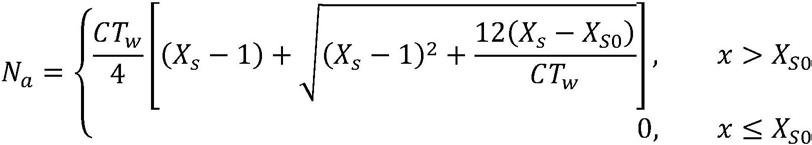1.本发明涉及智能交通信号灯技术领域,具体涉及一种基于树莓派智能配时交通信号灯控制方法。
背景技术:
2.交通拥堵是许多城市的通病,给城市中的生活人们造成很多不便,传统的信号灯时间控制不合理、故障、失效频发,导致交通事故、工时损失、噪音污染、空气污染、燃油增加、违法交通规则等诸多问题,在上下班的高峰时期段,经常需要多名交警进行现场指挥,增加人力物力成本,但上述事故频频发生,为了避免上述情况,
3.例如,中国发明专利申请号201811079047.6公开了一种基于树莓派的城市交通智能管理系统,包括:高清摄像头以及树莓派计算机,所述高清摄像头与树莓派计算机通讯连接,本设计方案使用人工智能算法采用了基于密度的方法来控制车辆交通,交通信号灯计时会在交汇感知交通密度状态自动改变,所提出的系统将使用树莓派结合高清摄像头,搭建神经网络分析预测,自动改变道路交界点交通信号灯的时间以适应车辆的移动及稀密状态,从而避免在道路交界处不必要的等待时间,该方案无法预测下一时段整条道理上的车流量,进行调整预测时间,完成交通灯的智能配时。
技术实现要素:
4.针对上述的不足,本发明采用智能配时交通信号灯,在保证信号灯进行精准控时下,还可实时根据路况、车况进行信号灯的调控,即智能配时交通信号灯短期预测下一时段整条道路上的车流量分析、效验调整,配时现有道路上车辆通行时间,实时进行预测、调整时间,完成交通信号灯的智能配时。
5.为实现上述目的,本发明提供如下技术方案:
6.一种基于树莓派智能配时交通信号灯控制方法,包括如下步骤:
7.步骤1,利用若干个高清摄像头实时采集道路状况和车辆信息,采集信息压缩为h264格式传输至树莓派计算机中;
8.步骤2,在树莓派计算机系统中利用差分自回归移动平均模型预测小时车流量;
9.步骤3,预测设定周期的车辆数,通过存储的历史数据形成两个时间序列,两条时间序列分别采用步骤2中的模型,利用差分法实现数据的平稳性操作,然后对模型参数(p,d,q)进行定阶,利用bic准则确定最优模型,之后对模型进行标准化残差检验,确定模型的可信度,对下一时段的车流量进行预测,并比较两条时间序列产生的标准化残差,选取最小的结果作为车流预测的最终结果;
10.步骤4,采用上述步骤3预测的得到的车流量、视频检测分析的数据,以使用过渡延误模型求得最小延误时间为目标,利用遗传算法对路口的信号灯进行精准配时。
11.本发明技术方案的进一步改进在于:步骤1中,通过树莓派opencv对信息进行操作,捕获信息中的车辆,再追踪信息中连续帧的车辆,最后对追踪的车辆进行计数分类。
12.本发明技术方案的进一步改进在于:步骤3中,所述两个时间序列,一种是根据当前需要预测周期的前10个周期形成的时间序列,另一种是根据当前时间节点获取数据库中同一时间节点不同日期的十条车流量数据形成时间序列。
13.与现有技术相比,本发明提供的一种基于树莓派智能配时交通信号灯控制方法有益效果如下:
14.1.本发明提供一种基于树莓派智能配时交通信号灯控制方法,该方法在保证信号灯进行精准控时下,根据路况、车况进行信号灯的调控,短期预测下一时段整条道路上的车流量,实时进行预测、调整时间,完成交通信号灯的智能配时。
具体实施方式
15.下面将通过具体实施方式对本发明的技术方案进行清楚、完整地描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
16.所述一种基于树莓派智能配时交通信号灯控制方法,包括如下步骤:
17.步骤1,利用若干个高清摄像头实时采集道路状况和车辆信息,采集信息压缩为h264格式传输至树莓派计算机中;
18.本实施例中,采用高清摄像头实时采集道路状况视频,视频压缩成h264格式传输至树莓派计算机;通过树莓派opencv对视频流进行背景扣除操作,捕获视频流中的车辆,再追踪视频中连续帧的车辆,最后对追踪的车辆进行计数分类;
19.具体步骤如下:
20.1.高清摄像头模块通过csi接口与树莓派连接,进行视频传输;
21.2.在树莓派计算机内部使用命令安装所有最新功能和驱动程序以更新操作系统,能正确访问互联网:$sudo apt
‑
get update#此命令使用最新功能和驱动程序更新操作系统,$sudo raspi
‑
config raspi
‑
config#打开由raspbian操作系统编写和维护的配置工具;
22.3.$raspivid
‑
o video.h264
‑
t 1000用以捕获以h264编码的视频t秒;
23.4.为了检测车辆,采用背景扣除方式从道路上有车辆的另一个图像中减去没有车辆的道路图像,背景扣除是从原始图像中提取目标图像的过程;公式如下:
24.target(x,y)=(1
‑
alpha)﹒target(x,y) alpha﹒origin(x,y)
25.其中,origin(x,y)是原始图像为彩色或灰度图像的8位或32位浮点数;target(x,y)是图像的32位或64位浮点;alpha是输入图像的权重;更新速度由alpha决定,在现有帧中为此变量设置了一个较低的值;
26.5.车辆追踪,跟踪的主要目标是确定视频连续帧中的目标对象,对于跟踪当前对象,将输入质心与现有对象质心进行匹配,并计算每对对象之间的距离,如欧几里得距离;
27.6.车辆分类计数,所跟踪的车辆在离开路口或在越过路口停车线时被计数,为了对每个相位上的车辆进行计数,对每条车道停车线处到视频拍摄尾部使用计数线划车辆计数区域,对每个交叉口分为4个相位,分别为南北直行加右转、南北左转、东西直行加右转、东西左转;计数的车辆基于周长进行分类,如果边界框的周长小于300,则将其计为自行车;
如果边界框的周长小于500,则将其计为汽车,并且如果边界框的周长大于500被计为卡车/公共汽车;
28.7.将得到的车辆数据包括车辆类型、数量、车辆间距等数据以四个相位分开以每个信号周期为时间单位编辑表格存入阿里云mysql中,且存入之后对车辆类型进行统一标准转换(以4
‑
5座的小汽车为标准车),换算系数如下表:
29.车辆类型换算系数自行车0.4小汽车1.0卡车/公共汽车1.5
30.步骤2,在树莓派计算机系统中利用差分自回归移动平均模型预测小时车流量;
31.本实施列中采用差分自动回归移动模型(arima);
32.1.自回归模型(ar):描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测;p阶自回归过程的公式定义:
[0033][0034]
2.移动平均模型(ma):移动平均模型关注的是自回归模型中误差项的累加;q阶自回归过程的公式定义:
[0035][0036]
3.差分自回归移动平均模型(arima):ar是自回归,p为自回归项,ma为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数;
[0037][0038]
式中:y
t
是当前预测值,μ是常数项,p、q为阶数,γ
i
与θ
i
是自相关系数,y
t
‑
i
为序列前几个数据,∈
t
为误差;
[0039]
4.模型构建步骤如下:
[0040]
4.1.数据预处理
[0041]
原始交通流量数据序列为{b(t)},一般来讲它是非平稳的,将它差分,即令
[0042]
y
n
=b(t
‑
n)b(t),
[0043]
定义
[0044][0045][0046]
其中,为组合系数;{b(t)}的d阶差分为arma(p,q)序列,那么我们称{b(t)}为(p,d,q)阶的差分自回归移动平均模型,记为arima(p,d,q);
[0047]
4.2.差分序列的稳定性判定
[0048]
采用daniel趋势检验法,将时间序列按照时间周期进行排序得到y1,y2,
…
,y
n
(按年排列的序号),将时间值按从小到大进行排序得到相应序号x1,x2,
…
,x
n
,统计检验所应用
的秩相关系数为:
[0049][0050]
式中:d
i
=x
i
‑
y
i
;n为数据量。
[0051]
4.3.p和q阶数通过自相关函数(acf)与偏自相关函数(pacf)确定:
[0052]
4.3.1.自相关函数acf:
[0053]
有序的随机变量序列与其自身相比较自相关函数反映了同一序列在不同序列的取值的相关公式:
[0054][0055]
变量与自身的变化,y
t
和y
t
‑1到y
t
和y
t
‑
k
的相关系数,k阶滞后点,ρ
k
的取值范围[
‑
1,1];
[0056]
4.3.2.偏自相关函数(pacf):
[0057]
对于一个平稳ar(p)模型,求出滞后k自相关系数p(k)时,实际上得到的并不是x(t)与x(t
‑
k)之间单纯的相关关系。x(t)同时还会受到中间k
‑
1个随机变量x(t
‑
1)、x(t
‑
2)、
…
x(t
‑
k 1)的影响,而这个k
‑
1个随机变量又都和x(t
‑
k)具有相关关系,所以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t
‑
k)的影响,剔除了中间k
‑
1个随机变量x(t
‑
1)、x(t
‑
2)、
…
x(t
‑
k 1)的干扰之后,得到x(t)与x(t
‑
k)影响的相关程度;
[0058]
4.3.3确认方法,如下表格:
[0059][0060]
截尾:落在置信区间内,ar(p)看pace,ma(q)看acf;
[0061]
4.4.最优模型选择:通过bic准则弥补根据自相关函数和偏自相关函数定阶的主观性,在有限的阶数范围内帮助寻找相对最优拟合模型,贝叶斯信息准则是用于模型选择的常用准则,一般选择具有最小bic值的模型,
[0062]
bic定义为:bic(t)=log(n)t
‑
2log(l)
[0063]
式中:t为模型中参数的个数,l为模型的极大似然函数;
[0064]
在arima模型的情况下,根据上述得到的p与q的值,得到p∈[0,p],q∈[0,q],d=d.,可以匹配出m
n,
n=1,
…
,p*q个模型,假设每个备选模型的参数为θ
n
,参数θ
n
的先验分布为pr(θ
n
|m
n
),则给定数据之后,m
n,
的后验概率为:
[0065]
pr(m
n
|b)
∝
pr(m
n
)pr(b|m
n
)
[0066]
∝
pr(m
n
)*∫pr(b|θ
n
m
n
)pr(θ
n
|m
n
)dθ
n
[0067]
不同的两个模型m
n
和m
l
,我们比较它们的后验概率:
[0068][0069]
上述比值大于1,我们就选择模型m
n
,上式中的
[0070][0071]
称为贝叶斯因子,它度量了训练集对后验概率的贡献,
[0072]
一般地,我们假设关于不同模型的先验分布是相同的,基于所谓laplace近似可得:
[0073][0074]
式中:表示参数的极大似然估计,d
n
表示θ
n
的维数,
[0075]
乘以(
‑
2)可得bic,bic值越小说明模型越可取;
[0076]
4.5.模型标准化残差检验
[0077]
检验模型的残差是否是平均值为0且方差为常数的正态分布。所谓残差是指观测值与预测值(拟合值之间的差),即观测值b
t
与根据模型预测出来的值之差,用e表示,对于ε正态性的检验,可以通过标准化残差分析完成,标准化残差是残差除以其标准差后得到的数值,也称pearson残差,用r
e
表示,因此第i个观察值的标准化残差为:
[0078]
(s
e
是残差的标准差估计)
[0079]
如果标准化残差的分布服从正态分布,则误差项ε服从正态分布,大约有95%的标准化残差落在(
‑
2,2)之间;
[0080]
步骤3,预测设定周期的车辆数,通过存储的历史数据形成两个时间序列,两条时间序列分别采用步骤2中的模型,利用差分法实现数据的平稳性操作,然后对模型参数(p,d,q)进行定阶,利用bic准则确定最优模型,之后对模型进行标准化残差检验,确定模型的可信度,对下一时段的车流量进行预测,并比较两条时间序列产生的标准化残差,选取最小的结果作为车流预测的最终结果;
[0081]
本实施列中,需要预测某个周期的车辆数目,通过存储的历史数据形成两个时间序列,一种是根据当前需要预测周期的前10个周期形成的时间序列,另一种是根据当前时间节点获取数据库中同一时间节点不同日期的十条车流量数据形成时间序列。两条时间序列分别利用上述模型,利用差分法实现数据的平稳性操作,然后对模型参数(p,d,q)进行定阶,利用bic准则确定最优模型,之后对模型进行标准化残差检验,确定模型的可信度,然后对未来的小时时段的车流量进行预测。比较两条时间序列产生的标准化残差,选取最小的结果作为车流预测的最终结果;
[0082]
步骤4,采用上述步骤3预测的得到的车流量、视频检测分析的数据,以使用过渡延误模型求得最小延误时间为目标,利用遗传算法对路口的信号灯进行精准配时;采用如下
步骤:
[0083]
1.过渡延误模型:
[0084]
1.1.本模型使用的参数:c:信号周期时长;g
g
:绿灯时间;g
r
:红灯时间;
[0085]
λ:进口道方向绿信比,计算公式:λ=g
g
/c;q
a
:进口道实际交通到达流量;q:道路通行能力;s:道路饱和流量;y:进口道交通流量比,计算公式:y=q
a
/c;x
s
:进道口方向饱和度,计算公式:t
w
:观测所设定时间;d
u
:车辆平均延误时间;d
r
:车辆随机到达延误时间;n
a
:平均滞留车辆数;
[0086]
x
s0
:交叉口饱和度临界值;
[0087]
1.2.过渡延误模型:
[0088]
车辆平均延误时间,计算公式如下:
[0089][0090]
车辆随机到达延误时间,计算公式如下:
[0091][0092]
其中,平均滞留车辆数与交叉口饱和度临界值,计算公式如下:
[0093][0094][0095]
1.3.对过渡模型进行优化:根据交叉口路况的评价指标可以得知,为了缓和交通压力,获得最优的信号配时,一方面要提高道路的通行能力,另一方面要降低平均延误时间,因此获得如下目标函数:
[0096][0097]
对于多目标问题,一般要转换为但目标进行优化,因两个参数指标的单位不同,对两者进行无量纲化处理,得到多目标联合优化函数:
[0098][0099]
式中:d0为车辆在交叉口的初始总平均延误时间;q0为交叉口的初始通行能力;β为
交叉口的平均延误时间的权重;
[0100]
1.4.对优化模型进行修正:为了使车辆减少在各个交叉口上的停车时间,将一条干道上一批相邻的信号交叉口连接起来进行协调控制,生成干线交叉口协调控制系统,简称线控。基于此思路,对多目标联合优化函数进行修正,达到线控目的。引入一个可变参数γ对原始的平均延误时间进行修正,以达到强调干线重要性的目的,修正后的平均延误时间模型,计算公式如下:
[0101][0102]
式中:n为能够疏散干道上车辆相位的集合n的元素个数,γ
i
为集合,n中相位i的修正系数;
[0103]
修正后的目标函数:
[0104][0105]
1.5.模型约束条件,包括如下步骤:
[0106]
1.5.1.信号周期
[0107]
若信号周期取太短,则导致车辆在路口频繁启动停止,若周期取太长,则会导致车辆等待时间过长,增加了车辆的延误时间,因此存在约束:
[0108]
c
min
≤c≤c
max
[0109]
1.5.2.绿信比约束
[0110]
某一信号相位绿信比越大,表示该相位绿灯时间越长,则其他相位绿灯时间就会减少,为了协调各相位车辆顺利通过交叉口,因而设定上下限,且上限不能大于1:
[0111]
λ
min
≤λ
j
≤λ
max
<1,λ
j
=g
g,j
/c
j
[0112]
式中:g
g,j
为第j,相位的绿灯时间;
[0113]
1.6.综上,修正后的过渡延误模型,计算公式如下:
[0114][0115][0116]
1.7.进行修正时涉及一个相位修正参数γ,通过公式γ=eμ 1来计算,其中μ为比率;
[0117]
1.8.令权重β=0.5,利用遗传算法求解,得到配时优化方案;
[0118]
2.利用遗传算法求解:
[0119]
2.1.根据第一阶段预测得到的下一周期相邻两路口a与b各个方向的进出车辆数目,采用二进制编码方法,随机产生预定种群数目的染色体。设定周期值、种群数目、染色体长度、迭代总代数;
[0120]
2.2.设置适应度函数,设目标函数为j,表示交叉口平均延误时间,需要求得最小值,适应度函数用z表示,其表达式为z=o
max
‑
j,其中o
max
为最大估计值;
[0121]
2.3.计算筛选适应函数,求出接触当前中种群中的适应度z
t
,t代表当前种群代数。对z
t
中的数据进行处理,其中为第t代种群中的适应度的最大值;
[0122]
2.4.根据比例选择法,对处理后的z
t
对应的染色体进行处理,选出染色体组作为新的种群,第n条染色体被筛选出来的概率为
[0123]
2.5.按照预定的交叉率在候选解群体中随机抽取数对候选解进行交叉操作;
[0124]
2.6.按照预定的杂交、变异率抽取候选解进行交叉、变异操作;
[0125]
2.7.计算每个候选解的目标函数值,根据所选的淘汰率淘汰候选解中目标函数值最差者,所缺位置从目标函数较好的解中产生;
[0126]
2.8.判断是否到预定迭代次数,如果是则继续下一步,否则转入第2.5步骤重复此步骤计算;
[0127]
2.9.计算各相位最优配时。
[0128]
以上所述的实施例仅仅是对本发明的优选实施方式进行描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明装置权利要求书确定的保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。