1.本发明涉及图像目标检测领域,具体为一种耦合注意力和上下文的轻量化小目标检测方法。
背景技术:
2.目标检测又称目标识别是图像处理和计算机视觉领域中的基本任务之一,它用于在给定图像中查找目标类别并标定目标位置;近几年,基于深度学习的目标检测技术取得了很大的突破,总体可划分为两类:两阶段模型和单阶段模型。
3.两阶段模型通常能保证目标检测质量,它通过提取建议区和对其进行分类完成检测任务;提取建议区的方法有很多,比如滑动窗口,选择性搜索(van de sande等,2011),边缘检测(zitnick等,2014),目标物颜色和形状(che等,2020)等。在此基础上,训练分类器进行分类与回归;使用较广泛的分类器包括支撑向量机(support vector machine,svm)和卷积神经网络(convolutional neural network,cnn)。两阶段模型代表性方法包括r
‑
cnn系列模型,如r
‑
cnn、fast r
‑
cnn、faster r
‑
cnn(girshick等,2014;girshick等,2015;ren等,2015)等和spp net模型(he等,2015)。
4.相对于两阶段模型,单阶段模型不需要提取建议区,只利用单一网络即可直接快速输出目标类别和相应的位置;这类模型根据是否使用锚框(即先验框)又可分为无锚框模型和有锚框模型;前者主要以yolo(you only look once)模型(redmon等,2016)为代表,后者则以单发多框检测(single shot multibox detector,ssd)模型(liu等,2016)和yolo v2
‑
v5(redmon等,2017;redmon等,2018;bochkovskiy等,2020)等为代表;无锚框模型不需要预先估计边框先验信息,模型参数体量较小,但容易产生目标漏检和误检;相比之下,有锚框模型虽能提高目标检测精度,但需要边框先验信息,会增加模型体量和复杂度。
5.上述模型在目标检测业务应用中各有利弊,单阶段模型的检测精度不如两阶段模型高,而两阶段模型的实时性不如单阶段模型强。在检测小尺寸目标物方面,上述模型的检测性能表现都差强人意;以voc 2007数据集中的水瓶(bottle)检测为例,该目标物在图像中的平均面积占比低于5%,在相关参考文献中,上述模型的检测精度(average precision,ap)不足0.6,这意味着深度学习模型在小目标检测方面具有较大的局限性;为进一步提高检测精度,多种先进技术被提出,如超像素标注(yan等,2015),特征金字塔(lin等,2017),注意力机制(wang等,2017;woo等,2018),上下文信息(lin等,2019)等。通过在骨干网络中耦合上述模块可以提高检测精度;然而上述模块的使用需要谨慎行事,贸然使用很可能会显著增加模型参数体量,延长模型训练和运行时间,甚至还可能会进一步降低模型的检测精度。
6.由此可见,现有的深度学习模型在小目标检测方面的应用性并不强。虽然有一些可用于提高检测精度的先进技术被提出,但如何最优化使用它们仍面临巨大困难,尤其是在协调精度、速度、体量和复杂度等方面,为此需要作进一步的技术优化。
技术实现要素:
7.发明目的:本发明的目的是为了解决现有技术中的不足,提供了一种耦合注意力和上下文的轻量化小目标检测方法,以解决现有目标检测方法在检测小目标方面存在的召回率较低、精准率不高、运行效率低下等技术问题。
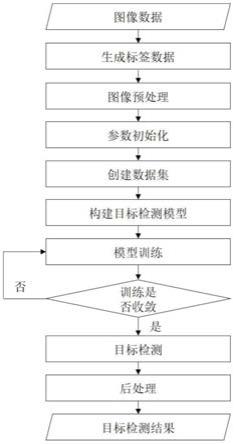
8.技术方案:本发明所述的一种耦合注意力和上下文的轻量化小目标检测方法,包括以下步骤:(1)生成标签数据:根据获取的图像数据,利用图像标注工具在图像数据中标注小目标物位置,生成目标物图像
‑
标签数据;(2)图像预处理:对步骤1中的图像数据进行增强处理,包括图像去燥、图像锐化和图像均衡化等操作;(3)参数初始化:对检测方法中涉及到的参数进行初始化;(4)创建数据集:对步骤2的图像
‑
标签数据进行图像
‑
标签筛选,确保图像数据和标签数据一一对应。根据步骤3设置的初始参数,对图像进行尺寸调整和通道归一化,将标签数据转化为格网数据。根据训练集和测试集比例将数据集划分为训练数据和测试数据;(5)构建目标检测模型:模型框架记为batnet,它主要包括骨架网络,注意力机制模块和上下文聚合网络三部分。骨架网络由轻量级的conv1模块,一系列串联的block模块和regressor模块等构成。注意力机制模块采用woo等(2018)设计的轻量级的卷积块注意力模块(convolutional block attention module,cbam)。由于cbam模块同时考虑了通道注意力和空间注意力机制,因此它相比单一的空间或通道注意力机制模块在捕获检测重点区域方面能获得更好的效果。上下文聚合网络由浅层的上下文特征图和深层的目标特征图进行通道聚合构成。利用上下文聚合网络,可以将浅层的目标物细节信息和深层的目标物语义信息相融合,从而减缓目标物信息在网络传递中的衰减,特别是小目标物信息;(6)模型训练:根据步骤3设置的初始参数,使用步骤4中得到的训练集来训练检测模型直到收敛,记录并保存最优的模型权重,获得最优的网络模型;(7)目标检测:加载已经保存的最优网络模型权重,利用本方法构建的目标检测模型进行目标物检测;(8)后处理:根据步骤3设置的初始参数,对检测出的边框进行非极大值抑制(non
‑
maximum suppression,nms)去重处理,对边框的坐标进行空间变换,还原为图像绝对坐标,并使用步骤4中得到的测试集进行测试。
9.优选的,在上述步骤(1)中,标签数据格式为json或xml。
10.优选的,在上述步骤(2)中,图像去燥方法主要采用卷积核为3
×
3的中值滤波消除椒盐噪声;图像锐化主要使用4领域的拉普拉斯算子(laplace operator)突出地物轮廓;图像均衡化方法主要为全局直方图均衡化,以此保持图像各区域亮度一致性及提高部分区域图像清晰度。
11.优选的,在上述步骤(3)中,需要初始化的参数主要包括:分类数量cls_num,格子尺寸s,每个格子预测的边框数b,图像尺寸img_size,批次大小batch_size,学习率lr,损失阈值loss_thr,置信度阈值conf_thr,交并比阈值iou_thr等。
12.优选的,在上述步骤(4)中,根据设置的图像尺寸img_size对图像数据按最近邻域法进行重采样并对标签数据进行尺寸变换;图像数据经通道归一化后可转换为值域为[
‑
1,
1]的张量;根据设置的格网数s将标签数据转化为格网数据,同时将标签边框坐标由图像绝对坐标变换为格网相对坐标;优选的,在上述步骤(5)中,骨架网络由conv1模块、block1模块、block2模块、block3模块、block4模块和regressor模块等串联构成;注意力机制模块包括:attention1和attention2,attention1和attention2分别连接在conv1模块和block1模块后面;上下文聚合网络包括:feature fusion1和feature fusion2;feature fusion1连接在attention1模块、block1模块和block4模块后面,feature fusion2连接在attention2模块、block2模块和block4模块后面;在conv1模块中,卷积核为3的基础卷积(conv)操作和跨度为2的最大池化操作将对输入特征图进行4倍的降采样;在基础卷积模块conv中,卷积运算、batchnorm批量归一化和relu线性映射构成了三层网络模块;block模块以squeezenet模型(iandola等,2017)的fire模块为基础单元,通过堆积不同的fire模块和连接池化层构建有效的block;fire模块包括压缩层和扩展层两部分;压缩层由一组连续的1
×
1卷积组成,扩展层则是由一组连续的1
×
1卷积和一组连续的3
×
3卷积拼接组成。使用1
×
1卷积和3
×
3卷积的特殊组合可以大幅度降低参数量;其中,block1和block2具有相同的结构,均包含2个frie模块和1个最大池化层;它们的区别在于通道数不同。经过block1和block2操作,输入图像的空间尺寸分别降为原尺寸的1/8和1/16;block3包含4个frie模块和1个最大池化层,用于进一步增加网络深度;经过block3操作,输入图像的空间尺寸分别降为原尺寸的1/32;block4包含2个frie模块和1个全局平均池化层,用于将特征图空间尺寸降低到目标特征图大小;在上下文聚合网络中,上下文特征图分别经过1
×
1卷积模块,3
×
3卷积模块,全局平均池化和通道聚合后形成聚合特征图;其中卷积模块仍由卷积运算、batchnorm批量归一化和relu线性映射构成。采用1
×
1卷积操作用于减少上下文特征图的通道数,即将其缩减为目标特征图通道数的r倍,r取值为[0.1,0.5],这样处理是为了确保上下文信息的数量不会遮盖目标特征图本身;采用3
×
3卷积操作用于第一次下采样;全局平均池化操作用于直接下采样。最后,对上下文特征图进行通道聚合,形成聚合特征图,并和目标特征图再次进行通道聚合,送入回归器regressor中进行训练或预测;regressor模块采用三层串联的1
×
1卷积运算取代了常规的全连接层以此降低参数量,最后进行sigmoid函数映射;其中卷积模块仍由卷积运算、batchnorm批量归一化和relu线性映射构成;目标特征图经过回归器处理后,会得到空间大小为s
×
s,通道数为c的特征图向量;该特征图向量经过训练后,可用于目标检测;类似yolo模型(redmon等,2016)的设计思路,每个特征向量包含了b个预测边框和一个分类概率;其中b个预测边框分别用来预测b个目标(如果边框有重叠,视为一个目标),且每个边框均为5维向量,它包含目标存在概率conf、左上角坐标(x,y)和目标尺寸(w,h);若检测目标包含cls_num类,因此通道数c为b*5 cls_num。
[0013]
优选的,在上述步骤(6)中,优化器使用rmsprop算法,学习率衰减采用等间隔调整steplr策略;当检测模型的损失函数值低于损失阈值loss_thr时,被认为是训练收敛,结束训练。
[0014]
优选的,在上述步骤(8)中,nms去重处理首先筛选置信度高于阈值conf_thr的边框,再依据交并比阈值iou_thr,去除高重合率的边框;边框的坐标变换由格网的相对坐标变换为图像的绝对坐标。
[0015]
与现有技术相比,本发明揭示了一种耦合注意力和上下文的轻量化小目标检测方法,具有如下有益效果:1)以轻量化的卷积模块和fire模块为基础,设计了骨架网络和上下文聚合网络,结合简单易用的cbam作为时间
‑
空间注意力机制模块,设计了batnet模型;利用该模型检测小目标提高了检测精度。
[0016]
2)设计的batnet模型主要由1
×
1卷积和3
×
3卷积模块构成,因此模型的参数是轻量化的,模型的权重文件只有23.67mb,仅是yolo模型的10%,为vgg
‑
yolo模型的39%,是ssd模型的25%,进一步提高方法整体的运行速度。
[0017]
3)该检测方法具有较高的实时性,轻量化的权重文件缩短了模型的加载时间,精心设计的batnet结构减少了模型前馈时间,因此本发明设计的检测方法的帧频(frames per second,fps)可达80,相比yolo模型提高了35,相比vgg
‑
yolo模型提高了69,相比ssd模型提高了46。
附图说明
[0018]
图1为本发明的流程示意图;图2为本发明设计的目标检测模型结构图;图3为本发明设计的目标检测模型包含的模块结构图;图4为本发明设计的目标检测模型包含的上下文聚合网络结构图;图5为本发明设计的目标检测模型包含的回归器结构图;图6为本发明检测小目标物的实际效果图(黑框为检测值,白框为真实值)。
具体实施方式
[0019]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0020]
一种耦合注意力和上下文的轻量化小目标检测方法,如图1所示,具体步骤包括如下:(1)生成标签数据:根据获取的图像数据,利用图像标注工具在图像数据中标注小目标物位置,生成目标物图像
‑
标签数据;(2)图像预处理:对步骤1中的图像数据进行增强处理,包括图像去燥、图像锐化和图像均衡化等操作;(3)参数初始化:对检测方法中涉及到的参数进行初始化;(4)创建数据集:对步骤2的图像
‑
标签数据进行图像
‑
标签筛选,确保图像数据和标签数据一一对应。根据步骤3设置的初始参数,对图像进行尺寸调整和通道归一化,将标签数据转化为格网数据。根据训练集和测试集比例将数据集划分为训练数据和测试数据;
(5)构建目标检测模型:模型框架记为batnet,它主要包括骨架网络,注意力机制模块和上下文聚合网络三部分,如图2所示。骨架网络由轻量级的conv1模块,一系列串联的block模块和regressor模块等构成。各模块结构如图3所示。注意力机制模块采用woo等(2018)设计的轻量级的卷积块注意力模块(convolutional block attention module,cbam)。由于cbam模块同时考虑了通道注意力和空间注意力机制,因此它相比单一的空间或通道注意力机制模块在捕获检测重点区域方面能获得更好的效果。上下文聚合网络由浅层的上下文特征图和深层的目标特征图进行通道聚合构成,如图4所示。利用上下文聚合网络,可以将浅层的目标物细节信息和深层的目标物语义信息相融合,从而减缓目标物信息在网络传递中的衰减,特别是小目标物信息;(6)模型训练:根据步骤3设置的初始参数,使用步骤4中得到的训练集来训练检测模型直到收敛,记录并保存最优的模型权重,获得最优的网络模型;(7)目标检测:加载已经保存的最优网络模型权重,利用本方法构建的目标检测模型进行目标物检测;(8)后处理:根据步骤3设置的初始参数,对检测出的边框进行非极大值抑制(non
‑
maximum suppression,nms)去重处理,对边框的坐标进行空间变换,还原为图像绝对坐标,并使用步骤4中得到的测试集进行测试。
[0021]
本实例中进一步优选的,在上述步骤(1)中,获取的图像数据主要为街景图像,包含近1800幅高清彩色图像,其分辨率为1024*512像素。该数据集中的场景主要包括道路、人行道、行道树、道路隔离带和建筑物等等。其中小目标物为雨水篦子,主要分布在道路两侧和人行横道上游,在整幅图像中的面积占比非常小(平均值仅为5
‰
)。所使用的图像标注工具不唯一,在本实施例中使用开源注释工具labelme,标签数据保存格式为json或xml;本实例中进一步优选的,在上述步骤(2)中,图像去燥方法主要采用卷积核为3
×
3的中值滤波消除椒盐噪声。图像锐化主要使用4领域的拉普拉斯算子(laplace operator)突出地物轮廓。图像均衡化方法主要为全局直方图均衡化,以此保持图像各区域亮度一致性及提高部分区域图像清晰度;本实例中进一步优选的,在上述步骤(3)中,需要初始化的参数主要包括:分类数量cls_num=1,格子尺寸s=7,每个格子预测的边框数b=2,图像尺寸img_size=448,批次大小batch_size=8,学习率lr=2*10
‑4,损失阈值loss_thr=50,置信度阈值conf_thr=0.8,交并比阈值iou_thr=0.5等;本实例中进一步优选的,在上述步骤(4)中,根据设置的图像尺寸img_size对图像数据按最近邻域法进行重采样并对标签数据进行尺寸变换。图像数据经通道归一化后可转换为值域为[
‑
1,1]的张量。根据设置的格网数s将标签数据转化为格网数据,同时将标签边框坐标由图像绝对坐标变换为格网相对坐标。训练集和测试集比例保持在8:2;本实例中进一步优选的,在上述步骤(5)中,骨架网络由conv1模块、block1模块、block2模块、block3模块、block4模块和regressor模块等串联构成,如图2所示。注意力机制模块attention1和attention2分别连接在conv1模块和block1模块后面。上下文聚合网络feature fusion1连接在attention1模块、block1模块和block4模块后面,feature fusion2连接在attention2模块、block2模块和block4模块后面。
[0022]
在conv1模块中,卷积核为3的基础卷积(conv)操作和跨度为2的最大池化操作将
对输入特征图进行4倍的降采样,如图3b所示。经过conv1操作,输入图像的空间尺寸降为原尺寸的1/4。
[0023]
在基础卷积模块conv中,卷积运算、batchnorm批量归一化和relu线性映射构成了基础的三层网络模块,如图3a所示。
[0024]
block模块以squeezenet模型(iandola等,2017)的fire模块为基础单元,通过堆积不同的fire模块和连接池化层构建有效的block。fire模块包括压缩层和扩展层两部分。压缩层由一组连续的1
×
1卷积组成,扩展层则是由一组连续的1
×
1卷积和一组连续的3
×
3卷积拼接组成。使用1
×
1卷积和3
×
3卷积的特殊组合可以大幅度降低参数量。在本发明中,block1和block2具有相同的结构,均包含2个frie模块和1个最大池化层。它们的区别在于通道数不同,如图3c所示。经过block1和block2操作,输入图像的空间尺寸分别降为原尺寸的1/8和1/16。block3包含4个frie模块和1个最大池化层,用于进一步增加网络深度,如图3d所示。经过block3操作,输入图像的空间尺寸分别降为原尺寸的1/32。block4包含2个frie模块和1个全局平均池化层,用于将特征图空间尺寸降低到目标特征图大小,如图3e所示。
[0025]
在上下文聚合网络中,上下文特征图分别经过1
×
1卷积模块,3
×
3卷积模块,全局平均池化和通道聚合后形成聚合特征图,如图4所示。其中卷积模块仍由卷积运算、batchnorm批量归一化和relu线性映射构成,如图3a所示。采用1
×
1卷积操作用于减少上下文特征图的通道数,即将其缩减为目标特征图通道数的r倍,r取值为[0.1,0.5],这样处理是为了确保上下文信息的数量不会遮盖目标特征图本身。采用3
×
3卷积操作用于第一次下采样。全局平均池化操作用于直接下采样。最后,对上下文特征图进行通道聚合,形成聚合特征图,并和目标特征图再次进行通道聚合,送入回归器regressor中进行训练或预测。
[0026]
regressor模块采用三层串联的1
×
1卷积运算取代了常规的全连接层以此降低参数量,最后进行sigmoid函数映射,如图5所示。其中卷积模块仍由卷积运算、batchnorm批量归一化和relu线性映射构成,如图3a所示。目标特征图经过回归器处理后,会得到空间大小为s
×
s,通道数为c的特征图向量。该特征图向量经过训练后,可用于目标检测。类似yolo模型(redmon等,2016)的设计思路,每个特征向量包含了b个预测边框和一个分类概率。其中b个预测边框分别用来预测b个目标(如果边框有重叠,视为一个目标),且每个边框均为5维向量,它包含目标存在概率conf、左上角坐标(x,y)和目标尺寸(w,h)。若检测目标包含cls_num类,因此通道数c为b*5 cls_num。在本实施例中c=11;本实例中进一步优选的,在上述步骤(6)中,优化器使用rmsprop算法,学习率衰减采用等间隔调整steplr策略。当检测模型的损失函数值低于损失阈值loss_thr时,被认为是训练收敛,结束训练;本实例中进一步优选的,在上述步骤(8)中,nms去重处理首先筛选置信度高于阈值conf_thr的边框,再依据交并比阈值iou_thr,去除高重合率的边框。边框的坐标变换由格网的相对坐标变换为图像的绝对坐标。
[0027]
经过上述步骤处理后,本发明设计的检测方法检测小目标物的实际效果如图6所示(黑框为检测值,白框为真实值)。同时,图6中也显示了参考方法的检测效果。可以看出,两种方法在场景1中都能检测出目标物,尽管交并比有一定差异。在场景2中,参考方法出现了漏检,而本发明设计的检测方法则全部检出。
[0028]
综上所述,一种耦合注意力和上下文的轻量化小目标检测方法中,其优点,(1)以轻量化的卷积模块和fire模块为基础,设计了骨架网络和上下文聚合网络,结合简单易用的cbam作为时间
‑
空间注意力机制模块,设计了batnet模型;利用该模型检测小目标(以街景图像中的雨水篦子为例)的平均精度(average precision,ap)可达0.83,其中召回率(recall)达到0.90,精准率(precision)达到0.91,相比yolo模型提高了13%的精度,相比vgg
‑
yolo模型提高了5%的精度,相比ssd模型提高了15%的精度。
[0029]
2)本发明设计的batnet模型主要由1
×
1卷积和3
×
3卷积模块构成,因此模型的参数是轻量化的,模型的权重文件只有23.67mb,仅是yolo模型的10%,为vgg
‑
yolo模型的39%,是ssd模型的25%。
[0030]
3)本发明设计的检测方法具有较高的实时性,轻量化的权重文件缩短了模型的加载时间,精心设计的batnet结构减少了模型前馈时间,因此本发明设计的检测方法的帧频(frames per second,fps)可达80,相比yolo模型提高了35,相比vgg
‑
yolo模型提高了69,相比ssd模型提高了46。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。