技术特征:
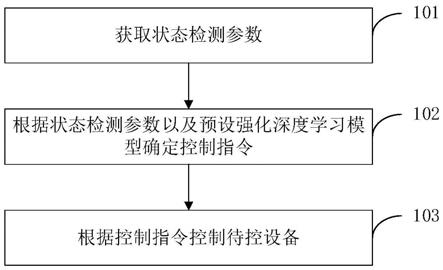
1.一种控制方法,其特征在于,包括:获取状态检测参数,所述状态检测参数用于表征待控设备的物理状态;根据所述状态检测参数以及预设强化深度学习模型确定控制指令,所述控制指令用于控制所述待控设备,其中,所述预设强化深度学习模型根据第一数据样本集以及第二数据样本集训练得到,所述第一数据样本集为所述状态检测参数对应的实际测量值所构成的样本集,所述第二数据样本集为根据预设仿真模型所确定的仿真模拟值所构成的样本集。2.根据权利要求1所述的控制方法,其特征在于,还包括:获取所述第一数据样本集;根据所述第一数据样本集以及所述预设仿真模型确定所述第二数据样本集;根据所述第一数据样本集以及所述第二数据样本集确定混合样本池,所述混合样本池用于训练所述预设强化深度学习模型。3.根据权利要求2所述的控制方法,其特征在于,所述根据所述第一数据样本集以及所述预设仿真模型确定所述第二数据样本集,包括:根据所述第一数据样本集以及所述预设仿真模型确定待选数据样本集;从所述待选数据样本集中筛选符合预设联合分布限制条件的样本,以确定所述第二数据样本集。4.根据权利要求3所述的控制方法,其特征在于,所述根据所述第一数据样本集以及所述预设仿真模型确定待选数据样本集,包括:根据所述第一数据样本集以及预设联合条件概率分布模型确定所述待选数据样本集,其中,所述联合条件概率分布模型为深度神经网络模型;对应的,所述从所述待选数据样本集中筛选符合预设联合分布限制条件的样本,包括:从所述待选数据样本集中筛选出联合条件概率大于预设概率阈值的样本。5.根据权利要求3所述的控制方法,其特征在于,所述根据所述第一数据样本集以及所述预设仿真模型确定待选数据样本集,包括:根据所述第一数据样本集以及预设对抗网络确定所述待选数据样本集;对应的,所述从所述待选数据样本集中筛选符合预设联合分布限制条件的样本,包括:从所述待选数据样本集中筛选出判别值大于预设判别阈值的样本,所述判别值根据判别网络进行确定。6.根据权利要求2-5中任意一项所述的控制方法,其特征在于,在所述根据所述第一数据样本集以及所述第二数据样本集确定混合样本池之后,还包括:利用所述第一数据样本集对预设基准策略模型进行训练;确定训练后的基准策略模型与预设学习策略模型之间的策略分布差异;利用所述混合样本池训练所述预设学习策略模型、预设奖励价值模型以及预设安全价值模型,其中,所述策略分布差异作为所述预设学习策略模型、所述预设奖励价值模型以及所述预设安全价值模型的正则化项;当训练步数符合预设条件时,将训练后的学习策略模型作为所述预设强化深度学习模型。7.根据权利要求6所述的控制方法,其特征在于,所述确定训练后的基准策略模型与预设学习策略模型之间的策略分布差异,包括:
根据预设最大均值差异算法确定所述训练后的基准策略模型与所述预设学习策略模型之间的所述策略分布差异;或者,根据预设散度算法确定所述训练后的基准策略模型与所述预设学习策略模型之间的所述策略分布差异。8.根据权利要求6所述的控制方法,其特征在于,所述预设基准策略模型选用变分编码器。9.根据权利要求6所述的控制方法,其特征在于,在所述预设学习策略模型、预设奖励价值模型以及预设安全价值模型的训练过程中,使用预设二次项约束形式确定训练目标。10.根据权利要求2-5中任意一项所述的控制方法,其特征在于,所述预设仿真模型为深度神经网络模型、循环神经网络模型以及卷积神经网络模型中的任意一种或者多种的组合。11.一种控制装置,其特征在于,包括:参数获取模块,用于获取状态检测参数,所述状态检测参数用于表征待控设备的物理状态;控制处理模块,用于根据所述状态检测参数以及预设强化深度学习模型确定控制指令,所述控制指令用于控制所述待控设备,其中,所述预设强化深度学习模型根据第一数据样本集以及第二数据样本集训练得到,所述第一数据样本集为所述状态检测参数对应的实际测量值所构成的样本集,所述第二数据样本集为根据预设仿真模型所确定的仿真模拟值所构成的样本集。12.一种电子设备,其特征在于,包括:处理器;以及存储器,用于存储所述处理器的计算机程序;其中,所述处理器被配置为通过执行所述计算机程序来实现权利要求1至10任一项所述的控制方法。13.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至10任一项所述的控制方法。
技术总结
本申请提供一种控制方法、装置、存储介质及电子设备。本申请实施例提供的控制方法,通过获取用于表征待控设备物理状态的状态检测参数,并将状态检测参数输入至预设强化深度学习模型中,以确定与状态检测参数相对应的控制指令,其中,该预设强化深度学习模型是通过实际测量值所构成的第一数据样本集以及根据预设仿真模型与第一数据样本集所确定的仿真模拟值所构成的第二数据样本集进行训练得到的,从而使得基于真实数据以及模拟数据相结合所得到的强化深度学习模型所确定的学习策略的分布更接近真实策略分布,提高基于该深度强化学习模型所确定的控制指令与实际情况的匹配度。度。度。
技术研发人员:张玥 詹仙园 朱翔宇 霍雨森 殷宏磊 郑宇
受保护的技术使用者:京东城市(北京)数字科技有限公司
技术研发日:2020.05.29
技术公布日:2021/12/3
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。