一种基于k邻域最大距离平均值的dbscan聚类半径估计方法
技术领域
1.本发明涉及涉及激光雷达数据分析方法,具体涉及一种基于k邻域最大距 离平均值的dbscan聚类半径估计方法。
背景技术:
2.激光雷达(光探测和测距)技术具有数据密度高、精度高、操作效率高、 穿透能力强的优点。除了传统的现场测量和遥感外,激光雷达技术还广泛应用 于许多其他领域,如森林生态、森林变化检测、城市道路检测和规划、机器人 环境感知和自动驾驶技术,其中发挥了越来越重要的作用。
3.然而,解释激光雷达点云数据仍然是一个基本的研究挑战。激光扫描技术 是地面观测技术的新空间,但与激光扫描系统硬件的快速发展相比,点云数据 处理和应用滞后。目前,虽然在点云分割、过滤、分类和特征提取的研究中已 经提出了一系列的研究结果,但这些方法主要适用于某些数据集,或需要用户 有良好的事先了解然而,很少有研究表明dbscan方法的自动分割的效率和激 光雷达数据分割。
4.半径参数&通常很难设置。目前使用dbscan进行激光雷达分割的研究主要 集中于特定的数据上。例如,每个激光雷达数据集都必须理解清楚,并且应仔 细选择参数值£。鉴于dbscan的设计方式,£应该尽可能小。£的值也取决于距 离函数。在理想的情况下,存在域知识来选择基于应用程序域的参数。也就是 说,用户必须非常好地理解数据,并非常仔细地选择£。这种情况阻碍了dbscan 在自动聚类中的应用,为了解决上述技术问题,特提出一种新的技术方案。
技术实现要素:
5.本发明所要解决的技术问题是一种基于k邻域最大距离平均值的dbscan聚 类半径估计方法,以解决背景技术所提出的技术问题。
6.本发明是通过以下技术方案来实现的:一种基于k邻域最大距离平均值的 dbscan聚类半径估计方法,该方法包括以下步骤
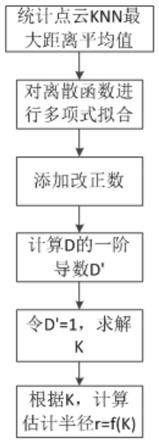
7.步骤一、统计点云knn最大距离平均值;
8.步骤二、对离散函数进行多项式拟合;
9.步骤三、添加改正数;
10.步骤四、计算d的一阶导数d’;
11.步骤五、求解k;
12.步骤六、计算估计半径r;
13.作为优选的技术方案,所述的统计点云knn最大距离平均值为d
mk
,当k=1 时,点p最邻近的一个点为p自身,距离为0,因此k的取值范围从2开始,k 的取值范围为k=(2,3,4,...,k),一般选k=40或k=60;根据公式 计算d
k
,得到d
k
关于k的离散函数d
k
=g(k), 即(2,d
m2
),(3,d
m3
),(4,d
m4
),...,(k,d
mk
)序列。
14.作为优选的技术方案,所述的公式得出方 式为点云knn最大距离平均值d
mk
:假设点云数据p具有m个点,对于给定的整 数k,点云中所有点的knn最大距离的平均值,称为点云p的knn最大距离平均 值d
k
。
15.作为优选的技术方案,所述的对离散函数进行多项式拟合,对公式d
k
=g(k) 进行多项式拟合,得到连续函数关于k的连续函数d
k
=f(k)k∈[2,k]。
[0016]
作为优选的技术方案,所述的添加改正数,设k的最大值为k,d
k
的最大值 为d
k
,则添加改正数,
[0017]
作为优选的技术方案,所述的计算d的一阶导数d’,对d
mk
进行求导,则d
mk
一 阶导数为令d
mk’=1,求解得k=a。
[0018]
作为优选的技术方案,所述的计算估计半径r,将k=a代入公式(3.10),求 得d
ma
,则r=d
ma
为估计半径。
[0019]
本发明的有益效果是:该方法首先统计点云内各个点周边k个最邻近点的 最大距离,并统计最大距离的平均值,该值能够反映点云内点之间的密度,也 即相互之间距离的大小。通过拟合得到k与最大距离平均值之间的函数关系, 将f(k)值域变换到与k的值域相同后,本文通过针对不同点云数据进行多次 的实验后,得到最佳聚类参数对应的函数切线斜率经验值,即在函数切线斜率 等于1时,k对应的f(k)值作为聚类半径进行聚类分割,效果较好。
附图说明
[0020]
图1为本发明参数估计流程图;
[0021]
图2为本发明pi点处knn最大距离d
maxi
(k=8)图;
[0022]
图3为本发明三个阶段和转折点图;
[0023]
图4为本发明三个阶段的切坡和转折点图。
具体实施方式
[0024]
本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互 相排斥的特征和/或步骤以外,均可以以任何方式组合。
[0025]
本说明书(包括任何附加权利要求、摘要和附图)中公开的任一特征,除 非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换。即,除非 特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
[0026]
在本发明的描述中,需要理解的是,术语“一端”、“另一端”、“外侧”、“上”、
ꢀ“
内侧”、“水平”、“同轴”、“中央”、“端部”、“长度”、“外端”等指示的方位 或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简 化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的 方位构造和操作,因此不能理解为对本发明的限制。
[0027]
此外,在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等, 除非另有明确具体的限定。
[0028]
本发明使用的例如“上”、“上方”、“下”、“下方”等表示空间相对位置的 术语是出于便于说明的目的来描述如附图中所示的一个单元或特征相对于另一 个单元或特征的关系。空间相对位置的术语可以旨在包括设备在使用或工作中 除了图中所示方位以外的不同方位。例如,如果将图中的设备翻转,则被描述 为位于其他单元或特征“下方”或“之下”的单元将位于其他单元或特征“上 方”。因此,示例性术语“下方”可以囊括上方和下方这两种方位。设备可以以 其他方式被定向(旋转90度或其他朝向),并相应地解释本文使用的与空间相 关的描述语
[0029]
在本发明中,除非另有明确的规定和限定,术语“设置”、“套接”、“连接”、
ꢀ“
贯穿”、“插接”等术语应做广义理解,例如,可以是固定连接,也可以是可 拆卸连接,或成一体;可以是机械连接,也可以是电连接;可以是直接相连, 也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互 作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据 具体情况理解上述术语在本发明中的具体含义。
[0030]
参照各图,本发明的一种基于k邻域最大距离平均值的dbscan聚类半径估 计方法,该方法包括以下步骤
[0031]
步骤一、统计点云knn最大距离平均值;
[0032]
步骤二、对离散函数进行多项式拟合;
[0033]
步骤三、添加改正数;
[0034]
步骤四、计算d的一阶导数d’;
[0035]
步骤五、令一阶导数d’=1,求解k;
[0036]
步骤六、计算估计半径r;
[0037]
基于密度的聚类方法中,对象间的相似程度需要对象间的距离来度量,因此 聚类半径的选择十分重要。dbscan聚类方法需要用户输入的参数有聚类半径r、 类中最大点数maxpts和类中最小点数minpts。maxpts和minpts用来控制结果类的 规模,聚类半径r用来设置类内点之间的最大距离。
[0038]
dbscan方法对输入的聚类半径r非常敏感,聚类半径细小的差别可能会导致 聚类结果较大的差别。以往的聚类半径的选择一般依靠人的经验值,聚类半径 的估计研究的较少,参数的估计一般以某一类数据作为研究对象,通过大量的 分析实验的到针对该类数据的经验值,但针对其他数据该经验值可能不适用; 开源软件pcl(point cloud library)中针对不同的数据分割需要不同的参数 给出的建议是:不断的实验点云分辨率的5倍、10倍、15倍、20倍
……
,直至 找到最佳的聚类结果。同时,不同数据的最佳参数一般不同,获得的参数成果 难以重复利用,因此建立一套针对不同点云数据类型的聚类参数估计方法十分 必要。
[0039]
针对以上问题,本发明提出基于k邻域最大距离平均值的聚类参数估计方 法。该方法通过分析点云内每个点的k邻域距离均值,经过分析计算,给出最 佳聚类半径。利用k最邻近结点算法(k nearest neighbor,knn)对点云数据 内点之间的距离进行分析,并根据分析结果提出最佳聚类参数的选择方法—— 基于k邻域最大距离平均值的聚类参数估计方法。
[0040]
首先,相关概念定义如下:某点的knn最大距离d
maxi
:对于具有n个m维度点 的点云数据p,p
i
(i=1,2,3,......,n)为其中一点,与p
i
的最近的k个点集合为q, q
j
(j=1,2,
3,......,k)为其中一点,设d(p
i
,q
j
)为p
i
至q
j
的距离,d(p
i
,q
j
)的距离的定义, 即
[0041]
其中p
i
=(x
i1
,x
i2
,...,x
im
)和q
j
=(x
j1
,x
j2
,...,x
jm
)分别是点云数据p中两 个m维点,则点p
i
的knn最大距离d
maxi
为:d
maxi
=max
1≤j≤k
d
ij
。
[0042]
作为优选的技术方案,所述的统计点云knn最大距离平均值为d
mk
,当k=1 时,点p最邻近的一个点为p自身,距离为0,因此k的取值范围从2开始,k 的取值范围为k=(2,3,4,...,k),一般选k=40或k=60;根据公式 计算d
k
,得到d
k
关于k的离散函数d
k
=g(k), 即(2,d
m2
),(3,d
m3
),(4,d
m4
),...,(k,d
mk
)序列。
[0043]
作为优选的技术方案,所述的公式得出方 式为点云knn最大距离平均值d
mk
:假设点云数据p具有m个点,对于给定的整 数k,点云中所有点的knn最大距离的平均值,称为点云p的knn最大距离平均 值d
k
。
[0044]
作为优选的技术方案,所述的对离散函数进行多项式拟合,对公式d
k
=g(k) 进行多项式拟合,得到连续函数关于k的连续函数d
k
=f(k)k∈[2,k]。
[0045]
作为优选的技术方案,所述的添加改正数,设k的最大值为k,d
k
的最大值 为d
k
,则添加改正数,
[0046]
作为优选的技术方案,所述的计算d的一阶导数d’,对d
mk
进行求导,则d
mk
一 阶导数为令d
mk’=1,求解得k=a。
[0047]
作为优选的技术方案,所述的计算估计半径r,将k=a代入公式(3.10),求 得d
ma
,则r=d
ma
为估计半径。
[0048]
该方法首先统计点云内各个点周边k个最邻近点的最大距离,并统计最大 距离的平均值,该值能够反映点云内点之间的密度,也即相互之间距离的大小。 通过拟合得到k与最大距离平均值之间的函数关系,将f(k)值域变换到与k 的值域相同后,本发明方法通过针对车载、机载激光点云数据进行多次的实验 后,得到最佳聚类参数对应的函数切线斜率经验值,即在函数切线斜率等于1 时,k对应的f(k)值作为聚类半径进行聚类分割,效果较好。
[0049]
由于dbscan方法段指向邻域到集群,因此当阶段从阶段1变化到阶段2 时,最优半径可以设置为dk的值。曲线的切线斜率可用作查找从阶段1至阶 段2阶段的转折点。可以向拟合曲线添加修正,以使dk和k具有相同的范 围。添加校正后,每个阶段的切线斜率为r1>1,r2<1,r3<1,如图3所示。因 此,当切切坡r=1时,可以找到从阶段1到阶段2的转折点。
[0050]
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于 此,任何不经过创造性劳动想到的变化或替换,都应涵盖在本发明的保护范围 之内。因此,本发明的保护范围应该以权利要求书所限定的保护范围为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。