only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0222]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
[0223]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。