一种基于特征变换的三维cbct牙齿图像的分割方法
技术领域
1.本发明属于口腔临床医学和计算机视觉技术领域,具体涉及一种基于特征变换的三维cbct牙齿图像的分割方法。
背景技术:
2.在口腔医学领域,人们结合计算机图形学、数字媒体和图形图像处理等技术研发的虚拟正畸系统正在辅助牙科医生进行诊治。cbct图像具有成像清晰,分辨率高,辐射剂量低的特点。对三维cbct进行牙齿分割后生成的三维牙齿模型可以用来分析相邻牙齿的关系,指导牙齿种植;也可以进行机械操作,如测量牙根和冠的比例进行正畸治疗。三维牙齿模型对方案选择和种植治疗有重要的指导意义和参考价值。
3.然而在cbct图像中通过手动分割牙齿边缘会耗费大量的时间、精力,并且肉眼识别cbct图像牙齿边界会产生由图像伪影等干扰因素导致的主观性误差。在这种情况下,通过计算机技术实现的牙齿自动分割可以有效地克服人为勾画的主观性误差、减少医生的工作量,对牙齿疾病的诊断和治疗具有重要意义。
4.目前,已有很多方法被提出以实现对cbct口腔影像中牙齿的分割,但这些方法还未能较好的解决以下问题:1)cbct牙根根尖形态差异大,依靠局部特征分割十分困难,容易出现错分漏分;2)不同牙齿类别可能出现同类差异大、类间差异小的情况,容易产生类间混淆。这些问题导致牙齿分割结果和实际图像牙齿边界的精标准相差甚远,因此急需一种新的方法对三维cbct牙齿图像进行更为精确的分割。
技术实现要素:
5.为解决以上现有技术存在的问题,本发明提出了一种基于特征变换的三维 cbct牙齿图像的分割方法,该方法包括:实时获取cbct图像数据,并对该数据进行预处理;将预处理后的cbct图像数据输入到训练好的cbct图像牙齿分割模型中进行分割处理;对分割结果进行评估分析;cbct图像牙齿分割模型为改进的3d卷积神经网络,改进的3d卷积神经网络包括编码器、空间变换模块stm、类别变换模块ctm、特征融合模块、解码器以及输出层;所述空间变换模块stm和所述类别变换模块ctm均与编码器的末端连接,空间变换模块stm和类别变换模块ctm的输出端均与特征融合模块连接,特征融合模块的输出端以及编码器的输出端均与解码器连接,解码器的输出端与输出层连接,构成改进的3d卷积神经网络。
6.优选的,对cbct图像进行预处理的过程包括:对获取的cbct图像进行清洗,删除无用的图像;对清洗后的图像进行去噪增强处理;对增强后的图像进裁剪,得到颌骨图像。
7.优选的,编码器和解码器共包括12个卷积模块、3个下采样模块、3个上采样模块以及3条跳跃路径;每个卷积模块包括一个3
×
3卷积层和一个归一化层,并采用relu激活函数;空间变换模块stm和类别变换模块ctm为并行结构,均包括12个变换层,每个变换层由多头自注意力模块和多层感知机组成;特征融合模块为一次concat操作的模块;输出层为通道数等于类别数的卷积模块。
8.优选的,对cbct图像牙齿分割模型进行训练的过程包括:
9.s1:获取原始cbct图像数据,对原始图像数据进行预处理,得到训练集和测试集;
10.s2:将训练集中的数据输入到cbct图像牙齿分割模型中进行训练;
11.s3:将cbct图像数据输入到cbct图像牙齿分割模型的编码器中进行特征提取,在每次下采样前保存该分辨率的特征图,得到多个具有不同分辨率的特征图;将除最高分辨率的特征图外的其他特征图作为跳跃路径,并与解码器对应分辨率的特征图进行融合;
12.s4:将最高分辨率的特征图分别输入到stm和ctm中,得到空间变换特征图和类别变换特征图;
13.s5:将空间变换特征图和类别变换特征图输入到特征融合模块中进行融合处理,得到融合特征图;
14.s6:将其他分辨率特征图和融合特征图输入到解码器中,得到还原后的全尺寸特征图;
15.s7:将全尺寸特征图输入到输出层中,并采用softmax函数对输出图像进行处理,得到分割结果;
16.s8:根据分割结果计算模型的损失函数,通过梯度反向传播,不断更新模型的参数,当损失函数收敛到最小值时完成模型的训练,得到训练好的cbct 图像牙齿分割模型。
17.进一步的,采用空间变换模块stm对高分辨率特征图进行处理的过程包括:采用空间变换模块stm将特征图分为p3个相同尺寸的图块patch,其中,p表示将图像在每个维度分为p等分;对每个图块进行reshape操作,使得每个图块拉伸为一维向量,将该一维向量作为空间嵌入向量组spatial embedding;将空间嵌入向量组依次输入到由多头自注意力模块和多层感知机组成的transformer结构中,得到全局特征;对该特征进行reshape操作,使其还原回与输入特征图相同尺寸的空间变换特征图。
18.进一步的,采用类别变换模块ctm对高分辨率特征图进行处理的过程包括:将输入的特征图分别输入到两个卷积层中,并进行reshape操作,得到一个表示单个体素节点类别概率的特征图x
cate
和一个表示每个体素潜在特征的特征图 x
hidden
;将x
cate
转置后与x
hidden
进行矩阵乘法,得到表示每个类别节点具有全部体素特征的特征矩阵x
g
,将x
g
按类别分为n个通道数为1的特征矩阵将特征矩阵作为一个类别嵌入向量组;将类别嵌入向量依次输入到由多头自注意力模块和多层感知机组成的transformer结构,得到类别变换特征;对类别变换特征进行reshape操作,使其维度变为m
×
n的还原特征;将x
hidden
与还原特征做矩阵乘法,得到维度为hwd
×
n的特征矩阵,将维度为hwd
×
n的特征矩阵进行reshape操作,使该矩阵的维度变为n
×
h
×
w
×
d,再将维度变为n
×
h
×ꢀ
w
×
d维矩阵输入到一个通道数与输入特征图相同的卷积层中,得到与输入特征图相同尺寸的类别变换特征图。
19.进一步的,对空间变换特征图和类别变换特征图进行融合的过程包括:采用concat函数对两个特征图进行拼接操作,得到融合特征图。
20.进一步的,分类结果的表达式为:
[0021][0022]
进一步的,模型的损失函数包括交叉熵损失和多类soft
‑
dice损失;对交叉熵损失
与多类soft
‑
dice损失求和,得到模型损失函数。
[0023]
进一步的,交叉熵损失函数表达式为:
[0024][0025]
其中,n表示图像体素的总数,n表示类别数,和分别表示第i个体素预测和ground truth的类别;
[0026]
多类soft
‑
dice损失函数表达式为:
[0027][0028]
最终损失函数为:
[0029]
l=l
ce
αl
msd
[0030]
其中,α是人工设定的超参数。
[0031]
本发明采用一种结合了空间特征变换和类别特征变换模块的3d卷积神经网络模型,stm和ctm分别结合了空间全局信息和类别全局信息,有效的在空间信息中建立长程关系,并有效的考虑了不同类别特征之间的相似关系,将由卷积神经网络提取的局部特征更加有效的利用起来,解决了根尖分割效果差和类间混淆的问题。
附图说明
[0032]
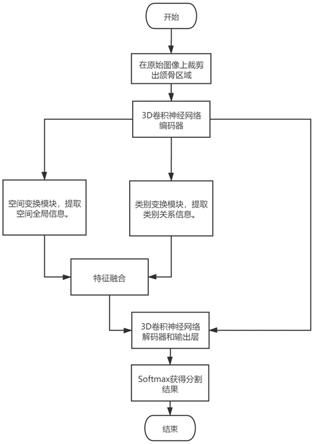
图1为本发明的整体流程图;
[0033]
图2为本发明的cbct图像牙齿分割模型中的3d卷积神经网络框架结构图;
[0034]
图3为本发明的空间变换模块stm和类别变换模块ctm结构图;
[0035]
图4为本发明的空间变换模块stm和类别变换模块ctm对高分辨率特征图进行处理的过程图。
具体实施方式
[0036]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0037]
一种基于特征变换的三维cbct牙齿图像的分割方法,该方法包括:对 cbct图像数据进行预处理;将预处理后的cbct图像输入到训练好的cbct 图像牙齿分割模型中进行分割处理;对分割结果进行评估分析;所述cbct图像牙齿分割包括具有编解码结构的3d卷积神经网络、空间变换模块(stm),类别变换模块(ctm)和特征融合模块。空间变换模块,类别变换模块设置在3d卷积神经网络的编码器末端。
[0038]
一种基于特征变换的三维cbct牙齿图像的分割方法的具体实施方式,该方法包括实时获取cbct图像数据,并对该数据进行预处理;将预处理后的 cbct图像数据输入到训练好的cbct图像牙齿分割模型中进行分割处理;对分割结果进行评估分析;cbct图像牙齿分
割模型为改进的3d卷积神经网络,改进的3d卷积神经网络包括编码器、空间变换模块stm、类别变换模块ctm、特征融合模块、解码器以及输出层;所述空间变换模块stm和所述类别变换模块ctm均与编码器的末端连接,空间变换模块stm和类别变换模块ctm的输出端均与特征融合模块连接,特征融合模块的输出端以及编码器的输出端均与解码器连接,解码器的输出端与输出层连接,构成改进的3d卷积神经网络。
[0039]
可选的,对cbct图像进行预处理的过程包括:对获取的cbct图像进行清洗,删除无用的图像;对清洗后的图像进行去噪增强处理;对增强后的图像进裁剪,得到颌骨图像。
[0040]
如图2所示,cbct图像牙齿分割模型中的3d卷积神经网络为3d u
‑
net 卷积神经网络,该网络由编码器、stm、ctm、解码器和输出层组成;其中, 3d u
‑
net包括编解码结构,共12个卷积模块(3
×
3卷积、bn(batch normalize) 和relu激活函数)、3个下采样模块、3个上采样模块、1个输出层(1
×
1卷积) 以及三条跳跃路径(即一次拼接操作);如图3所示,stm和ctm为并行结构,主要包括12个变换层(transformer layer),每个变换层主要由多头自注意力模块和多层感知机组成;最后通过特征融合模块对空间变换特征和类别变换特征进行融合,然后输入解码器,得到最终分割结果。
[0041]
如图1所示,对cbct图像牙齿分割模型进行训练的过程包括:
[0042]
s1:获取原始cbct图像数据,对原始图像数据进行预处理,得到训练集和测试集;度原始图像数据进行预处的过程包括对cbct图像进行预处理的过程包括:对获取的cbct图像进行清洗,删除无用的图像;对清洗后的图像进行去噪增强处理;对增强后的图像进裁剪,得到颌骨图像,将颌骨图像的尺寸固定为352
×
352
×
196,并对固定尺寸后的图像进行划分,按7:3的比例得到训练集和测试集;所述训练集用于对cbct图像牙齿分割模型进行训练,所述测试用于对训练好的cbct图像牙齿分割模型进行测试。
[0043]
s2:将训练集中的数据输入到cbct图像牙齿分割模型中进行训练;
[0044]
s3:将cbct图像数据输入到cbct图像牙齿分割模型的编码器中进行特征提取,在每次下采样前保存该分辨率的特征图,得到多个具有不同分辨率的特征图;将除最高分辨率的特征图外的其他特征图作为跳跃路径,并与解码器对应分辨率的特征图进行融合;
[0045]
s4:将最高分辨率的特征图分别输入到stm和ctm中,得到空间变换特征图和类别变换特征图;
[0046]
s5:将空间变换特征图和类别变换特征图输入到特征融合模块中进行融合处理,得到融合特征图;
[0047]
s6:将其他分辨率特征图和融合特征图输入到解码器中,得到还原后的全尺寸特征图;
[0048]
s7:将全尺寸特征图输入到输出层中,并采用softmax函数对输出图像进行处理,得到分割结果;
[0049]
s8:根据分割结果计算模型的损失函数,通过梯度反向传播,不断更新模型的参数,当损失函数收敛到最小值时完成模型的训练,得到训练好的cbct 图像牙齿分割模型。
[0050]
特征提取阶段包括6个卷积模块和3个下采样模块。输入的数据每通过两个卷积模块后进行一次下采样操作(maxpooling3d),使得图像尺寸缩小一半,采用下采样模块对数据进行处理的公式为:
[0051][0052]
其中,m表示下采样前的图像,c表示特征图通道数,表示图像所在的数域,w、h、d分别表示图像的宽度、高度和深度,m
*
表示经过下采样后的图像。
[0053]
如图4所示,空间变换模块stm和类别变换模块ctm对高分辨率特征图进行处理的具体过程包括:
[0054]
采用空间变换模块stm将特征图分为p3个相同尺寸的图块patch,其中,p表示将图像在每个维度分为p等分;;对每个图块进行reshape操作,使得每个图块拉伸为一维向量,将该一维向量作为空间嵌入向量组(spatial embedding);
[0055]
类别变换模块ctm将输入的特征图分别输入到两个卷积层中,该卷积层的通道数分别为n和m,其中n为牙齿的类别数,m为设置的隐藏特征通道数。对进行卷积后的特征图进行reshape操作,得到一个表示单个体素节点类别概率的特征图和一个表示每个体素潜在特征的特征图表示每个体素潜在特征的特征图其中,whd为最高分辨率特征图的宽度、高度和深度之积。特征图x
cate
和特征图x
hidden
的特征表达式为:
[0056][0057]
其中,x表示输入的高维特征,表示1
×
1卷积,σ(
·
)表示一个激活函数, w
n
和w
m
表示卷积层的参数矩阵。
[0058]
将x
cate
转置后与x
hidden
进行矩阵乘法,得到表示每个类别节点具有的全部体素特征的特征矩阵将x
g
按类别分为n个通道数为1的特征矩阵作为类别嵌入向量组。
[0059]
x
g
=x
catet
x
hidden
[0060]
其中,t表示转置。
[0061]
将空间嵌入向量组和类别嵌入向量组分依次输入到由多头自注意力模块和多层感知机组成的transformer结构中,获取空间上的全局特征和类别关系特征。
[0062]
v
′
l
=msa(ln(v
l
‑1)) v
l
‑1[0063]
v
l
=mlp(ln(v
′
l
)) v
′
l
[0064]
其中,v
l
表示第l层transformer layer的输出特征,v
l
表示第l层transformerlayer的中间特征,msa(
·
)表示多头自注意力模块,ln(
·
)表示层归一化操作, mlp(
·
)表示多层感知机。
[0065]
对stm输出的变换特征进行reshape操作得到与输入特征图尺寸相同的变换特征图。
[0066]
对ctm输出的变换特征进行reshape操作,使其维度变为m
×
n的还原特征 x
r
;将x
hidden
与还原特征x
r
做矩阵乘法,得到维度为hwd
×
n的特征矩阵,再进行一次reshape操作,使其维度变为n
×
h
×
w
×
d,输入一个通道数与输入特征图相同的卷积层后得到相同尺寸的变换特征图。
[0067]
[0068]
其中,σ表示一个激活函数,表示1
×
1卷积,reshape(
·
)代表reshape操作,x
′
表示与输入高维特征x尺寸相同的变换特征图,w
c
表示与输入高维特征通道数相同的参数矩阵。
[0069]
对两张变换特征图进行concat操作得到融合特征图,输入解码器。解码器输出采用softmax函数后得到最终分割结果。分类结果的表达式为:
[0070][0071]
其中,softmax(
·
)表示归一化指数函数,x
i
表示x
out
中第c个类别语义对应的输出,n表示类别总数,j表示第j个类别的语义。
[0072]
模型的损失函数包括交叉熵损失(cross
‑
entropy loss)函数和多类soft
‑
dice 损失(multi
‑
class soft dice loss,msdl)函数;对交叉熵损失与多类soft
‑
dice损失求和,得到模型损失函数。
[0073]
交叉熵损失表达式为:
[0074][0075]
其中n表示图像体素的总数,n表示类别数,和分别表示第i个体素预测和ground truth的类别。ground truth表示用于有监督训练的训练集的分类准确性。
[0076]
多类soft
‑
dice损失表达式为:
[0077][0078]
最终损失函数为:
[0079]
l=l
ce
αl
msd
[0080]
其中α是人工设定的超参数,作为损失平衡权重。
[0081]
根据分割结果计算模型的损失函数,通过梯度反向传播,不断更新模型的参数,提高模型分割的精确度,当损失函数收敛在最小值附近时完成模型的训练,得到训练好的cbct图像牙齿分割模型。
[0082]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:rom、ram、磁盘或光盘等。
[0083]
以上所举实施例,对本发明的目的、技术方案和优点进行了进一步的详细说明,所应理解的是,以上所举实施例仅为本发明的优选实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内对本发明所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。