1.本发明涉及多维数据分析领域,具体涉及一种基于字段语义的数据表自动join推荐方法。
背景技术:
2.在多维数据分析系统中,两表join是频繁且常见的操作,通过对数据表字段名和字段值的分析来推荐join的联接子句,帮助用户完成join的操作,提升系统的智能化水平。
3.多维数据关联技术已成为大数据分析领域的常见操作和基本手段,如何有效地将不同来源、不同组织,设计规范多样化,甚至缺乏数据字典的多维数据相互融合并建立统一的数据模型,对当今的数据分析任务来说至关重要。依靠人工对各个维度数据进行筛选匹配的方式虽然准确率高,但耗时长效率低,且随着工作量的增大错误率也相应增加。近年来,在多维数据分析系统中,两表join是频繁且常见的操作,通过对数据表字段名和字段值的分析来推荐join的联接子句,帮助用户完成join的操作,提升系统的智能化水平。基于多维数据语义分析构建关联模型具有一定参考性,但多数算法缺乏对数据内容本身的考量,特别是在不同数据类型下数据内容及其分布所隐藏的潜在关联性。
技术实现要素:
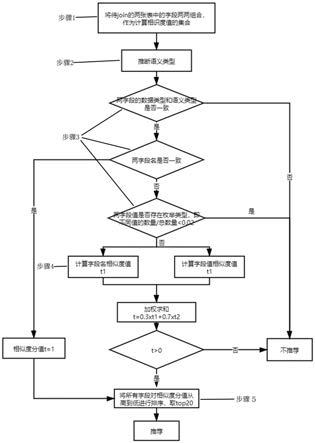
4.本发明提出一种基于字段语义的数据表自动join推荐方法,在用户交互触发join操作时,给出join匹配字段的推荐,即要join的字段通常具有相似的字段名和一致的数据类型,基于字段名和字段值的相似度计算出匹配系数,根据匹配系数进行排序并推荐,其具体技术方案如下:一种基于字段语义的数据表自动join推荐方法,包括如下步骤:步骤1,将待join的两数据表中的字段两两组合,作为计算相似度值的集合;步骤2,推断出字段的语义类型;步骤3,判断两字段的数据类型和语义类型是否一致,再判断两字段名是否一致,接着判断两字段值是否存在枚举类;步骤4,分别计算字段名相似度和字段值的相似度,后通过加权求和,得到匹配系数,即两字段的相似度;步骤5,将所有字段的相似度的分值从高到低进行排序并输出提取前20条,作为推荐。
5.进一步的,所述语义类型包括经纬度、国家、省份、城市、邮编、ip地址、url、邮箱、电话、身份证、护照、类别和空,共13种类型;其中经纬度、ip地址、url、邮箱、电话、身份证和护照采用正则匹配;国家、省份、城市和邮编采用人工建表、查表的方式匹配;类别类型的判断依据:不同数值的数量<=12;若以上语义类型都不满足则为空类型。
6.进一步的,所述步骤3,具体为:匹配字段的数据类型,对不同类型的字段不进行推荐,对相同类型的字段先判断字段名是否一样,忽略大小写,若一样则直接返回相似度分值
t=1,即匹配系数,否则判断两字段值是否存在枚举类,即判断是否满足:不同数值的数量/总数据量<0.02,若满足则不进行推荐。
7.进一步的,所述步骤4,具体为:若不是枚举类,则分别计算字段名相似度分值t1和字段值的相似度分值t2,再通过加权求和,表达式为:t=0.3
×
t1 0.7
×
t2,得到匹配系数。
8.进一步的,所述字段名和字段值的相似度计算均采用单词词向量来计算,单词词向量维度相同,通过计算词向量距离来衡量单词的语义相似度;所述单词词向量通过神经网络语义模型训练文本分类得到。
9.进一步的,所述神经网络语义模型包括输入层、隐藏层和输出层,输入层输入是构成文档的所有单词及其n
‑
gram的热编码,n
‑
gram为由相邻n个单词或字符组成的词组,输出层输出是文档中特定一个词的概率,隐藏层是对多个词向量的叠加平均。
10.进一步的,所述计算字段名相似度,具体包括如下步骤:s1,对字段名预处理,将大写字母变成小写字,把除字母、数字和中文以外的字符变成空格;s2,将预处理后的字段按空格划分成词组;s3,使用fasttext计算词组内各单词的词向量;s4,各单词的词向量求平均后得到字段的词向量;s5,计算两字段词向量的余弦夹角,作为字段名的相似度。
11.进一步的,所述计算字段值的相似度,按字段类型分类,包括:数值类型、日期类型、字符串类型三种情况;对于数值类型,先计算所有记录的归一化直方图,再计算直方图的余弦相似度;对于日期类型,直接设相似度分值为1,即表示匹配;对于字符串类型,各取x条随机记录作为词组来计算字段值相似度,后将x条字段值相似度按空格组合成一个新的字符串,该相似度计算参考字段名相似度计算过程。
12.进一步的,对于所述的数值类型,具体的,随机取字段值m条,利用m条字段值相似度中最大和最小值划分m个均等大小的空间,统计m中所有相似度值落在所述m个均等大小的空间中的个数,并做归一化处理,得到一个m维向量,计算两字段的m维向量的余弦夹角作为字段值的相似度。
13.进一步的,所述步骤5,具体为:对匹配系数按从高到低排序并输出前20条,若最高匹配系数大于0.8,则自动应用该推荐的字段名。
14.本发明结合数据元信息及其内容的自动化join推荐,更准确更全面地帮助用户发现多维数据隐藏的关联信息,有效地提升大数据分析系统的智能化水平。
附图说明
15.图1是本发明的表自动join推荐模型整体流程示意图;图2是本发明的字段名相似度计算流程示意图;图3是本发明的字段值相似度计算流程示意图;图4是本发明的神经网络语义模型架构示意图。
具体实施方式
16.为了使本发明的目的、技术方案和技术效果更加清楚明白,以下结合说明书附图,
对本发明作进一步详细说明。
17.如图1所示,本发明的一种基于字段语义的数据表自动join推荐方法,包括如下步骤:步骤1,当两表连接到join节点时触发auto join推荐,分别从两表的数据库中各选5000条非空记录,将待join的两张数据表中的字段两两组合,作为计算相似度值的集合;步骤2,首先推断出字段的语义类型,包括经纬度、国家、省份、城市、邮编、ip地址、url、邮箱、电话、身份证、护照、类别和空共13种类型;其中经纬度、ip地址、url、邮箱、电话、身份证和护照采用正则匹配;国家、省份、城市和邮编采用人工建表、查表的方式匹配;类别类型的判断依据:不同数值的数量<=12;若以上语义类型都不满足则为空类型。
18.所述人工建表的过程为:从维基百科获取全球国家和城市的中英文列表,包括缩写,写进数据库得到国家和城市两张表。从百度百科得到中国省份的中英文列表,包括缩写,以及中国主要城市的邮编列表,写进数据库得到省份和邮编两张表。通过查询数据库的方式得到匹配结果。
19.步骤3,然后判断两字段的数据类型和语义类型是否一致,再判断两字段名是否一致,接着判断两字段值是否存在枚举类;具体为:匹配字段的数据类型,包括:数值、日期和字符串,对相同类型的字段先判断字段名是否一样,忽略大小写,若一样则直接返回相似度分值t=1,即匹配系数,否则判断两字段值是否存在枚举类,即判断是否满足:不同数值的数量/总数据量<0.02,由于大数据量下join枚举类存在跑不出来的情况,故不推荐枚举类;步骤4,分别计算字段名相似度分值和字段值的相似度分值,后通过加权求和,得到匹配系数,即两字段的相似度分值;具体为:若不是枚举类则分别计算字段名相似度分值t1和字段值的相似度分值t2,再通过加权求和,表达式为:t=0.3
×
t1 0.7
×
t2,得到匹配系数;所述字段名和字段值的相似度计算都采用了单词词向量来计算。单词词向量是用一个多维数组来表征一个单词,两个单词的词向量维度相同,因此可以计算两向量的距离来衡量两单词的语义相似程度。
20.通过神经网络语义模型训练文本分类可以得到单词的词向量。本发明使用类似于cbow的输入层
‑
隐藏层
‑
输出层的三层神经网络来构建语言模型,输入是构成文档的所有单词及其n
‑
gram的热编码,n
‑
gram为由相邻n个单词或字符组成的词组,输出是文档中特定一个词的概率,隐藏层是对多个词向量的叠加平均如图4所示,是神经网络语义模型架构,其中x
1k
、x
2k
…
x
ck
是构成文档的所有单词及其n
‑
gram的词向量,每个词向量是n维的向量,n是自主设定的参数,v是词库的大小;是维权重矩阵,与输入的热编码相乘求平均后得到n维向量h
i
;是维权重矩阵,与h
i
相乘后得到v维向量,再经过一个分层softmax层,与softmax效果一致但更快,最终得到词向量y
j
的分类概率。
21.完整训练流程如下:使用维基百科中、英文文章作为语料库,每一条语料是文章中的一个句子,对于中文语料库,使用jieba工具进行分词;对于英文语料库,按空格或标点符号进行分词,分词后使用n
‑
gram获得单词词组,单词和词组热编码后作为输入,随机初始化矩阵或使用预训练的词向量矩阵和随机初始化矩阵。对于每一条输入,前向传
播得到输出分类概率,计算分层softmax损失,使用随机梯度下降法反向传播更新模型参数,模型训练后得到的副产物就是词向量矩阵。
22.分别得到中、英文词向量矩阵后,通过中英文词典在两向量矩阵中寻找一一对应的词向量对,计算投影矩阵使得投影后的词向量对的距离最短。通过投影矩阵合并两向量矩阵得到一个支持中英文双语互译的词向量矩阵,支持137万个中英文单词。由于n
‑
gram的引入,该模型允许一定限度的单词拼写错误。最后通过降维和量化技术把模型大小从9gb压缩到了180mb。
23.步骤5,将所有字段的相似度分值从高到低进行排序并输出提取前20条,作为推荐。具体为:对匹配系数按从高到低排序并输出前20条推荐,若最高匹配系数大于0.8,则自动应用该推荐的字段名。
24.综上可得输出结果包括:匹配系数,字段名相似度,字段值相似度,匹配字段名及来源的表名。
25.如图2所示,所述计算字段名相似度,具体包括如下步骤:s1,对字段名预处理,将大写字母变成小写字,把除字母、数字和中文以外的字符变成空格;s2,将预处理后的字段按空格划分成词组;s3,使用fasttext计算词组内各单词的词向量;s4,各单词的词向量求平均后得到字段的词向量;s5,计算两字段词向量的余弦夹角,作为字段名的相似度。
26.所述fasttext是facebook开源的一个词向量与文本分类工具,它结合了自然语言处理和机器学习中最成功的理念,提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快。
27.通过中英文词典,将维基百科中、英文fasttext词向量投影到同一向量空间,训练了一个能同时支持中英文的模型,将词向量维度从300维压缩到了100维,结合量化技术把模型大小从9gb压缩到了46.7mb。
28.如图3所示,所述计算字段值的相似度,按字段类型分类,包括:数值类型、日期类型、字符串类型三种情况。对于数值类型,先计算所有记录的归一化直方图,为10维的向量,再计算直方图的余弦相似度;对于日期类型,直接设相似度为1;对于字符串类型,各取5条随机记录作为词组来计算字段值相似度,后将5条字段值相似度按空格组合成一个新的字符串,具体的,该相似度计算参考字段名相似度计算过程。
29.对于所述的数值类型,具体的,随机取字段值n=5000条,若不足5000则取全部,利用m条字段值相似度中最大和最小值划分10个均等大小的空间,统计m中所有相似度值落在所述10个均等大小的空间中的个数,并做归一化处理,得到一个10维向量,计算两字段的10维向量的余弦夹角作为字段值的相似度。
30.本发明的技术优势有:1,在匹配数据类型和语义类型的基础上,分别计算了字段名和字段值的相似度,其中字段值的相似度根据不同数据类型采用了不同的计算方法,充分利用了数据蕴含的信息。
31.2,在计算字段名和字符型字段值相似度时使用了自己搭建的神经网络语义模型,
该模型允许单词有一定程度的拼写错误,并且支持中英文互译。通过词向量计算语义相似度的方法只需计算采样的数据,只使用了5条随机采样的无重记录,相比于模糊匹配等需要遍历数据一一比对的方法,效率上有极大的优势,且通用性更强。通过扩充训练词库可以支持专业领域的词向量计算,比如医学领域。
32.以上所述,仅为本发明的优选实施案例,并非对本发明做任何形式上的限制。虽然前文对本发明的实施过程进行了详细说明,对于熟悉本领域的人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行同等替换。凡在本发明精神和原则之内所做修改、同等替换等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。