1.本发明涉及视频图像处理、目标检测、多目标追踪、深度学习领域,尤其是涉及一种基于图像序列的行人行为类别检测方法。
背景技术:
2.随着当今社会的发展推进,为了节约人力资源和资金成本,摄像头在各个领域都得到广泛的应用,获取的视频信息可以帮助我们高效的获取我们需要的信息。行为识别action recognition是指对视频中人的行为动作进行识别,即读懂视频。比如说在单行道上出现逆向行驶的车辆,在客厅突然摔倒的老人。通过行为识别,在具体某些行为上可以及时获取这些重要信息。
3.当前在行为识别领域的方法分为基于传统模型和基于深度学习模型两大类。在传统的行为识别模型中,通常都是先提取手工特征(hog,hof,densetrajectories等),然后使用分类器进行分类,idt是传统方法中很经典的模型,dt算法和idt算法的基本框架括密集采样点特征、特征点轨迹跟踪和基于轨迹的特征提取三部分,后续再进行特征编码和分类。基于深度学习模型的方法按照是否先检测人体关键点,基于深度学习的方法可以简单地划分为“skeleton
‑
based”和“video
‑
based”两类。
4.对于大多数的动作都具有不同的表现形式,动作持续的时间也有差别。通过图像获得的信息不足以描述当前的行为信息。而通过视频来作为处理数据,由于视频段的长度不易,而且开放环境下存在多尺度、多目标、摄像机移动等众多问题,这些问题都将导致行为识别未能实用化。基于骨胳轨迹序列的方法在面对复杂场景如遮挡等或者出现复杂动作时这对骨胳点的提取准确度有着很大的要求,人与人之间、人与背景之间的相互遮挡也使得模型对动作分类前期特征提取带来了很大的困难;
技术实现要素:
5.本发明是为了解决上述现有技术存在的不足之处,提出一种基于图像序列的行人行为类别检测方法,以期望能充分利用目标图像序列的空间信息以及时间信息,在保证模型的行为检测准确度的同时,又能使检测速度达到实时的效果。
6.本发明为达到上述发明目的,采用如下技术方案:
7.本发明一种基于图像序列的行人行为类别检测方法的特点包括以下步骤:
8.步骤1:训练测试数据集的采集与处理;
9.步骤1.1:通过监控摄像头采集真实场景的行人活动视频,并将所述行人活动视频进行跳帧处理,获得不同场景下的行人图像帧并进行归一化处理后,用于训练多目标跟踪器;
10.利用训练后的多目标跟踪模型对所述行人活动视频进行跟踪处理,获得第p个目标人物的图像帧序列其中,为第p个目标人物在第t帧中的图像;t表示总帧数;
11.步骤1.2:对图像帧序列中的每帧图像进行类别的标注,从而构建训练数据集;
12.从所述图像帧序列中取长度为n的连续图像帧并构建成一个子序列记y
label
为所述子序列的真实标签;
13.将第p个目标人物在第t帧中的图像进行归一化处理后,得到维度为(c,h,w)的特征图为从而得到特征图序列作为判别网络的输入序列;
14.步骤2:构建基于时空网络的判别模块,所述判别模块由一个卷积神经网络ifenet、一个双向长短期记忆网络以及以一个注意力机制层构成;
15.步骤2.1:所述卷积神经网络ifenet由m个下采样块组成,m个下采样块分别记为downblock1,...,downblock
m
,...,downblock
m
,其中downblock
m
代表第m级下采样块,m=1,2,...,m;其中,第m级下采样块由第m级的一个二维卷积层conv2d
m
、一个batchnormalization层bn
m
以及一个激活函数leakyrelu组成;
16.所述特征图经过卷积神经网络ifenet中m个下采样块downblock1,...,downblock
m
,...,downblock
m
后,得到维度为(c
′
,h
′
,w
′
)特征图从而将所有输出的特征图进行concat聚合并得到维度为(n,c
′×
w
′×
h
′
)的特征矩阵
17.步骤2.2:所述长短期记忆网络lstm为包含hs个隐含层的双向网络;令长短期记忆网络lstm的隐含层数量为v;
18.所述特征矩阵输入所述lstm网络中,并由最后一层隐含层输出所述特征图对应的隐含层特征h
t
;
19.步骤2.3:所述注意力机制层将所述隐含层特征h
t
经过一个激活函数tanh进行处理,从而利用式(1)得到中间输出u
t
:
20.u
t
=tanh(w
w
h
t
b
w
)
ꢀꢀ
(1)
21.式(1)中,b
w
为偏置矩阵,w
w
为根据h
t
所设置的随机参数矩阵;
22.所述注意力机制层对所述中间输出u
t
进行归一化处理,从而利用式(2)得到权重α
t
:
[0023][0024]
式(1)中,为u
t
的转置,u
w
为根据设置的随机参数矩阵;
[0025]
所述注意力机制层利用式(2)对权重α
t
与隐含层特征h
t
进行加权求和后,得到维度为(1,2
×
v)的向量表示s:
[0026][0027]
将所述特征向量s经过softmax层得到子序列的类别概率预测分
布向量为y
pred
;
[0028]
步骤2.4:y
pred
、y
label
分别表示维度为(1,c)类别概率预测分布向量和真实标签,其中c表示类别数,通过式(4)构建基于时空网络判别模块的损失函数loss1:
[0029][0030]
步骤3:构建基于未来帧的预测网络模块;
[0031]
所述预测网络模块是由编码器网络和解码器两个部分组成,所述编码器网络与所述判别模块的结构相同;
[0032]
所述解码器网络是由线性结构层和x个上采样块组成;x个上采样块分别记为upsampleblock1,...,upsampleblock
x
,...,upsampleblock
x
;其中,upsampleblock
x
表示第x级上采样块;
[0033]
当x=1,...,x
‑
1时,所述upsampleblock
x
上采样块由一个装置卷积层convtranspose2d
x
、一个batchnormalization层bn
x
以及一个relu激活函数构成;
[0034]
当x=x时,所述upsampleblock
x
上采样块由一个装置卷积层convtranspose2d
x
和一个sigmoid激活函数组成;
[0035]
步骤3.1:将子序列分为两个部分,选取其中长度为n
‑
1的第一部分子序列作为所述预测网络模块的输入,记所述第一部分子序列的标签i
label
为第t帧中的图像
[0036]
步骤3.2:将第一部分子序列输入到编码器网络中进行处理,并得到维度为(1,2
×
v)的特征向量s
′
;
[0037]
将特征向量s
′
输入到线性结构层中后输出维度为(2
×
v,1,1)的特征图featuremap;
[0038]
所述特征图featuremap经过x个上采样块后得到维度为(c,w,h)的特征矩阵i
pred
;
[0039]
根据预测的特征矩阵i
pred
与真实的标签i
label
,利用式(5)建立损失函数loss2:
[0040][0041]
式(5)中,h,w,c分别表示预测的特征矩阵与标签所对应的图像的高度、图像的宽度以及图像的通道数,j,k,l为三个变量;
[0042]
步骤4:训练预测阶段:
[0043]
步骤4.1:利用式(6)建立反向传播的损失函数l
total
,并通过adam优化器以学习率l
r
对判别模块和预测网络模块进行训练,从而更新网络参数使得损失函数l
total
收敛,并得到最优网络模型;
[0044]
l
total
=loss1 λloss2ꢀꢀ
(6)
[0045]
式(6)中,λ为权重系数,λ∈(0,1];
[0046]
步骤4.2:将子序列输入最优网络模型中,并由训练后的判别模块得到第p个目标人物在t帧的类别概率预测分布向量
[0047]
所述第一部分子序列经过训练后的预测模块网络得到对应的特
征矩阵i
′
pred
;从而利用式(7)获得预测阶段的第p个目标人物在t帧时的行为类别概率分布
[0048][0049]
式(7)中,β为权重参数,且β∈(0,1];f为一个线性操作。
[0050]
与现有技术相比,本发明的有益效果在于:
[0051]
1、本发明利用所获得的前景目标输入到特征提取网络中,而不是输入每一帧的整张图像,通常行为的特征由目标前景产生的,使得模型在对序列提取特征信息时可以有效地避免背景噪声对实验结果的影响,提高了检测精度;
[0052]
2、本发明利用未来帧预测模块和时空网络模块联合训练优化模型,通过两个模块的预测输出作为跌倒检测的参考度量,有助于模型能够应对不同场景下的特殊行为导致的误检,从而提升了模型的准确性;
[0053]
3、本发明attention机制的实现是通过保留lstm编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习,并且在模型输出时,将输出序列与之进行关联,从而使得模型更加关注动作变化的时刻,以便于模型对该序列信息的提取;
[0054]
4、本发明在两个模块中的卷积神经网络都是用了一个包含5层卷积模块的网络ifenet,基于长短期记忆网络的方法主要是从时间序列上处理不同帧之间的变化情况,可专注于人体运动从而忽略静态场景图像,网络深度较浅,且本发明的整体流程实现了端到端的训练和检测,使用少量计算资源和少量样本就能够实现较好的效果,实现了实时的视频目标行为的检测目的。
附图说明
[0055]
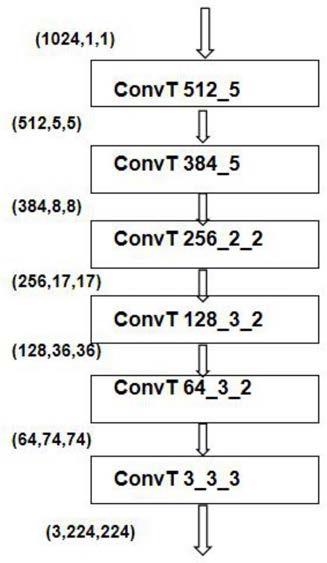
图1为本发明卷积神经网络ifenet网络结构图;
[0056]
图2为本发明解码器decoder的网络结构图;
[0057]
图3为本发明长度为8视频目标图像序列实例;
[0058]
图4为本发明检测模块流程图。
具体实施方式
[0059]
本实施例中,参见图4,一种基于图像序列的行人行为类别检测方法,分别利用时空网络模块以及未来帧预测模块两个网络模块对同一段序列进行处理构造损失函数,对两个模块进行优化学习整合到一个网络结构中。具体如以下步骤:
[0060]
步骤1:训练测试数据集的采集与处理;
[0061]
步骤1.1:通过监控摄像头采集真实场景的行人活动视频,并将行人活动视频进行跳帧处理,获得不同场景下的行人图像帧并进行归一化处理后,用于训练多目标跟踪器;具体实施中,使用普通网络摄像头,放置房间的斜上方,前侧以及后侧。摄像头使用海康威视网络摄像头,型号为ds
‑
2cd1021fd
‑
iw1,视频分辨率为720*480,帧数为15fps。采集人员在房间内活动的视频图像。通过裁减掉视频中长时间没有目标任务以及干扰因素较多的视频片段,保留质量高的视频用作后期的跟踪处理。
[0062]
利用训练后的多目标跟踪模型对行人活动视频进行跟踪处理,获得第p个目标人
物的图像帧序列其中,为第p个目标人物在第t帧中的图像;t表示总帧数;
[0063]
步骤1.2:对图像帧序列中的每帧图像进行类别的标注,从而构建训练数据集;具体实施中,将图像的标签分为四类分别是正常行走、突然加速、摔倒以及跳跃,将四个类别分别用0、1、2、3表示。
[0064]
从图像帧序列中取长度为n的连续图像帧并构建成一个子序列记y
label
为子序列的真实标签;具体实施中,取n=8构建子序列,通过one
‑
hot编码根据四个类别构建子序列标签{0:(1,0,0,0),1:(0,1,0,0),2:(0,0,1,0),3:(0,0,0,1)};
[0065]
将第p个目标人物在第t帧中的图像进行归一化处理后,得到维度为(c,h,w)的特征图为从而得到特征图序列作为判别网络的输入序列;具体实施中,特征图的维度为(3,224,224);
[0066]
步骤2:构建基于时空网络的判别模块,判别模块由一个卷积神经网络ifenet、一个双向长短期记忆网络以及以一个注意力机制层构成;
[0067]
步骤2.1:如图1所示,卷积神经网络ifenet由m个下采样块组成,m个下采样块分别记为downblock1,...,downblock
m
,...,downblock
m
,其中downblock
m
代表第m级下采样块,m=1,2,...,m;其中,第m级下采样块由第m级的一个二维卷积层conv2d
m
、一个batchnormalization层bn
m
以及一个激活函数leakyrelu组成;具体实施中,m=5,如图3所示,第一个下采样模块使用64个大小为7
×
7的卷积核,第二个下采样模块使128个大小为5
×
5的卷积核,第三个下采样模块使256个大小为3
×
3的卷积核,第四个下采样模块使256个大小为3
×
3的卷积核,第五个下采样模块使384个大小为3
×
3的卷积核;
[0068]
特征图经过卷积神经网络ifenet中m个下采样块downblock1,...,downblock
m
,...,downblock
m
后,得到维度为(c
′
,h
′
,w
′
)特征图从而将所有输出的特征图进行concat聚合并得到维度为(n,c
′×
w
′×
h
′
)的特征矩阵具体实施中,维度为(3,224,224)的特征图经过ifenet得到维度为(384,5,5)的输出特征图
[0069]
步骤2.2:长短期记忆网络lstm为单层的双向网络;令长短期记忆网络lstm的隐含层数量为v;具体实施中,v=512;
[0070]
特征矩阵输入lstm网络中,并由最后一层隐含层输出特征图对应的隐含层特征h
t
;
[0071]
步骤2.3:注意力机制层将隐含层特征h
t
经过一个激活函数tanh进行处理,从而利用式(1)得到中间输出u
t
:
[0072]
u
t
=tanh(w
w
h
t
b
w
)
ꢀꢀ
(1)
[0073]
式(1)中,b
w
为偏置矩阵,w
w
为根据h
t
所设置的随机参数矩阵;
[0074]
注意力机制层对中间输出u
t
进行归一化处理,从而利用式(2)得到权重α
t
:
[0075][0076]
式(1)中,为u
t
的转置,u
w
为根据设置的随机参数矩阵;
[0077]
注意力机制层利用式(2)对权重α
t
与隐含层特征h
t
进行加权求和后,得到维度为(1,1024)的向量表示s:
[0078][0079]
将特征向量s经过softmax层得到子序列的类别概率预测分布向量为y
pred
;具体实施中s为通过attention对8个隐含层输出h
t
进行加权求和得到维度为(1,1024)的输出向量s,y
pred
对应四种类别的预测概率分布向量;
[0080]
步骤2.4:y
pred
、y
label
分别表示维度为(1,c)类别概率预测分布向量和真实标签,其中c表示类别数,通过式(4)构建基于时空网络判别模块的损失函数loss1:具体实施中,c=4;
[0081][0082]
步骤3:构建基于未来帧的预测网络模块;
[0083]
预测网络模块是由编码器网络和解码器两个部分组成,编码器网络与判别模块的结构相同;
[0084]
如图2所示,解码器网络是由线性结构层和x个上采样块组成;m个上采样块分别记为upsampleblock1,...,upsampleblock
x
,...,upsampleblock
x
;其中,upsampleblock
x
表示第x级上采样块;
[0085]
当x=1,...,6时,upsampleblock
x
上采样块由一个装置卷积层convtranspose2d
x
、一个batchnormalization层bn
x
以及一个relu激活函数构成;
[0086]
当m=7时,upsampleblock
x
上采样块由一个装置卷积层convtranspose2d
x
和一个sigmoid激活函数组成;
[0087]
步骤3.1:将子序列分为两个部分,选取其中长度为n
‑
1的第一部分子序列作为预测网络模块的输入,记第一部分子序列的标签i
label
为第t帧中的图像具体实施中,取n=8;
[0088]
步骤3.2:将第一部分子序列输入到编码器网络中进行处理,并得到维度为(1,2
×
v)的特征向量s
′
;
[0089]
将特征向量s
′
输入到线性结构层中后输出维度为(1024,1,1)的特征图featuremap;
[0090]
特征图featuremap经过x个上采样块后得到维度为(3,224,224)的特征矩阵i
pred
;
[0091]
根据预测的特征矩阵i
pred
与真实的标签i
label
,利用式(5)建立损失函数loss2:
[0092]
[0093]
式(5)中,h=224,w=224,c=3分别表示预测的特征矩阵与标签所对应的图像的高度、图像的宽度以及图像的通道数,j,k,l为变量值;
[0094]
步骤4:训练预测阶段:
[0095]
步骤4.1:利用式(6)建立反向传播的损失函数l
total
,并通过adam优化器以学习率l
r
对判别模块和预测网络模块进行训练,从而更新网络参数使得损失函数l
total
收敛,并得到最优网络模型;
[0096]
l
total
=loss1 λloss2ꢀꢀ
(6)
[0097]
式(6)中,λ为权重系数根据不同数据集以及需求调节,λ∈(0,1];
[0098]
步骤4.2:将子序列输入最优网络模型中,并由训练后的判别模块得到第p个目标人物在t帧的类别概率预测分布向量s
tp
;
[0099]
第一部分子序列经过训练后的预测模块网络得到对应的特征矩阵i
′
pred
;从而利用式(7)获得预测阶段的第p个目标人物在t帧时的行为类别概率分布score
tp
:
[0100][0101]
式(7)中,β为权重参数根据不同数据集以及需求调节,且β∈(0,1];f为一个线性操作。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。