技术特征:
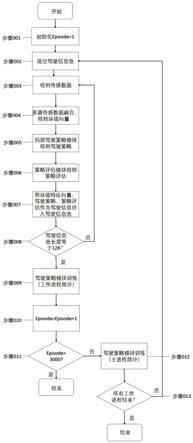
1.一种融合多源数据及综合多维指标的自动驾驶决策方法,其特征在于,包括以下步骤:步骤1、单目视觉信息处理,训练图像处理模块,将高维的图片信息处理为一维的特征向量,构建环境感知数据集,使用噪声增强驾驶策略在无人驾驶环境中采集图像数据,通过车载单目摄像头保存图像数据,使用噪声增强的驾驶策略把随机噪声引入到专家策略中并让专家策略能够收集到一些错误驾驶所对应的图像以利于驾驶策略的训练,专家策略是基于人类驾驶经验设计的一系列包含环境模型、驾驶员模型和汽车模型在内的复杂规则集合,在收集好图像信息之后,使用这些信息进行图像处理模块的自监督训练,图像处理模块使用自监督的方法把rgb图像使用一个编码器提取为一维特征向量并使用重参数技巧将一维的特征向量重构为rgb图像,通过编码器
‑
解码器结构对环境特征进行提取,提取对于驾驶策略有用的环境信息并为驾驶策略的训练提供输入环境信息;步骤2、多源传感数据融合,环境感知模块融合摄像头传感器、gnss传感器、imu传感器和速度传感器数据,共同构造环境感知信息;多源数据融合包含两部分,分别为经步骤1训练好的图像处理模块和直接接收传感器低维数据的偏移计算模块,图像处理模块用于接收rgb摄像头采集的图像,得到图像感知信息,偏移计算模块用于接收路径规划器产生的航点数据,imu传感器信息、gnss传感器信息和速度传感器信息,计算自车和航点之间的偏移距离和偏移角度,自车即为受本发明所述自动驾驶决策方法控制的车辆;步骤3、多维评价指标综合,设计一个策略评估模块,对自动驾驶当前的横向控制即车辆方向的控制和纵向控制即车辆速度的控制的好坏进行实时评估,用于以下步骤5的训练,也能用于其他驾驶策略的评估,策略评估模块包含自动驾驶系统横向控制的评估、纵向控制的评估和事件评估三个部分;步骤4、异步驾驶信息收集,使用分布式结构,在不同环境中在线收集驾驶信息并存储在驾驶信息池中,用于步骤5中的驾驶策略的训练;异步信息收集体现在每个工作进程含有独立的自动驾驶环境,各个进程间的驾驶信息收集互相独立,同时进行,通过分布式的框架,增加相同时间内产生的驾驶信息的个数与多样性以提高驾驶策略训练的效率;步骤5、驾驶策略模块训练,将环境感知模块固定,使用分布式在线深度强化学习训练方法控制自动驾驶系统与自动驾驶环境进行交互,训练得到一个鲁棒的驾驶策略,驾驶策略模块包括长短期记忆人工神经网络、策略网络和状态价值预估网络,长短期记忆人工网络用于从前后多帧对应的环境特征向量中提取时序特征,策略网络用于输出驾驶策略即转向值、油门值、刹车值,其中转向值的范围是[
‑
90,90],
‑
90代表向左转90
°
,90代表向右转90
°
,油门值的范围是[0,1],0代表不踩油门,1代表油门全部踩下,刹车值的范围是[0,1],0代表不踩刹车,1代表刹车全部踩下,状态价值预估网络是对当前自动驾驶状态的好坏进行预估,驾驶策略模块根据策略评估模块给出的评估值并更新驾驶策略模块中的长短期记忆人工神经网络、策略网络和状态价值预估网络。2.根据权利要求1所述的一种融合多源数据及综合多维指标的自动驾驶决策方法,其特征在于,所述步骤2包括以下步骤:步骤201、从gnss传感器得到当前自车位置(x0,y0),从路径规划器和自车位置得到距离当前自车位置最近的航点(x
w
,y
w
),从imu传感器得到当前车辆的偏航角α;步骤202、将全局坐标系转换为相对坐标系,以当前自车位置为原点,根据下面的公式
(1)计算航点相对位置(x
′
w
,y
w
):步骤203、根据下列公式(2)计算车辆方向向量(x1,y1):步骤204、根据下列公式(3)计算车辆偏移角度θ:步骤205、根据车辆位置和航点位置,计算车辆偏移距离d,如以下公式(4)所示:步骤206、综合上述结果,偏移计算模块得到度量向量(θ,d,v);步骤207、将图像处理模块得到的特征向量和上述步骤得到的度量向量结合,环境感知模块得到t时刻的环境特征向量环境z
t
。3.根据权利要求1所述的一种融合多源数据及综合多维指标的自动驾驶决策方法,其特征在于,所述步骤3包括以下步骤:步骤301、自动驾驶系统横向控制的评估对于自动驾驶车辆的方向控制进行评估,使沿车道行驶的驾驶策略得到高的评估并使远离车道行驶的驾驶策略得到低的评估,横向评估分为对于自动驾驶车辆偏移角度的评估和对于偏移距离的评估,输入是偏移距离、道路宽度、偏移角度和最大偏移角度,输出是横向评估值;步骤302、自动驾驶系统纵向控制的评估对于自动驾驶车辆的速度控制进行评估,使能够沿目标速度稳定的驾驶策略得到高的评估,使错误的速度控制驾驶策略得到低的评估,具体分为前方有障碍物时车辆速度的评估和前方无障碍物时车辆速度的评估,纵向控制评估的输入是通过车载速度传感器得到的车辆速度、预设的最大速度、距离前方障碍物的距离,输出是纵向评估值;步骤303、自动驾驶系统的事件评估,步骤301和步骤302中的评估是一个密集的评估方法,对每一时刻的车辆驾驶策略进行评估,得到一个评估值,事件评估是通过某些特定的事件触发才有评估值,其他情况下评估值为0,将事件分为5个危险事件和1个成功事件,5个危险事件包含:碰撞动态物体、碰撞静态物体、车辆阻塞、偏离路线、超速,1个成功事件为在规定时间内无碰撞驶完既定路线;将纵向评估值记为r
ig
,横向控制评估值记为r
la
,事件评估值记为r
et
,策略评估模块的输出如以下公式(5)所示:r=r
lg
r
la
r
et
......(5),是自动驾驶系统纵向评估、横向评估、事件评估的线性和;策略评估模块不仅能够对城市道路中的驾驶策略进行全面的评估,还能够指导以下步骤5中的驾驶策略的训练。4.根据权利要求1所述的一种融合多源数据及综合多维指标的自动驾驶决策方法,其特征在于,所述步骤5包括以下步骤:步骤501、初始化工作进程,初始化路线池,路线池中含有l条路线,每个路线包括路线
的起始航点和路线的完成度,路线的完成度的范围从0%到100%,初始化局部驾驶策略模块中的模型参数,清空驾驶信息池;步骤502、根据ε
‑
greedy的方法选择当前的路线,从[0,1]的均匀分布中随机采集一个概率值p,基于贪心的策略选择一条路线用于训练如以下公式(6)所示:ε=0.2;步骤503、构建交通场景,在城镇中随机生成100辆专家策略控制的自动驾驶汽车且沿着道路正常行驶并且遵守交通规则,在路边随机生成150个行人,行人在遵守交通规则的情况下随意走动,初始化自车的位置为路线的起点;步骤504、在时刻t,自车通过传感器收集传感数据,放入环境感知模块中,得到环境特征向量z
t
,把环境特征z
t
放入历史特征存储器中,在历史特征存储器中得到环境特征向量序列如以下公式(7)所示:z
t:t
‑7=[z
t
,z
t
‑1,z
t
‑2,z
t
‑3,z
t
‑4,z
t
‑5,z
t
‑6,z
t
‑7]
……
(7),步骤505、将特征序列z
t:t
‑7放入长短期记忆人工神经网络,得到时序特征步骤506、将时序特征放入策略网络中,得到驾驶策略的分布π
t
,根据分布采样得到转向值油门值刹车值步骤507、自车执行驾驶策略自动驾驶环境更新;步骤508、根据当前自车的状态,使用策略评估模块计算策略评估值r
t
,当发生步骤303中任意一个事件,则m
t
=0,否则m
t
=1,将(z
t
,a
t
,r
t
,π
t
(a
t
),m
t
)作为一个驾驶信息样本存入驾驶信息池当的长度等于128,进入步骤509,更新驾驶策略模块;步骤509、得到小批量样本集合z,a,r,m,π,z
i
∈z,a
i
∈a,r
i
∈r,v
i
∈v,π
i
∈π,m
i
∈m;步骤510、对第i个样本,根据以下公式(8)计算策略评估的折扣累积和:其中,代表长短时记忆神经网络的输出,v代表状态价值预估网络的输出,根据如下公式(9)计算状态价值预估网络的损失l
v
:其中,步骤511、根据如下公式(10)计算策略网络损失l
π
:其中,δ
i
为更新前后的策略差距,定义为π
i
为更新后的当前策略网络的输出,为更新前策略网络的输出,a
i
称为优势函数,a
i
=g
i
‑
v
i
,优势函数描述了当前驾驶策略的相对好坏,a
i
>0代表当前驾驶策略下选取的动作好,a
i
<0代表当前驾驶策略下
采取的动作差;步骤512、根据步骤510和步骤511,得到当前驾驶策略模块的总损失步骤513、根据使用反向梯度传播计算神经网络的梯度;步骤514、把梯度存入模型更新梯度池。
技术总结
本发明公开了一种融合多源数据及综合多维指标的自动驾驶决策方法,包括以下步骤:步骤1、单目视觉信息处理,步骤2、多源传感数据融合,步骤3、多维评价指标综合,步骤4、异步驾驶信息收集,步骤5、驾驶策略模块训练;本发明的有益效果是能够通过自动化收集训练数据集,使用预先定义好的策略评估模块指导训练,无需提前采集专家策略的驾驶信息,降低了训练的成本,提高了驾驶策略的鲁棒性。提高了驾驶策略的鲁棒性。提高了驾驶策略的鲁棒性。
技术研发人员:赵一诺 刘驰
受保护的技术使用者:北京理工大学
技术研发日:2021.08.04
技术公布日:2021/12/3
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。