1.本发明属数据获取技术领域,尤其是涉及一种基于scrapy和puppeteer的动态数据抓取方法技术领域。
背景技术:
2.随着网络技术的不断发展,越来越多的网站采用了动态网页技术,通过使用ajax异步获取内容,再通过javascript渲染,api的安全防护也越来越完善。这些极大提升了用户的体验和数据安全,但是也给爬虫带来了新的挑战。scrapy是一套目前非常流行的爬虫框架,可以快速的高效抓取网站并从其页面中提取结构化数据,支持异步、并发、去重,但是只能采集到静态展示的数据,和通过api稳定获取的数据,很多异步加载的数据、接口带有随机参数无法破解的数据则无法采集。对于这部分数据,可以使用模拟浏览器的方式来采集。主流的模拟浏览器方式有两种:一种是使用selenium定位到元素位置来获取数据,不过selenium是专为自动化测试开发的工具,运行速度慢、不稳定、无法截取网络请求;另一种puppeteer则具有更强大的功能,可以通过截取ajax响应直接获取到动态的请求数据,采集速度更快。为实现动态数据采集的高效获取,需要开发一套新的抓取方法。
技术实现要素:
3.本发明正是为了解决上述问题缺陷,提供一种基于scrapy和puppeteer的动态数据抓取方法。本发明结合scrapy和puppeteer的优点,开发一套方法用于数据采集,使用scrapy采集静态数据,速度更快,将动态页面的请求交给puppeteer来处理,解决技术难题。中间使用redis通信,实现分布式处理任务,易于扩展。本发明是一套高并发、易扩展、能处理动态请求的爬虫采集方法。
4.本发明采用如下技术方案实现。
5.一种基于scrapy和puppeteer的动态数据抓取方法,本发明所述的动态数据抓取方法包括以下步骤:
6.步骤1):分析网络请求,分析待采集数据哪些是静态数据,哪些是动态数据;静态数据放入scrapy中采集;
7.步骤2):分析动态网络请求,判断api接口是否能否稳定的返回数据;如是,将该动态数据放到scrapy中采集;如否,则将该动态数据放到puppeteer中采集;
8.步骤3):安装scrapy
‑
redis,使scrapy支持分布式采集;
9.步骤4):设置爬虫的初始url,scrapy将用get方法来请求该url,请求成功以后自动调用默认的回调函数parse返回请求结果;当请求完成以后,scrapy将请求返回的结果response作为参数传递给回调函数;
10.步骤5):提前定义scrapy.item对象,将需要的目标数据定义为item的属性;在回调函数中分析response内容;
11.步骤6):在pipeline中处理item对象;
12.步骤7):puppeteer监听redis队列,当队列中有数据时,取出保存的url和其他的一些关键信息,启动chromium,打开目标网站url;
13.步骤8):等待页面加载完成,获取页面html,通过xpath提取目标数据;
14.步骤9):将目标数据直接插入、或通过id更新到mongodb中持久化保存。
15.进一步为,本发明所述的步骤1)具体为:分析网络请求:使用chrome的开发者工具查看目标网页的网络请求,分析待采集数据哪些是静态数据,哪些是动态数据;静态数据为:在doc类型的网络请求中返回的html里能获取到的数据;动态数据为没有在doc类型的网络请求中返回,而是需要额外调用ajax发送的请求返回的数据;静态数据放入scrapy中采集。
16.进一步为,本发明所述的步骤2)具体为:分析动态网络请求:使用postman工具尝试手动多次发送从步骤1获取到的ajax请求,根据相同的要素,查看返回结果是否能得目标数据,查看是否每次都能得到相同的返回结果,从而判断api接口是否能否稳定的返回数据;如果每次都能得到想要的目标数据,表示接口能够稳定返回数据,则将这部分动态数据放到scrapy中采集,如果不能稳定返回,则将这部分动态数据放到puppeteer中采集。
17.进一步为,本发明所述的步骤2)中:所述的相同的要素为url、请求头、cookies。
18.进一步为,本发明所述的步骤4)包括:初始的url请求使用重写scrapy的start_requests方法,从数据库、redis中读取所有的初始url,手动定义请求头、cookies、参数,并设置自定义的回调函数。
19.进一步为,本发明所述的步骤5)包括:创建一个item对象,将具体目标数据赋值到对应的属性中,最后把封装成的item对象返回。
20.进一步为,本发明所述的步骤5)包括:如果返回的是html类型的数据,使用xpath提取数据。
21.进一步为,本发明所述的步骤5)包括:如果返回json类型的数据,使用json_dumps提取数据。
22.进一步为,本发明所述的步骤6)包括:将已经采集到的目标数据放入mongodb中持久化保存;没有采集到的数据,比如页面的url、数据id等关键字段打包放入到redis队列中。
23.进一步为,本发明所述的步骤8)为:监听http请求的响应事件,当api接口一返回数据,触发响应事件,在该事件的回调函数里处理返回的内容;如果是html类型的数据,使用xpath提取数据;如果是json类型的数据,使用json_dump提取数据。
24.本发明的有益效果为,本发明结合了scrapy和puppeteer两者的优势,将数据进行分类,静态数据和可以通过api稳定获取到的数据放入scrapy采集,实现快速高效的采集。puppeteer可以采集异步加载的、api加密的、复杂的数据。通过redis进行通信,易于扩展。根据具体采集的不同种类数据的多少,增加或减少对应的scrapy、puppeteer服务器就可以保持采集到高性能状态。
25.下面结合附图和具体实施方式本发明做进一步解释。
附图说明
26.图1为本发明具体实施例方法流程示意图。
具体实施方式
27.一种基于scrapy和puppeteer的动态数据抓取方法,所述的动态数据抓取方法包括以下步骤:
28.1.分析网络请求:使用chrome的开发者工具查看目标网页的网络请求,分析待采集数据哪些是静态的,哪些是通过ajax请求得到的。
29.在doc类型的网络请求中返回的html里能获取到的数据,我们称之为静态数据;反之没有在doc类型的网络请求中返回,而是需要额外调用ajax发送的请求返回的数据,我们称之为动态数据。这部分静态数据放入scrapy中采集。
30.2.分析动态网络请求:使用postman工具尝试手动多次发送从步骤1获取到的ajax请求,根据相同的url、请求头、cookies、参数,查看返回结果是否能得目标数据,查看是否每次都能得到相同的返回结果,从而判断api接口是否能否稳定的返回数据。
31.如果每次都能得到想要的目标数据,表示接口能够稳定返回数据,则将这部分动态数据也放到scrapy中采集,如果不能稳定返回,则将这部分动态数据放到puppeteer中采集。
32.3.安装scrapy
‑
redis,使scrapy可以支持分布式采集。
33.4.设置爬虫的初始url,scrapy将用get方法来请求该url,请求成功以后自动调用默认的回调函数parse返回请求结果。
34.如果初始的url请求比较复杂,可以重写scrapy的start_requests方法,从数据库、redis中读取所有的初始url,手动定义请求头、cookies、参数,并设置自定义的回调函数。
35.当请求完成以后,scrapy将请求返回的结果response作为参数传递给回调函数。
36.5.提前定义scrapy.item对象,将需要的目标数据定义为item的属性。在回调函数中分析response内容。
37.如果返回的是html类型的数据,使用xpath提取数据;
38.如果返回json类型的数据,json_dumps提取数据。
39.创建一个item对象,将刚才的提取到的具体目标数据赋值到对应的属性中,最后把封装成的item对象返回。
40.6.在pipeline中处理item对象。
41.将已经采集到的目标数据放入mongodb中持久化保存;
42.没有采集到的数据,比如页面的url、数据id等关键字段打包放入到redis队列中。
43.7.puppeteer监听redis队列,当队列中有数据时,取出保存的url和其他的一些关键信息,启动chromium,打开目标网站url。
44.8.等待页面加载完成,获取页面html,通过xpath提取目标数据。
45.或者监听http请求的响应事件,当api接口一返回数据,触发响应事件,在该事件的回调函数里处理返回的内容,
46.如果是html类型的数据,使用xpath提取数据,
47.如果是json类型的数据,使用json_dump提取数据。
48.监听http请求的响应事件可以不必等待页面全部加载完毕,对于有大量动态请求的网页来说,节省了采集的时间和服务器带宽。
49.9.最后将目标数据直接插入、或通过id更新到mongodb中持久化保存。
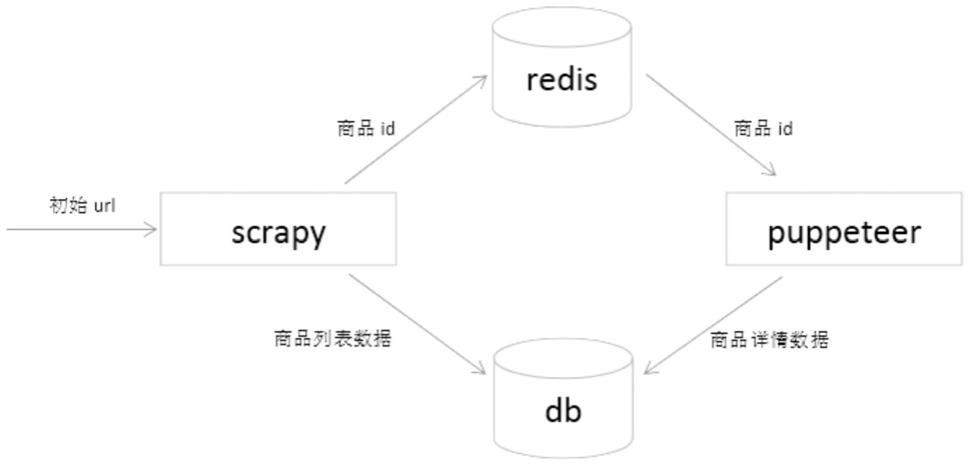
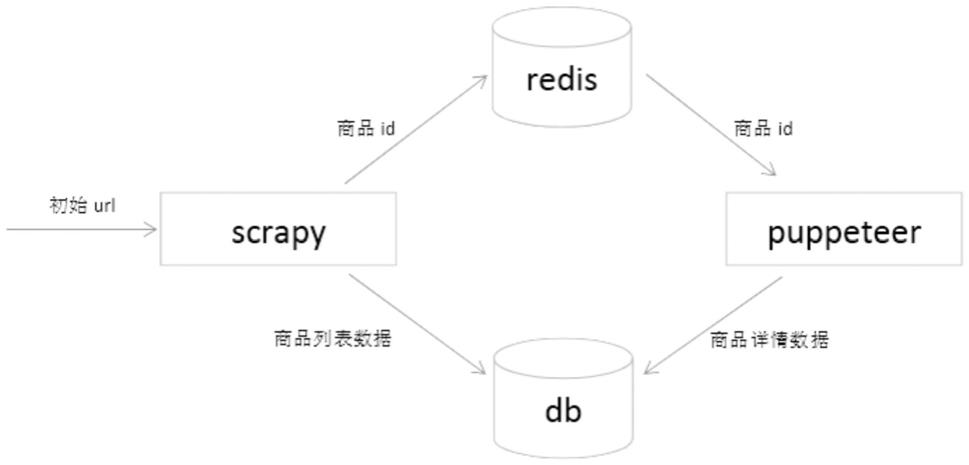
50.见图1所示:
51.实施例:
52.1.采集一个电商网站,包含商品列表页和商品详情页。列表页包含商品id和商品名称,详情页包含商品的价格和销量。
53.2.在电脑上安装scrapy、scrapy
‑
redis、puppeteer、chrome、mongodb、redis、postman。
54.3.打开chrome,跳转到商品列表页,使用chrome的开发者工具查看所有网络请求,分析发现doc类型请求中没有商品的列表数据,列表数据是动态加载的。在xhr类型的请求中找到关键的api能够返回商品列表。打开postman,在postman中使用相同的url、请求头、cookies、参数,手动多次发送请求,可以返回商品列表,并且每次请求都可以得到相同的商品列表,表示可以通过该api稳定获取到商品列表。所以列表页数据放入scrapy中采集。
55.4.打开chrome,跳转到商品详情页,使用chrome的开发者工具查看所有网络请求,分析发现doc类型请求中没有商品的价格和销量数据,该数据是动态加载的。在xhr类型的请求中找到关键的api能够返回商品价格和销量。打开postman,在postman中使用相同的url、请求头、cookies、参数,手动多次发送请求,发现只有第一次请求能够成功返回商品价格和销量,后面再次请求返回错误。原因是获取商品api参数带有一个token,该token使用过后会失效,目前的技术还不能破解token生成的原理,不能通过api稳定获取到数据。所以详情页数据放到puppeteer中采集。
56.5.设置列表页作为初始url,并设置回调函数。在回调函数中得到json类型的响应数据,json_dumps提取出数据,创建item对象,将商品的id和商品名称赋值到item对象的属性中返回。
57.6.在pipeline中处理item对象。先将id和商品名称放入mongodb中持久化保存,再将商品id放入到redis队列中。
58.7.puppeteer监听redis队列,当队列中有数据时,取出商品id,拼接成商品详情页的url,启动chromium,打开url。
59.8.监听获取详情api响应,设置响应回调函数。在回调函数中得到json类型的响应数据,提取出商品的价格和销量。
60.9.最后通过id,把商品的价格和销量数据更新到mongodb中持久化保存。
61.以上所述的仅是本发明的部分具体实施例,方案中公知的具体内容或常识在此未作过多描述。应当指出,上述实施例不以任何方式限制本发明,对于本领域的技术人员来说,凡是采用等同替换或等效变换的方式获得的技术方案均落在本发明的保护范围内。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。