一种基于迁移学习的web服务分类方法
技术领域
1.本发明涉及软件技术领域,具体涉及一种基于迁移学习的web服务分类方法。
背景技术:
2.软件重用是软件开发中非常重要的手段和方法,它能够降低软件开发的成本,使开发者专注于核心功能的开发。web服务(web services)是一种基于网络的、分布式、自描述的模块化组件,它遵循w3c的技术规范并执行特定的任务,能够使用标准的互联网协议如tcp/ip和http,提供通过互联网动态请求的能力,使人们在重用软件代码的同时还能够方便地重用代码背后的数据。随着互联网开发和云计算的高速增长,web服务分类成为软件重用的常用方法之一。基于关键字的方法是大多数情况下发现web服务的首选方法,如何为web服务分配适当的关键字成为了基于关键字搜索的一个重要任务。目前web服务共享平台programmableweb有400多种类型的服务,由于人工水平的差异和服务标签种类繁多,人工为每个web服务正确标记是困难的。因此如何根据web服务的名称和描述自动为web服务分配准确的标签成为迫切需求。现有的web服务自动分类的机器学习方法主要可以被分为两大类:一类是传统机器学习方法,另一类是基于深度学习的方法。
3.基于传统机器学习的web服务分类,主要利用web服务描述语言(wsdl)结构化文档进行服务聚类和其他一些机器学习方法如支持向量机(svm)、朴素贝叶斯、词袋模型、k邻近算法(knn)和随机森林算法(rf)等进行web服务分类;此类方法主要问题在于构建分类器之前,通常需要复杂的人工特征工程,并且分类精度很大程度上依赖人工特征工程的质量,因此特征提取受设计者经验影响较大,自适应性较差。
4.近年来也有越来越多基于深度学习的web服务分类相关研究。cao等人提出了一种基于局部注意力和lstm的web服务分类方法(参见文献:cao y,liu j,cao b,et al.web service s classification with topical attention based bi
‑
lstm[c]//international conference on collaborativ e computing:networking,applications and worksharing.springer,cham,2019:394
‑
407),通过注意力机制将双向lstm和局部模型结合起来考虑web服务间的关系。yang等人在icws’19’20上提出了servenet模型。servenet2019(参见文献:yang y,ke w,wang w,et al.deep learning for web services classification[c]//2019ieee international conference on web services(icws).ieee,2019:440
‑
442.)将二维cnn与双向lstm堆叠起来用于自动特征提取,不仅可以提取相邻词间局部特征,而且可以提取词内小区域。在此基础上,servenet2020(参见文献:yang y,qamar n,liu p,et al.servenet:a deep neural network for web services clas sification[c]//2020ieee international conference on web services(icws).ieee,2020.)进一步加入了bert语言模型作为词嵌入层做上下文相关的词嵌入,考虑了词在句子上的位置信息。不仅可以从服务描述中提取特征,还可以从服务名称中提取特征,而且特征可以是任意长度的,然后自动地将它们合并成统一的特征来预测服务类别。这种提升使得servenet达到更高的准确率。除上述方法外,图卷积网络(gcn)也是一种重要的文本分类方
法。工作中利用自注意力机制和衡量邻近web服务节点的重要性方法构建了一个图注意力网络用于web服务分类(参见文献:peng m,cao b,chen j,et al.sc
‑
gat:web services classification based on graph attention network[c]//international conference on collaborative computing:net working,applications and worksharing.springer,cham,2020:513
‑
529.)。双重图卷积网络(dual
‑
gcn)框架(参见文献:wang x,liu j,liu x,et al.a novel dual
‑
graph convolutional net work based web service classification framework[c]//2020ieee international conference on web services(icws).ieee,2020:281
‑
288.)也被用于web服务分类,可以通过区分web服务描述文档和融合api(mashup
‑
api)联合调用模式来抑制文本内容的噪声传播。
[0005]
如何设计并构建一个高分类精度的web服务分类方法是一项非常有挑战性的工作,目前存在多方面的难题:(1)对于传统机器学习而言,需要依赖大量人工特征工程,并且要想达到高精度则非常依赖高质量的特征工程;(2)深度学习可以提供一种端到端的解决方案,但是目前web服务公共数据集中缺乏高质量的标记数据,现有的机器学习方法分类准确率还不高。深度学习的方法必须有足够可利用的训练样本才能训练得到一个好的分类模型,而目前有标签的样本数据较为有限,我们无法得到足够的标记数据样本,并且收集到的样本数据质量也不高,存在着诸如服务数据集分布非常不平衡、不同服务类别数据量相差较大以及服务描述本身质量差异等问题。
技术实现要素:
[0006]
针对目前web服务分类数据集质量不高、长尾效应严重的问题,本发明采用迁移学习的策略,将移动app分类任务的知识复用到web服务分类上,以提高web服务分类的准确率。
[0007]
为了实现上述发明目的,本发明提供了如下的技术方案:
[0008]
一种基于迁移学习的web服务分类方法,方法如下:首先构建一个与web服务非常相似且具有大量高质量标记数据的app数据集作为源数据集,利用相关领域上丰富的标记数据预训练一个用于app分类任务的深度学习模型,然后将预训练模型的词嵌入和特征提取迁移到web服务分类模型上,通过迁移学习在web服务分类中复用app分类任务学到的知识,最后采用适当的模型微调策略使web服务精确分类。
[0009]
进一步地,一种基于迁移学习的web服务分类方法,具体步骤为:
[0010]
步骤1、源域数据的获取、分析与处理,搜集来自apple store由官方审核的移动端应用程序mobile app领域数据,令搜集到的app数据只保留名称、描述和类别三种属性参数,然后下采样app数据所含数据量较多的类别使数据集分布尽量均衡,构建一个与web服务非常相似且具有大量高质量标记数据的app数据集作为源域;
[0011]
步骤2、将app数据每个类别中按比例随机划分训练集和测试集,使二者遵循同分布,之后将app数据按描述由短到长划分小批次,用于分批装入内存进行训练,在小批次内对app描述进行分词和动态填充,填充至小批次内的最长描述长度nlen,预处理web服务数据亦是如此;
[0012]
步骤3、根据app分类数n,设计n分类的源模型结构,用预处理所得到的app描述和名称,输入到源模型的网络结构中,通过多层模型结构计算得到最终的m维向量输出,其中m
=n;
[0013]
步骤4、结合app分类中源模型的n维向量输出和输入样本对应的标签,构建损失函数和合适的优化器,通过最小化损失函数训练源模型;
[0014]
步骤5、训练好app分类的源模型后,将预训练模型的词嵌入和特征提取部分用基于模型参数的迁移学习方式迁移至web服务分类任务的模型上;
[0015]
步骤6、根据web服务分类数n
′
,设计n
′
分类的目标模型结构,用预处理所得到的web服务描述和名称,输入到目标模型的网络结构中,通过多层模型结构计算得到最终的m
′
维向量输出,其中m
′
=n
′
;
[0016]
步骤7、结合web服务分类上目标模型的n
′
维向量输出和输入样本对应的标签,构建损失函数和合适的优化器,通过最小化损失函数训练目标模型,训练过程中对所迁移层进行冻结;
[0017]
步骤8、结合迁移学习训练好最终的web服务分类的目标模型后,即可用于web服务分类。
[0018]
进一步地,所述步骤3中,源模型结构由bert语言模型、cnn和双向lstm以及后面的权重融合层和数层全连接层组成,其中所述bert语言模型作为词嵌入层分别将名称和描述的输入转化为词向量和矩阵,用于后面的特征提取,所述cnn代表二维卷积层,所述lstm代表双向长短期记忆网络。
[0019]
进一步地,所述步骤3中,f
bert_seq
用于表示描述的词嵌入输出,是一个nlen
×
n的矩阵,f
bert_pool
用于表示名称的词嵌入输出,是一个n维向量;对于描述,使用两层卷积层和双向lstm从中提取高级特征,两层卷积层用于发现和提取相邻词间的局部特征,双向lstm用于提取描述中长期相关的全局特征;对于名称,直接使用一个全连接层加上一个tanh激活函数来提取名称中的特征,名称与描述二者的特征向量可由以下公式得出:
[0020]
h1=f
lstm
·
f
cnn
(f
bert_seq
(x1))
[0021]
h2=f
full
·
f
bert_pool
(x2)
[0022]
得到app描述的特征h1和名称的特征h2后,结合不同权重将二者融合为统一的特征用于分类,在此将描述特征和名称特征的权重分别记作w1和w2,统一特征h可由以下公式计算得出:
[0023]
h
‑
h1×
w1 h2×
w2[0024]
特征融合后,任务层根据特征h对app进行分类任务,借助一个具有n个节点的全连接层以及softmax激活函数的全连接层作为app分类器,得到m维向量,其中m=n。
[0025]
进一步地,所述步骤4中,构建损失函数和合适的优化器具体过程为:选择categorical_crossentropy(ce)作为模型的损失函数,即:
[0026][0027]
上式中,n代表总分类类别数,x代表输入样本,y
i
代表第i类对应的真实标签,如果是真实标签则为1,否则为0,f
i
(x)代表预测概率。
[0028]
本发明提供的自动web服务分类是解决服务发现的搜索空间爆炸的一个有效途径。本发明延续发明人在服务计算顶会icws
′
20年的工作,更进一步提升web服务任务的准
确性和鲁棒性,其创新性表现在:1)找到一个高质量无严重长尾问题的相近任务,并论证可迁移性,2)建立源域任务(移动app分类任务)与目标任务(web服务分类)的关系,通过消融实验,剔除负迁移的影响,将源域正迁移知识复用到目标任务上,3)证明方法的有效性,比目前最先进的模型提高准确性和鲁棒性。
[0029]
本发明所达到的有益效果是:本发明通过重用在app分类问题上学到的知识来帮助解决web服务分类问题,利用app中的大量高质量标记数据在app数据集上训练一个源模型解决app分类问题,并将其作为迁移学习的预训练模型,并通过迁移并冻结模型的词嵌入和特征提取层而重新训练其他层来提高web服务的特征提取能力,进而提升web服务分类的准确率;本发明具有分类准确率高、泛化性能强等特点,能较好地解决现有标记web服务数量少、长尾分布严重的问题,使模型具有更好的泛化性能和更高的分类精度。
附图说明
[0030]
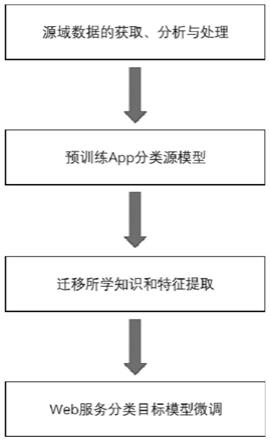
图1为本发明方法流程图。
[0031]
图2为基于迁移学习的web服务分类方法框架图。
[0032]
图3为web服务分类方法top
‑
1准确率雷达图。
具体实施方式
[0033]
为了使本发明的目的、优势能够被清晰的了解,下面结合附图和具体实施方式对本发明内容做进一步详细的阐述。
[0034]
如图1所示,本发明具体实现如下步骤:
[0035]
步骤1、源域数据的获取、分析与处理,搜集移动端应用程序(mobileapp)领域数据,令搜集到的app数据只保留名称、描述和类别三种属性参数,然后下采样app数据所含数据量较多的类别使数据集分布尽量均衡。构建一个与web服务非常相似且具有大量高质量标记数据的app数据集作为源域。
[0036]
步骤2、将app数据每个类别中按4∶1比例随机划分训练集和测试集,使二者遵循同分布,之后将app数据按描述由短到长划分小批次,用于分批装入内存进行训练,在小批次内对app描述进行分词和动态填充,预处理web服务数据亦是如此。即将web服务数据集每个类别按4∶1比例随机划分训练集和测试集,使训练集和测试集遵循同分布,之后将web服务数据按描述长度由短到长排序并划分小批次,在每个小批次内对web服务描述进行分词和动态填充,填充至小批次内的最长描述长度nlen。经过此种处理,模型可以接受任意长度的描述输入,如图2所示。
[0037]
步骤3、根据app分类数n,设计n分类的源模型结构,用预处理所得到的app描述和名称,输入到源模型的网络结构中,通过多层模型结构计算得到最终的m维向量输出,其中m=n。具体来讲,源模型架构由bert语言模型、cnn和双向lstm以及后面的权重融合层和数层全连接层组成。如图2所示,cnn代表二维卷积层,lstm代表双向长短期记忆网络,fc代表全连接层。其中,模型的输入表示是由符号(token)、分词(segment)和位置嵌入(position embeddings)三部分组成。bert语言模型作为词嵌入层分别将名称和描述的输入转化为词向量和矩阵,用于后面的特征提取。由于名称和描述的长度相差较大,因此采用不同的词嵌入方法。f
bert_pool
用于表示名称的词嵌入输出,是一个n维向量。f
bert_seq
用于表示描述的词嵌
入输出,是一个nlen
×
n的矩阵。对于描述,使用两层卷积层和双向lstm从中提取高级特征,两层卷积层用于发现和提取相邻词间的局部特征,双向lstm用于提取描述中长期相关的全局特征。对于名称,直接使用一个全连接层加上一个tanh激活函数来提取名称中的特征。二者的特征向量可由以下公式得出:
[0038]
h1=f
lstm
·
f
cnn
(f
bert_seq
(x1))h2=f
full
·
f
bert_pool
(x2)
[0039]
得到app描述的特征h1和名称的特征h2后,结合不同权重将二者融合为统一的特征用于分类,在此将描述特征和名称特征的权重分别记作w1和w2。统一特征h可由以下公式计算得出:
[0040]
h=h1×
w1 h2×
w2[0041]
特征融合后,任务层根据特征h对app进行分类任务。借助一个具有n个节点的全连接层以及softmax激活函数的全连接层作为app分类器,得到m维向量,其中m=n,作为输入的app数据对于n分类的归属概率。
[0042][0043]
上式中,h1代表softmax前的输出值,p(h
i
)代表输入app属于第i类的概率。
[0044]
步骤4、结合app分类中源模型的n维向量输出和输入样本对应的标签,构建损失函数和合适的优化器,通过最小化损失函数训练源模型。其中,构建损失函数和合适的优化器具体过程为:选择categorical_crossentropy(ce)作为模型的损失函数,即:
[0045][0046]
上式中,n代表总分类类别数,x代表输入样本,y
i
代表第i类对应的真实标签,如果是真实标签则为1,否则为0,f
i
(x)代表预测概率。优化器为使用nesterov动量的随机梯度下降(sgd)算法。
[0047]
步骤5、训练好app分类的源模型后,将预训练模型的词嵌入和特征提取部分用基于模型参数的迁移学习方式迁移至web服务分类任务的模型上。其中,所迁移的模型部分如图2所示,将源模型的嵌入描述层和嵌入名称层及其对应的219百万个参数,以及两层二维cnn和双向lstm层组成的特征提取层及其对应的近6百万个参数从用于app分类的模型迁移至用于web服务分类的目标模型上。
[0048]
步骤6、根据web服务分类数n
′
,设计n
′
分类的目标模型结构,用预处理所得到的web服务描述和名称,输入到目标网络结构中,通过多层模型结构计算得到最终的m
′
维向量输出,其中m
′
=n
′
。
[0049]
步骤7、结合web服务分类中目标模型的n
′
维向量输出和输入样本对应的标签,构建损失函数和合适的优化器,通过最小化损失函数训练目标模型,训练过程中对所迁移层进行冻结。对于目标模型,将迁移的词嵌入层和特征提取层都进行冻结,与源模型不同的是,将后面的特征融合层和任务层进行初始化重新训练,其中任务层是一个带有m
′
个节点和softmax激活函数的全连接层。
[0050]
步骤8、结合迁移学习训练好最终的web服务分类的目标模型后,即可用于web服务分类。
[0051]
在本实施例中,针对本发明提出的基于迁移学习的web服务分类方法进行了实验验证,下面对实施例的数据集、评估指标和实验结果及分析进行描述:
[0052]
数据集:
[0053]
为了评估本发明提出的web服务分类方法,采用icws’20最新发表的web服务数据集,收集自web服务共享平台programmableweb,它包含50个类别和10000个来自工业界的web服务。在每个类别上用随机切分的方式按4:1划分训练集和测试集。app数据集来自apple app store的移动端应用程序,经过数据预处理后的26类90118条应用程序(app)数据。
[0054]
表1:app与web服务类别对比
[0055][0056]
如表1所示,对比app数据和web服务数据集,它们有9个类别是完全相同的。此外两个数据集之间还有5个类别几乎相同,只是它们在两个数据集中的类别名字略有差异。例如,app数据集中名为finance的类在web服务中对应类被命名为financial。由于apple app store中照片和视频是被划分到一个类别photo&video中的,而web服务中其对应的是photos和video两个类,因此应用程序中有14个类对应了web服务当中的15个类。由此可见,从类别的分布来看,源域与目标域较为相似。
[0057]
评估指标:
[0058]
top
‑
1准确率,选取每条数据的概率向量50个类中预测概率最大的作为预测结果,若预测概率最大的类别是数据的真实类别,则认为模型预测正确。记:
[0059]
num
top1_correct
为某一类c中概率向量中预测概率最大的类别为真实类别的数据条数,即预测正确的条数。
[0060]
num
c
为某一类c中所有参与预测的数据总条数。
[0061]
num
all
为某一类c中所有参与预测的数据总条数。
[0062]
对于某个类c的top
‑
1准确率,计算公式为:
[0063][0064]
对于全部50类的top
‑
1准确率,计算公式为:
[0065][0066]
此外,我们还计算了各web服务分类方法的50类分类准确率的标准差,用来反映和比较分类方法的鲁棒性,计算公式为:
[0067][0068]
n在本web服务分类任务中为web服务的总类别数50。
[0069]
对比方法:我们在web服务分类任务上对本发明所提出的方法与现有的机器学习方法做了定量评估,现有的11种机器学习方法有传统机器学习方法和深度学习方法,所有的web服务分类任务都在上述的公开web数据集上进行。现有的11种机器学习方法包括朴素贝叶斯、随机森林算法、adaboost、lda线性支持向量机、lda径向基函数支持向量机(lda
‑
rbf
‑
svm)、cnn、递归cnn、lstm、双向lstm(bi
‑
lstm)、c
‑
lstm和servenet。
[0070]
实验结果与分析:
[0071]
表2:web服务分类准确率和标准差对比
[0072]
web服务分类方法top
‑
1准确率标准差σcnn27.60%16.97adaboost34.93%23.03lda
‑
linear
‑
svm33.28%25.01lda
‑
rbf
‑
svm39.79%25.34naive
‑
bayes47.74%28.52lstm51.18%31.26rf54.29%29.50recurrent
‑
cnn60.02%24.84c
‑
lstm59.24%26.36bi
‑
lstm60.45%24.08servenet69.95%19.86tr
‑
servenet72.58%18.55
[0073]
如表2所示,本发明提出的tr
‑
servenet在top
‑
1准确率上达到了72.58%,分类准确率的标准差为18.55,实现了目前最高的分类准确率和第二小的方差,超越了其他机器学习方法。实验结果表明本文提出的tr
‑
servenet在web服务分类上具有更高的准确性和更好的鲁棒性,从app分类任务到web服务分类的迁移学习是有效的。
[0074]
图3所示的web服务分类方法top
‑
1准确率雷达图中可以更清楚地看出,本发明提出的方法在许多类别上都超越之前的web服务分类方法,实现了最高的准确率。尤其是对于web服务数据集中数据很少但app数据集中具有较多高质量数据的长尾类别,tr
‑
servenet相比现有大多数机器学习模型表现更好,取得了更高的准确率。因为迁移学习可以将源域知识复用于目标域,先利用源域更多的标记数据来预训练模型,再通过迁移学习帮助目标
模型更容易提取出对应类别数据的特征,从而达到更高的分类精度。因此迁移学习是解决web服务长尾分布问题的一个很有前景的方向。
[0075]
此外,对于web服务数据中一些未在app数据集出现的类别,该模型也取得了比之前更高的分类准确率,如marketing、bitcoin、media、internet of things等。其中,对于internet of things类,tr
‑
servenet的top
‑
1准确率比从头训练的servenet高出26.09%。一个可能的原因是,tr
‑
servenet的源模型在较大的app数据集上预训练得到了一个好的特征提取器,将这部分层次迁移可以帮助提高目标模型从web服务中提取特征的能力。更重要的是,在目标域进行模型微调时,相应的层被冻结,使得预训练学习到的特征提取能力得以较好地保留,web服务的特征提取相比之前有所改进。因此,即使是在与app类别不同的web服务类别中,它的性能也比之前更好。
[0076]
总之,本发明针对web服务分类任务,通过构建一个与web服务非常相似且具有大量高质量标记数据的app数据集作为源数据集,利用相关领域上丰富的标记数据预训练一个用于app分类任务的源模型,之后将预训练模型的词嵌入和特征提取迁移到web服务分类模型上,经迁移学习在web服务分类中复用app分类任务学到的知识,最后采用适当的模型微调策略,较好解决了现有标记web服务数量少、长尾分布严重的问题,使web服务分类达到更高的准确率。这一过程中,丰富且与目标域相似的标记数据有助于目标模型更好地提取web服务特征,显著提升模型的泛化性能,进而取得更高的分类精度。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。