1.本发明涉及数据处理技术领域,尤其涉及一种数据处理方法及装置。
背景技术:
2.随着科学技术的发展,数据处理技术不断提高。
3.当前,企业可以通过采用线上服务模式,来向客户提供非接触式服务。比如,银行可以设立空中柜台,通过视频来远程为客户办理业务。
4.具体的,企业在进行线上服务过程中,可以通过识别客户的情绪变化,来掌握客户对服务的满意度和好感度,及时发现问题并给予必要的服务辅助,以为客户提供更优质服务。
5.但是,现有技术无法有效识别客户的情绪变化。
技术实现要素:
6.鉴于上述问题,本发明提供一种克服上述问题或者至少部分地解决上述问题的数据处理方法及装置,技术方案如下:
7.一种数据处理方法,包括:
8.采用深度摄像头对目标人脸进行拍摄,获得三维人脸数据;
9.对所述三维人脸数据进行预处理,获得处理后三维人脸数据;
10.基于至少一个人脸关键点,从所述处理后三维人脸数据中提取出至少一份局部三维人脸数据;
11.将所述处理后三维人脸数据和各所述局部三维人脸数据,输入至训练好的微表情识别模型;获得所述微表情识别模型输出的至少一种基本微表情类别的概率值;
12.基于各所述基本微表情类别的概率值,获得相应的情绪变化信息。
13.可选的,各所述人脸关键点中包括:左眼、右眼、嘴巴和鼻子;所述基于至少一个人脸关键点,从所述处理后三维人脸数据中提取出至少一份局部三维人脸数据,包括:
14.基于所述目标人脸中左眼、右眼、嘴巴和鼻子的中心点坐标,将所述目标人脸划分为相应的四个局部人脸区域;
15.分别按照四个所述局部人脸区域,从所述处理后三维人脸数据中,提取出相应的四份局部三维人脸数据。
16.可选的,所述基于各所述基本微表情类别的概率值,获得相应的情绪变化信息,包括:
17.将各所述基本微表情类别的概率值输入至面部动作编码系统,获得所述面部动作编码系统输出的情绪变化信息。
18.可选的,当所述微表情识别模型为多数据流注意力神经网络模型时,所述微表情识别模型中包括基础特征提取器、第一感知器、特征融合器和第二感知器,所述第一感知器为包含有sigmoid激活函数的一层感知器,所述第二感知器为多层感知器;在所述将所述处
理后三维人脸数据和各所述局部三维人脸数据,输入至训练好的微表情识别模型之后,所述方法还包括:
19.所述基础特征提取器分别对所述处理后三维人脸数据和各所述局部三维人脸数据执行特征提取操作,获得相应的各多维特征;其中,各所述多维特征的维数是相同的;
20.所述第一感知器对各所述多维特征进行权重映射,获得各所述多维特征的重要性权重;
21.所述特征融合器分别将各所述多维特征与相应的所述重要性权重进行相乘,获得相应的多个赋权后多维特征,对各所述赋权后多维特征进行融合处理,获得融合特征;
22.所述第二感知器基于所述融合特征,确定各所述基本微表情类别的概率值。
23.可选的,所述预处理包括:离群点去除、降采样、填孔插值、鼻尖点检测、人脸分割、平滑去噪和/或姿态矫正。
24.一种数据处理装置,包括:第一获得单元、第二获得单元、第一提取单元、第一输入单元、第三获得单元和第四获得单元;其中:
25.所述第一获得单元,用于采用深度摄像头对目标人脸进行拍摄,获得三维人脸数据;
26.所述第二获得单元,用于对所述三维人脸数据进行预处理,获得处理后三维人脸数据;
27.所述第一提取单元,用于基于至少一个人脸关键点,从所述处理后三维人脸数据中提取出至少一份局部三维人脸数据;
28.所述第一输入单元,用于将所述处理后三维人脸数据和各所述局部三维人脸数据,输入至训练好的微表情识别模型;
29.所述第三获得单元,用于获得所述微表情识别模型输出的至少一种基本微表情类别的概率值;
30.所述第四获得单元,用于基于各所述基本微表情类别的概率值,获得相应的情绪变化信息。
31.可选的,各所述人脸关键点中包括:左眼、右眼、嘴巴和鼻子;所述第一提取单元,包括:划分单元和第二提取单元;其中:
32.所述划分单元,用于基于所述目标人脸中左眼、右眼、嘴巴和鼻子的中心点坐标,将所述目标人脸划分为相应的四个局部人脸区域;
33.所述第二提取单元,用于分别按照四个所述局部人脸区域,从所述处理后三维人脸数据中,提取出相应的四份局部三维人脸数据。
34.可选的,所述第四获得单元,包括:第二输入单元和第五获得单元;其中:
35.所述第二输入单元,用于将各所述基本微表情类别的概率值输入至面部动作编码系统;
36.所述第五获得单元,用于获得所述面部动作编码系统输出的情绪变化信息。
37.可选的,当所述微表情识别模型为多数据流注意力神经网络模型时,所述微表情识别模型中包括基础特征提取器、第一感知器、特征融合器和第二感知器,所述第一感知器为包含有sigmoid激活函数的一层感知器,所述第二感知器为多层感知器;
38.在所述将所述处理后三维人脸数据和各所述局部三维人脸数据,输入至训练好的
微表情识别模型之后,所述基础特征提取器分别对所述处理后三维人脸数据和各所述局部三维人脸数据执行特征提取操作,获得相应的各多维特征;其中,各所述多维特征的维数是相同的;
39.所述第一感知器对各所述多维特征进行权重映射,获得各所述多维特征的重要性权重;
40.所述特征融合器分别将各所述多维特征与相应的所述重要性权重进行相乘,获得相应的多个赋权后多维特征,对各所述赋权后多维特征进行融合处理,获得融合特征;
41.所述第二感知器基于所述融合特征,确定各所述基本微表情类别的概率值。
42.可选的,所述预处理包括:离群点去除、降采样、填孔插值、鼻尖点检测、人脸分割、平滑去噪和/或姿态矫正。
43.本实施例提出的数据处理方法及装置,可以采用深度摄像头对目标人脸进行拍摄,获得三维人脸数据,对三维人脸数据进行预处理,获得处理后三维人脸数据,基于至少一个人脸关键点,从处理后三维人脸数据中提取出至少一份局部三维人脸数据,将处理后三维人脸数据和各局部三维人脸数据,输入至训练好的微表情识别模型;获得微表情识别模型输出的至少一种基本微表情类别的概率值,基于各基本微表情类别的概率值,获得相应的情绪变化信息。本发明可以结合微表情识别模型和目标人脸的三维人脸数据进行微表情识别,基于微表情识别模型输出的各基本微表情类别的概率值进行情绪变化信息的确定,从而有效实现对情绪变化的识别。
44.上述说明仅是本发明技术方案的概述,为了能够更清楚地了解本发明的技术手段,可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
45.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
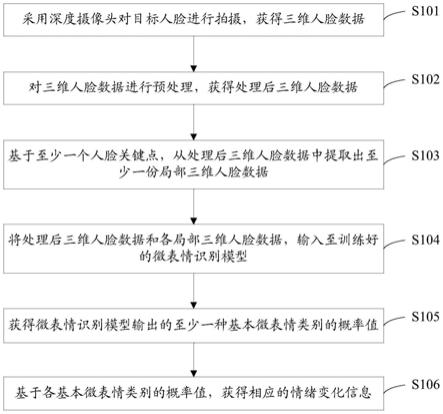
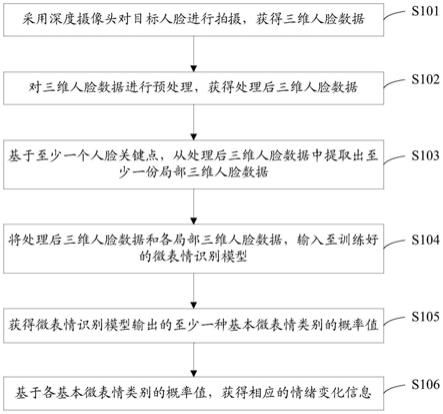
46.图1示出了本发明实施例提供的第一种数据处理方法的流程图;
47.图2示出了本发明实施例提供的第二种数据处理方法的流程图;
48.图3示出了本发明实施例提供的第一种数据处理装置的结构示意图。
具体实施方式
49.下面将参照附图更详细地描述本发明的示例性实施例。虽然附图中显示了本发明的示例性实施例,然而应当理解,可以以各种形式实现本发明而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本发明,并且能够将本发明的范围完整的传达给本领域的技术人员。
50.如图1所示,本实施例提出了第一种数据处理方法,该方法可以包括以下步骤:
51.s101、采用深度摄像头对目标人脸进行拍摄,获得三维人脸数据;
52.其中,目标人脸可以为某个人的人脸。可选的,目标人脸可以为正接受线上服务的
客户的人脸。
53.其中,三维人脸数据可以为目标人脸的三维坐标数据。
54.可选的,本发明可以在对客户进行线上服务的过程中,通过深度摄像头实时采集目标人脸的人脸图像和深度信息,构建目标人脸的三维模型,获得目标人脸的三维人脸数据。
55.可选的,三维人脸数据可以为目标人脸的点云数据。
56.s102、对三维人脸数据进行预处理,获得处理后三维人脸数据;
57.可选的,预处理包括:离群点去除、降采样、填孔插值、鼻尖点检测、人脸分割、平滑去噪和/或姿态矫正。
58.具体的,本发明可以对三维人脸数据进行包括离群点去除、降采样、填孔插值、鼻尖点检测、人脸分割、平滑去噪和姿态矫正在内的预处理过程,获得处理后三维人脸数据。
59.s103、基于至少一个人脸关键点,从处理后三维人脸数据中提取出至少一份局部三维人脸数据;
60.其中,人脸关键点可以为目标人脸上的耳朵、眉毛、眼睛、鼻子和嘴巴等人脸关键部位。
61.其中,局部三维人脸数据可以为目标人脸中局部区域的三维人脸数据。可以理解的是,处理后三维人脸数据可以是目标人脸中全局区域的三维人脸数据。
62.具体的,局部三维人脸数据可以是处理后三维人脸数据中与某个人脸关键点对应的部分三维人脸数据。
63.具体的,本发明可以基于至少一个人脸关键点,将目标人脸划分为相应个数的局部人脸区域,再从处理后三维人脸数据中提取出与各局部人脸区域相对应的局部三维人脸数据。
64.可选的,在本实施例提出的其它数据处理方法中,各人脸关键点中包括:左眼、右眼、嘴巴和鼻子;此时,步骤s103可以包括:
65.基于目标人脸中左眼、右眼、嘴巴和鼻子的中心点坐标,将目标人脸划分为相应的四个局部人脸区域;
66.分别按照四个局部人脸区域,从处理后三维人脸数据中,提取出相应的四份局部三维人脸数据。
67.具体的,本发明可以按照左眼、右眼、嘴巴和鼻子,将目标人脸分割成相应的四个局部人脸区域,之后从处理后三维人脸数据中提取出相应的四份局部三维人脸数据。
68.可选的,本发明在从处理后三维人脸数据中提取一份局部三维人脸数据的过程中,可以先行通过坐标点采样或者插值,在目标人脸的相应局部人脸区域中确定2048个坐标点,之后将确定的2048个坐标点的三维坐标数据确定为相应的一份局部三维人脸数据。此时,处理后三维人脸数据集可以为8192个坐标点的三维坐标数据。
69.s104、将处理后三维人脸数据和各局部三维人脸数据,输入至训练好的微表情识别模型;
70.可选的,微表情识别模型可以为训练好的多数据流注意力神经网络模型,也可以为其它类型的训练好的机器学习模型,本发明对此不做限定。需要说明的是,多数据流注意力神经网络模型的计算机视觉注意力机制可以具备人类视觉注意力机制的特征。可以理解
的是,人类视觉可以通过快速扫描全局图像,确定需要重点关注的目标局部区域,也就是一般所说的注意力焦点,而后对这一局部区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。本发明在采用多数据流注意力神经网络模型作为微表情识别模型时,微表情识别模型可以通过这种原理进行微表情识别,即可以聚焦于人脸特征的学习,同时去抑制与人脸无关的特征。此时,本发明可以先行对目标人脸进行分割,获得局部三维人脸数据,使用微表情识别模型学习每个局部三维人脸数据的权重,自适应的学习与微表情相关的特征表示,增强微表情识别模型的微表情识别能力。
71.可选的,当局部三维人脸数据中包括上述2048个坐标点的三维坐标数据,处理后三维人脸数据中包括上述8192个坐标点的三维坐标数据时,各局部三维人脸数据输入至微表情识别模型的输入维度均可以为2048
×
3,处理后三维人脸数据输入至微表情识别模型的输入维度可以为8192
×
3。
72.可选的,当所述微表情识别模型为多数据流注意力神经网络模型时,所述微表情识别模型中包括基础特征提取器、第一感知器、特征融合器和第二感知器,所述第一感知器为包含有sigmoid激活函数的一层感知器,所述第二感知器为多层感知器;在所述将所述处理后三维人脸数据和各所述局部三维人脸数据,输入至训练好的微表情识别模型之后,所述方法还包括:
73.所述基础特征提取器分别对所述处理后三维人脸数据和各所述局部三维人脸数据执行特征提取操作,获得相应的各多维特征;其中,各所述多维特征的维数是相同的;
74.所述第一感知器对各所述多维特征进行权重映射,获得各所述多维特征的重要性权重;
75.所述特征融合器分别将各所述多维特征与相应的所述重要性权重进行相乘,获得相应的多个赋权后多维特征,对各所述赋权后多维特征进行融合处理,获得融合特征;
76.所述第二感知器基于所述融合特征,确定各所述基本微表情类别的概率值。
77.其中,基础特征提取器可以为本发明采用在modelnet40数据集上训练获得的pointnet网络。当然,基础特征提取器也可以为其它类型的特征提取器,本发明对此不作限定。
78.具体的,基础特征提取器可以分别从输入的处理后三维人脸数据和各局部三维人脸数据中,提取出特征维数相同的多维特征。比如,当各局部三维人脸数据的输入维度均为2048
×
3,处理后三维人脸数据的输入维度为8192
×
3时,基础特征提取器可以分别从处理后三维人脸数据和各局部三维人脸数据中提取出1024维的特征。
79.具体的,第一感知器可以分别对基础特征提取器提出的各多维特征进行权重映射,分别获得各多维特征在区间[0,1]内的重要性权重。
[0080]
可选的,特征融合器可以为特征级联器;具体的,特征级联器可以在获得多个赋权后多维特征后,按照预定义次序对各赋权后多维特征进行级联,获得级联特征(即上述融合特征)。
[0081]
可选的,特征融合器可以为特征元素相加器;具体的,特征元素相加器可以在获得多个赋权后多维特征后,采用元素相加的方式获得融合特征。
[0082]
可选的,当基础特征提取器从处理后三维人脸数据和各局部三维人脸数据中提出的均为1024维的特征时,特征融合器获得的融合特征可以为1024
×
5维特征。
[0083]
其中,第二感知器的核数可以分别为分别为2048、512、128和7。
[0084]
s105、获得微表情识别模型输出的至少一种基本微表情类别的概率值;
[0085]
可选的,基本微表情类别可以为惊讶、厌恶、愤怒、恐惧、悲伤和喜悦等类别。
[0086]
需要说明的是,基本微表情类别可以由技术人员根据实际情况进行设置,本发明对此不做限定。
[0087]
s106、基于各基本微表情类别的概率值,获得相应的情绪变化信息。
[0088]
其中,情绪变化信息可以为体现情绪变化的信息。比如,情绪变化信息可以为“由喜悦转换为愤怒”的信息。
[0089]
具体的,本发明可以在获得各基本微表情类别的概率值之后,根据各概率值进行情绪变化解析,获得相应的情绪变化信息。
[0090]
可选的,本发明可以预先设置目标数据表,在目标数据表中预先定义各基本微表情类别的概率值与情绪变化信息的对应关系。此时,本发明可以在获得各基本微表情类别的概率值之后,从目标数据表中查找出相应的情绪变化信息。
[0091]
可选的,本发明也可以由人工进行情绪变化信息的解析。此时,本发明可以在获得各基本微表情类别的概率值之后,由技术人员基于各基本微表情类别的概率值,确定相应的情绪变化信息。
[0092]
需要说明的是,现有技术可以基于二维人脸数据进行微表情识别,但是会给了虚假照片、视频或人脸硅胶面套的可乘之机,安全性较低,且在光照和人脸姿态等因素的影响下,识别准确率不高,鲁棒性较差。而本发明可以获得目标人脸的三维人脸数据,即可以获得视野内空间得每个点位的三维坐标信息,并可以基于三维人脸数据进行微表情识别,从而提升分析判断的准确性,且相较于二维人脸数据的微表情识别技术,本发明有更强的描述能力,可以减小环境光变化对微表情识别的影响,在人脸姿态变化时,依然能保证较高的识别准确率。
[0093]
可选的,本发明在应用于银行线上服务场景时,可以识别客户在接受线上服务过程中的情绪变化,从而可以确定客户的真实意图,提升客户体验和服务能力,加强银行非接触式服务能力,提升金融服务智慧化水平。比如,本发明可以在银行为客户提供空中柜台服务的过程中,执行图1所示方法,获取客户在业务办理过程中的情绪变化,客观的了解客户对服务的满意度和好感度,及时发现问题并给予必要的服务辅助,全面提升空中柜台的服务质量。再比如,本发明可以在智慧无人银行以及产品营销场景中,执行图1所示方法来及时感知客户对金融产品的情绪变化,确定客户兴趣度,有针对性的向客户智能推荐其感兴趣的金融产品,实现智慧营销、千人千面的效果,提升整体营销水平。
[0094]
可选的,本发明在银行信贷线上面签场景中,在客户进行关键问题应答过程中执行图1所示方法,确定客户在进行关键问题应答过程中的情绪变化,基于清晰变化识别是否存在客户欺诈风险,提升风险防控能力。
[0095]
可选的,在银行应用场景中,本发明也可以在网银和手机银行等线上服务中执行图1所示方法,应用于更多的零接触服务应用场景。
[0096]
本实施例提出的数据处理方法,可以采用深度摄像头对目标人脸进行拍摄,获得三维人脸数据,对三维人脸数据进行预处理,获得处理后三维人脸数据,基于至少一个人脸关键点,从处理后三维人脸数据中提取出至少一份局部三维人脸数据,将处理后三维人脸
数据和各局部三维人脸数据,输入至训练好的微表情识别模型;获得微表情识别模型输出的至少一种基本微表情类别的概率值,基于各基本微表情类别的概率值,获得相应的情绪变化信息。本发明可以结合微表情识别模型和目标人脸的三维人脸数据进行微表情识别,基于微表情识别模型输出的各基本微表情类别的概率值进行情绪变化信息的确定,从而有效实现对情绪变化的识别。
[0097]
基于图1所示步骤,如图2所示,本实施例提出第二种数据处理方法。在该方法中,步骤s106可以包括以下步骤:
[0098]
s201、将各基本微表情类别的概率值输入至面部动作编码系统;
[0099]
需要说明的是,本发明可以通过面部动作编码系统来进行情绪变化的识别。
[0100]
具体的,本发明可以在获得各基本微表情类别的概率值之后,将各基本微表情类别的概率值输入至面部动作编码系统中,由面部动作编码系统基于各基本微表情类别的概率值进行情绪变化的识别。
[0101]
s202、获得面部动作编码系统输出的情绪变化信息。
[0102]
具体的,本发明可以在将各基本微表情类别的概率值输入至面部动作编码系统之后,获得面部动作编码系统输出的情绪变化信息。
[0103]
需要说明的是,现有技术可以进行基于全局特征的微表情识别,此时现有技术可以通过深度学习技术对目标人脸进行全局特征提取。但是,现有技术此时无法通过面部动作编码系统去解析客户细微的情绪变化。而本发明采用的多数据流注意力神经网络模型可以聚焦人脸的不同局部区域,此时本发明可以通过端到端神经网络的学习,解析出人脸不同局部区域的重要性,之后结合面部动作编码系统能够准确判断客户的情绪变化,可以有效增强对情绪变化的解析能力,深化情绪变化理解,提高情绪变化解析准确率。
[0104]
本实施例提出的数据处理方法,可以有效增强对情绪变化的解析能力,深化情绪变化理解,提高情绪变化解析准确率。
[0105]
与图1所示步骤相对应,如图3所示,本实施例提出第一种数据处理装置,该装置可以包括:第一获得单元101、第二获得单元102、第一提取单元103、第一输入单元104、第三获得单元105和第四获得单元106;其中:
[0106]
第一获得单元101,用于采用深度摄像头对目标人脸进行拍摄,获得三维人脸数据;
[0107]
其中,目标人脸可以为某个人的人脸。可选的,目标人脸可以为正接受线上服务的客户的人脸。
[0108]
其中,三维人脸数据可以为目标人脸的三维坐标数据。
[0109]
可选的,本发明可以在对客户进行线上服务的过程中,通过深度摄像头实时采集目标人脸的人脸图像和深度信息,构建目标人脸的三维模型,获得目标人脸的三维人脸数据。
[0110]
可选的,三维人脸数据可以为目标人脸的点云数据。
[0111]
第二获得单元102,用于对三维人脸数据进行预处理,获得处理后三维人脸数据;
[0112]
可选的,预处理包括:离群点去除、降采样、填孔插值、鼻尖点检测、人脸分割、平滑去噪和/或姿态矫正。
[0113]
具体的,本发明可以对三维人脸数据进行包括离群点去除、降采样、填孔插值、鼻
尖点检测、人脸分割、平滑去噪和姿态矫正在内的预处理过程,获得处理后三维人脸数据。
[0114]
第一提取单元103,用于基于至少一个人脸关键点,从处理后三维人脸数据中提取出至少一份局部三维人脸数据;
[0115]
其中,人脸关键点可以为目标人脸上的耳朵、眉毛、眼睛、鼻子和嘴巴等人脸关键部位。
[0116]
其中,局部三维人脸数据可以为目标人脸中局部区域的三维人脸数据。可以理解的是,处理后三维人脸数据可以是目标人脸中全局区域的三维人脸数据。
[0117]
具体的,局部三维人脸数据可以是处理后三维人脸数据中与某个人脸关键点对应的部分三维人脸数据。
[0118]
具体的,本发明可以基于至少一个人脸关键点,将目标人脸划分为相应个数的局部人脸区域,再从处理后三维人脸数据中提取出与各局部人脸区域相对应的局部三维人脸数据。
[0119]
可选的,在本实施例提出的其它数据处理装置中,各人脸关键点中包括:左眼、右眼、嘴巴和鼻子;第一提取单元103,包括:划分单元和第二提取单元;其中:
[0120]
划分单元,用于基于目标人脸中左眼、右眼、嘴巴和鼻子的中心点坐标,将目标人脸划分为相应的四个局部人脸区域;
[0121]
第二提取单元,用于分别按照四个局部人脸区域,从处理后三维人脸数据中,提取出相应的四份局部三维人脸数据。
[0122]
具体的,本发明可以按照左眼、右眼、嘴巴和鼻子,将目标人脸分割成相应的四个局部人脸区域,之后从处理后三维人脸数据中提取出相应的四份局部三维人脸数据。
[0123]
可选的,本发明在从处理后三维人脸数据中提取一份局部三维人脸数据的过程中,可以先行通过坐标点采样或者插值,在目标人脸的相应局部人脸区域中确定2048个坐标点,之后将确定的2048个坐标点的三维坐标数据确定为相应的一份局部三维人脸数据。此时,处理后三维人脸数据集可以为8192个坐标点的三维坐标数据。
[0124]
第一输入单元104,用于将处理后三维人脸数据和各局部三维人脸数据,输入至训练好的微表情识别模型;
[0125]
可选的,微表情识别模型可以为训练好的多数据流注意力神经网络模型,也可以为其它类型的训练好的机器学习模型,本发明对此不做限定。
[0126]
可选的,当局部三维人脸数据中包括上述2048个坐标点的三维坐标数据,处理后三维人脸数据中包括上述8192个坐标点的三维坐标数据时,各局部三维人脸数据输入至微表情识别模型的输入维度均可以为2048
×
3,处理后三维人脸数据输入至微表情识别模型的输入维度可以为8192
×
3。
[0127]
可选的,当微表情识别模型为多数据流注意力神经网络模型时,微表情识别模型中包括基础特征提取器、第一感知器、特征融合器和第二感知器,第一感知器为包含有sigmoid激活函数的一层感知器,第二感知器为多层感知器;
[0128]
在将处理后三维人脸数据和各局部三维人脸数据,输入至训练好的微表情识别模型之后,基础特征提取器分别对处理后三维人脸数据和各局部三维人脸数据执行特征提取操作,获得相应的各多维特征;其中,各多维特征的维数是相同的;
[0129]
第一感知器对各多维特征进行权重映射,获得各多维特征的重要性权重;
[0130]
特征融合器分别将各多维特征与相应的重要性权重进行相乘,获得相应的多个赋权后多维特征,对各赋权后多维特征进行融合处理,获得融合特征;
[0131]
第二感知器基于融合特征,确定各基本微表情类别的概率值。
[0132]
其中,基础特征提取器可以为本发明采用在modelnet40数据集上训练获得的pointnet网络。当然,基础特征提取器也可以为其它类型的特征提取器,本发明对此不作限定。
[0133]
具体的,基础特征提取器可以分别从输入的处理后三维人脸数据和各局部三维人脸数据中,提取出特征维数相同的多维特征。比如,当各局部三维人脸数据的输入维度均为2048
×
3,处理后三维人脸数据的输入维度为8192
×
3时,基础特征提取器可以分别从处理后三维人脸数据和各局部三维人脸数据中提取出1024维的特征。
[0134]
具体的,第一感知器可以分别对基础特征提取器提出的各多维特征进行权重映射,分别获得各多维特征在区间[0,1]内的重要性权重。
[0135]
可选的,特征融合器可以为特征级联器;具体的,特征级联器可以在获得多个赋权后多维特征后,按照预定义次序对各赋权后多维特征进行级联,获得级联特征(即上述融合特征)。
[0136]
可选的,特征融合器可以为特征元素相加器;具体的,特征元素相加器可以在获得多个赋权后多维特征后,采用元素相加的方式获得融合特征。
[0137]
可选的,当基础特征提取器从处理后三维人脸数据和各局部三维人脸数据中提出的均为1024维的特征时,特征融合器获得的融合特征可以为1024
×
5维特征。
[0138]
其中,第二感知器的核数可以分别为分别为2048、512、128和7。
[0139]
第三获得单元105,用于获得微表情识别模型输出的至少一种基本微表情类别的概率值;
[0140]
可选的,基本微表情类别可以为惊讶、厌恶、愤怒、恐惧、悲伤和喜悦等类别。
[0141]
需要说明的是,基本微表情类别可以由技术人员根据实际情况进行设置,本发明对此不做限定。
[0142]
第四获得单元106,用于基于各基本微表情类别的概率值,获得相应的情绪变化信息。
[0143]
其中,情绪变化信息可以为体现情绪变化的信息。比如,情绪变化信息可以为“由喜悦转换为愤怒”的信息。
[0144]
具体的,本发明可以在获得各基本微表情类别的概率值之后,根据各概率值进行情绪变化解析,获得相应的情绪变化信息。
[0145]
可选的,本发明可以预先设置目标数据表,在目标数据表中预先定义各基本微表情类别的概率值与情绪变化信息的对应关系。此时,本发明可以在获得各基本微表情类别的概率值之后,从目标数据表中查找出相应的情绪变化信息。
[0146]
可选的,本发明也可以由人工进行情绪变化信息的解析。此时,本发明可以在获得各基本微表情类别的概率值之后,由技术人员基于各基本微表情类别的概率值,确定相应的情绪变化信息。
[0147]
本实施例提出的数据处理装置,可以结合微表情识别模型和目标人脸的三维人脸数据进行微表情识别,基于微表情识别模型输出的各基本微表情类别的概率值进行情绪变
化信息的确定,从而有效实现对情绪变化的识别。
[0148]
基于图3,本实施例提出第二种数据处理装置。在该装置中,第四获得单元106,包括:第二输入单元和第五获得单元;其中:
[0149]
第二输入单元,用于将各基本微表情类别的概率值输入至面部动作编码系统;
[0150]
第五获得单元,用于获得面部动作编码系统输出的情绪变化信息。
[0151]
需要说明的是,本发明可以通过面部动作编码系统来进行情绪变化的识别。
[0152]
具体的,本发明可以在获得各基本微表情类别的概率值之后,将各基本微表情类别的概率值输入至面部动作编码系统中,由面部动作编码系统基于各基本微表情类别的概率值进行情绪变化的识别。
[0153]
具体的,本发明可以在将各基本微表情类别的概率值输入至面部动作编码系统之后,获得面部动作编码系统输出的情绪变化信息。
[0154]
需要说明的是,现有技术可以进行基于全局特征的微表情识别,此时现有技术可以通过深度学习技术对目标人脸进行全局特征提取。但是,现有技术此时无法通过面部动作编码系统去解析客户细微的情绪变化。而本发明采用的多数据流注意力神经网络模型可以聚焦人脸的不同局部区域,此时本发明可以通过端到端神经网络的学习,解析出人脸不同局部区域的重要性,之后结合面部动作编码系统能够准确判断客户的情绪变化,可以有效增强对情绪变化的解析能力,深化情绪变化理解,提高情绪变化解析准确率。
[0155]
本实施例提出的数据处理装置,可以有效增强对情绪变化的解析能力,深化情绪变化理解,提高情绪变化解析准确率。
[0156]
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括要素的过程、方法、商品或者设备中还存在另外的相同要素。
[0157]
以上仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。