1.本发明涉及自然语言处理技术领域,具体涉及一种面向机械臂抓取的自然语言指令消歧方法及系统。
背景技术:
2.随着自然语言处理和人工智能技术的不断发展与突破,服务型机器人在人机交互中的表现更加自然。目前,由于国家对人工智能的大力扶持,智能服务型机器人的市场不断扩大,已有相关成熟的产品投入到了酒店、家庭、工厂等多种环境中。自然语言处理的语义消歧技术是指对于两个表达方式不同、语义相同的句子而言,能够实现两者之间语义的一致性判别。目前,对于复杂的、时序逻辑不同(语义相同)的自然语言指令而言,机器人难以正确理解其语义和实现语义的一致性判别。与此同时,自然语言指令控制机械臂已成为机器人操作研究领域的热点。机械臂已经能够根据简单的自然语言指令完成一些基本的操作任务,例如开关门、拿杯子等。然而由于自然语言指令表达的多样性,自然语言指令的消歧研究对于机械臂抓取至关重要。许多学者致力于去训练一个语义解析模型,将自然语言指令转化为一个可执行的逻辑程序,让机械臂再根据逻辑程序去实现抓取任务。
3.现有技术通过训练语义解析模型获得句子逻辑形式,其需要人工对不同的自然语言现象进行分类,并分别建立一个庞大的语料库,一一进行标注,进而通过神经网络模型进行训练,整个过程需要耗费大量的时间和人力。简单的自然语言指令通过训练好的语义解析模型会生成大量的逻辑程序,但其中包括许多虚假程序(部分能够实现自然语言指令的任务,但不能体现句子语义)。例如,当自然语言指令含有时序操作要求时,虚假程序虽然可能指导机械臂实现预期的任务效果,但是指导机械臂抓取的整个过程是错误的。因此,对于两句复杂的、时序逻辑不同(语义相同)并包含了不同自然语言现象的指令而言,训练一个获取句子逻辑形式的语义解析模型去实现句子之间的语义消歧是不可行的。即当前只能通过一些简单的自然语言指令指导机械臂完成基本的操作任务。对于复杂的、时序逻辑不同(语义相同)的自然语言指令而言,它们之间的语义消歧难以实现,进而不能正确指导机械臂实现相同的抓取任务。
技术实现要素:
4.本发明的目的是提供一种面向机械臂抓取的自然语言指令消歧方法及系统,实现自然语言指令之间语义的一致性判别,进一步指导机械臂完成抓取任务。
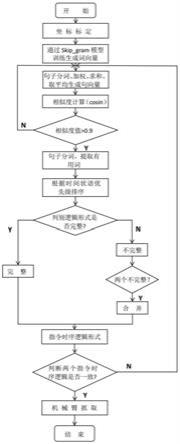
5.为了解决上述技术问题,本发明提供了一种面向机械臂抓取的自然语言指令消歧方法,包括以下步骤:
6.s1:标定物体抓取区域和释放区域的各点位置坐标;
7.s2:对语料库进行分词处理后,通过词预测模型训练生成词向量模型;
8.s3:对输入句子进行处理,基于词向量模型生成相应的句向量;
9.s4:通过损失函数计算两个句向量之间的相似度,初步判别两个句子之间语义的
一致性,若一致则进行下一步骤,否则返回步骤s2;
10.s5:对句子提取有用词,并根据时间状语优先级重新排序,获得规定的句子时序逻辑形式;
11.s6:根据得到的句子时序逻辑形式,判别句子之间语义的一致性,若一致则进行下一步骤,否则返回步骤s2;
12.s7:通过堆栈确定句子时序逻辑中的指定物体;
13.s8:结合方位词和位置坐标,机械臂对指定物体进行抓取和摆放。
14.作为本发明的进一步改进,所述步骤s1中位置坐标为机械臂末端的位姿。
15.作为本发明的进一步改进,所述步骤s2中,所述词预测模型采用skip_gram模型或cbow模型,词经过one
‑
hot编码进入神经网络训练得到词向量模型。
16.作为本发明的进一步改进,所述步骤s3具体包括以下步骤:
17.s31:通过分词模块对句子进行分词,并统计句子分词的个数,记为n;
18.s32:计算每个词的权重,词的权重计算公式:
[0019][0020]
其中,x
i
表示一个句子中词语i的个数,y
i
表示整个语料库中词语i的个数;
[0021]
s33:结合词向量模型和词的权重,计算句向量,句向量计算公式:
[0022][0023]
其中,sen_vec表示句向量,vec
i
表示词向量,weight
i
表示词的权重。
[0024]
作为本发明的进一步改进,所述步骤s4中的两个句向量之间的相似度计算,相似度计算公式:
[0025][0026]
其中,a
i
、b
i
分别是向量a和向量b的各分量,m表示向量的维度;
[0027]
设定阈值为0.9,若相似度值大于0.9,则进行步骤s5;若相似度值小于0.9,则进行步骤s2。
[0028]
作为本发明的进一步改进,所述步骤s5中具体包括以下步骤:
[0029]
s51:通过分词模块对句子进行分词,提取有用词,删除停用词,所述有用词包括时间状语、动词、名词和属性词;
[0030]
s52:根据时间状语优先级对时间状语进行排序,并将时间状语提到其所负责词的前面;
[0031]
s53:对提取到的每个时间状语所负责的词进行判别,判别依据为时间状语后的名词是否有两个:若只有一个名词,则时序逻辑不完整;若有两个名词,则时序逻辑完整;其中,若只有一个时间状语所负责的时序逻辑不完整,则将其舍去;若有两个时间状语所负责的时序逻辑不完整,则将两个进行组合成时序逻辑完整形式;
[0032]
s54:将动词提取到其对应的时序逻辑后面,删除时间状语,并对每个时序逻辑形式里的特定物体对调位置,获得规定的时序逻辑形式。
[0033]
作为本发明的进一步改进,所述步骤s6具体包括以下步骤:遍历步骤s5中得到的时序逻辑形式,若除动词外,时序逻辑形式指令一致,则语义相同,进行步骤s7;若除动词外,时序逻辑指令不一致,则语义不同,返回步骤s2。
[0034]
作为本发明的进一步改进,所述步骤s7具体包括以下步骤:将时序逻辑中的属性词压入到堆栈中,当物体存到堆栈中时则会弹出前面对应的参数词,并返回相应计算结果,循环往复,依次获取每个时序逻辑形式里的指定物体。
[0035]
作为本发明的进一步改进,所述步骤s8具体包括以下步骤:根据s1中标记的坐标位置,对方位词进行赋值,机械臂根据方位词和具体赋值对指定物体进行抓取和摆放,并依次记录每个物体对应的位置。
[0036]
一种面向机械臂抓取的自然语言指令消歧系统,包括:
[0037]
标定单元,标定物体抓取区域和释放区域的各点位置坐标;
[0038]
词向量模型,对语料库进行分词处理后,通过词预测模型训练生成词向量;
[0039]
句向量模型,对输入句子进行处理,基于词向量模型生成相应的句向量;
[0040]
相似度计算单元,通过损失函数计算两个句向量之间的相似度,初步判别两个句子之间语义的一致性,若一致则进行下一单元,否则返回词向量模型;
[0041]
时序逻辑形式获取单元,对句子提取有用词,并根据时间状语优先级重新排序,获得规定的句子时序逻辑形式;
[0042]
判别单元,根据得到的句子时序逻辑形式,判别句子之间语义的一致性,若一致则进行下一单元,否则返回词向量模型;
[0043]
获取物体单元,通过堆栈确定句子时序逻辑中的指定物体;
[0044]
操作单元,结合方位词和位置坐标,机械臂对指定物体进行抓取和摆放。
[0045]
本发明的有益效果:本发明将自然语言处理技术与机械臂相结合,提出句向量相似度计算模型和指令时序逻辑模型相结合的方法,用于判别自然语言指令之间语义的一致性,进而实现句子之间的语义消歧;同时,复杂的、带有时序逻辑的自然语言指令能够根据提出的方法获得句子简短的时序逻辑形式,从而进一步指导机械臂完成复杂的抓取任务。
附图说明
[0046]
图1是本发明方法流程示意图;
[0047]
图2是本发明时间状语优先级实例示意图;
[0048]
图3是本发明实施例一机械臂抓取前示意图;
[0049]
图4是本发明实施例一机械臂抓取后示意图。
具体实施方式
[0050]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0051]
实施例一
[0052]
参考图1,本发明实施例提供了一种面向机械臂抓取的自然语言指令消歧方法,包括以下步骤:
[0053]
s1:坐标标定,标定物体抓取区域和释放区域的各点位置坐标;
[0054]
s2:词向量模型,对语料库进行分词处理后,先采取skip
‑
gram模型和one_hot编码的方式,再通过神经网络训练得到词向量;
[0055]
s3:句向量模型,对句子进行处理,基于词向量模型生成句向量;
[0056]
s4:句子语义相似度计算,通过损失函数(cosin)计算两个句向量之间的相似度,设定阈值为0.9,初步判别两个句子之间语义的一致性;如果相似度值大于0.9,则进行步骤s5;如果相似度值小于0.9,则进行步骤s2;
[0057]
s5:获取句子时序逻辑形式。对带有时序逻辑的自然语言指令进行分词、删除停用词(介词、定冠词、冠词等),然后对时间状语、指示代词等进行处理,从而获得规定好的句子时序逻辑形式;
[0058]
s6:根据上述得到的句子时序逻辑形式,判别句子之间语义的一致性;
[0059]
s7:通过堆栈的方式确定时序逻辑中的特定物体;
[0060]
s8:结合方位词,机械臂对物体进行抓取和摆放,并依次记录每个物体对应的位置。
[0061]
具体的,步骤s1中的标定的位置坐标即为机械臂10末端的位姿。如图3所示,本实施例实验标定的释放区域为九宫格,并用数字1,2,......,8,9依次分别表示每一个释放点,采用的机械臂10是安装在leo移动机器人上的四轴台式机械臂;
[0062]
步骤s2中的skip_gram模型是指输入一个单词w,输出其上下文的单词w
o1
,w
o2
,...,w
oc
,其中c为上下文窗口的大小。skip_gram模型的主要参数包括:size、window、min_count和iter。其中size表示输出词向量的维度;window表示窗口的大小,即当前词与预测词在一个句子中的最大距离;min_count表示对字典做截断,即词频少于min_count次数的单词会被丢弃掉,默认值为5;iter表示迭代次数。词经过one_hot编码作为神经网络的输入,词向量作为神经网络的输出。skip_gram模型中的参数经过不断的调试,选取的最合理的一组参数为:size=400,window=5,min_count=5,iter=5。
[0063]
步骤s3中本次实验所用的句子是“先将蓝色方块放到红色方块的右边,再抓取粉色方块,然后把它放在红色方块的后边,最后将绿色方块放到粉色方块的左边”和“将粉色方块放在红色方块的后边之前,应该先把蓝色方块摆在红色方块的右边,接着抓取绿色放块,最后把它放到粉色方块的左边”,以第二个句子为例,具体处理步骤如下:
[0064]
s31:通过jieba模块对句子进行分词,并统计分词的个数,即为33;
[0065]
s32:句子中存在很多词对句子整体语义的理解作用不大,且出现的频率较高,例如停用词(介词、冠词、定冠词等)。因此,根据词频的方法,计算每个词的权重来降低停用词对整体语义的影响。以助词“的”为例,在句子中出现的次数是3,在整个与语料库中出现的次数为4642,则其权重的计算如公式(1)所示:
[0066][0067]
s33:结合词向量模型和词的权重,计算句向量。句向量计算如公式(2)所示:
[0068][0069]
其中,sen_vec表示维度是400的句向量,vec
i
表示维度是400的词向量,weight
i
表示词的权重,33表示句子的分词个数。
[0070]
步骤s4中的句子语义相似度计算是指对两个句向量进行计算,并且希望计算的结果能够很明显的看出句子之间语义的正相关性和负相关性程度,因此,采用余弦公式计算句向量之间的语义相似度。本实验上述两个句子的语义相似度计算结果,由公式(3)可得:
[0071][0072]
其中,400表示句子向量的维度,a
i
、b
i
分别表示向量a和向量b的各分量。由相似度计算结果可知,上述两个句子的相似度值大于0.9,因此初步判定两个句子的语义是相似的,进行步骤s5;
[0073]
步骤s5中的句子时序逻辑形式获取(以第二个句子为例),包括以下步骤:
[0074]
s51:通过jieba模块对句子进行分词,并提取出有用词(删除停用词),其中包括时间状语(之前、先、接着、最后)、动词(放、放到、摆在)、名词(方块)、属性词(红色、粉色、绿色、蓝色)、方向词(后边、左边、左边)。词的具体顺序如下:粉色
→
方块
→
放
→
红色
→
方块
→
后边
→
之前,先
→
蓝色
→
方块
→
摆在
→
红色
→
方块
→
右边,接着
→
绿色
→
方块,最后
→
放
→
粉色
→
方块
→
左边。
[0075]
s52:根据时间状语优先级对时间状语进行排序,并将时间状语提到其所负责词的前面,时间状语优先级如图2所示。词的具体顺序如下:先
→
蓝色
→
方块
→
摆在
→
红色
→
方块
→
右边,之前
→
粉色
→
方块
→
放
→
红色
→
方块
→
后边,接着
→
绿色
→
方块,最后
→
放
→
粉色
→
方块
→
左边;
[0076]
s53:由于指示代词不会被提取,导致有的时间状语负责的词并不是一个完整的时序逻辑形式。所以,如果要正确得到规定的时序逻辑形式,需要对提取到的每个时间状语所负责的词进行判别。判别依据是时间状语后的名词(物体)是否有两个:如果只有一个名词,则时序逻辑不完整;如果有两个名词,则时序逻辑完整。在上述情况下,如果只是单独的一个时间状语所负责的时序逻辑不完整,则将其舍去;如果是两个时间状语所负责的时序逻辑不完整,则将两个进行组合。由步骤s52可知,接着和最后两个时间状语的时序逻辑不完整,因此将它们进行组合。词的具体顺序如下:先
→
蓝色
→
方块
→
摆在
→
红色
→
方块
→
右边,之前
→
粉色
→
方块
→
放
→
红色
→
方块
→
后边,接着
→
绿色
→
方块
→
放
→
粉色
→
方块
→
左边;
[0077]
s54:将动词提取到对应的时序逻辑后面,删除时间状语,并对每个时序逻辑形式里的特定物体对调位置,以获得规定的时序逻辑形式。时序逻辑形式如下:红色
→
方块
→
蓝色
→
方块
→
右边
→
摆在,红色
→
方块
→
粉色
→
方块
→
后边
→
放,粉色
→
方块
→
绿色
→
方块
→
左边
→
放。
[0078]
步骤s6中句子语义一致性判别方式是指依次遍历两个自然语言指令的时序逻辑形式。经比较上述两个句子的时序逻辑形式一致,则进行步骤s7。
[0079]
步骤s7中堆栈的实际应用以第二个时序逻辑为例。将时序逻辑中的第一个属性词(红色)压入到堆栈中,当物体(方块)存到堆栈中时则会弹出其前面对应的参数,并返回计算结果(红色方块)。同上,第二个属性词(绿色)压入到堆栈中,当物体(方块)存到堆栈中时则会弹出其前面对应的参数,并返回计算结果(绿色方块)。依次获取每个时序逻辑形式里的特定物体。
[0080]
步骤s8中机械臂10抓取操作,方向词处理的计算值如表1所示:
[0081]
方向词计算值前 3后
‑
3左
‑
1右 1
[0082]
表1
[0083]
本实验机械臂10抓取和释放的具体步骤如下:
[0084]
a、对于第一个时序逻辑而言,机械臂10先抓取第一个物体(红色方块)放在5号位,再结合方向词“右边”抓取第二个物体进行放置,则第二个物体(蓝色方块)的位置为第一个物体(红色方块)的位置加1,释放点为6号位,并记录各物体对应的释放点位;
[0085]
b、对于第二个时序逻辑而言,机械臂10先判断第一个物体(红色方块)有没有被抓取,被抓取后则不进行操作,再结合方向词“后边”抓取第二个物体(粉色方块)进行放置,则第二个物体(粉色方块)的位置为第一个物体(红色方块)的位置减3,则释放点为2号位,并记录各物体对应的释放点位;
[0086]
c、对于第三个时序逻辑而言,机械臂10先判断第一个物体(粉色方块)有没有被抓取,被抓取后则不进行操作,再结合方向词“左边”抓取第二个物体(绿色方块)进行放置,则第二个物体(绿色方块)的位置为第一个物体(粉色方块)的位置减1,则释放点为1号位,并记录各物体对应的释放点位;依此类推。本实验的自然语言指令消歧实现机械臂10的抓取任务,最终实现如图4所示。
[0087]
实施例二
[0088]
为充分证明本发明的有效性,本实施例搜集了200句带有时序逻辑的自然语言指令进行验证,即100对时序逻辑不同(语义相同)的自然语言指令。将自然语言指令分为4组进行实验,将4组语言指令按本发明方法进行操作,其中实验指标包括三部分:句子语义相似度计算的正确率、句子时序逻辑获取的正确率、机械臂抓取任务的成功率。实验数据如表2所示:
[0089]
[0090]
表2
[0091]
由上表可知,句子语义相似度计算的正确率、句子时序逻辑获取的正确率、机械臂抓取任务的成功率均在90%以上,有效指导机械臂完成抓取任务。
[0092]
实施例三
[0093]
基于同一发明构思,本发明实施例提供了一种面向机械臂抓取的自然语言指令消歧系统,其解决问题的原理与所述一种面向机械臂抓取的自然语言指令消歧方法类似,重复之处不再赘述。
[0094]
一种面向机械臂抓取的自然语言指令消歧系统,包括:
[0095]
标定单元,标定物体抓取区域和释放区域的各点位置坐标;
[0096]
词向量模型,对语料库进行分词处理后,通过词预测模型训练生成词向量;
[0097]
句向量模型,对输入句子进行处理,基于词向量模型生成相应的句向量;
[0098]
相似度计算单元,通过损失函数计算两个句向量之间的相似度,初步判别两个句子之间语义的一致性,若一致则进行下一单元,否则返回词向量模型;
[0099]
时序逻辑形式获取单元,对句子提取有用词,并根据时间状语优先级重新排序,获得规定的句子时序逻辑形式;
[0100]
判别单元,根据得到的句子时序逻辑形式,判别句子之间语义的一致性,若一致则进行下一单元,否则返回词向量模型;
[0101]
获取物体单元,通过堆栈确定句子时序逻辑中的指定物体;
[0102]
操作单元,结合方位词和位置坐标,机械臂对指定物体进行抓取和摆放。
[0103]
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。