1.本发明涉及一种社交媒体中基于多模态信息融合账号位置识别方法。
背景技术:
2.随着信息技术与互联网的不断发展,社交媒体对用户开放的服务与功能也日趋完善。鉴于社交媒体的便利性、开放性以及多样性,它被人们认为是在线互动和信息共享的合适平台。其中,社交账号作为社交媒体中活跃的主体每天发布着数以亿计的消息,为市场调研、商业决策和事件检测等多个领域提供了丰富且宝贵的数据资源。
3.账号位置信息作为账号最基本的属性之一,描述了账号使用者在实际生活中的地理位置,在人流统计、区域性决策及个性化服务等方面都有广泛应用。但由于社交媒体没有严格的信息审查机制,由社交账号使用者自己填写的位置信息往往是缺失、不完整甚至是错误的。因此,在实际生活中,账号的位置信息是很难获取的,这给上述应用的开展带来了巨大挑战。
4.为了获取社交媒体中账号的位置信息,研究者们就社交媒体账号位置识别这一领域展开了深入的研究,提出了一系列的账号位置识别方法。现有方法主要从社交媒体中单一或部分信息入手来推断账户位置信息,但社交媒体中的信息是复杂多样的,单一或部分信息不能完整地描述该账号的位置特征。其次,传统方法对于多种特征的融合大多是简单的拼接,这种处理方式将多个特征看作是独立的个体,忽略了特征间的关联联系,导致提取的特征没有充分利用,最终账号位置识别准确率不高。
5.按照社交媒体中信息种类的不同,现有的社交媒体账号位置识别方法可以分为三类:基于发布内容的方法、基于消息语境的方法和基于关系网络的方法。
6.发布内容是指账户在社交媒体中发送的消息内容,以文本、语音、图片或视频的方式存在。基于发布内容的账号位置识别方法通过分析挖掘账户发送的消息内容来推断该账户的地理位置。该类方法认为账户发布的消息中只有部分内容具有位置指向功能,其余消息为位置无关的噪声信息。通过提取并分析这些具有位置指向的内容,就可以识别账号的位置。基于该思想,cheng等(cheng,zhiyuan,james caverlee,and kyumin lee."you are where you tweet:a content
‑
based approach to geo
‑
locating twitter users."proceedings of the 19th acm international conference on information and knowledge management.2010)使用空间变化模型为每一个单词拟合二维的地理分布。每个单词在对应的地理分布中都有一个地理中心,越靠近地理中心,该单词的出现概率越高。而具有位置指向功能的单词在地理分布上呈现中心高、四周低的特性。通过机器学习模型判别出消息中的地理词汇,之后利用极大似然思想将地理词中最高频的地理中心作为账户位置。与之类似,hecht等(hecht,brent,et al."tweets from justin bieber's heart:the dynamics of the location field in user profiles."proceedings of the sigchi conference on human factors in computing systems.2011)也提取了社交媒体中具有位置指向的单词,不同的是他们选用calgari分数作为地理词的判断依据,最终将calgari
值最高的10000个单词作为地理词,借用词袋模型和朴素贝叶斯模型对账号位置进行分类。
7.社交媒体除了传递内容信息本身外,还会伴随着一系列的语境信息,这些语境信息对消息内容起到补充说明的作用。比如,发送者的个人概述、发送时间、gps信息等都属于消息的语境信息。通过上述这些语境信息也能帮助我们识别账号位置。mahmud等(mahmud,jalal,jeffrey nichols,and clemens drews."where is this tweet from?inferring home locations of twitter users."sixth international aaai conference on weblogs and social media.2012)观察到不同时区的人在一天内活跃的时间分布不同,于是他们将消息的发送时间作为特征,个人概述中的时区信息作为标签训练了时区分类器,最后账号的位置以时区维度的形式展现出来。此外,huang等(huang,binxuan,and kathleen m.carley."a hierarchical location prediction neural network for twitter user geolocation."arxiv preprint arxiv:1910.12941(2019))将每个账号的时区信息,语言字段等语境信息进行嵌入表征形成一个二维向量,输入到一个预训练神经网络模型中训练,新账号进行特征提取后输入训练好的神经网络中就可以输出该账号的位置信息。
8.除了发布内容和消息语境信息外,社交媒体中还存在关系网络这类信息(如:提及和回复关系、关注和被关注关系等)。它描述了账号间交流和关联关系,通过关系网络中暗含的位置联系同样可以识别账号位置。基于关系网络的账号位置识别方法核心思想是:一个账号的真实位置与其关系网络中的其它账号的位置相近。基于该思想,backstrom等(backstrom,lars,eric sun,and cameron marlow."find me if you can:improving geographical prediction with social and spatial proximity."proceedings of the 19th international conference on world wide web.2010)尝试将两个账号成为朋友的概率与两个账号位置间的距离使用多项式函数来拟合,之后账号的位置可以通过最大化该账号与其网络关系中所有账号之间的距离来确定,其中,账号的网络关系由追随者列表和朋友列表构建。由于追随者列表和朋友列表获取成本较高,rahimi等(rahimi,afshin,trevor cohn,and timothy baldwin."semi
‑
supervised user geolocation via graph convolutional networks."arxiv preprint arxiv:1804.08049(2018))选择使用推文中的提及关系来构建网络关系。在构网完成之后,图卷积神经网络被用于提取网络中账号间的关联特征并最终输出账号位置。近期,tian等(tian,hechan,et al."twitter user location inference based on representation learning and label propagation."proceedings of the web conference 2020.2020)借用异质网络和标签传播算法来识别账号位置。首先,他们利用账号间的朋友关系以及账号与位置指向词之间的关联关系构建异质网络。之后,在异质网络中为每个账号提取一个特征向量,该向量可以用于计算两个账户间的位置相似度。最后,通过标签传播算法并结合账户间的位置相似度,将位置已知账号的标签信息传播到位置未知账号,最终识别出剩余账号的位置。
9.现有的账号位置识别方法主要存在特征挖掘不充分和模型构建不完备两方面问题。特征挖掘不充分是指识别方法只利用了单一或者部分社交媒体中的信息特征来推断账户位置,导致识别效果达不到预期。而模型构建不完备是指识别方法所构建的识别模型不能充分利用所提取特征的信息,导致模型的识别效果不佳。因此,现有的很多方法在实际社交媒体账号位置识别中,无法获得准确的识别效果。
技术实现要素:
10.本发明的目的在于克服现有技术的不足,提供一种通过研究构建了高效的融合判别网络,该网络通过分组输入、前端融合与张量融合混合的融合方法以及集成学习等手段,能够高效地组织多种模态特征并计算特征与特征之间的联系,位置识别准确率能达到95%以上的社交媒体中基于多模态信息融合账号位置识别方法。
11.本发明的目的是通过以下技术方案来实现的:社交媒体中基于多模态信息融合账号位置识别方法,包括以下步骤:
12.s1、从数据库中获取训练集;
13.s2、通过特征提取器对训练集中的数据进行特征提取;
14.s3、将提取的特征输入多模态融合判别网络,实现账号位置的识别。
15.进一步地,所述特征提取器负责提取三种正交且与账户位置高度相关模态特征,包括时间序列特征、名称词缀特征和实体语义特征。
16.时间序列特征提取方法为:通过统计账户在24个小时段中发送推文的频次分布,可以得到用户在实际生活中一天的活跃时间段,也就是该账户的时间序列特征,共24维。
17.名称词缀特征提取方法为:对一个账户的用户名进行二元词缀和三元词缀的分解,即将一个账号表示为多个二元词缀或三元词缀的组合,将该组合作为账户的名称词缀特征。
18.实体语义特征提取方法为:提取消息内容中的地点和话题特征,以及个人描述中的语义信息作为实体语义特征。
19.进一步地,所述多模态融合判别网络的识别过程包括以下子步骤:
20.s31、采用平行输入的策略,即将时间序列特征、名称词缀特征、实体语义特征作为平行特征输入到融合判别网络中;
21.s32、将时间序列特征、名称词缀特征、地点和话题特征分别输入pca降维模块进行降维处理;
22.s32、将降维处理后的特征通过张量融合的方式进行特征融合;
23.s34、将张量融合后的特征与个人描述中的语义信息特征进行前端融合;
24.s35、将前端融合后的特征通过梯度提升树模型来拟合最终特征。
25.本发明的有益效果是:
26.1)本发明分析后提取了与账号位置相关的三种正交模态特征(时间序列特征、名称词缀特征和实体语义特征),并将这些特征进行量化处理。这些特征不仅可以准确全面地刻画账号与位置属性之间的关系,同时还可以迁移到其它自然语言处理的任务中。
27.2)本发明通过研究构建了高效的融合判别网络,该网络通过分组输入、前端融合与张量融合混合的融合方法以及集成学习等手段,能够高效地组织多种模态特征并计算特征与特征之间的联系。该融合判别网络模型在国家级位置识别准确率能达到95%以上。
附图说明
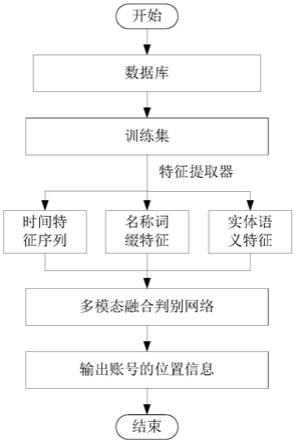
28.图1为本发明的基于多模态信息融合账号位置识别方法的流程图;
29.图2为本发明的时间序列特征的实例;
30.图3为本发明的名称词缀特征的实例;
31.图4为本发明的实体语义特征的实例;
32.图5为本发明的融合判别网络进行识别的示意图;
33.图6为本发明的张量融合示意图。
具体实施方式
34.下面结合附图进一步说明本发明的技术方案。
35.如图1所示,本发明的一种社交媒体中基于多模态信息融合账号位置识别方法,包括以下步骤:
36.s1、从数据库中获取训练集;
37.s2、通过特征提取器对训练集中的数据进行特征提取;所述特征提取器负责提取三种正交且与账户位置高度相关模态特征,解决了传统账号位置识别方法中特征挖掘不充分的问题。鉴于社交媒体中与位置相关信息的不充足性、不准确性以及多样性,仅通过单一或部分特征信息识别账号位置是无法达到预期效果的。针对上述问题,本发明通过全面分析账号信息与用户位置之间的关系,提取了三种与账户位置高度相关且正交的模态特征,包括时间序列特征、名称词缀特征和实体语义特征。因为这几种特征在表现形式上是多样且彼此正交的,因此被称为是多模态特征。用这三种模态信息共同描述一个账号,保证了与账号位置相关特征的完整性。
38.时间序列特征是根据用户在社交媒体上发布信息时间所统计出的特征。在实际中,用户发布信息的时间和用户位置是密切相关的。因为用户在不同的位置所属不同的时区,在不同的时区又有不同的作息规律。例如国内的用户,一般在北京时间21:00到2:00发送的信息较为频繁,而在2:00到6:00一般用户都处于睡眠阶段,其在社交网络中活跃的程度就相对较低。通过账户消息时间的统计分布,就可以反向推断出账户所在的时区位置。如图2所示,通过统计账户在24个小时段中发送推文的频次分布,可以得到用户在实际生活中一天的活跃时间段,也就是该账户的时间序列特征,共24维。
39.名称词缀特征是根据账户用户名字段进行词缀拆分得到的词袋特征。受地域的影响,用户在为自己账户命名时会结合当地语言文化特色进行命名。如图3所示,中国账户命名以汉字拼音为主,而国外用户以英语单词为主,两套命名体系基本的词缀单元是不一样的。因此我们可以对一个账户的用户名进行二元词缀和三元词缀的分解,即将一个账号表示为多个二元词缀或三元词缀的组合,将该组合作为账户的名称词缀特征。
40.实体语义特征由用户消息内容中地理实体、话题词汇以及个人描述三个子部分构成。社交媒体中,位置不同的账户讨论的地点、话题以及个人描述也不同。例如,国内账户更关心与本国相关的话题和地点,而国外账户更关心属于它们本国的话题和地点。此外,国内账户在个人描述中所介绍基本概况也是和国内位置高度相关的。因此,将消息内容中的地点和话题特征,以及个人描述中的语义信息作为实体语义特征。值得注意的是,在这里我们并没有直接将所有消息内容作为账户特征,这是因为账户消息内容噪声信息较多,我们只选择其中的话题和地点词汇作为账户特征不仅能够最大程度的保留消息内容中与位置相关的信息,还能去除其它无关噪声的影响。
41.图4所示是一个国内账户中实体语义特征的实例,红色标注的beijing就是该账户消息内容中的地点词汇,绿色标注的#sunny为消息中提炼的话题词汇(由发送者自己填
写),而个人描述则反映了账号的基本概况。我们将这三种信息共同作为实体语义特征。其中,地点、话题特征由高频词汇构成的词袋模型进行表示,而个人描述中的语义信息用平均词嵌入的方式来表示,本发明选用word2vec进行词嵌入计算,word2vec词嵌入后的个人语义信息特征维度为200。
42.s3、将提取的特征输入多模态融合判别网络,实现账号位置的识别。在提取账户三种正交且与位置高度相关的模态特征后,需要进一步对这些特征进行融合分析,从而实现用户位置的准确识别。本发明基于提取的多模态特征,提出了一种新的多模态特征融合模型——融合判别网络模型,将三种模态特征输入到构建的多模态融合判别网络模型中,该判别网络模型会对三种不同模态特征的数据做统一处理,并计算模态间的高维关联特征,最后该融合判别网络会将三种模态特征及其高维的关联特征一起进行集成学习训练,并最终输出账号的位置信息。
43.对于融合判别网络的设计,本发明考虑了三部分因素。首先,融合判别网络结构必须能够适应多种模态特征的输入;其次,该网络结构能够充分学习到各种模态特征中的信息以及模态特征之间的联系。最后,网络分类器要尽可能综合和完善。针对第一个因素,本发明采用平行输入的策略。针对第二个因素,我们采用张量融合加前端融合的混合融合方式,让模型充分学习多种模态自身以及它们间的关联特征。针对第三个因素,本发明采用集成学习的策略,将多个弱分类器进行关联学习,最终形成一个综合完善的强分类器。具体的融合判别网络结构如图5所示。多模态融合判别网络的识别过程包括以下子步骤:
44.s31、本发明采用平行输入的策略,即将时间序列特征、名称词缀特征、实体语义特征作为平行特征输入到融合判别网络中;将三类平行的模态特征输入分为两大部分,第一个部分是由时间序列特征、名称词缀特征和地点话题特征组成的可降维特征部分,第二部分则由不可降维的描述语义特征单独构成。之所以不对语义特征进行降维处理,是因为词嵌入维数已经由训练时决定,再次降维将破坏词嵌入的训练特性。
45.s32、将时间序列特征、名称词缀特征、地点和话题特征分别输入pca降维模块进行降维处理;
46.进行平均词向量处理的描述语义特征,后面括号的数字是降维后该特征的维数。
47.s32、将降维处理后的特征通过张量融合的方式进行特征融合;
48.s34、将张量融合后的特征与个人描述中的语义信息特征进行前端融合;
49.s35、将前端融合后的特征通过梯度提升树模型来拟合最终特征。
50.在混合融合方面,由于本发明要挖掘特征自身以及特征间的关联关系,于是借用张量融合和前端融合混合融合的方式处理多种模态特征。其中,张量融合用于第一部分可降维的特征间的融合,而前端融合用于将张量融合后的结果与第二部分不可降维特征进行再次融合。
51.考虑到张量融合会导致最后的融合向量维度激增,使分类器失去学习能力。于是,采用pca降维的方式预先对第一部分特征进行降维,然后再进行张量融合,降维后的时间序列特征、名称词缀特征和地点话题特征维度分别为7、7、30。之所以不先融合再进行降维处理,是因为张量融合属于特征间的线性变换,先融合再降维由于特征间线性相关的特性会导致特征消失,因此采用先降维后融合的方式。其中,张量融合公式如下:
[0052][0053]
分别表示时间序列特征、名称词缀特征和地点话题特征;其中,地点话题特征是由地点特征和话题特征进行拼接处理形成的;
[0054]
通过上述变换可以得到时间序列特征、名称词缀特征以及地点话题特征在张量空间的融合特征,如图6所示。
[0055]
经过张量融合后,不仅包含了原有的时间序列特征、名称词缀特征以及地点话题特征。还包含了这些特征之间的二维关系特征以及三维关系特征。我们将由张量融合后的特征与之前的第二部分描述语义特征再次进行前端融合就得到了最终融合特征。
[0056]
在分类器选择方面,考虑到单一分类器的学习偏好以及有限的学习能力,本发明并没有选用朴素贝叶斯、支持向量机这些单一分类器进行训练,而是采用集成学习中的梯度提升树模型来拟合最终特征。该模型在每一轮会产生一个弱分类器模型(一般选用回归树模型),并在上一轮弱分类器的残差上继续训练,达到逐步优化的目的,最终将多个弱分类器通过加法模型的方式拼接起来得到最终的集成模型。最终特征通过已训练的梯度提升树模型最终就可以输出账号位置。
[0057]
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。