技术特征:
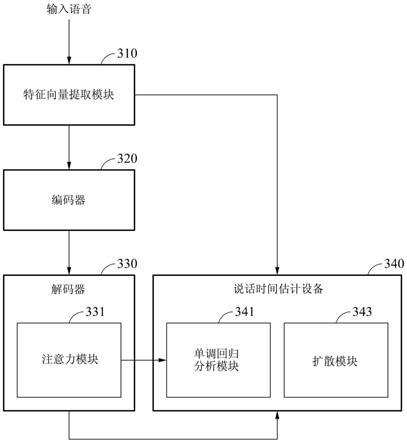
1.一种用于说话时间估计的方法,所述方法包括:使用基于注意力的序列到序列模型来确定多个注意力权重矩阵;从所述多个注意力权重矩阵选择注意力权重矩阵;和基于选择的注意力权重矩阵来估计与输出序列对应的说话时间。2.根据权利要求1所述的方法,其中,选择注意力权重矩阵的步骤包括:对所述多个注意力权重矩阵执行单调回归分析,并且基于单调回归分析的结果来选择注意力权重矩阵。3.根据权利要求1所述的方法,其中,估计说话时间的步骤包括:对选择的注意力权重矩阵执行单调回归分析,并且基于单调回归分析的结果来估计与输出序列对应的说话时间。4.根据权利要求1或2所述的方法,其中,选择的注意力权重矩阵包括输入序列的与输出序列的输出词法单元对应的输入帧的注意力权重作为元素,并且估计说话时间的步骤包括:从输入帧的注意力权重选择预定数量的高注意力权重;和基于选择的注意力权重来估计与输出序列对应的说话时间。5.根据权利要求4所述的方法,其中,基于选择的注意力权重来估计说话时间的步骤包括:基于选择的注意力权重来校正选择的注意力权重矩阵;和基于校正后的注意力权重矩阵来估计与输出序列对应的说话时间。6.根据权利要求4所述的方法,其中,预定数量的高注意力权重是与每个输出词法单元对应的注意力权重之中的预定数量的最高注意力权重。7.根据权利要求1或2所述的方法,其中,估计说话时间的步骤包括:对选择的注意力权重矩阵执行扩散校正;和基于被执行了扩散校正的选择的注意力权重矩阵来估计与输出序列对应的说话时间。8.根据权利要求1或2所述的方法,其中,选择的注意力权重矩阵包括输入序列的与输出序列的输出词法单元对应的输入帧的注意力权重作为元素,并且估计说话时间的步骤包括:从输入帧的注意力权重选择预定数量的高注意力权重;基于选择的注意力权重对选择的注意力权重矩阵执行扩散校正;和基于被执行了扩散校正的选择的注意力权重矩阵来估计与输出序列对应的说话时间。9.根据权利要求1至3中的任意一项所述的方法,其中,所述多个注意力权重矩阵的数量对应于基于注意力的序列到序列模型的注意力层的数量和基于注意力的序列到序列模型的解码器层的数量的乘积。10.根据权利要求1所述的方法,还包括:训练基于注意力的序列到序列模型,使得所述多个注意力权重矩阵之中的预定的注意力权重矩阵被生成为选择的注意力权重矩阵。11.根据权利要求10所述的方法,其中,训练基于注意力的序列到序列模型的步骤包括:掩蔽与预定的注意力权重矩阵对应的注意力层,并且基于掩蔽的注意力层来训练基于注意力的序列到序列模型。12.一种用于说话时间估计的方法,所述方法包括:
接收输入序列;通过对输入序列进行编码来生成编码特征;针对至少一个注意力层中的每个注意力层,确定输入序列的输入帧的注意力权重;基于编码特征和注意力权重来估计输出序列的输出词法单元;基于注意力权重来确定与输出词法单元对应的输入帧;和基于与输出词法单元对应的输入帧来估计与输出序列对应的说话时间。13.根据权利要求12所述的方法,其中,估计说话时间的步骤包括:基于与输出词法单元对应的输入帧,确定所述至少一个注意力层中的每个注意力层的注意力权重矩阵;从所述至少一个注意力层中的每个注意力层的注意力权重矩阵选择与单调性对应的注意力权重矩阵;和基于选择的注意力权重矩阵来估计与输出序列对应的说话时间。14.根据权利要求13所述的方法,其中,从所述至少一个注意力层中的每个注意力层的注意力权重矩阵选择与单调性对应的注意力权重矩阵的步骤包括:对注意力权重矩阵执行单调回归分析;和将具有单调回归分析的最小误差的注意力权重矩阵选择为与单调性对应的注意力权重矩阵。15.一种用于说话时间估计的设备,所述设备包括:处理器,被配置为:使用基于注意力的序列到序列模型确定多个注意力权重矩阵;从所述多个注意力权重矩阵选择注意力权重矩阵;和基于选择的注意力权重矩阵来估计与输出序列对应的说话时间。16.根据权利要求15所述的设备,其中,为了选择注意力权重矩阵,处理器被配置为:对所述多个注意力权重矩阵执行单调回归分析,并且基于单调回归分析的结果来选择注意力权重矩阵。17.根据权利要求15所述的设备,其中,为了估计说话时间,处理器被配置为:对选择的注意力权重矩阵执行单调回归分析,并且基于单调回归分析的结果来估计与输出序列对应的说话时间。18.根据权利要求15或16所述的设备,其中,选择的注意力权重矩阵包括输入序列的与输出序列的输出词法单元对应的输入帧的注意力权重作为元素,并且为了估计说话时间,处理器被配置为:从输入帧的注意力权重选择预定数量的高注意力权重;和基于选择的注意力权重来估计与输出序列对应的说话时间。19.根据权利要求18所述的设备,其中,为了估计说话时间,处理器被配置为:基于选择的注意力权重来校正选择的注意力权重矩阵;和基于校正后的注意力权重矩阵来估计与输出序列对应的说话时间。20.根据权利要求15或16所述的设备,其中,为了估计说话时间,处理器被配置为:对选择的注意力权重矩阵执行扩散校正;和基于被执行了扩散校正的选择的注意力权重矩阵来估计与输出序列对应的说话时间。
21.根据权利要求15或16所述的设备,其中,选择的注意力权重矩阵包括输入序列的与输出序列的输出词法单元对应的输入帧的注意力权重作为元素,并且为了估计说话时间,处理器被配置为:从输入帧的注意力权重选择预定数量的高注意力权重;基于选择的注意力权重对选择的注意力权重矩阵执行扩散校正;和基于被执行了扩散校正的选择的注意力权重矩阵来估计与输出序列对应的说话时间。22.根据权利要求15至17中的任意一项所述的设备,其中,所述多个注意力权重矩阵的数量对应于基于注意力的序列到序列模型的注意力层的数量和基于注意力的序列到序列模型的解码器层的数量的乘积。23.根据权利要求15所述的设备,其中,处理器被配置为:训练基于注意力的序列到序列模型,使得所述多个注意力权重矩阵之中的预定的注意力权重矩阵被生成为选择的注意力权重矩阵。24.根据权利要求23所述的设备,其中,处理器被配置为:掩蔽与预定的注意力权重矩阵对应的注意力层,并且基于掩蔽的注意力层来训练基于注意力的序列到序列模型。25.一种移动设备,包括:至少一个传感器,被配置为接收输入序列;和处理器,被配置为:通过对输入序列进行编码来生成编码特征;针对至少一个注意力层中的每个注意力层,确定输入序列的输入帧的对应的注意力权重;基于编码特征和注意力权重来估计输出序列的输出词法单元;基于注意力权重来确定与输出词法单元对应的输入帧;和基于与输出词法单元对应的输入帧来估计与输出序列对应的说话时间。26.根据权利要求25所述的移动设备,其中,为了估计说话时间,处理器被配置为:基于与输出词法单元对应的输入帧,确定所述至少一个注意力层中的每个注意力层的注意力权重矩阵;从所述至少一个注意力层中的每个注意力层的注意力权重矩阵选择与单调性对应的注意力权重矩阵;和基于选择的注意力权重矩阵来估计与输出序列对应的说话时间。27.根据权利要求25或26所述的移动设备,其中,所述至少一个传感器包括麦克风,输入序列包括语音,并且所述移动设备还包括:用户接口,被配置为输出输出序列和说话时间。28.一种用于说话时间估计的方法,所述方法包括:通过对包括输入帧的输入序列进行编码来生成编码特征;基于编码特征来估计与输入序列对应的输出序列的输出词法单元;确定包括与输出词法单元对应的输入帧的注意力权重的注意力权重矩阵;和基于注意力权重矩阵来估计与输出序列对应的说话时间。29.一种存储指令的非暂时性计算机可读存储介质,所述指令在由处理器执行时,配置所述处理器执行权利要求1至权利要求14以及权利要求28中的任意一项所述的方法。
技术总结
提供了一种用于说话时间估计的方法和设备。所述方法包括:使用基于注意力的序列到序列模型来确定多个注意力权重矩阵;从所述多个注意力权重矩阵选择注意力权重矩阵;和基于选择的注意力权重矩阵来估计与输出序列对应的说话时间。说话时间。说话时间。
技术研发人员:李敏重
受保护的技术使用者:三星电子株式会社
技术研发日:2020.11.04
技术公布日:2021/11/19
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。