1.本发明属于计算机安全领域,具体涉及一种针对模糊测试工具漏洞挖掘能力的集成化评估方法及装置。
背景技术:
2.近年来,在漏洞挖掘领域,模糊测试工具发展迅猛。相比于其他漏洞挖掘工具,如smt解算器、符号执行、静态分析,模糊测试表现优秀。模糊测试的基本方法论相对其他方法较为简单:循环并随机地生成程序输入端数据,将其不断向目标测试程序的输入接口传递,通过被测程序的运行表现和结果,挖掘潜在漏洞。例如,afl是一款由美国谷歌开发的模糊测试工具。将afl和符号执行应用于同一被测程序集,包括base64,md5sum,uniq,who,sqlite3,libtiff。最终,二十四小时内afl找到的比符号执行发现的平均漏洞个数多76%。
3.随着模糊测试在评估和检测软件重要安全性漏洞上取得了重大的成功,不仅学术届的模糊测试工具的开发和研究方兴未艾,而且在工业届的软件开发测试当中,模糊测试也被广泛部署。简单的理念却有非凡的效果,极高的理论到实际的可实现度,都是学术界和工业界的研究成果如雨后春笋般涌现的重要原因。近几年以来,探究人员对模糊测试算法,模糊测试策略,模糊测试工具优化和模糊测试工具开发,产生极大兴趣并付诸了巨大努力。
4.但是,模糊测试是一个随机过程的本质所导致的问题,随着模糊测试领域的蓬勃发展,赫然摆在了众多科研人员面前,棘手却亟待解决。模糊测试本质上作为一个随机过程,加之不同的模糊测试工具的算法理论体系、测试框架、测试决策机制的大相径庭,使得客观且有效地对比和评价模糊测试工具成为一个难题。模糊测试评估领域的现状恰好印证了这一点:模糊测试各个技术要点上,不同的科研人员却有着不同的主张,所以如何在比较工具时评判优劣,成为了一大难题。许多科研人员也逐渐意识到了这样的问题,尝试提出了多种不同的评估评价体系与方法,但因种种缺陷无法被业界广泛认可并使用,例如中国专利申请cn112749097a公开了一种模糊测试工具性能测评方法、装置,性能指标不全面,权重选取方法未知,而性能指标的全面读和权重选取的准确度是影响评分准确读的两大重要标准,本方法在包括但不仅限于两方面都有显著优化。
技术实现要素:
5.为了解决上述问题,本发明的目的在于提供一种针对模糊测试工具漏洞挖掘能力的集成化评估方法及装置,具有科学客观性强,适用范围广泛,自我适配能力高的特点,旨在为模糊测试工具的开发者和使用者提供一个全面科学的评价报告。
6.为了实现上述发明目的,发明了以下技术方案:
7.一种针对模糊测试工具漏洞挖掘能力的集成化评估方法,其步骤包括:
8.1)将n种模糊测试工具与m种测试程序集交叉配对,抓取参考数据和目标值;
9.2)以目标值作为监督数据,利用参考数据进行训练,得到评估模型;
10.3)将待测模糊测试工具与p种测试程序集交叉配对后,将相应参考数据输入评估
模型,生成评估报告。
11.进一步地,模糊测试工具包括:oss
‑
fuzz、honggfuzz、syzkaller、awesome fuzzing、raccoon、afl、aflplusplus、memlock、triforceafl、vuzzer、mopt
‑
afl、collafl、hypothesis、clusterfuzz、afl.rs、paramspider、fuzzit、peach fuzzer、dharma和uafuzz中的一种或多种;测试程序集包括:magma、lava、lava
‑
m、cgc和fts中的一种或多种。
12.进一步地,参考数据包括:刚性结构值和韧性架构值。
13.进一步地,所述刚性结构值包括:块覆盖率、边覆盖率、触发崩溃数、特有崩溃数、漏洞到达率、漏洞触发率、漏洞检测率、触发崩溃数、漏洞挖掘准确率和崩溃输入产生率。
14.进一步地,所述韧性架构值包括:代码处理方法深度、初始集适应度、白灰黑属性、部署消耗、便利性、稳定性、真值完整性、去重复化机制质量、结构分析法质量和运行监控质量。
15.进一步地,所述目标值包括:漏洞发掘率。
16.进一步地,利用参考数据进行训练之间,对参考数据进行预处理:
17.1)依据数据的类型,对参考数据分类;
18.2)对韧性架构值进行聚类,得到各韧性架构值相应的分级化韧性架构值;
19.将刚性结构值进行归一化处理,并利用可信区间对归一化数据的特征值进行过滤后,得到归一化刚性结构值;
20.3)基于分级化韧性架构值及归一化刚性结构值,生成预处理后的参考数据。
21.进一步地,所述评估模型包括:分类模型和回归模型,其中将分级化韧性架构值送入分类模型,归一化刚性结构值送入回归模型。
22.进一步地,依据评估报告,通过以下步骤进行反馈学习:
23.1)将训练时的参考数据作为原始数据集,将测试时的参考数据作为新数据集,并利用可信区间查正态分布表,分别获取原始数据集的数据区间[min,max]及新数据集的数据区间[min
′
,max
′
];
[0024]
2)判断数据区间[min
′
,max
′
]与数据区间[min,max]重合率:若重合率大于标准模糊测试可信度x%,则进入步骤4),若小于标准模糊测试可信度,进入步骤3);
[0025]
3)基于新数据集的标准差σ
′
与原始数据集的标准差区间σ进行判断:若标准差σ
′
没有落在标准差区间σ内,则舍弃新数据集;若标准差σ
′
落在标准差区间σ内,进入步骤4);
[0026]
4)整合新数据集与原始数据,得到更新数据集,并进行判断:若大于标准模糊测试可信度x%的新数据集的数据落在更新数据集的标准模糊测试区间内,进入步骤5);否则,进入步骤6);
[0027]
5)提升模糊测试可信度x的数值,并依据提升后的数值,得到新的标准模糊测试区间;
[0028]
6)若更新数据集的标准模糊测试区间是原始数据相应标准数据集的区间均一偏离,则将[min(μ,μ
′
)
‑
min(σ,σ
′
)y,max(μ,μ
′
) min(σ,σ
′
)y]作为新的标准模糊测试区间,其中,μ为原始数据孙集的平均值,μ
′
为新数据集孙集的平均值。
[0029]
进一步地,所述评估报告包括:测试数据、韧性评估、刚性评估、综合评定和改进意见。
[0030]
一种存储介质,所述存储介质中存储有计算机程序,其中,所述计算机程序被设置
为运行时执行以上所述方法。
[0031]
一种电子装置,包括存储器和处理器,其中存储器存储执行以上所述方法的程序。
[0032]
与现有方法相比,本发明引入人工智能中深度学习,神经网络学习的技术,解决了模糊测试领域中众多评价方法中存在的主观性强,科学性差,适用范围局限等问题。本发明不仅能够全面科学地对被测程序进行定性结合定量的评估,还能在每一次对被测工具的评估过程中,在统计学理论的指导下,进行正向的自我成长,只要不断喂入新的待测工具,整个评价体系将与时俱进。本发明可发展应用于更多的新兴模糊测试工具,供进行新型模糊测试工具的研究人员使用,并为他们提供在提高模糊测试工具的漏洞挖掘能力方面的指导性和建设性意见。
附图说明
[0033]
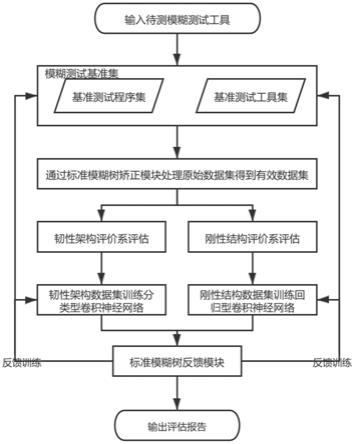
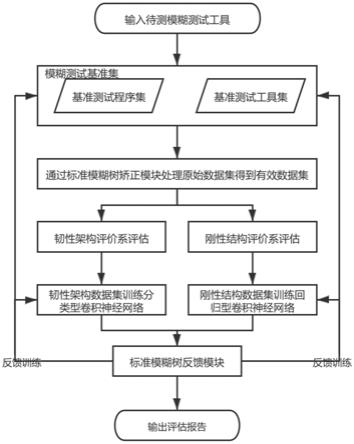
图1是本实施例的模糊测试工具集成化评估方法流程图。
[0034]
图2是本实施例的集成化方法评估综合指标的结构示意图。
[0035]
图3是本实施例中评估报告输出的结构图。
[0036]
图4是本实施例中标准模糊树矫正模块实施流程图。
具体实施方式
[0037]
为了使本发明的目的、技术方案及优点更加清晰,下面通过具体实施例和附图对本发明进行进一步详细阐述。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0038]
本发明的集成化评估方法,如图1所示,包括:将所选取的二十种模糊测试工具和五种测试程序集交叉配对;将待测程序与四种测试程序集交叉配对进行x天数据抓取,以y小时为一观察周期,全面记录数据;过标准模糊树矫正模块对各项指标数据进行处理;将处理后的标准数据集输入卷积神经网络,以监督学习的方式训练此模型;训练完成后,将待测程序的数据集输入神经网络模型,得到评估报告;将所测试的模糊测试工具及其数据入库,并在标准模糊树反馈模块的帮助下进行集成化评估方法的反馈学习。其中,具体步骤如下:
[0039]
1、获取原始数据
[0040]
将所选取的二十种模糊测试工具和五种测试程序集交叉配对;将待测程序与四种测试程序集交叉配对进行x天数据抓取,以y小时为一观察周期,全面记录原始数据。
[0041]
例如x天数据抓取,y小时为一周期,抓取原始数据n组,其中n=24
×
x
÷
y。二十种模糊测试标准工具集包括oss
‑
fuzz,honggfuzz,syzkaller,awesome fuzzing,raccoon,afl,aflplusplus,memlock,triforceafl,vuzzer,mopt
‑
afl,collafl,hypothesis,clusterfuzz,afl.rs,paramspider,fuzzit,peach fuzzer,dharma,uafuzz。这二十种模糊测试工具的选取标准为:在2007年至2021年每年的新模糊测试工具中选取一到两个具代表性的,具体地,代表性强需满足包括算法代表性强,测试模式代表性强和决策机制代表性强。五种模糊测试标准程序集包magma,lava,lava
‑
m,cgc和fts,这些是所有研究人员开发新模糊测试工具的使用率的前五位测试目标。
[0042]
全面抓取的数据包括以下三种,如图2所示:
[0043]
a)刚性结构值;块覆盖率,边覆盖率,触发崩溃数,特有崩溃数,漏洞到达率,漏洞
触发率,漏洞检测率,触发崩溃数,漏洞挖掘准确率,崩溃输入产生率,共十个;
[0044]
b)韧性架构值:代码处理方法深度,初始集适应度,白灰黑属性,部署消耗,便利性,稳定性,真值完整性,去重复化机制质量,结构分析法质量,运行监控质量,共十个;
[0045]
c)目标值:漏洞发掘率,共一个。
[0046]
本步骤具体说明如下:
[0047]
1a)本评价体系基于众多模糊测试工具测试的表现数据为指标数据,以漏洞挖掘率作为评价数据,转到lb)。
[0048]
1b)获得数据。二十种模糊测试工具和五种测试程序集交叉配对,同时将待测程序与四种测试程序集交叉配对,对所有配对组合进行x天数据抓取,y小时为一观察周期,全面记录数据。具体地,本实验部分x=10,y=8,即可得到10*24
÷
8=30组原始数据。
[0049]
2、通过标准模糊树矫正模块对各项原始数据进行处理
[0050]
对于训练数据,标准模糊树矫正模块过滤处理包括以下几个步骤:
[0051]
2a依据设定规则,分别抽取参考数据和目标值,其中参考数据包括:刚性结构值和韧性架构值;
[0052]
2b)判断数据类型,如果是韧性架构值,则韧性架构值聚类评级,得到分级化韧性架构值;如果是刚性结构值,则进行归一化处理,并利用归一化数据的特征值后进行标准模糊可信区间过滤,得到归一化刚性结构值;其中,在进行标准模糊可信区间过滤时,默认起始可信度为60%,故取中间20%
‑
80%的数据作为有效数据,若非首次运行,可信度按当前值为准。综合评分为0
‑
100,规定初始硬指标评分为目标指标d
t
×
100,d
t
为目标值;
[0053]
2c)整合生成{训练标准数据集}={分级化韧性架构值∪归一化刚性结构值}∪{目标值}。
[0054]
其中,步骤2b)中的标准模糊测试可信度和可信区间定义如下:
[0055]
令由已集成的n个模糊测试工具f1,f2,......,f
n
,与已集成m个标准被测程序集p1,p2,......,p
m
逐一组成的标准测试子集其中其中共m
×
n个子集。由于f、p配对模糊测试过程不断循环往复进行,子集s
ij
中存在多个孙集,孙集合数量上限为max
gs
。模糊测试集正态归一化后,孙集数据近似符合正态分布x~n(μ,σ),μ为算数平均数,σ为标准差,n为正态分布算法。当前标准模糊测试可信度设定为x%,即可信区间为的数据,查正态分布表可得对应数据区间(μ
‑
d,μ d),此处d为正态区间两端与算术平均数的距离。
[0056]
而对于测试数据,仅抽取参考数据,并对参考数据得到预处理,得到{测试标准数据集}={分级化韧性架构值∪归一化刚性结构值}。
[0057]
3、将预处理后的参考数据输入卷积神经网络,以目标值为监督数据进行监督学习的方式的训练。
[0058]
卷积神经网络的结构主要包括:
[0059]
分类模型:分级化韧性架构值进入分类模型,输出由高到低四种分级t0、t1、t2、t3;回归模型:归一化刚性结构值进入回归模型,输出评分s,其中0≤s≤1;
[0060]
输出层:基于分类模型与回归模型的输出,输出以总评分。
[0061]
训练过程中,将处理后的标准数据集的不同部分作为训练组输入两个不同卷积神
经网络,以监督学习的方式训练此模型,具体说明如下:
[0062]
3a)分级化韧性架构值作为分类训练集,输入分类模型;
[0063]
3b)归一化刚性结构值作为回归训练集,输入回归模型;
[0064]
3c)以目标值监督输出层的总评分,进行卷积网络的训练。
[0065]
4、训练完成后,将待测程序的测试标准数据集输入神经网络模型,得到评估报告。
[0066]
将待测程序的测试标准数据集输入神经网络模型,具体说明如下:
[0067]
4a)分级化韧性架构值输入分类模型,分类模型输出各项韧性架构值的评级,转到4c;
[0068]
4b)归一化刚性结构值输入回归模型,回归模型输出综合评分,转到4c);
[0069]
4c)生成评估报告,如图3所示,评估报告将包含以下几个方面:
[0070]
原始数据;
[0071]
韧性评估;
[0072]
刚性评估;
[0073]
综合评定,当前被测模糊测试工具在历史被测工具中的百分比排名将作为综合评定的主要内容输出,包括软指标排名,硬指标排名和综合排名;
[0074]
改进意见,当前被测模糊测试工具在历史被测工具中所有低于平均评定数值的指标的集合将作为主要内容在本项内容中作为需改进部分提出。
[0075]
5、将所测试的模糊测试工具及其数据入库,并在标准模糊树矫正模块的指导下进行集成化评估方法的反馈学习。
[0076]
本发明借助标准模糊树反馈模块帮助的反馈训练,如图4所示,主要包括以下步骤:
[0077]
5a)生成数据区间。基于可信区间查正态分布表,分别生成被测程序生成的新数据集数据区间[min
′
,max
′
]与标准测试集合数据区间[min,max];
[0078]
5b)判断被测程序生成数据可信度。当前模糊测试结束,判断新数据集数据区间[min
′
,max
′
]与标准测试集合数据区间[min,max]重合率,若重合率大于标准模糊测试可信度x%,则进入步骤5d),若小于标准模糊测试可信度,进入步骤5c);
[0079]
5c)计算新数据集合标准差σ
new
,若σ
new
大于标准测试集合的标准差σ
standard
,结束反馈,即直接结束反馈升级流程,舍弃新数据集,若σ
new
小于σ
standard
,进入步骤5d);
[0080]
5d)整合新数据集与标准数据集为更新数据集,若大于标准模糊测试可信度x%的新数据集的数据落在更新数据集的标准模糊测试区间内,进入步骤5e),若不大于,进入步骤5f);
[0081]
5e)提高标准模糊测试可信度x持续提升至x
′
,使得恰好数据孙集的数量为max
gs
时停止,此时标准模糊测试可信度将更新为x
′
,相应标准模糊测试区间随之更新。
[0082]
5f)若更新数据集的标准模糊测试区间是标准数据集的区间均一偏离,则将[min(μ,μ
′
)
‑
min(σ,σ
′
)y,max(μ,μ
′
) min(σ,σ
′
)y]作为新的标准模糊测试区间,通过正态分布对应表相应算出的x
′
%作为新的标准模糊测试可信度(μ和σ为原标准数据孙集的平均值和标准差,μ
′
和σ
′
为新数据集的平均值和标准差,令[μ
‑
σy,μ σ
′
y]为原标准模糊测试区间)。
[0083]
容易理解,本发明中的集成化的初始模糊测试工具和被测程序集可以应实际要求变换,数据抓取时间和周期也可以根据测试工具和被测对象的不同调整数值,刚性结构数
据和韧性架构数据的选择和评分都可以依据更细化的需求调整,因此以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求所述为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。