一种高效处理gpu片内和片间缓存一致性的数字电路设计方法
技术领域
1.本发明属于数字电路技术领域,具体涉及一种高效处理gpu片内和片间缓存一致性的数 字电路设计方法。
背景技术:
2.早期gpu既不频繁同步也不共享数据,而是通过把线程信息和缓存结构暴露给程序员, 让程序员在没有硬件一致性的情况下,通过软件实现同步和数据共享。现在,gpgpu越来越 流行。技术人员开始用gpu架构做通用的任务(general purpose workloads)。这类任务需要频 繁的同步和更普遍的数据共享,因此gpu的架构需要有一个能保证所有线程可以同步的直 观、严格的访存一致性(consistency)模型。此外要有又能确保访存一致性正确又能允许数据高 效共享和同步的缓存一致性(coherency)协议。同时这个协议要保证足够简单能过够满足图 形任务占主导的传统gpu架构。
3.lrcc(lazy released consistency
‑
direct coherence)是一种适合gpu实现数据同步和共 享的缓存一致性协议。该协议主要基于“生产者
‑
消费者”访存一致性模型,通过acquire
‑
release (消费者
‑
生产者)机制实现片内l1缓存之间的数据共享和同步。同步发生在消费者去试图 获取(acquire)生产者已经释放(release)的flag,作为生产者一侧的l1缓存在发生同步时 把缓存内已更新的共享数据写回到消费者可见的点(一般是公共可见的l2缓存),而作为消 费者一侧的l1缓存则需要在完成同步时无效缓存内旧的数据,以避免后续访存请求仍旧读到 过时的缓存数据,而是可以从同步点读取到最新的数据。l2缓存作为l1缓存共享数据的同 步点,负责记录缓存行的状态
‑‑
归属情况,当发生同步时,作为生产者、消费者的桥梁,通 过请求交互,来指示生产者、消费者的l1开始数据同步及完成数据同步。其中l1在lrcc 协议中的逻辑行为如图1所示,l2在lrcc协议中的逻辑行为如图2所示。图中的getv和 geto是lrcc定义的两种类型的读请求,getv不要求获得该地址的所有权(owner),geto 需要获得该地址的所有权。具体lrcc协议缓存一致性数据同步流程如图3所示。
技术实现要素:
4.本发明所要解决的技术问题是针对上述现有技术的不足,提供一种高效处理gpu片内和 片间缓存一致性的数字电路设计方法,能够解决一般gpu的数据共享和同步问题。还考虑到 随着芯片规模增大或存在gpu
‑
gpu互联时,lrcc协议生产者
‑
消费者的同步路径变得很长, 解决缓存一致性可能变得低效,本发明能够提高上述场景下,数据共享和同步的效率,且具 有扩展性,是一个可扩展的解决gpu片间及片内一致性的数字设计方法。
5.为实现上述技术目的,本发明采取的技术方案为:
6.一种高效处理gpu片内和片间缓存一致性的数字电路设计方法,包括:
7.步骤1:划分地址区域并增加pgl2,实现gpu的缓存一致性具有可扩展性;
分成若干缓存子块,非本发明描述重点,后续为描述方便,会将一个区域l2只视为一个整体 缓存块)。一个区域的l2缓存块与该区域的设备内存地址空间对应,该l2缓存块定义为该 区域设备内存地址空间的原始拥有者缓存。原始拥有者缓存需负责记录所有属于该区域设备 内存地址空间的数据被缓存的缓存块状态,并负责最终将被缓存的缓存块写回该区域的设备 内存。
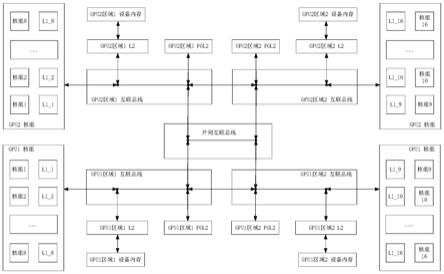
48.实施例中,本发明定义了一种特殊的缓存模块,命名为代理二级缓存(pgl2)。pgl2 也分成若干份,每个区域都由一份pgl2。一个区域内的pgl2不缓存属于本区域地址空间的 数据,而只缓存非本区域地址空间的数据。其所共享的数据需与本区域l1及非本区域的原始 拥有者缓存通过本发明定义的逻辑行为完成交互,来实现数据共享和同步。本发明逻辑行为 定义如图6所示。区别于普通l2,特别注意pgl2收到getv(acquire indicate)时的逻辑行为。
49.实施例中,本发明的访存子系统互联结构如图7所示,对原本l2和设备内存的访问请求, 根据请求地址是否属于本区域,将属于本区域的请求路由到本区域的原始拥有者缓存,而将 非属于本区域的请求路由到pgl2。pgl2与所有其他区域的原始拥有着有一个物理上的连接 通路。连接通路基于具体系统架构实际情况而定。对于存在片内划分的不同设备内存地址区 域,pgl2和其他区域的原始拥有者可以通过新增的片内互联总线直接连接,对与gpu
‑
gpu 片间的不同区域,pgl2需要通过片间互联总线(如pcie p2p),路由到其他gpu上,再通 过特定的连接通路连接到原始拥有者。
50.实施例:
51.图10是一例基于本发明数字设计方法的单gpu内划分两个设备区域的,仅展示必要参与 缓存一致性模块的同步流程示意图,场景1:生产者、消费者及要同步的数据都属于同一个 区域的情况。基本同步流程:
52.①
生产者release flag,根据图4的行为逻辑,发送geto flag请求到互联总线,互联 总线根据flag地址属于区域1路由到flag地址的原始拥有者l2
53.②
消费者acquire flag,根据图4的行为逻辑,发送getv flag请求到互联总线,互联 总线根据flag地址属于区域1路由到flag地址的原始拥有者l2
54.③
原始拥有者l2根据图2的行为逻辑,发送“请求写回”给生产者
55.④
生产者根据图4的行为逻辑,写回同步数据和flag
56.⑤
原始拥有者l2根据图2的行为逻辑,响应消费者的getv flag请求。消费者收到响应, 根据图4的行为逻辑,无效自己的非占有数据,完成数据一致性同步。
57.图11展示了场景2生产者、消费者属于同一个区域,要同步的数据属于另一个区域的 情况下的同步流程示意图。基本同步流程:
58.①
生产者release flag,根据图4的行为逻辑,发送geto flag请求到区域1互联总线, 区域1互联总线根据flag地址属于区域2,路由到区域1的pgl2。
59.②
pgl2根据图6的行为逻辑,将geto flag请求forward给flag所属区域2的原始拥 有者l2缓存。l2根据图2的行为逻辑,更新flag占有状态。
60.③
消费者acquire flag,根据图4的行为逻辑,发送getv flag请求到区域1互联总线, 区域1互联总线根据flag地址属于区域2,路由到区域1的pgl2。
61.④
pgl2根据图6的行为逻辑,发送“请求写回”给生产者
的pgl2。
83.②
pgl2根据图6的行为逻辑,将geto flag请求forward给flag所属gpu1区域2的原 始拥有者l2缓存。l2根据图2的行为逻辑,更新flag占有状态。
84.③
gpu2区域2消费者acquire flag,根据图4的行为逻辑,发送getv flag请求到gpu2 区域2互联总线,gpu2区域2互联总线根据flag地址属于gpu1区域2,路由到gpu2区域2 的pgl2。
85.④
gpu2区域2的pgl2的flag为无效状态,根据图6的行为逻辑将getv通过片间互联 总线发给flag的原始拥有者gpu1区域2的l2。
86.⑤
原始拥有者l2根据图2的行为逻辑,发送“请求写回”给gpu1区域1pgl2。
87.⑥
gpu1区域1的pgl2根据图6的行为逻辑,发送“请求写回”给生产者
88.⑦
生产者根据图4的行为逻辑,写回同步数据和flag到pgl2
89.⑧
gpu1区域1的pgl2根据图6的行为逻辑,在收到生产者写回的flag后,将自己非占 有数据也全部写回。再将flag写回原始拥有者l2。
90.⑨
原始拥有者l2收到gpu1区域1pgl2写回的flag后,根据图3的行为逻辑,响应gpu2 区域2的pgl2的getv flag请求。gpu2区域2的pgl2收到响应,根据图6的行为逻辑,无 效自己的非占有数据。
91.⑩
gpu2区域2的pgl2完成无效后响应消费者getv flag请求。消费者收到响应,根据图 4的行为逻辑,无效自己的非占有数据。完成整个数据同步。(生产者写回,消费者和消费 者所属区域的pgl2无效旧数据)
92.综上所述,原本lrcc一致性协议需要l1(生产者)
‑
l2(地址原始拥有者)
‑
l1(消费 者)之间的握手交互,随着gpu的片内规模增大及片间一致性的需求,当需要同步的地址空 间属于距离l1较远的l2/设备内存时,可能需要反复来回通过非常长的片内通路或片间通路, 如图8所示。本发明通过划分区域,添加的代理pgl2,及互联的数字逻辑电路,仅在第一次 跨区域读取和写回时需要发生交互,避免了上述场景反复来回交互的情况,缩短了该场景下 的一致性交互时间,减少了数据的流动,提高了完成硬件一致性的效率,如图9所示。
93.本发明划分地址区域增加pgl2的方法来实现gpu的缓存一致性具有可扩展性,当gpu 规模增大或需要支持片间gpu互联或更多片间gpu互联时,基于本发明方法只需要同等增 加区域和pgl2即仍然可支持它们之间的缓存一致性。
94.以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于 本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术 人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。