1.本发明涉及地理信息技术领域,特别是涉及一种细粒度地理位置定位方法。
背景技术:
2.来源于人工监测、新闻媒体和社交媒体等渠道的多源文本数据内蕴含丰富的地理信息,是地理信息获取与更新的重要数据源和传递地理信息的重要媒介,已成为用户表达和接收地理信息的主要方式之一,为地理信息的深度挖掘和知识发现带来了巨大机遇;但其内文本形态的地理位置信息往往难以被直接使用。为了增强地理位置文本的可用性,使位置信息发布者、接受者跨越机器语义障碍,直接进行语义沟通,需将地理位置文本描述与现实世界中的空间位置相关联,使其发挥空间参考作用,从而更好地消除地理信息系统中非结构化数据的语义鸿沟,促进智能化地理信息处理。
3.然而,现有的地理位置定位方法主要包括依赖地名地址词典的匹配定位、模糊区域建模定位以及地名消歧辅助定位,只适用于大区域内粗粒度地理位置,难以实现小区域内颗粒度较小、显著度较低的细粒度地理位置定位。其中,依赖地名地址词典的匹配定位通常使用自建的地名地址词典,或者借助互联网地图服务供应商如百度、高德和谷歌提供的地理编码功能完成,这两种方式的实质都是词典匹配;但因其依赖地名地址词典与地理编码服务系统,而构建新的词典存在人力成本较高、工作量较大以及时效性较差等问题,且很多地名地址未被词典收录,因而无法实现“未登录”的细粒度地理位置定位。而对于模糊区域建模与地名消歧辅助定位方法,具有使用范围及限制条件,不支持大规模推广应用,且其定位精度难以满足实际应用的需求。
技术实现要素:
4.有鉴于此,本发明提供了一种细粒度地理位置定位方法,提升了地理位置空间化质量,完善了地理编码与地名检索服务功能。
5.为实现上述目的,本发明提供了如下方案:
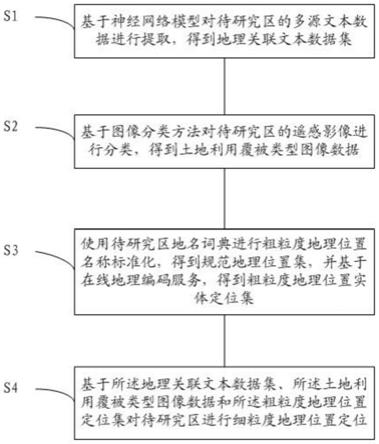
6.一种细粒度地理位置定位方法,包括:
7.基于神经网络模型对待研究区的多源文本数据进行提取,得到地理关联文本数据集;
8.基于图像分类方法对待研究区的遥感影像进行分类,得到土地利用覆被类型图像数据;
9.使用待研究区地名词典进行粗粒度地理位置名称标准化,得到规范地理位置集,并基于在线地理编码服务,得到粗粒度地理位置实体定位集;
10.基于所述地理关联文本数据集、所述土地利用覆被类型图像数据和所述粗粒度地理位置定位集对待研究区进行细粒度地理位置定位。
11.优选地,所述地理关联文本数据集包括地理位置实体文本集、土地利用覆被类型文本集和空间关系文本集。
12.优选地,所述基于神经网络模型对待研究区的多源文本数据进行提取,得到地理关联文本数据集,包括:
13.获取待研究区的多源文本数据;
14.基于所述多源文本数据构建所述神经网络模型;
15.设置超参数并对所述神经网络模型进行训练;
16.对训练后的所述神经网络模型的提取精度进行判断;若所述提取精度达到第一设定值,则应用训练好的所述神经网络模型对所述多源文本数据进行提取,得到所述地理关联文本数据集;若所述提取精度没有达到所述第一设定值,则修改所述超参数,并对所述神经网络模型重新进行训练,重复此过程,直至所述提取精度达到所述第一设定值。
17.优选地,所述神经网络模型包括albert
‑
crf模型和bigru
‑
dual attention模型;
18.所述albert
‑
crf模型用于对所述多源文本数据进行提取,得到所述地理位置实体文本集和所述土地利用覆被类型文本集;
19.所述bigru
‑
dualattention模型用于对所述多源文本数据进行提取,得到所述空间关系文本集。
20.优选地,所述对训练后的所述神经网络模型的提取精度进行判断,具体为基于精确率、召回率和调和平均数对训练后的所述神经网络模型的所述提取精度进行判断。
21.优选地,所述基于图像分类方法对待研究区的遥感影像进行分类,得到土地利用覆被类型图像数据,包括:
22.获取待研究区的所述遥感影像;所述遥感影像为高空间分辨率遥感影像;
23.基于图像分类方法对所述遥感影像进行分类,得到初始土地利用覆被类型图像数据;
24.对所述遥感影像的分类精度进行判断;若所述分类精度达到第二设定值,则将所述初始土地利用覆被类型图像数据作为所述土地利用覆被类型图像数据;若所述分类精度没达到所述第二设定值,参照所述遥感影像对所述初始土地利用覆被类型图像数据进行修正,得到所述土地利用覆被类型图像数据。
25.优选地,所述对所述遥感影像的分类精度进行判断,具体为基于总体精度、用户精度、制图精度和kappa系数四个指标对所述遥感影像的分类精度进行判断。
26.优选地,使用待研究区地名词典进行粗粒度地理位置名称标准化,得到规范地理位置集,并基于在线地理编码服务,得到粗粒度地理位置实体定位集,包括:
27.对所述地理位置实体文本集进行标准化,得到所述规范地理位置集;
28.基于在线地理编码服务和所述规范地理位置集,通过坐标转换工具得到坐标集;
29.将所述规范地理位置集与所述坐标集进行匹配得到所述粗粒度地理位置实体定位集。
30.优选地,所述基于所述地理关联文本数据集、所述土地利用覆被类型图像数据和所述粗粒度地理位置定位集对待研究区进行细粒度地理位置定位,包括:
31.提取第n个粗粒度地理位置定位实体g
n
,判断所述土地利用覆被类型文本集中是否存在与g
n
有关联的土地利用覆被类型文本;n∈n,n为所述粗粒度地理位置定位集中粗粒度地理位置定位实体的数量;
32.若不存在,则在所述土地利用覆被类型图像数据中直接输出g
n
;若存在,则判断所
述空间关系文本集中与g
n
关联的空间关系文本的数量;
33.若只有一个空间关系文本r
m
,则基于自然语言空间关系转换模型对r
m
进行计算得到g
n
的搜索范围,基于g
n
的搜索范围,在所述土地利用覆被类型图像数据中检索与匹配,得到与g
n
有关联的土地利用覆被类型文本l
m
的细粒度位置定位;
34.若存在t个空间关系文本,t为大于1的正整数;则基于自然语言空间关系转换模型对t个空间关系文本进行计算得到g
n
的搜索范围,基于g
n
的搜索范围,在所述土地利用覆被类型图像数据中检索与匹配,得到与g
n
有关联的土地利用覆被类型文本l
m
的细粒度位置定位。
35.优选地,所述自然语言空间关系转换模型包括方位关系近似转换模型、度量关系近似转换模型和拓扑关系近似转换模型。
36.根据本发明提供的具体实施例,本发明公开了以下技术效果:
37.本发明涉及一种细粒度地理位置定位方法,首先获取待研究区的多源文本数据,并对其进行提取,得到地理关联文本数据集;然后获取待研究区的遥感影像,并基于图像分类方法对其进行精细分类,得到土地利用覆被类型图像数据;再使用待研究区地名词典进行粗粒度地理位置名称标准化,得到规范地理位置集,并基于在线地理编码服务,得到粗粒度地理位置实体定位集;最后基于所述地理关联文本数据集、所述土地利用覆被类型图像数据和所述粗粒度地理位置定位集对待研究区进行细粒度地理位置定位。本发明提升了地理位置空间化的质量,完善地理编码与地名检索服务功能,同时,更好地消除地理信息系统中的语义鸿沟,促进智能化地理信息处理。
附图说明
38.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
39.图1为本发明细粒度地理位置定位方法流程图;
40.图2为本发明albert
‑
crf模型结构图;
41.图3为本发明bigru
‑
dualattention模型结构图;
42.图4为本发明土地利用覆被类型图像数据图;
43.图5为本发明细粒度位置定位结果图;
44.图6为本发明定位验证点精度区间分布对比图。
具体实施方式
45.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
46.本发明的目的是提供一种细粒度地理位置定位方法,提升了地理位置空间化质量,完善了地理编码与地名检索服务功能。
47.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
48.图1为本发明粒度地理位置定位方法流程图,如图1所示,本发明提供了一种细粒度地理位置定位方法,包括:
49.步骤s1,基于神经网络模型对待研究区的多源文本数据进行提取,得到地理关联文本数据集。本实施例中,所述地理关联文本数据集包括地理位置实体文本集、土地利用覆被类型文本集l和空间关系文本集r。具体地,所述步骤s1包括:
50.获取待研究区的初始多源文本数据,对所述初始多源文本数据进行删除特殊符号、删除空行、去停用词与数据标注等处理得到所述多源文本数据。
51.基于所述多源文本数据构建所述神经网络模型。优选地,本实施例中,所述神经网络模型包括albert
‑
crf模型和bigru
‑
dualattention模型。
52.设置第一超参数并基于第一训练集对所述albert
‑
crf模型进行训练,设置第二超参数并基于第二训练集对所述bigru
‑
dualattention模型进行训练。
53.基于精确率、召回率和调和平均数对训练后的所述albert
‑
crf模型和所述bigru
‑
dualattention模型的提取精度进行判断;
54.若所述albert
‑
crf模型的提取精度达到第一设定值,则应用训练好的所述albert
‑
crf模型对所述多源文本数据进行提取,得到所述地理位置实体文本集和所述土地利用覆被类型文本集;若所述albert
‑
crf模型的提取精度没有达到所述第一设定值,则修改所述第一超参数,并对所述albert
‑
crf模型重新进行训练,重复此过程,直至所述albert
‑
crf模型的提取精度达到所述第一设定值。
55.若所述bigru
‑
dualattention模型的提取精度达到第一设定值,则应用训练好的所述bigru
‑
dualattention模型对所述多源文本数据进行提取,得到所述空间关系文本集集;若所述bigru
‑
dualattention模型的提取精度没有达到所述第一设定值,则修改所述第二超参数,并对所述albert
‑
crf模型重新进行训练,重复此过程,直至bigru
‑
dualattention模型的提取精度达到所述第一设定值。本实施例中,所述第一设定值取0.9。
56.具体地,所述精确率p的计算公式为:所述召回率q的计算公式为:所述调和平均数f的计算公式为:
57.式中:tp表示正确识别的实体数量;fp表示错误识别的实体数量;fn表示未被识别出的实体数量。
58.步骤s2,基于图像分类方法对待研究区的遥感影像进行分类,得到土地利用覆被类型图像数据。具体地,所述步骤s2包括:
59.获取待研究区的所述遥感影像;所述遥感影像为高空间分辨率遥感影像。
60.基于图像分类方法对所述遥感影像进行分类,得到初始土地利用覆被类型图像数据。
61.对所述遥感影像的分类精度进行判断;若所述分类精度达到第二设定值,则将所述初始土地利用覆被类型图像数据作为所述土地利用覆被类型图像数据;若所述分类精度没达到所述第二设定值,参照所述遥感影像对所述初始土地利用覆被类型图像数据进行修
正,得到所述土地利用覆被类型图像数据。
62.作为一种可选的实施方式,所述对所述遥感影像的分类精度进行判断,具体为,基于所述遥感影像和所述初始土地利用覆被类型图像数据得到分类结果,并基于总体精度、用户精度、制图精度和kappa系数四个指标对所述分类结果进行分析得到所述分类精度,对所述分类精度进行判断。
63.其中,总体精度表示分类结果与参考样本的土地利用覆被类型相同的概率;用户精度表示分类结果中任一随机样本,其类型与同一位置参考样本类型相同的概率;制图精度表示任一参考样本与分类结果在同一位置类型相同的概率。
64.步骤s3,使用待研究区地名词典进行粗粒度地理位置名称标准化,得到规范地理位置集,并基于在线地理编码服务,得到粗粒度地理位置实体定位集。
65.进一步地,所述步骤s3包括:
66.对所述地理位置实体文本集进行标准化,得到所述规范地理位置集。
67.基于在线地理编码服务和所述规范地理位置集,通过坐标转换工具得到坐标集。本实施例中,所述坐标集中的坐标为基于wgs
‑
84坐标系的坐标。
68.将所述规范地理位置集与所述坐标集进行匹配得到所述粗粒度地理位置实体定位集g。
69.步骤s4,基于所述地理关联文本数据集、所述土地利用覆被类型图像数据和所述粗粒度地理位置定位集对待研究区进行细粒度地理位置定位。
70.具体地,所述步骤s4包括:
71.提取第n个粗粒度地理位置定位实体g
n
,判断所述土地利用覆被类型文本集中是否存在与g
n
有关联的土地利用覆被类型文本;n∈n,n为所述粗粒度地理位置定位集中粗粒度地理位置定位实体的数量。
72.若不存在,则在所述土地利用覆被类型图像数据中直接输出g
n
;若存在,则判断所述空间关系文本集中与g
n
关联的空间关系文本的数量;
73.若只有一个空间关系文本r
m
,则基于自然语言空间关系转换模型对r
m
进行计算得到g
n
的搜索范围,基于g
n
的搜索范围,在所述土地利用覆被类型图像数据中检索与匹配,得到与g
n
有关联的土地利用覆被类型文本l
m
的细粒度位置定位;
74.若存在t个空间关系文本,t为大于1的正整数;则基于自然语言空间关系转换模型对t个空间关系文本进行计算得到g
n
的搜索范围,基于g
n
的搜索范围,在所述土地利用覆被类型图像数据中检索与匹配,得到与g
n
有关联的土地利用覆被类型文本l
m
的细粒度位置定位。
75.优选地,所述步骤s4由python语言编程匹配完成。
76.作为一种可选的实施方式,本发明所述自然语言空间关系转换模型包括方位关系近似转换模型、度量关系近似转换模型和拓扑关系近似转换模型。具体地,所述方位关系近似转换模型为依赖相对参考框架和八方向锥形模型的模型;所述度量关系近似转换模型为基于欧氏距离和误差参数的模型;所述拓扑关系近似转换模型为基于点状、线状、面状参照物的相离、包含、相接和相交关系描述的模型。
77.下述以云南省普洱市澜沧拉祜族自治县与西双版纳傣族自治州勐海县部分区域作为研究区进行说明,具体范围为东经100
°
13'54"—100
°
25'06",北纬22
°
13'14"—22
°
24'
14"。
78.初始多源文本数据为待研究区内的750条亚洲象活动肇事文本数据,通过监测员提供和使用python程序从新闻媒体与社交媒体自行爬取,然后对其进行删除特殊符号、删除空行、去停用词与数据标注等处理得到待研究区的多源文本数据。
79.构建的albert
‑
crf模型如图2所示,图中,input为输入层;albert为预训练模型;crf为条件随机场(conditional randomfields,crf)模型;b
‑
loc与i
‑
loc为地理位置实体输出标记,b
‑
luc与i
‑
luc为土地利用/覆被实体输出标记。
80.训练好的albert
‑
crf模型的提取精度如表1所示。
81.表1 albert
‑
crf模型提取精度
[0082][0083]
构建的bigru
‑
dualattention模型如图3所示,图中,input为输入层;bigru为隐含层;字级别attention层为字级别机制层;句级别attention层为句级别机制层;sofmax为输出层,采用sofmax函数。
[0084]
训练好的albert
‑
crf模型的提取精度如表1所示。
[0085]
表2 bigru
‑
dualattention模型提取精度
[0086][0087]
选取待研究区2020年高分二号卫星影像。首先,进行高分二号卫星影像预处理;继而,使用人机交互式遥感解译方法,识别研究区内林地、茶园、水体、建设用地、道路、甘蔗地和香蕉地土地利用覆被类型,结果如图4所示。最后,借助野外实地验证与google earth高分辨率影像判读样本,使用总体精度、用户精度、制图精度和kappa系数四个指标进行分类结果的精度评价,评价结果如表3所示。分类结果如图4所示。
[0088]
表3 2020年研究区土地利用/覆被分类精度
[0089][0090]
基于自建的研究区地名词典,匹配完成地理位置实体名称标准化,得到规范的地理位置名称;基于地名词典与在线地理编码服务,通过正向最大匹配法,借助坐标转换工具或程序,匹配完成wgs
‑
84坐标系下规范的粗粒度地理位置定位,部分示例如表4所示。通过计算匹配坐标与实验数据原始坐标之间的欧氏距离,评价定位精度。
[0091]
表4标准化地理位置定位示例
[0092][0093]
通过步骤s4得到待研究区的细粒度位置定位,结果如图5所示。选取待研究区内75个典型采样点,评价细粒度位置模糊定位的定位精度,并与现有的主流地理编码服务商的定位精度评价结果进行对比,对比结果如图6所示,指标由位置误差距离即定位坐标与真实坐标之间的欧氏距离反映,并将计算出的位置误差距离划分为六级精度区间:第一级:[0,50m]、第二级:(50m,200m]、第三级:(200m,500m]、第四级:(500m,1000m]、第五级:(1000m,2000m]与第六级:(2000m,∞),从图中可以看出,本发明的定位精度明显远远高于现有的主流地理编码服务商的定位精度。
[0094]
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对
[0095]
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说
明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。