1.本发明涉及小样本图像分类技术领域,尤其是一种基于记忆力机制和图神经网络的小样本图像分类方法。
背景技术:
2.深度学习的成功源于大量标注数据,而人类只需利用少量的几个样本,就有很好的泛化能力,两者之间的差距引起了人们对小样本学习的研究。与传统的深度学习场景不同,小样本学习的目的不在于对未知样本进行分类,而是在非常有限的标注数据和过往的知识中对新任务快速适应。
3.最近,利用元学习与情景(episode)训练相结合的思想,在解决这一问题上取得了显著的优势。直觉上,使用情景(episode)抽样策略,是一个很有希望的趋势,将知识从已知的类别(即有足够训练样本的已知类别)转移到新的类别(即有少量样本的新类别),模拟人类的学习过程。尽管元学习与episode训练策略在小样本学习上取得了显著的成果,但是它们中的大多数忽略了一个关键性问题,即当一个一个情景(episode)来临训练时,过去所学的知识如何面对新任务。
4.现有技术存在着当面对未知的任务时,学习到的概念无法利用模型进行推理预测。
技术实现要素:
5.本发明的目的是针对现有技术的不足而提出的一种基于记忆力机制和图神经网络的小样本图像分类方法,采用基于信息瓶颈的记忆图增广网络的方法,当面对未知分类任务时,利用图神经网络与记忆机制,使得学习到的概念帮助小样本模型进行推理预测,该方法很好的借鉴人类识别过程,借助学习好的概念知识,较好的实现了利用模型进行推理预测,方法简便,实用性强,具有一定推广应用的前景。
6.实现本发明目的的具体技术方案是:一种基于记忆力机制和图神经网络的小样本图像分类方法,该方法包括:
7.步骤1:预训练阶段
8.1.1)在整个训练集上学习一个有监督的特征提取器和线性分类器;
9.1.2)使用训练好的特征提取器和分类器分别作为元训练阶段编码器和记忆库的初始化,该预训练阶段有助于提取泛化性的特征表达。
10.步骤2:元训练阶段
11.2.1)使用小样本普遍应用的情景训练策略,具体的,考虑一个n
‑
way k
‑
shot t
‑
query任务,其中包含支撑集样本和查询集样本通过编码器提取支撑集样本和查询集样本的特征表示作为任务相关的节点
12.2.2)为了便于快速适应,本发明持有一个记忆库存储支撑集样本的特征表示,使
用类内均值计算支撑集样本中每个类的中心点f
cen
∈r
[n,d]
,将其与存储在记忆库中相同类别的原型点f
p
∈r
[n,d]
进行串接,将串接后的特征表示f
cat
∈r
[n,2d]
输入到一个全连接层以减少维度来提纯语义信息,该迭代更新过程可以被视作一种特殊的知识蒸馏技术,使用信息瓶颈原理(information bottleneck,ib)来提纯,为了确保ib工作良好,即避免与任务无关的干扰,同时保留语义标签信息,所述语义信息由下述1式进行约束:
[0013]
maxi(f
p
,y)
‑
βi(f
cen
,f
p
)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1);
[0014]
其中:i(.,.)表示互信息,y表示标签,β表示拉格朗日系数。
[0015]
具体运用中强制执行下述2式的约束来提纯信息并进一步提纯记忆库:
[0016][0017]
将提纯后的特征表示f
b
∈r
[n,d]
与记忆库相同类别的原型点使用动量的更新方式进一步优化记忆库,具体如下述3式所示:
[0018]
f
p
←
λf
p
(1
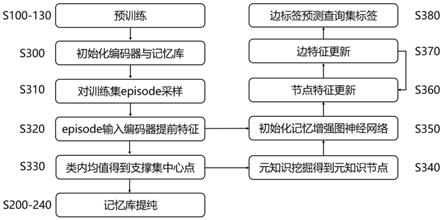
‑
λ)f
b
ꢀꢀꢀꢀꢀꢀꢀꢀ
(3);
[0019]
其中:λ是动量系数。
[0020]
2.3)提纯的原型表示进一步与元知识挖掘结合,这个过程中对于每个类中心点,首先计算该类中心点与记忆库中每个原型点之间的余弦相似性,选择与中心点最近的k个原型点mk={m1,m2,...,m
k
},接着将k个原型点都与中心点拼接输入到一个聚合网络,将k个原型点的信息进行聚合,其输出作为该类的元知识节点,进一步扩充支撑集,作为该类别的伪样本,具体如下述4式所示:
[0021][0022]
其中:[.,.]是拼接操作;f(.;θ
agg
)执行一个转换:r
2d
→
r
d
由一个全连接层组成,其参数化为θ
agg
。
[0023]
另外,a
j
为m
j
和f
cen
[i]的相关性系数,如下述5式所示:
[0024][0025]
其中:τ为温度系数;〈.,.〉为余弦相似度。
[0026]
2.4)将任务相关节点和元知识节点一起构造一个全连接的图g=(v,e),其中,2.4)将任务相关节点和元知识节点一起构造一个全连接的图g=(v,e),其中,每个节点代表一个样本的特征,边表示两个节点的相似性,两个节点来自同一个类则为1,否则为0,由于查询集样本标签信息未知,将与查询集相连的边初始化为0.5,具体如下述6式:
[0027][0028]
其中:为扩充元知识节点后的支撑集。
[0029]
2.5)对记忆增强的图神经网络每一层节点特征和边特征进行更新,给定前一层的节点特征和边特征,通过领域聚合过程更新节点特征,边的特征基于更新的节点特征重新计算,所述节点特征的更新规则如下述7式:
[0030][0031]
其中:[.,.]是拼接操作;为记忆增强模块的第层;f
node
(.;θ
node
)为节点更新网络,参数化为θ
node
。
[0032]
所述边特征的更新规则如下述8式:
[0033][0034]
2.6)经过多层增强的图神经网络的更新,每个查询集节点属于某个类的概率可以被计算为:所有同类的支撑集节点与查询集节点边的值求和,具体如下述9式:
[0035][0036]
其中:δ(y
i
=c
k
)为克罗内克函数,当y
i
=c
k
,值为1,否则为0。
[0037]
2.7)在元训练阶段,为了确保查询集准确预测,优化目标为下述10式表示的最小化二元交叉熵损失函数
[0038][0039]
其中:e
i
和分别表示预测的查询集边标签和真实的查询集边标签;是第层的权重系数;bce表示二元交叉熵损失。为了使元知识节点与预测的标签保持一致,还引入了另一种二元交叉熵损失函数来估计元知识节点边标签的真值与预测之间的差异。
[0040]
所述另一种二元交叉熵损失函数为下述11式所示:
[0041][0042]
其中:e
i
和分别表示预测的元知识边标签和真实的元知识边标签;是第层的权重系数;bce表示二元交叉熵损失。
[0043]
最终的优化目标为下述12式表示的损失函数
[0044][0045]
其中:α和β为平衡系数,α=0.2,β=0.01。
[0046]
步骤3:元测试阶段
[0047]
3.1)元测试阶段与元训练节点类似,但所有模块和记忆库不更新,episode采样训练策略的样本来自测试集。
[0048]
所述步骤1在整个训练集上学习一个有监督的特征提取器和线性分类器,使用训练好的特征提取器和分类器分别作为元训练阶段编码器和内存库的初始化,该预训练阶段有助于提取泛化性的特征表达。
[0049]
所述步骤2使用小样本普遍应用的情景训练策略,具体的,考虑一个n
‑
way k
‑
shot t
‑
query任务,通过编码器提取支撑集样本和查询集样本的特征表示作为任务相关的节点。
[0050]
所述步骤2为了便于快速适应,建立了一个记忆库存储支撑集样本的特征表示,使用类内均值计算支撑集样本中每个类的中心点,并将其与存储在记忆库中相同类别的原型
点进行串接,将串接后的特征表示输入到一个全连接层以减少维度来提纯语义信息,该迭代更新过程可以被视作一种特殊的知识蒸馏技术,接着将提纯后的信息与记忆库对应类别的信息使用动量的更新方式进一步优化记忆库。
[0051]
所述步骤2在元知识挖掘,对于每个类中心点,首先计算该类中心点与记忆库中每个原型点之间的余弦相似性,选择与中心点最近的k个原型点mk={m1,m2,
…
,m
k
},接着将k个原型点都与中心点拼接输入到一个聚合网络,将k个原型点的信息进行聚合,其输出作为该类的元知识节点,进一步扩充支撑集,作为该类别的伪样本。
[0052]
所述步骤2将任务相关节点和元知识节点一起构造一个全连接的图,其中,每个节点代表一个样本的特征,边表示两个节点的相似性,两个节点来自同一个类则为1,否则为0,由于查询集样本特征不知道标签信息,将与查询集相连的边初始化为0.5。
[0053]
步骤2所述记忆增强的图神经网络每一层包含节点特征更新和边特征更新,给定前一层的节点特征和边特征,通过领域聚合过程更新节点特征,边的特征基于更新的节点特征重新计算。
[0054]
所述步骤2记忆增强的图神经网络每一层包含节点特征更新和边特征更新,为了使元知识节点与预测的标签保持一致,还引入了另一种二元交叉熵损失函数来估计元知识节点边标签的真值与预测之间的差异。
[0055]
本发明与现有技术相比具有借鉴人类识别过程,基于信息瓶颈的记忆图增广网络,能借助学习好的概念知识,较好的帮助模型进行推理预测实,方法简便,实用性强,具有一定推广应用的前景。
附图说明
[0056]
图1为本发明流程图;
[0057]
图2为预训练流程图;
[0058]
图3为记忆库提纯流程图。
具体实施方式
[0059]
本发明包括三个步骤:第一步为预训练,在训练集上训练一个有监督的特征提取器和一个线性分类器,并将训练好的特征提取器和分类器作为后续编码器和记忆库的初始化权值;第二步为元训练,首先通过编码器提取支撑集和查询集样本的特征,将其作为任务相关节点,为了使模型快速适应新任务,本发明建立一个记忆库来存储支撑集样本的特征,该记忆库采用一种新的更新方式进行优化,以逐步提纯判别性信息,最后从记忆库中挖掘每个类相关信息作为元知识,并通过一个图神经网络来传播任务相关节点以及元知识之间的相似性;第三步为元测试,与第二步相似,通过任务相关节点和元知识结点得到分类结果,在元测试过程中,记忆库和其他模块不会被更新。
[0060]
以下结合附图和具体实施方式对本发明作进一步的详细说明。
[0061]
实施例1
[0062]
参阅图1,本发明利用图神经网络与记忆机制,借助学习好的概念知识帮助小样本模型进行推理预测,具体操作步骤如下:
[0063]
s300:由预训练阶段得到训练好编码器和分类器,将编码器和分类器分别作为元
训练阶段的特征提取器和记忆库的初始化。
[0064]
s310:采用episode采样策略,从训练集中采样n个类,每个类k个样本作为支撑集,再从同样的n个类中,每个类采样1个样本作为查询集。
[0065]
s320:将步骤s310采样的支撑集和查询集输入特征提取器得到每个样本的特征表示。
[0066]
s330:将支撑集样本特征做类内均值,得到这n个类的类中心点,并参照步骤s200~s240动态更新记忆库。
[0067]
s340:用步骤s330得到的类中心点,去记忆库中检索每个类中心点的k近邻,并用余弦距离计算每个中心点与k近邻的相似程度,将中心点与每个k近邻进行拼接输入到到一个网络进行降维,最后使用加权求和的方式将k近邻进行聚合得到每个类的元知识节点。
[0068]
s350:将步骤s320得到的每个样本特征和步骤s340得到的元知识节点构造一个全连接图,将样本特征与元知识节点作为记忆增强图神经网络节点的初始化,边表示两个节点的相似性,两个节点来自同一个类则为1,否则为0,由于查询集样本特征不知道标签信息,将与查询集相连的边初始化为0.5。
[0069]
s360~s370:将步骤s350初始化完成后,进行节点特征更新和边特征更新,记忆增强的图神经网络每一层包含节点特征更新和边特征更新,给定前一层的节点特征和边特征,通过领域聚合过程更新节点特征,边的特征基于更新的节点特征重新计算边的特征。
[0070]
s380:经过步骤s370~s380节点特征和边特征更新,利用边特征预测查询集样本的标签,每个查询集节点属于某个类的概率可以被计算为:所有同类的支撑集节点与查询集节点边的值求和。
[0071]
参阅图2,第一步骤中的预训练是从训练集中采样训练一个有监督的特征提取器与分类器,具体操作步骤如下:
[0072]
s100:在训练集中随机采样一个batch,包含n个样本以及标签;
[0073]
s110:将n个样本输入到一个特征提取器中,得到n个样本的特征;
[0074]
s120:将n个样本特征输入到一个分类器中,得到每个样本的类别的概率分布;
[0075]
s130:将概率最大的类别作为预测的标签,并计算交叉熵损失函数,进行反向传播更新特征提取器与分类器权重参数。
[0076]
参阅图2,第二步步骤中对记忆库的提纯,利用当前任务支撑集对记忆库进一步的提纯更新,具体步骤如下:
[0077]
s200:将支撑集样本输入当编码器得到样本特征,并使用类内均值得到支撑集样本中每个类的中心点;
[0078]
s210:根据支撑集样本的类标签找记忆库对应类的原型点;
[0079]
s220:将每个类的原型点与中心点进行拼接得到一个更高维的样本特征;
[0080]
s230:将每个类的高维特征输入到一个ib层进行降维,之后将每个类ib层的输出与原型点动量更新对应类别的记忆库。
[0081]
以上只是对本发明作进一步的说明,并非用以限制本专利,凡为本发明等效实施,均应包含于本专利的权利要求范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。