1.本发明属于自然语言生成领域,具体涉及一种文档生成系统。
背景技术:
2.随着自然语言处理技术的飞速增长,计算机在处理文本方面的能力越来越强。计算机和人一样,可以对话,阅读文章,评论文章等等。在日常生活中,我们需要撰写大量的文档,很多文档的撰写很繁琐,并且具有较高的重复性和机械性,如果能从历史文档中获取信息,自动生成文档将大大节省人力。由此可见,作为自然语言生成的一个应用,自动生成文档有很大的需求。
3.现有的自然语言生成技术主要有抽取式和生成式两种。抽取式文本生成方法统计文本中各个句子的权重,根据权值进行排序选取重要的句子。主要有基于统计,基于图模型,基于潜在语义等方法。在句子挑选时,句子的重要性计算可以通过规则的方法,比如依赖业务知识总结的一些线索词,也可以利用机器学习方法考虑句子特征,比如crf,svm等,然后进行句子组合,则可以充分考虑句子的相似性,进行去重(mmr算法),以及连贯性排列(自底向下法)。近几年也有人提出了基于整数线性规划和模函数最大化的的方法来考虑句子的冗余性进行句子选择。生成式的方法主要采用seq2seq的方法。从最开始的rnn,lstm深度学习模型,到后来的copynet和pointer network,最近又兴起利用gnn,gcn,理解式的文本生成效果确实在不断提高,但是还在探索阶段。
4.然而,上述抽取式的方法重复性很高,抽取的质量和流畅度差强人意,并且比如textrank算法主要考虑单词词频,没有考虑过多的语义信息。而生成式的方法又太泛,会损失掉很多有用信息,目前还不能很好地处理很长的序列。
5.另外,现在大多数基于上述方法的文档生成系统,都是针对一个特定任务的,不具有普适性,更多的可以理解成代替统计和格式转换的方法,比如doxygen是一个程序的文件产生工具,只是文档作为另一个表现形式,或者是模板性非常高的文档生成,比如自动生成目录,而无法真正地自动生成一个文档。
技术实现要素:
6.为解决上述问题,提供一种能够根据高相关性的历史文档材料自动生成新的文档生成系统,本发明采用了如下技术方案:
7.本发明提供了一种文档生成系统,其特征在于,包括:输入数据获取模块,用于获取训练数据以及用户输入的待分析文档材料,该训练数据包括多个高重复性的历史文档材料以及与该历史文档材料的文本内容相关的多种相关材料;论据信息抽取组合模块,用于对待分析文档材料进行论据信息的抽取并组合为相应的论据段,存储有预先根据训练数据训练完成并且用于识别句子的类型的分类器以及用于抽取相应类型的句子的模板规则;论点信息匹配生成模块,用于根据论据段生成相应的论点信息,存储有预先根据训练数据训练完成并且用于至少根据论据段生成相应候选论点信息的论点生成模型、以及由历史文档
材料中的所有论点句子组成的论点池,论点信息为论据段的概括性的中心句;文档生成模块,用于根据论据段以及论点信息生成新的文档材料,其中,论据信息抽取组合模块具有论据抽取单元、分类识别单元、匹配抽取单元以及组合单元,论点信息生成匹配模块具有候选论点生成单元以及论点信息匹配单元,论据抽取单元根据模板规则从待分析文档材料中抽取各个类型的句子作为相应类型的论据信息,分类识别单元通过分类器对相关材料中的各个句子进行类型识别得到各个句子的句子类型,匹配抽取单元根据模板规则以及句子类型从相关材料中抽取相应句子作为相应类型的论据信息,组合单元用于将相同类型的论据信息组合形成论据段,候选论点生成单元用于将论据段输入论点生成模型生成候选论点信息,论点信息匹配单元用于根据候选论点信息在论点池中匹配出最相似的论点句子作为论点信息。
8.本发明提供的文档生成系统,还可以具有这样的技术特征,还包括:信息推荐模块,其中,论点池包含多个小论点池,该小论点池基于聚类算法对论点句子进行聚类得到,信息推荐模块用于在论点信息所对应的小论点池中获取预定数量个论点句子作为推荐论点信息,并获取预定数量个论据段作为推荐论据信息,进一步将推荐论点信息以及推荐论据信息进行输出。
9.本发明提供的文档生成系统,还可以具有这样的技术特征,还包括:输入显示模块,存储有推荐信息显示画面,其中,信息推荐模块将推荐论点信息以及推荐论据信息输出给输入显示模块,输入显示模块显示推荐信息显示画面并显示推荐论点信息以及推荐论据信息让用户选定需要的推荐论点信息以及推荐论据信息作为文档生成信息,一旦用户完成了文档生成信息的选定,文档生成模块就根据文档生成信息生成新的文档材料。
10.本发明提供的文档生成系统,还可以具有这样的技术特征,其中,分类器为fasttext分类器,该分类器的目标函数为:式中,n是历史文档材料与待分析文档材料中句子的数量,x
n
是第n个句子的特征,y
n
是预测标签,f是softmax函数,a和b是权重矩阵,另外,该fasttext分类器还采用了层次softmax和n-gram特征,即:式中,n
i
表示深度i的节点。
11.本发明提供的文档生成系统,还可以具有这样的技术特征,其中,历史文档材料为多个干部的历史考察材料,待分析文档材料为待分析考察材料,相关材料为各个干部的业绩信息以及述职材料,类型为总括、品德、工作表现(能力业绩,作风)、廉政以及特点特长不足中的任意一种。
12.本发明提供的文档生成系统,还可以具有这样的技术特征,其中,相关信息还包括行业目录,论点信息生成匹配模块还具有行业信息匹配单元,行业信息匹配单元用于通过文本相似度对行业目录进行匹配并得到各个干部的行业信息,论点生成模型不仅根据论据段还根据行业信息生成候选论点信息。
13.本发明提供的文档生成系统,还可以具有这样的技术特征,其中,训练器的训练过程包括:通过论据抽取单元根据模板规则从历史文档材料中抽取各个类型的句子作为相应类型的训练用论据信息;基于每个训练用论据信息所对应的类型对历史文档材料中的各个句子进行自动标注;利用标注后的历史文档材料对训练器完成训练。
14.本发明提供的文档生成系统,还可以具有这样的技术特征,其中,组合单元通过聚
类将同一类的论据信息放在一起,并利用自底向下方法对论据信息进行连贯性排列从而形成论据段。
15.发明作用与效果
16.根据本发明的文档生成系统,由于具有论据信息抽取组合模块以及论点信息匹配生成模块,可以通过论据信息抽取组合模块抽取历史文档材料以及相关材料中的“论据”并组合,再通过论点信息匹配生成模块基于“论据”生成候选论点并利用该候选论点知道最终“论点”的生成,因此,既保证了“论点”和“论据”之间的相关性,同时也可以使“论点”更具有信息性。还由于通过文档生成模块组织“论点”和“论据”并生成新的文档材料,因此,本发明的文档生成系统可以根据用户输入的历史文档自动生成新的文档。同时,该文档生成系统可以适用于很多具有重复性的文档生成任务中,而不仅仅限于一类文档的生成,具有普适性。
附图说明
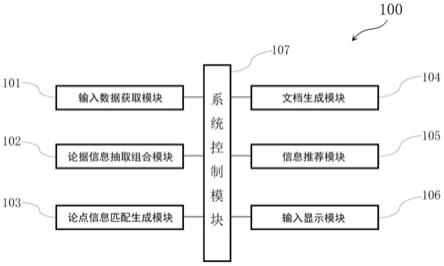
17.图1是本发明实施例中文档生成系统的结构框图;
18.图2是本发明实施例中文档生成过程的框架示意图;
19.图3是本发明实施例中论据信息抽取组合模块的框架示意图;
20.图4是本发明实施例中论点生成模块的框架示意图;以及
21.图5是本发明实施例中文档生成系统生成的考察材料的效果展示图。
具体实施方式
22.为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的文档生成系统作具体阐述。
23.<实施例>
24.本实施例中,以考察材料的生成为例,这里的背景是干部每年需要撰写大量的考察材料来表述自己的业绩等信息,很多事迹也是以前提到过的,大量的考察材料之间有很高的相关性,另外考察材料的行文风格也比较固定,因此可以通过文档生成系统来自动撰写考察材料。此时,文档生成系统的输入是历史考察材料,业绩信息和述职材料,输出是新生成的考察材料。
25.图1是本发明实施例中文档生成系统的结构框图。
26.如图1所示,文档生成系统100包括输入数据获取模块101、论据信息抽取组合模块102、论点信息匹配生成模块103、文档生成模块104、信息推荐模块105、输入显示模块106以及用于控制上述各模块的系统控制模块107。
27.其中,文档生成系统100为一台由用户持有的计算机,系统控制模块107存储有用于对文档生成系统100的各个构成部件的工作进行控制的计算机程序。
28.输入数据获取模块101用于训练数据以及待分析文档材料。
29.其中,训练数据是预先获取的,例如,可以通过技术人员导入获取或是在相关的训练数据库中获取。该训练数据为多个历史文档材料以及与多种相关材料。本实施例中,历史文档材料为针对每个人员的考察材料,一般每年一份,且行文风格比较类似和统一,包含总括,品德,工作表现(能力业绩,作风),廉政和特点特长不足。相关材料有和历史文档材料文
本内容相关的,也有最新的一些描述人员事迹的材料,可以作为历史材料的补充,行文风格比较灵活。另外,相关材料还包括行业目录,但是考察材料业绩信息和述职材料都是针对每个人员的,行业目录是总的,大家共用的。
30.待分析文档材料由用户(即文档生成系统100的使用者)输入。本实施例中,待分析文档材料为用户输入的待分析历史文档材料和多种相关材料。系统处理这些材料后会返回分析结果,综合所有材料形成一篇新的描述该人员的文档材料,它的行文风格也比较固定,和历史文档材料类似,可作为新一年的人员考察材料。
31.图2是本发明实施例中文档生成过程的框架示意图。
32.如图2所示,本实施例中,文档材料以及相关材料为各个干部的考察材料(即历史文档材料和待分析文档材料)以及业绩信息和述职材料(相关材料),每一位干部的考察材料、业绩信息和述职材料都对应有该干部的人员id。
33.一旦技术人员将历史考察材料、业绩信息以及述职材料作为训练数据输入计算机后,输入数据获取模块101就会获取到这些训练数据,并由系统控制部106控制论据信息抽取组合模块102和论点信息匹配生成模块103根据训练数据完成训练。
34.在完成训练并实际使用时,用户将考察材料输入计算机,输入数据获取模块101就会获取到该考察材料并作为待分析考察材料,进一步由论据信息抽取组合模块102和论点信息匹配生成模块103根据待分析考察材料进行论据信息的抽取和论点信息的生成,最后由文档生成模块104根据这些论据信息以及论点信息生成新的考察材料并输出。
35.论据信息抽取组合模块102用于对待分析文档材料进行论据信息的抽取并组合为相应的论据段。
36.本实施例中,论据信息为考察材料中每段文本的具体内容。论据信息抽取组合模块102的输入是考察材料、业绩信息和述职材料中的句子,输出是处理得到的多个类型的论据信息。该论据信息抽取组合模块102综合利用了分类器、模板规则等方法,按照一定的“论据”优化目标,组合得到最终的论据段。其中,“论据”优化目标是人员事迹具有代表性、类似事迹组合在一起使得“论据”具有层次性、“论据”组合通顺合理无重复、比较全面等。
37.本实施例中,根据对历史考察材料、业绩信息和述职材料的分析,可以发现历史考察材料的结构性很强,例如:第一段为总括,第二段为德的阐述,第三段及之后为能力和业绩的阐述等。因此,可以将论据信息划分为五个类型,即:总括、品德、能力和业绩、廉政以及特点特长不足,并根据这些类型在相应的段落中抽取各个句子作为相应的论据信息。同时,在论据信息抽取组合模块102对考察材料中的各个段落进行处理时,还会去掉第一句话,因为第一句话往往是“论点”。
38.本实施例中,论据信息抽取组合模块102存储有预先训练号的分类器以及模板规则,具有论据抽取单元21、分类识别单元22、匹配抽取单元23、关键词抽取单元24以及组合单元25。具体地:
39.论据抽取单元21用于根据模板规则从待分析文档材料中抽取各个类型的句子作为相应类型的论据信息。
40.本实施例中,论据抽取单元21所采用的模板规则为根据历史考察材料在对应各个类型的相应段落中抽取出多个除第一句以外的句子作为相应类型的论据信息。
41.分类识别单元22用于通过分类器对相关材料中的各个句子进行类型识别得到各
个句子的句子类型。
42.匹配抽取单元23用于根据模板规则以及句子类型从相关材料中抽取相应句子作为相应类型的论据信息。
43.本实施例中,匹配抽取单元23所采用的模板规则为根据匹配抽取单元23识别出的句子类型抽取相应的句子作为相应类型的论据信息。
44.关键词抽取单元24用于根据模板规则从相关材料中直接抽取出相应的句子作为相应类型的论据信息。
45.本实施例中,关键词抽取单元24采用的模板规则为基于关键词匹配的规则,能够通过对应各个类型的关键词对相关材料中的各个句子进行匹配,从而抽取出相应的句子。
46.组合单元25用于将相同类型的论据信息组合形成论据段。
47.图3是本发明实施例中论据信息抽取组合模块的框架示意图。
48.如图3所示,首先,通过训练数据对分类器进行训练,该分类器用于识别句子的类型。本实施例中,分类器为fasttext分类器,该fasttext分类器的目标函数为:
[0049][0050]
式中,n是句子数量,x
n
是第n个句子的特征,y
n
是预测标签,f是softmax函数,a和b是权重矩阵。
[0051]
与深度神经网络分类模型相比,fasttext在保证了准确率的情况下加快了训练速度和测试速度,并且fasttext自身可以训练词向量,另外fasttext用到了层次softmax和n-gram特征,层次softmax中每个节点概率p(w)计算如下:
[0052][0053]
式中,θ
n(w,j)
是非叶子结点n(w,j)的向量表示,h是隐藏层输出,l(w)为目标词所在层数,σ为sigmoid函数,sign(w,j)是特殊函数定义如下:
[0054][0055]
本实施例中,用于对分类器进行训练的历史考察材料包含有已经标注好的论据信息以及对应的类型标签,该类型标签可以基于论据抽取单元21自动完成标注,即由论据抽取单元21抽取出历史考察材料中对应各个类型的论据信息,并根据类型对历史考察材料中相应的句子(即论据信息)进行标注。
[0056]
其次,分类识别单元22使用训练好的fasttext分类器来对述职材料进行分析,这样就可以得到述职材料的每句话在写哪个方面的内容,即每个句子所对应的句子类型。
[0057]
此时,就可以分别由论据抽取单元21、匹配抽取单元23、关键词抽取单元24根据相应的模板规则从历史考察材料、述职材料以及业绩信息中抽取论据信息。
[0058]
本实施例中,考察材料从五个维度(即类型)来描述一个人,包括总括、品德、能力和业绩、廉政以及特点特长不足。但是,对于各个类型还可以根据实际情况进行细化。例如,
如图3所示,在考察材料中,对于能力和业绩这部分可以再进一步细化成作风和工作两段,其余每部分一段。作风主要是这个人总的一些工作表现,侧重描述该人的工作作风,而工作则是这个具体的工作事迹。历史考察材料中的能力和业绩中有工作的“论据”也有作风的“论据”,此时需要通过技术人员人工标注多条(例如100条)数据,放入分类器中学习,使得该分类器还能够对能力和业绩类型的论据信息进行分类并形成对应作风类型以及工作类型两个类型的论据信息。
[0059]
最终,本实施例生成的考察材料由总括、品德、工作、作风、廉政以及特点特长不足六个方面(即类型)构成,每一个方面都独立成段。其中,总括、品德的论据信息主要来源于历史考察材料(由论据抽取单元21按模板规则抽取),工作、作风的论据信息由历史考察材料和述职材料共同得到(历史考察材料由论据抽取单元21按模板规则抽取,述职材料则通过分类器识别并由匹配抽取单元23进行抽取),廉政的论据信息由关键词抽取单元24从述职材料中通过模板规则抽取得到,特点特长不足的论据信息则是关键词抽取单元24从业绩信息中通过模板规则抽取得到。
[0060]
本实施例中,组合单元25在将论据抽取单元21、匹配抽取单元23、关键词抽取单元24抽取的论据信息组合为论据段前,还对各个论据信息进行筛选。其中,组合单元25所进行的筛选包括:
[0061]
(1)能力和业绩方面的筛选。首先,考虑到这件事情达成的影响(比如包含全国,全省,全市,首次等词),选择出包含这些词的句子,然后考虑到情感类的词(比如牵头,前列,满意,肯定等),最后对句子不同长短和“论据”的时间信息划分类别赋予不同的权重,比如句子长度大于40赋予5的权重(小于40大于30的话就是4,依此类推),“论据”是今年的赋予5的权重(去年就是4),那么这句话总的权重是10,是很高的,这句话就很有可能被选择。因为我们更倾向于去选择影响大,情感强烈,较长,在时间比较近的材料中的“论据”。对所有选择出来的好的“论据”,用lcs(最长公共子串)来去重,去掉连续包含超过10个一样字符的句子。
[0062]
(2)对论据信息进行正则处理,删除一些不通顺的词,比如“(一)”,“二、”这些词。另外,考虑到考察材料并不一定是本人撰写,因此也要去掉论据信息中的“本人”“我”等词。
[0063]
通过上述处理,组合单元25将筛选出的论据信息进行组合,具体地:组合单元25通过聚类,把同一类的“论据”放在一起,比如一个人可能做了教育方面的业绩,也有医疗方面的业绩,那么会把教育和医疗的事迹分别放在一起。另外组合单元25还采用了自底向下法对同一类型的论据信息进行连贯性排列。
[0064]
论点信息匹配生成模块103用于根据论据段生成相应的论点信息。
[0065]
本实施例中,对于考察材料的论点信息生成,主要会关注于能力和业绩部分,一个好的“论点”往往是简练但富含信息性的。因此,论点信息匹配生成模块103采用了一个论点生成模型,输入是生成的“论据”,以及通过文本相似度匹配到的行业信息;输出是“论点”,再利用生成的“论点”去寻找“论点”池中最适合的“论点”。
[0066]
本实施例中,论点信息匹配生成模块103具有行业信息匹配单元31、候选论点生成单元32以及论点信息匹配单元33。
[0067]
行业信息匹配单元31用于通过文本相似度对行业目录进行匹配并得到各个人员的行业信息。
[0068]
本实施例中,行业目录为事先准备好的行业目录表,包含50个不同的行业类别。行业信息匹配单元31根据该行业目录的数据,对每个干部的论据段通过滑动窗口来对行业目录计算相似度,相似度最高的行业目录就是相应干部的行业信息。
[0069]
候选论点生成单元32用于将组合单元25组合形成的论据段以及行业信息匹配单元31匹配得到的行业信息输入论点生成模型生成候选论点信息。
[0070]
论点信息匹配单元33用于根据候选论点信息在候选论点池中匹配出最相似的训练用候选论点信息作为论点信息。
[0071]
图4是本发明实施例中论点生成模块的框架示意图。
[0072]
如图4所示,首先,通过论点生成模型进行候选论点信息的生成,该论点生成模型为transformer模型。transformer模型是基于encoder-decoder结构的模型,最大的特点是利用self-attention机制可以高效地并行化。该transformer模型具有两个重要结构:
[0073]
(1)多头注意力结构(multi-head attention),编码器的每个输入单词对应三个向量,即query vector,key vector,value vector:
[0074]
multihead(q,k,v)=concat(head1,
…
,head
h
)w
o
[0075][0076]
式中,q,k,v分别是输入向量,式中,q,k,v分别是输入向量,都是参数矩阵,这里我们取h=8个head,input和output的维度是d
model
=512,d
k
=d
v
=d
model
/h=64。
[0077]
(2)前馈网络结构,即:
[0078]
ffn(x)=max(0,xw1 b1)w2 b2[0079]
式中,x是上面muti-head attention的输出作为这里的输入向量,w1,w2为参数矩阵,b1,b2为偏置向量。
[0080]
通过上述两个结构,即可学习到输入文本的信息,从而生成对应的候选“论点”。
[0081]
对于原本的深度学习模型,输入是每个人历史考察材料里的能力和业绩的一段论据段,输出是对应这段的候选“论点”。然而,经测试发现这样生成的“论点”比较泛,因此本实施例中,还对论点生成网络的输入增加每个干部的行业信息,从而在深度学习中融入知识。我们把行业信息添加到“论据”信息最前面,作为输入。重新训练transformer模型,输出得到候选论点信息。
[0082]
进一步,本实施例中,在训练过程中,还会将训练数据中所有的能力和业绩段的论点句子抽取出来,形成一个论点池。同时,该论点池包括多个小论点池,各个小论点池是通过k-means算法对论点句子进行聚类形成。本实施例中,设置k-means算法的k=5,从而将一个大的论点池分为5个小论点池。
[0083]
添加了行业信息后的“论点”比之前的效果好了很多,但是用作最终“论点”还是不够好。因此,本实施例中,论点信息匹配单元33还根据候选论点信息对论点池中的每个“论点”计算相似度,选择其中最相似的“论点”作为最终“论点”(即论点信息)。
[0084]
文档生成模块104用于根据论据信息抽取组合模块102抽取的论据组以及论点信息匹配生成模块103生成的论点信息生成相应的新的文档材料。
[0085]
图5是本发明实施例中文档生成系统生成的考察材料的效果展示图。
[0086]
如图5所示,文档生成模块104依次将各个类型的论点信息和论据组组合为一个段落,并按类型的顺序依次将各个段落拼接从而形成文章内容,该文章内容即为新的考察材料。
[0087]
信息推荐模块105用于根据论点信息以及论据组获取相应的推荐论点信息以及推荐论据信息。
[0088]
本实施例中,推荐论点信息的获取方法为:信息推荐模块105通过论点信息确定相应的小论点池(即论点信息对应的论点句子所在的小论点池),并在该小论点池中随机抽取预定数量个论点句子得到;推荐论据信息的获取方法为:信息推荐模块105的“论据”信息和“论点”也是通过论据信息抽取组合模块102和论点信息匹配生成模块103来获取的。和文档生成模块不同的是,文档生成模块是以生成一个完整的文档为目标,一般是根据总括、品德、能力业绩、作风、廉政、特点特长不足生成六段,每段一个论点加论据信息,而信息推荐模块会在生成的“论点”基础上通过“论点”所属的“论点”池推荐多个相似论点,“论据”信息则会把在输入材料中连接在一起的“论据”连接起来,其余独立,供用户选择需要的“论据”进行组合。用户可以选择自己想要的“论点”和“论据”信息,组合成一篇完整的文档。
[0089]
在获取推荐论点信息以及推荐论据信息后,信息推荐模块105就会将其进行输出,例如,输出给计算机的显示屏从而显示给用户查看或是输出给其他系统进行相应处理。本实施例中,信息推荐模块105会将推荐论点信息以及推荐论据信息输出给输入显示模块106。
[0090]
输入显示模块106存储有推荐信息显示画面。
[0091]
推荐信息显示画面用于在接收到推荐论点信息以及推荐论据信息时显示,并在该画面中显示推荐论点信息以及推荐论据信息从而让用户选定需要的论点信息以及论据信息作为文档生成信息。
[0092]
本实施例中,推荐信息显示画面可以让用户选择需要的“论点”、“论据”从而组合成新的文档材料。一旦用户选定了文档生成信息,文档生成模块104就根据文档生成信息生成新的文档材料。
[0093]
实施例作用与效果
[0094]
根据本实施例提供的文档生成系统,由于具有论据信息抽取组合模块以及论点信息匹配生成模块,可以通过论据信息抽取组合模块抽取历史文档材料以及相关材料中的“论据”并组合,再通过论点信息匹配生成模块基于“论据”生成候选论点并利用该候选论点知道最终“论点”的生成,因此,既保证了“论点”和“论据”之间的相关性,同时也可以使“论点”更具有信息性。还由于通过文档生成模块组织“论点”和“论据”并生成新的文档材料,因此,本发明的文档生成系统可以根据用户输入的历史文档自动生成新的文档。同时,该文档生成系统可以适用于很多具有重复性的文档生成任务中,而不仅仅限于一类文档的生成,具有普适性。
[0095]
另外,实施例中,由于在构建论点池时,还通过聚类分为多个小论点池,并且通过信息推荐模块利用生成的“论点”计算文本相似度去对应的小“论点”池中寻找适合的“论点”,因此还可以抽取出多个推荐论点信息以及推荐论据信息供用户选择,进一步方便用户自行选择需要的“论点”和“论据”并生成新的文档材料。
[0096]
另外,实施例中,由于还论点生成模型中融入知识,即,在生成候选“论点”的时候加入了行业信息,因此可以进一步地增强“论点”的信息性,使得最终生成的文档材料更合适。
[0097]
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。