技术特征:
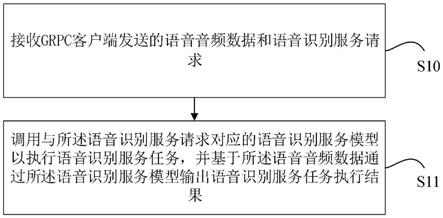
1.一种语音识别服务实现方法,其特征在于,包括:接收grpc客户端发送的语音音频数据和语音识别服务请求;调用与所述语音识别服务请求对应的语音识别服务模型以执行语音识别服务任务,并基于所述语音音频数据通过所述语音识别服务模型输出语音识别服务任务执行结果。2.根据权利要求1所述的语音识别服务实现方法,其特征在于,所述调用与所述语音识别服务请求对应的语音识别服务模型,包括:解析所述语音识别服务请求,得到语音识别服务请求字段,所述语音识别服务请求字段包括任务名称字段;根据所述任务名称字段调用与所述任务名称字段对应的语音识别服务模型。3.根据权利要求1所述的语音识别服务实现方法,其特征在于,在接收所述语音音频数据和所述语音识别服务请求前,所述语音音频数据和所述语音识别服务请求被protobuf序列化;在接收到序列化后的语音音频数据和语音识别服务请求后通过protobuf进行反序列化,并对反序列化的语音音频数据进行解析,得到pcm数据。4.根据权利要求1或3所述的语音识别服务实现方法,其特征在于,在输出语音识别服务任务执行结果后,通过protobuf对所述语音识别服务任务执行结果进行序列化。5.根据权利要求3所述的实现语音识别服务方法,其特征在于,所述语音识别服务任务包括以下至少之一:声纹注册任务、1:1声纹比对任务、1:n声纹比对任务。6.根据权利要求5所述的语音识别服务实现方法,其特征在于,若所述语音识别服务任务为声纹注册任务,则利用声纹提取模型对所述pcm音频数据进行特征提取,得到第一声纹特征向量,并利用所述第一声纹特征向量进行注册;若所述语音识别服务任务为1:1声纹比对任务,则利用声纹提取模型对所述pcm音频数据进行特征提取,得到第一声纹特征向量;将所述第一声纹特征向量与注册过的1个对象的第二声纹特征向量进行比对,得到比对结果;若所述语音识别服务任务为1:n声纹比对任务,则利用声纹提取模型对所述pcm音频数据进行特征提取,得到第一声纹特征向量;将所述第一声纹特征向量与注册过的n个对象的第二声纹特征向量进行比对,得到比对结果。7.一种语音识别服务实现装置,其特征在于,包括:接收模块,用于接收grpc客户端发送的语音音频数据和语音识别服务请求;任务执行模块,用于调用与所述语音识别服务请求对应的语音识别服务模型以执行语音识别服务任务,并基于所述语音音频数据通过所述语音识别服务模型输出语音识别服务任务执行结果。8.根据权利要求7所述的语音识别服务实现装置,其特征在于,所述任务执行模块包括:解析模块,用于解析所述语音识别服务请求,得到语音识别服务请求字段,所述语音识别服务请求字段包括任务名称字段;调用模块,用于根据所述任务名称字段调用与所述任务名称字段对应的语音识别服务模型。9.根据权利要求7所述的语音识别服务实现装置,其特征在于,该装置还包括:
序列化模块,用于在接收所述语音音频数据和所述语音识别服务请求前,对所述语音音频数据和所述语音识别服务请求被protobuf序列化;以及在接收到序列化后的语音音频数据和语音识别服务请求后通过protobuf进行反序列化;解析模块,用于对反序列化的语音音频数据进行解析,得到pcm数据。10.根据权利要求7或9所述的语音识别服务实现装置,其特征在于,所述序列化模块还用于在输出语音识别服务任务执行结果后,通过protobuf对所述语音识别服务任务执行结果进行序列化。11.根据权利要求9所述的语音识别服务实现装置,其特征在于,所述语音识别服务任务包括以下至少之一:声纹注册任务、1:1声纹比对任务、1:n声纹比对任务。12.根据权利要求11所述的语音识别服务实现装置,其特征在于,若所述语音识别服务任务为声纹注册任务,则利用声纹提取模型对所述pcm音频数据进行特征提取,得到第一声纹特征向量,并利用所述第一声纹特征向量进行注册;若所述语音识别服务任务为1:1声纹比对任务,则利用声纹提取模型对所述pcm音频数据进行特征提取,得到第一声纹特征向量;将所述第一声纹特征向量与注册过的1个对象的第二声纹特征向量进行比对,得到比对结果;若所述语音识别服务任务为1:n声纹比对任务,则利用声纹提取模型对所述pcm音频数据进行特征提取,得到第一声纹特征向量;将所述第一声纹特征向量与注册过的n个对象的第二声纹特征向量进行比对,得到比对结果。13.一种语音识别服务实现系统,其特征在于,包括:grpc客户端,用于获取语音音频数据,并向grpc服务端发送语音识别服务请求;grpc服务端,用于接收grpc客户端发送的语音音频数据和语音识别服务请求;所述grpc服务端调用与所述语音识别服务请求对应的语音识别服务模型以执行语音识别服务任务,并基于所述语音音频数据通过所述语音识别服务模型输出语音识别服务任务执行结果;所述grpc客户端接收所述语音识别服务任务执行结果。14.一种语音识别服务实现设备,其特征在于,包括:一个或多个处理器;和其上存储有指令的一个或多个机器可读介质,当所述一个或多个处理器执行时,使得所述设备执行如权利要求1
‑
6中一个或多个所述的方法。15.一个或多个机器可读介质,其特征在于,其上存储有指令,当由一个或多个处理器执行时,使得设备执行如权利要求1
‑
6中一个或多个所述的方法。
技术总结
本发明公开了一种语音识别服务现方法,包括:接收GRPC客户端发送的语音音频数据和语音服务请求;调用与所述语音服务请求对应的语音识别服务模型以执行语音识别服务任务,并基于所述语音音频数据通过所述语音识别服务模型输出语音识别服务任务执行结果。本发明基于GRPC的轻量级的实现语音识别服务方法,解决了语音识别服务模型工业部署应用较为困难的问题,使得语音识别服务模型可以无需进行onnx转换,无需依赖于固定的tfServing推理框架,具备更好的灵活性与可扩展性的同时,极大提高了服务器资源利用率与声纹识别服务并发量。同时结合GRPC与Protobuf对语音音频数据进行序列化压缩,减小传输数据大小,提高传输效率,减少大文件传输时延。文件传输时延。文件传输时延。
技术研发人员:周思逸 晏超
受保护的技术使用者:云从科技集团股份有限公司
技术研发日:2021.09.01
技术公布日:2021/11/30
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。