一种基于生成对抗网络的伪ct影像生成系统
技术领域
1.本发明涉及医学图像处理的技术领域,尤其是指一种基于生成对抗网络的伪ct影像生成系统。
背景技术:
2.在当前鼻咽癌放疗的临床实践中,ct和mri常常一同被用于放疗计划的制定。由于mr影像并不能直接提供计算辐射剂量所需的组织电子密度信息,因此在结合mri的放疗工作流程中,需要先通过配准算法对mr影像和ct影像进行跨模态配准,由此得到ct
‑
mr融合影像,在此基础上进行gtv的勾画以及后续的剂量规划工作。在放疗计划制定过程中融合使用ct和mr影像显著提高了整个流程的复杂性,增加了医疗系统的负担和工作人员的工作量,并给病患带来额外的经济开支。另外ct扫描过程中存在有害的电离辐射,因此不适合在一段时间内连续检查,并且对例如孕妇和幼儿等某些人群不适用,而mri扫描过程不产生电离辐射,不会对健康带来危害。同时临床上常用的刚性配准算法在进行头部mr
‑
ct影像配准时会带来约0.5
‑
2mm的误差,由配准带来的系统性错误将在整个放疗工作流程中传播,降低了放疗的精确程度,对放疗的有效性带来不利影响。如果能从mr影像中直接生成伪ct影像,即可从mr影像中得到组织电子密度信息,则仅仅依靠mr影像就能够完成整个放疗计划制定过程,可以简化临床放疗工作流程,减轻医生的工作负担,同时避免ct扫描给患者带来辐射,并且能够消除mr影像与ct影像跨模态配准带来的系统误差,进行更为精准的剂量规划,从而提升放疗的效果。
3.现有的基于生成对抗网络的影像生成系统在特定的医学影像生成任务中表现良好,但仍存在以下不足:
4.1、基于多通道输入和跨模态卷积等简单的特征融合方式,特征融合能力较差,特征融合前未考虑到不同序列特征之间的不平衡性,且待融合的特征信息尺度单一,未能对全局和局部特征信息加以充分利用,造成生成影像的质量一般。
5.2、未能实现对于放疗计划制定过程中重点关注的感兴趣区域(region of interest,roi)的生成质量的强化。
6.综上所述,在伪ct影像的生成系统中,如何充分利用多序列mr影像信息,对多序列影像特征进行深度融合,并且强化roi区域的生成质量,得到高质量的伪ct影像,是亟待解决的关键问题。
技术实现要素:
7.本发明的目的在于克服现有技术的缺点与不足,提出了一种基于生成对抗网络的伪ct影像生成系统,采用一种多序列特征深度融合ct影像生成器g,提升ct影像生成的质量,并应用辅助分割器,实现对于roi区域生成质量的强化。
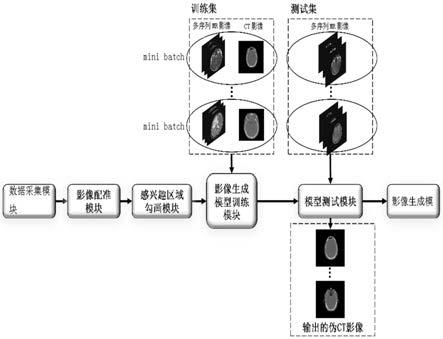
8.为实现上述目的,本发明所提供的技术方案为:一种基于生成对抗网络的伪ct影像生成系统,包括:
9.数据采集模块,用于采集影像数据集,影像数据集包括多个样本相同部位的ct影像和同期获得的多序列mr影像;将影像数据集随机划分为训练集和测试集;
10.影像配准模块,用于选定影像数据集中多序列mr影像的某一序列影像作为参考影像,采用刚性与弹性两步配准法,将各样本中其余序列mr影像、ct影像分别与参考影像进行配准;
11.感兴趣区域勾画模块,用于在参考影像中勾画感兴趣区域;
12.影像生成模型训练模块,用于使用训练集中的影像数据,对影像生成模型进行迭代训练,影像生成模型包括生成对抗网络和分割器s,其中生成对抗网络由多序列特征深度融合ct影像生成器g以及判别器d构成,二者通过分别优化各自的损失函数进行训练,分割器s通过优化感兴趣区域的分割损失,帮助训练多序列深度融合ct影像生成器g,以生成强化感兴趣区域生成质量的伪ct影像;
13.模型测试模块,用于将测试集中的全部样本多序列mr影像,输入影像生成模型训练模块得到的各个迭代训练轮次的影像生成模型中的多序列特征深度融合ct影像生成器g,生成对应的伪ct影像,并评估各样本得到的伪ct影像整体和感兴趣区域的生成质量,选择迭代训练的各个轮次得到的模型中伪ct影像平均生成质量最好的模型作为最优影像生成模型;
14.影像生成模块,用于采集多序列mr影像,将与影像配准模块中所选定的同种mr序列影像作为参考影像,采用刚性与弹性两步配准法,将各样本中其余序列mr影像与参考影像进行配准,将配准后的多序列mr影像输入最优影像生成模型中的多序列特征深度融合ct影像生成器g,生成伪ct影像。
15.进一步,所述影像配准模块用于校正每个样本不同序列的mr影像之间、ct影像与多序列mr影像之间的空间位置差异,选定多序列mr影像中某一序列影像作为参考影像;所述刚性与弹性两步配准法是指先采用刚性配准方法将各个样本中其余序列的mr影像、ct影像分别与参考影像进行配准,以校正头部刚性运动引起的空间位置差异,再应用弹性配准方法进一步校正软组织运动引起的位置差异,从而使同一样本的不同类型影像在空间位置上保持一致。
16.进一步,所述感兴趣区域勾画模块根据参考影像中组织结构特性,由人工确定各样本感兴趣区域并进行勾画,作为生成系统重点关注的区域。
17.进一步,所述影像生成模型训练模块将训练集分成n个小批次(mini batch)的数据并逐批次对影像生成模型进行训练;在训练阶段,当前批次的ct影像为真实ct影像,用i
real_ct
表示,对应的感兴趣区域标签用g表示;当前批次的t种多序列mr影像用i
real_mr
表示;同一批次的t种不同序列mr影像之间是空间位置对齐的;所述影像生成模型包括生成对抗网络和分割器s,其中生成对抗网络由多序列特征深度融合ct影像生成器g和判别器d构成,训练过程包括以下步骤:
18.1)将i
real_ct
输入分割器s,得到分割结果s
real_ct
,计算分割器s相应损失项并更新分割器s的参数;其中,分割结果i
seg
由下列表达式确定:
19.s
real_ct
=s(i
real_ct
)
20.分割器s相应损失项由dice分割损失构成,由下式确定:
[0021][0022]
2)将i
real_mr
输入多序列深度融合ct影像生成器g,生成伪ct影像i
sy_ct
;将i
real_ct
和i
real_mr
在通道维度上进行堆叠,输入到判别器d中;将i
sy_ct
和i
real_mr
在通道维度上进行堆叠,输入到判别器d中,计算判别器d相应损失项并更新判别器d的参数;其中,伪ct影像i
sy_ct
由下式确定:
[0023]
i
sy_ct
=g(i
real_mr
)
[0024]
判别器d相应损失项由对抗性损失构成,由下式确定:
[0025][0026]
式中,m为当前小批次中数据的个数,1为维度与d(i
real_mr
,i
sy_ct
)维度相同的全1矩阵;根据生成对抗网络中博弈论思想,构建对抗性损失的目的是让判别器d正确分辨真实ct影像i
real_ct
和伪ct影像i
sy_ct
的能力尽可能提高;
[0027]
所述多序列深度融合ct影像生成器g为带跳跃连接的多编码器
‑
单解码器结构,即包含多编码器部分和解码器部分;
[0028]
所述多编码器部分由t个结构相同的编码器分支构成,分别对应t种不同序列mr影像的输入;每个编码器分支均含有4个残差模块,每个残差块包含两个2d卷积层,每个卷积层后紧接着是实例归一化层,并使用lrelu作为激活函数;其中,第一个残差模块中卷积的步长设置为1,其余三个残差块卷积的步长均为2,目的是在扩大网络感受野的同时,对特征图进行降采样;当前分支残差模块的输出除了输送到下一级外,还与其它分支同级的输出共同输入到多序列深度融合模块中实现多序列特征的融合,融合后的多序列特征通过跳跃连接输入到对应层级的解码器模块中,以实现低级与高级特征之间的组合;
[0029]
所述多序列深度融合模块由aspp模块、注意力机制模块和残差模块构成;各序列特征首先分别通过aspp模块以获取多尺度特征信息,为后续特征融合提供更加丰富的特征表达;所述aspp模块由3个并行的空洞卷积构成,卷积核尺寸为3
×
3,膨胀比率分别设置为6、12、18,使用实例归一化层和lrelu激活函数;多个序列分别通过aspp模块后得到的多尺度特征将通过concatenate操作在通道维度上进行拼接,得到多个序列的多尺度特征;
[0030]
接下来多个序列的多尺度特征通过注意力机制模块,利用注意力机制在通道和空间两个维度上进行特征校正,通过给予生成任务密切相关的重要特征通道分配更高的权重,弱化不重要的特征通道,进而提升生成模型整体性能;所述注意力机制模块由两个连续的卷积层和通道注意力模块以及空间注意力模块顺序组成,其中,通道注意力模块对输入特征首先在宽
×
高的维度上分别进行最大池化和平均池化,从而得到全局特征信息,紧接着全局特征信息分别输入到相同的两个连续的全连接层,输出的结果相加后通过sigmoid函数得到各通道的权重;其中全连接层后同样使用实例归一化和lrelu激活函数;空间注意力模块则对输入特征在通道维度上应用最大和平均池化,得到的结果在通道维度上进行拼接,通过卷积降维后使用sigmoid函数得到空间位置上的权重;多尺度特征分别与各通道的权重和空间位置上的权重相乘,即可完成多序列特征的校正;校正后的特征经过残差块后完成多序列特征融合过程;
[0031]
所述解码器部分由3个反卷积层、3个残差块以及输出层组成,残差模块位于每个反卷积层后,反卷积层的卷积核尺寸为2
×
2,步长为2;残差块的卷积核尺寸为1
×
1,步长为1;输出层为2d卷积层,输出的通道数为1,卷积核尺寸为1
×
1,步长为1;除输出层无归一化层并使用tanh激活函数以外,其余各层即3个反卷积层和3个残差块均使用实例归一化和lrelu激活函数;
[0032]
所述反卷积层用于对特征图进行上采样以还原为原始尺寸;反卷积层输出的特征与对应层级融合模块通过跳跃连接递送的多序列融合特征通过连接concatenate操作进行连接,然后传递到残差块中实现高级特征与低级特征的组合;低级特征通过跳跃连接馈送至解码器的操作能够帮助网络恢复在下采样过程中丢失的诸如纹理、微小结构之类的细节特征信息,从而得到结构更为精细的生成结果;同时低级特征由多个序列特征融合而来,不同序列的特征信息进行优势互补,进一步提升模型的生成效果;
[0033]
3)将步骤2)中i
sy_ct
输入分割器s,得到分割结果s
sy_ct
,计算分割器s相应损失项并更新分割器的参数;计算多序列特征深度融合ct影像生成器g相应损失项并更新生成器的参数;其中,分割结果s
sy_ct
由下列表达式确定:
[0034]
s
sy_ct
=s(i
sy_ct
)
[0035]
分割器s相应损失项由dice分割损失构成,由下式确定:
[0036][0037]
所述多序列特征深度融合ct影像生成器g相应损失项由下列表达式确定:
[0038][0039]
式中,m为当前小批次中数据的个数,logd(i
real_mr
,i
sy_ct
)是对抗性损失,计算对抗性损失是为了使多序列特征深度融合ct影像生成器g尽可能生成能够欺骗判别器d的伪ct影像;(||i
real_ct
‑
g(i
real_mr
)||1)是真实ct影像和生成的伪ct影像之间的l1损失,计算l1损失是为了帮助多序列特征深度融合ct影像生成器g生成质量更高的伪ct影像,是真实ct影像与生成的伪ct影像由分割器s分割得到的分割结果之间的dice损失值,计算dice损失值是因为生成的伪ct影像的感兴趣区域分割结果与真实ct影像的感兴趣区域分割结果一致性越高,则生成的伪ct影像的感兴趣区域质量越好;通过dice损失值帮助多序列特征深度融合ct影像生成器g生成强化感兴趣区域生成质量的伪ct影像,其中λ和μ均为经验系数。
[0040]
进一步,所述模型测试模块用于将测试集中各样本的多序列mr影像,分别输入影像生成模型训练模块各个迭代训练轮次得到的影像生成模型中的多序列特征深度融合ct影像生成器g,得到各个迭代训练轮次对应的伪ct影像i
sy_ct
,评估伪ct影像整体和感兴趣区域的生成质量,选择迭代训练的各个轮次得到的模型中,伪ct影像平均生成质量最好的模型作为最优影像生成模型;得到伪ct影像i
sy_ct
过程由下列表达式确定:
[0041]
i
sy_ct
=g(i
real_mr
)
[0042]
式中,i
real_mr
指测试集中的多序列mr影像;
[0043]
评估伪ct影像整体的生成质量是指对由各样本多序列mr影像生成的伪ct影像,分别评估其与对应真实ct影像整体的像素强度一致性;
[0044]
评估感兴趣区域的生成质量是指依次采用刚性配准方法和弹性配准方法,对各个样本的伪ct影像与参考mr影像分别进行配准,将配准得到的形变场作用于感兴趣区域标签上,得到伪ct影像中感兴趣区域,分别评估各样本伪ct影像与对应真实ct影像中感兴趣区域的像素强度一致性和结构一致性;
[0045]
选择迭代训练的各个轮次得到的模型中,伪ct影像平均生成质量最好的模型,是指对于迭代训练各个轮次得到的模型,选择伪ct影像整体和感兴趣区域与对应真实ct影像的平均像素强度一致性和平均结构一致性最高的轮次的模型作为最优影像生成模型。
[0046]
进一步,所述影像生成模型采集多序列mr影像,选择与影像配准模块所选定的同种mr序列影像作为参考影像,应用刚性与弹性两步配准法,将各样本中其余序列mr影像与参考影像进行配准,得到空间位置对齐的多序列mr影像,再将多序列mr影像输入最优影像生成模型中的多序列特征深度融合ct影像生成器g,生成伪ct影像,过程由下列表达式确定:
[0047]
i
sy_ct
=g(i
real_mr
)
[0048]
式中,i
real_mr
指多序列mr影像,g指最优影像生成模型中的多序列特征深度融合ct影像生成器。
[0049]
本发明与现有技术相比,具有如下优点与有益效果:
[0050]
1、提出了一种基于深度学习从多序列mr影像生成伪ct影像的影像生成系统,系统中针对多序列影像以及特征融合任务的特点,采用一种基于aspp结构和注意力机制以及残差块的多序列特征深度融合生成器,可以获得多序列影像的多尺度特征,并利用注意力机制使系统中的生成模型更加关注关键特征,提升多序列特征的融合性能,能够充分利用不同序列提供的互补影像学信息,显著提高生成伪ct影像的质量。
[0051]
2、利用辅助分割器使生成对抗网络重点关注roi区域,从而改善系统生成伪ct影像中roi区域的质量。
[0052]
3、相较于传统的影像生成系统,本系统基于端到端的深度学习方法,不需要对数据进行复杂的预处理和后处理,系统中的影像生成模型训练完成后可以高效率地应用于从多序列mr影像中生成高质量的伪ct影像这一任务中。
附图说明
[0053]
图1是本发明系统的结构图。
[0054]
图2是本发明系统中生成对抗网络原理图。
[0055]
图3是多序列深度融合ct影像生成器的结构图。
[0056]
图4是多序列深度融合ct影像生成器中多序列深度融合模块的结构图。
具体实施方式
[0057]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0058]
如图1所示,本实施例所提供的基于生成对抗网络的伪ct影像生成系统,包括:数据采集模块、数据采集模块、感兴趣区域勾画模块、影像生成模型训练模块、模型测试模块和影像生成模块。
[0059]
所述数据采集模块用于采集影像数据集,影像数据集包括多个样本相同目标部位同期获得的t1w、t2w、t1c三个序列的mr影像和被试者同期获得的ct影像。在本实施例中,样本均为鼻咽癌患者,选取目标部位为头颈部;对患者进行随机划分,训练集和测试集比例为4:1;
[0060]
所述影像配准模块为了校正不同序列影像、ct影像与mr影像之间的空间位置差异,以t1c序列mr影像作为参考影像,先采用刚性配准方法,将各样本中其余序列mr影像、ct影像分别与参考影像进行配准,以校正头部刚性运动引起的空间位置差异,再应用弹性配准方法,进一步校正软组织运动引起的位置差异,从而使同一样本的不同类型影像在空间位置上保持一致;
[0061]
所述感兴趣区域勾画模块用于在参考影像中勾画感兴趣区域,由于原发肿瘤和阳性淋巴结为放疗计划重点关注对象,由影像科医生在t1c序列mr影像上对原发肿瘤和阳性淋巴结区域进行勾画,将原发肿瘤和阳性淋巴结区域作为本实施例中的感兴趣区域;
[0062]
所述影像生成模型训练模块用于将训练集分成n个小批次(mini batch)的数据逐批次对影像生成模型进行训练,其中mini batch大小设为m,具体数值可根据gpu可用显存的大小进行调整,本实施例中选取m为4;在训练阶段,当前批次的ct影像为真实ct影像,用i
real_ct
表示,对应的感兴趣区域标签由g表示;当前批次的3种多序列mr影像用i
real_mr
表示;同一批次的3种不同序列mr影像之间是空间位置对齐的;所述影像生成模型包括生成对抗网络和分割器s,其中生成对抗网络由多序列特征深度融合ct影像生成器g以及判别器d构成,训练过程包括以下步骤:
[0063]
将i
real_ct
输入分割器s,得到分割结果s
real_ct
,计算分割器相应损失项并更新参数;
[0064]
分割结果i
seg
由下列表达式确定:
[0065]
s
real_ct
=s(i
real_ct
)
[0066]
s相应损失项由dice分割损失构成,由下式确定:
[0067][0068]
其中,所述分割器s采用res
‑
u
‑
net网络结构,由编码器部分、解码器部分和跳跃连接组成。其中编码器部分由四个残差块构成,每个残差块含有4个残差模块,输出的通道数分别为8、16、32、64。每个残差块包含两个2d卷积层,每个卷积层后紧接着是批归一化层,并使用relu作为激活函数。编码器部分中残差模块的输出除了输送到下一级外,还通过跳跃连接输入到解码器模块的对应层级中,以实现低级与高级特征之间的组合。解码器部分由3个反卷积层、3个残差模块以及输出层组成,残差模块位于每个反卷积层后,反卷积层输出的通道数分别为64、32、16,反卷积层卷积核尺寸为2
×
2,步长为2;残差块输出的通道数分别为32、16、8,残差块卷积核尺寸为1
×
1,步长为1;输出层为2d卷积层,输出的通道数为1,卷积核尺寸为1
×
1,步长为1。除输出层无归一化层并使用sigmoid激活函数以外,其余各层
均使用批归一化和relu激活函数。
[0069]
如图2所示,将i
real_mr
输入多序列深度融合ct影像生成器g,生成伪ct影像i
sy_ct
;将i
real_ct
和i
real_mr
在通道维度上进行堆叠,输入到判别器d中;将i
sy_ct
和i
real_mr
在通道维度上进行堆叠,输入到判别器d中,计算d相应损失项并更新参数。
[0070]
生成伪ct影像i
sy_ct
由下式确定:
[0071]
i
sy_ct
=g(i
real_mr
)
[0072]
判别器d相应损失项由对抗性损失构成,由下式确定:
[0073][0074]
其中m为当前小批次中数据的个数,1为维度与d(i
real_mr
,i
sy_ct
)维度相同的全1矩阵。根据生成对抗网络中博弈论思想,构建对抗性损失的目的是让判别器d正确分辨真实ct影像i
real_ct
和伪ct影像i
sy_ct
的能力尽可能提高。
[0075]
如图3所示,多序列深度融合ct影像生成器g为带跳跃连接的多编码器
‑
单解码器结构,即包含多编码器部分和解码器部分。
[0076]
所述多编码器部分由3个结构相同的编码器分支构成,分别对应3种不同序列mr影像的输入。每个编码器分支均含有4个残差模块,输出的通道数分别为8、16、32、64。每个残差块包含两个2d卷积层,每个卷积层后紧接着是实例归一化层,并使用lrelu作为激活函数。其中第一个残差模块中卷积的步长设置为1,其余三个残差块卷积的步长均为2,目的是在扩大网络感受野的同时,对特征图进行降采样。当前分支残差模块的输出除了输送到下一级外,还与其他分支同级的输出共同输入到多序列深度融合模块中实现多序列特征的融合,融合后的多序列特征通过跳跃连接输入到解码器模块的对应层级中,以实现低级与高级特征之间的组合。
[0077]
如图4所示,所述多序列深度融合模块由aspp模块、注意力机制模块和残差模块构成。各序列特征首先分别通过aspp模块以获取多尺度特征信息,为后续特征融合提供更加丰富的特征表达。本实施例中的aspp模块由3个并行的空洞卷积构成,卷积核尺寸为3
×
3,膨胀比率分别设置为6、12、18,使用实例归一化层和lrelu激活函数,编码器分支中位于不同层级的aspp模块输出的通道数分别为8、16、32、64。多个序列分别通过aspp模块后得到的多尺度特征将通过concatenate操作在通道维度上进行拼接,得到多个序列的多尺度特征。接着多个序列的多尺度特征通过注意力机制模块,利用注意力机制在通道和空间两个维度上进行特征校正,通过给予生成任务密切相关的重要特征通道分配更高的权重,弱化不重要的特征通道,进而提升生成模型整体性能。注意力机制模块由两个连续的卷积层和通道注意力模块以及空间注意力模块顺序组成。其中通道注意力模块对输入特征首先在宽
×
高的维度上分别进行最大池化和平均池化,从而得到全局特征信息,紧接着全局特征信息分别输入到相同的两个连续的全连接层,输出的结果相加后通过sigmoid函数得到各通道的权重。其中全连接层后同样使用实例归一化和lrelu激活函数。空间注意力模块则对输入特征在通道维度上应用最大和平均池化,得到的结果在通道维度上进行拼接,通过卷积降维后使用sigmoid函数得到空间位置上的权重。多尺度特征分别与各通道的权重和空间位置上的权重相乘,即可完成多序列特征的校正。校正后的特征经过残差块后完成多序列特征
融合过程。
[0078]
所述解码器部分由3个反卷积层、3个残差块以及输出层组成,残差模块位于每个反卷积层后,反卷积层输出的通道数分别为64、32、16,反卷积层卷积核尺寸为2
×
2,步长为2;残差块输出的通道数分别为32、16、8,残差块卷积核尺寸为1
×
1,步长为1;输出层为2d卷积层,输出的通道数为1,卷积核尺寸为1
×
1,步长为1。除输出层无归一化层并使用tanh激活函数以外,其余各层均使用实例归一化和lrelu激活函数。其中反卷积层用于对特征图进行上采样以还原为原始尺寸。反卷积层输出的特征与对应层级融合模块通过跳跃连接递送的多序列融合特征通过concatenate操作进行连接,然后传递到残差块中实现高级特征与低级特征的组合。低级特征通过跳跃连接馈送至解码器的操作可以帮助网络恢复在下采样过程中丢失的诸如纹理、微小结构之类的细节特征信息,从而得到结构更为精细的生成结果;同时低级特征由多个序列特征融合而来,不同序列的特征信息进行优势互补,进一步提升模型的生成效果。
[0079]
所述判别器d使用patchgan的结构,其由6个连续的2d卷积层组成,卷积核尺寸均为4
×
4,输出通道数分别为16、32、64、128、128、1。步长分别为2、2、2、2、1、1,除第一个和最后一个卷积层以外,每个卷积层后均含有实例归一化层;除最后一个卷积层外,其余卷积层后均使用lrelu作为激活函数。
[0080]
如图2所示,将伪ct影像i
sy_ct
输入分割器s,得到分割结果s
sy_ct
,计算s相应损失项并更新参数;计算g相应损失项并更新参数。
[0081]
分割结果s
sy_ct
由下列表达式确定:
[0082]
s
sy_ct
=s(i
sy_ct
)
[0083]
s相应损失项由dice分割损失构成,由下式确定:
[0084][0085]
多序列特征深度融合ct影像生成器g相应损失项由下列表达式确定:
[0086][0087]
其中m为当前小批次中数据的个数,logd(i
real_mr
,i
sy_ct
)是对抗性损失,计算对抗性损失是为了使多序列特征深度融合ct影像生成器g尽可能生成能够欺骗判别器d的伪ct影像;(||i
real_ct
‑
g(i
real_mr
)||1)是真实ct影像和生成的伪ct影像之间的l1损失,计算l1损失是为了帮助多序列特征深度融合ct影像生成器g生成质量更高的伪ct影像;是真实ct影像与生成的伪ct影像由分割器s分割得到的分割结果之间的dice损失值,计算dice损失值的目的是基于这样的考虑:生成的伪ct影像的roi区域分割结果与真实ct影像的roi区域分割结果一致性越高,则生成的伪ct影像的roi区域质量越好。通过dice损失值帮助多序列特征深度融合ct影像生成器g生成强化roi区域生成质量的伪ct影像。其中λ和μ为经验系数,本实施例中分别设为100和1。
[0088]
所述判别器d由5个连续的2d卷积层构成,卷积核个数分别为64,128,256,512,1,
卷积核大小均为4,步长分别为2,2,2,1,1,除了第一个和最后一个卷积层以外,其余卷积层后都添加了instance normalization和leaky relu分别作为归一化层和激活函数,第一层后仅添加leaky relu作为激活函数。将生成的三个序列影像进行堆叠,作为三通道影像输入d。
[0089]
所述模型测试模块用于将测试集中的全部样本多序列mr影像,输入影像生成模型训练模块得到的各个迭代训练轮次的影像生成模型中的多序列特征深度融合ct影像生成器g,生成对应的伪ct影像,并评估各样本得到的伪ct影像整体和感兴趣区域的生成质量,选择迭代训练的各个轮次得到的模型中,伪ct影像平均生成质量最好的模型作为最优影像生成模型;得到伪ct影像i
sy_ct
过程由下列表达式确定:
[0090]
i
sy_ct
=g(i
real_mr
)
[0091]
其中i
real_mr
指测试集中的多序列mr影像。
[0092]
评估伪ct影像整体的生成质量,是指对由各样本多序列mr影像生成的伪ct影像,分别评估其与对应真实ct影像整体的像素强度一致性。本实施例采用mae(mean absolute error)、mse(mean square error)、psnr(peak signal to noise ratio)评估像素强度一致性,mae、mse越低,psnr越高,说明伪ct影像与对应真实ct影像的像素强度一致性越高。
[0093]
所述mae的计算由下列表达式所确定:
[0094][0095]
所述mse的计算由下列表达式所确定:
[0096][0097]
所述psnr的计算由下列表达式所确定:
[0098][0099]
其中,sct为生成的伪ct影像,realct为对应的真实ct影像。
[0100]
评估感兴趣区域的生成质量,是指依次采用刚性配准方法和弹性配准方法,对生成的伪ct影像与参考mr影像进行配准,将配准得到的形变场作用于感兴趣区域标签上,得到伪ct影像中对应的肿瘤和淋巴结区域。对伪ct影像中肿瘤和淋巴结区域,分别评估其与真实ct影像中感兴趣区域的像素强度一致性和结构一致性。本实施例采用dice系数(dice coefficient)和豪斯多夫距离(hausdorff distance,hd)评估结构一致性。豪斯多夫距离越低,dice系数越高,说明伪ct影像与对应真实ct影像的结构一致性越高。
[0101]
所述dice系数的计算由下列表达式所确定:
[0102][0103]
其中g为人工勾画的肿瘤或淋巴结区域,p为sct影像中得到的肿瘤或淋巴结区域。
[0104]
所述豪斯多夫距离的计算由下列表达式所确定:
[0105][0106]
其中d(a,b)为a、b两点间的欧氏距离。
[0107]
选择迭代训练的各个轮次得到的模型中,伪ct影像平均生成质量最好的模型,是指对于迭代训练各个轮次得到的模型,选择伪ct影像整体和感兴趣区域与对应真实ct影像的平均像素强度一致性和平均结构一致性最高的轮次的模型作为最优影像生成模型。
[0108]
所述影像生成模块用于采集多序列mr影像,选择与影像配准模块所选定的同种mr序列影像作为参考影像,应用刚性与弹性两步配准法,将各样本中其余序列mr影像与参考影像进行配准,得到空间位置对齐的多序列mr影像,再将多序列mr影像输入最优影像生成模型中的多序列特征深度融合ct影像生成器g,生成伪ct影像,过程由下列表达式确定:
[0109]
i
sy_ct
=g(i
real_mr
)
[0110]
其中,i
real_mr
指多序列mr影像,g指最优影像生成模型中的多序列特征深度融合ct影像生成器。
[0111]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。