用于自适应音量控制的方法和系统
1.相关申请的交叉引用
2.本技术要求2020年5月11日提交的美国临时专利申请序列号63/023114的权益和优先权,该临时专利申请在此全文以引用方式并入本文。
技术领域
3.本公开的一个方面涉及一种音频系统,该音频系统基于音频系统的扬声器的估计声音输出水平自适应地调节音量控制。还描述了其他方面。
背景技术:
4.头戴受话器是包括一对扬声器的音频设备,当头戴受话器配戴在用户头上或围绕用户头部配戴时,每个扬声器被放置在用户的耳朵上。类似于头戴受话器,耳机(或入耳式头戴受话器)是两个分开的音频设备,每个音频设备具有插入到用户耳朵中的扬声器。头戴受话器和耳机两者通常有线连接到单独的回放设备诸如mp3播放器,该回放设备以音频信号驱动设备的每个扬声器以便生成声音(例如,音乐)。头戴受话器和耳机提供用户可用以单独收听音频内容而不必将音频内容广播给附近其他人的一种方便的方法。
技术实现要素:
5.本公开的一个方面是由音频源设备诸如通信地耦接到头戴式耳机的多媒体设备执行的方法。该设备获取输入音频信号,该输入音频信号可包含用户期望的音频内容,诸如音乐。该设备基于输入音频信号、用户音量设置和头戴式耳机的声音输出灵敏度来确定头戴式耳机的声音输出水平(例如,音频输出设备的扬声器的输出a加权声压水平(spl))。该设备确定声音输出水平是否高于阈值。如果是,则该设备对输入音频信号应用(第一)标量增益以产生用于由头戴式耳机输出的输出音频信号。
6.在一个方面,用户音量设置可为正由多媒体设备执行的软件应用程序(例如,媒体播放器软件应用程序)中的“软件”用户音量设置,并且该设备可根据软件用户音量设置对输入音频信号应用(第二)标量增益以产生经增益调节的输入音频信号,声音输出水平基于所述经增益调节的输入音频信号。在另一方面,可将第一标量增益应用于经增益调节的输入音频信号以产生输出音频信号。在一些方面,该设备可基于声音输出水平和阈值确定要应用于经增益调节的音频信号的第一标量增益。例如,第一标量增益可基于声音输出水平和阈值之间的差值减小经增益调节的音频信号。
7.在一个方面,声音输出灵敏度是与头戴式耳机相关联的预定义灵敏度。在另一方面,声音输出灵敏度是默认灵敏度(例如,其可与若干头戴式耳机相关联)。在一些方面,响应于确定声音输出水平高于阈值,设备输出指示声音输出的音量已减小的通知。
8.在另一方面,响应于确定头戴式耳机是通电头戴式耳机(例如,从外部或内部电源汲取电力以便为一个或多个部件(诸如集成在其中的放大器)供电的设备),该设备可执行一个或多个不同的操作。例如,设备可获取作为通电头戴式耳机的“硬件”用户音量设置的
用户音量设置,其中头戴式耳机的声音输出水平是基于输入音频信号、硬件用户音量设置和通电头戴式耳机的声音输出灵敏度来确定。硬件音量设置可为用于通电头戴式耳机的一个或多个硬件部件(例如,放大器)的音量设置。在一个方面,设备可将输入音频信号和(第一)标量增益(其可如上所述基于声音输出水平来确定)传输给音频输出设备,使得音频输出设备将标量增益应用于输入音频信号以产生输出音频信号用于供音频输出设备输出。
9.以上概述不包括本公开的所有方面的详尽列表。可预期的是,本公开包括可由上文概述的各个方面以及在下文的具体实施方式中公开并且在权利要求书中特别指出的各个方面的所有合适的组合来实践的所有系统和方法。此类组合可具有未在上述发明内容中具体阐述的特定优点。
附图说明
10.在附图的图示中通过举例而非限制的方式示出了多个方面,在附图中类似的附图标号指示类似的元件。应当指出的是,在本公开中提到“一”或“一个”方面未必是同一方面,并且其意指至少一个。另外,为了简洁以及减少附图的总数,某个附图可能被用于示出不止一个方面的特征,并且对于某个方面,可能并不需要该附图中的所有元素。
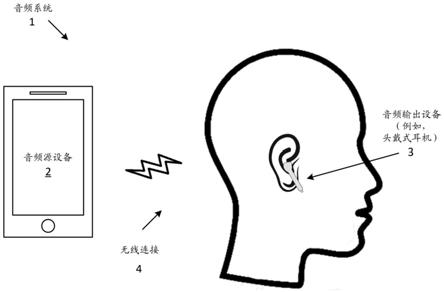
11.图1示出了包括音频源设备和音频输出设备的音频系统。
12.图2示出了根据一个方面的执行自适应音量控制的音频系统的框图。
13.图3示出了根据另一方面的执行自适应音量控制的音频系统的框图。
14.图4是执行自适应音量控制的过程的一个方面的流程图。
15.图5是基于音频输出设备是否是通电设备而执行不同自适应音量控制的过程的一个方面的流程图。
具体实施方式
16.现在将参考所附附图来解释本公开的各方面。只要在某个方面中描述的部件的形状、相对位置和其他方面未明确限定,这里本公开的范围就不仅仅局限于所示出的部件,所示出的部件仅用于说明的目的。另外,虽然阐述了许多细节,但应当理解,一些实施方案可在没有这些细节的情况下被实施。在其他情况下,未详细示出熟知的电路、结构和技术,以免模糊对该描述的理解。此外,除非该含义明确相反,否则本文示出的所有范围被认为包括每个范围的端值。
17.声学剂量测定是测量一段时间(例如,一小时、一天、一周、一个月等)内的噪声暴露以便提供累积噪声暴露读数(例如,声压水平(spl)值)的过程。通常,这可涉及电子设备(例如,spl计)测量紧邻收听者的环境噪声(例如,利用麦克风捕获的),并且输出spl读数(例如,在spl计的显示屏上显示读数)。
18.已显示长时间暴露于吵闹声音会引起听力损失(例如,噪声引起的听力损失(nihl))。nihl归因于由于吵闹声音暴露而对内耳内的微观毛细胞的损伤。例如,长时间暴露于85db或以上的声音可导致一只或两只耳朵中的暂时或永久听力损失。因此,一些组织(例如,国家职业安全与健康研究所(niosh))建议工人暴露于被控制低于相当于85db的水平的环境噪声八小时,以使职业nihl最小化。
19.音频输出设备诸如电子头戴式耳机已变得越来越受用户欢迎,因为它们以高保真
度再现诸如音乐、播客和电影音轨的媒体,同时不打扰附近的其他人。最近,世界卫生组织(who)发布了将头戴式耳机的最大声音输出限制为85db的听力健康和安全标准。为了满足该标准,声学剂量测定过程(例如,在头戴式耳机或与头戴式耳机配对的另一电子设备内执行的声学剂量测定过程)可监测头戴式耳机处的入耳spl,并且在声音超过该阈值时通知(或警示)用户。具体地讲,在声音回放期间,声学剂量测定过程例如在鼓膜参考点处或附近测量入耳spl。在一个方面,入耳spl如下测量。可使用例如实验室校准结果将来自拾取耳道中所有声音的头戴式耳机的内部麦克风的信号处理成等效spl,该实验室校准结果包括要应用于麦克风信号的校正因子,例如均衡化。这些校正因子可考虑其中头戴式耳机至少部分地闭塞用户耳道的闭塞效应。入耳spl可在通过由用户佩戴的头戴式耳机回放期间确定。一旦被估计,入耳spl就被转换成具有由听力健康和安全标准限定的单位的声音样本,如本文所述。然后,这些声音样本可被剂量测定过程用于跟踪头戴式耳机声音暴露。如本文所述,为了测量入耳spl,处理从内部麦克风获取的麦克风信号。麦克风的使用和信号的处理可能需要大量的处理资源(例如,一个或多个处理器的处理资源)和额外的功率(例如,从有限的电池存储装置汲取)。
20.为了克服这些缺陷,本公开描述了一种能够基于头戴式耳机的估计声音输出水平来调整用于剂量测定过程的音量控制的音频系统。具体地讲,音频系统获取可包含用户期望的内容诸如音乐的输入音频信号。该系统基于输入音频信号、音频系统的用户音量设置和头戴式耳机的声音输出灵敏度来确定头戴式耳机的声音输出水平(例如,spl值)。该系统确定声音输出水平是否高于阈值。例如,阈值可以是85db,如who所指定的,或者阈值可以是用户定义的阈值。响应于确定声音输出水平高于阈值,系统对输入音频信号应用标量增益以产生输出音频信号。例如,应用标量增益可降低输入音频信号的电平,从而在用于驱动扬声器时减少吵闹声音。因此,音频系统能够通过估计声音输出水平来自适应地控制头戴式耳机的音量(并因此控制声音输出水平),而无需处理内部麦克风信号。
21.图1示出了包括音频源设备2和音频输出设备3的音频系统1。在一个方面,音频系统可包括其他设备,诸如远程电子服务器(未示出),该远程电子服务器可通信地耦接到音频源设备、音频输出设备或这两者,并且可被配置为执行如本文所述的一个或多个操作。如图所示,音频输出设备是被布置成将声音引导到佩戴者的耳朵中的头戴式耳机。具体地讲,头戴式耳机是定位在用户的右耳上(或中)的耳机(或入耳式头戴受话器或耳塞)。在一个方面,头戴式耳机可包括一对耳机,用于用户的左耳的左耳机和用于用户的右耳的右耳机。在这种情况下,每个耳机可被配置为输出节目音频的至少一个音频声道(例如,右耳机输出立体声录音(诸如音乐作品)的双声道输入的右音频声道,并且左耳机输出左音频声道)。在一些方面,耳机可以是具有柔性耳机末端的密封类型,该柔性耳机末端用于通过阻挡或闭塞在耳道中来相对于周围环境在声学上密封用户的耳道的入口。在另一方面,头戴式耳机可以是至少部分地覆盖用户耳朵的罩耳式耳机。在一些方面,头戴式耳机可以是贴耳式耳机。在另一方面,输出设备可以是包括至少一个扬声器并且被布置为由用户佩戴并且被布置为通过用音频信号驱动扬声器来输出声音的任何电子设备。
22.音频源设备2被例示为多媒体设备,更具体地为智能电话。在一个方面,音频源设备可以是可执行音频信号处理操作和/或联网操作的任何电子设备。此类设备的示例可包括平板电脑、膝上型电脑、台式计算机、智能扬声器等。在一个方面,源设备可以是便携式设
备,诸如如该图所示的智能电话。在另一方面,源设备可以是头戴式设备诸如智能眼镜,或可穿戴设备诸如智能手表。
23.如图所示,音频源设备2经由无线连接4通信地耦接到音频输出设备。例如,源设备可被配置为经由无线通信协议(例如,bluetooth协议或任何其他无线通信协议)与音频输出设备3建立无线连接。在所建立的无线连接期间,音频源设备可与音频输出设备交换(例如,发射和接收)数据分组(例如,互联网协议(ip)分组),其可包括音频数字数据。
24.在另一方面,音频源设备2可经由其他方法与音频输出设备通信地耦接。例如,两个设备均可经由有线连接来耦接。在这种情况下,有线连接的一端可(例如,固定地)连接到音频输出设备,而另一端可具有插入音频源设备的插口中的连接器,诸如媒体插口或通用串行总线(usb)连接器。一旦连接,音频源设备就可被配置为经由有线连接利用一个或多个音频信号来驱动音频输出设备的一个或多个扬声器。
25.在一些方面,音频源设备2可以是音频输出设备的一部分(或与音频输出设备集成)。例如,如本文所述,音频源设备的至少一些部件(诸如控制器)可以是音频输出设备的一部分。在这种情况下,每个设备可经由作为音频输出设备内一个或多个印刷电路板(pcb)的一部分的迹线通信地耦接。
26.在一个实施方案中,音频输出设备3可以是被布置为将声音输出到周围环境中的任何电子设备。如本文所述,设备可由用户穿戴(例如,穿戴在用户的头部上)。其他示例可包括作为独立扬声器、智能扬声器、家庭影院系统或集成在车辆内的信息娱乐系统中至少一者的一部分的输出设备。
27.图2示出了根据一个方面的执行自适应音量控制的音频系统1的框图。具体地讲,系统1包括具有至少一个控制器21的音频源设备2、音频输出设备5和输入音频源20。在一个实施方案中,该系统可包括一个或多个设备,诸如两个或更多个音频输出设备。
28.音频输出设备5包括至少一个扬声器22。例如,如本文所述,音频输出设备可以是具有至少两个扬声器(被布置为将声音输出到用户的左耳中的一个左扬声器和被布置为将声音输出到用户的右耳中的右扬声器)的头戴式耳机(例如,贴耳式、入耳式或罩耳式头戴受话器)。在一个方面,输出设备5可与图1的输出设备3相同或类似。
29.在一个方面,扬声器22例如可以是可被专门设计用于特定频带的声音输出的电动驱动器,诸如低音扬声器、高音扬声器或中音驱动器。在一个方面,扬声器可以是“全音域”(或“全频”)电动驱动器,其尽可能多地再现可听频率范围。
30.在一个方面,音频输出设备5可以是不从外部源(例如,ac干线)或内部源(例如,集成在其中的电池存储装置)汲取电力以向音频放大器供电用于驱动扬声器22的“无源”或“不通电”设备。例如,音频输出设备可以是有线耳机(例如,耳塞)或头戴受话器(例如,贴耳式头戴受话器),其在(经由有线连接)通信地耦接到音频源设备2时从源设备汲取电力以驱动扬声器22。具体地讲,当音频源设备(例如,在其中执行的媒体播放器软件程序)回放音频信号(包含音频内容,诸如音乐)时,信号可通过音频源设备的放大器电路(未示出)以放大信号。经放大的信号然后(经由有线连接)被传输给音频输出设备以驱动其中包含的扬声器。在一个方面,音频输出设备可以不包含音频放大器。
31.输入音频源20可包括正在运行媒体播放器软件应用程序的经编程处理器,并且可包括正产生输入音频信号作为对音频源设备2(例如,其控制器21)的数字音频输入的解码
器。在一个方面,经编程处理器可以是音频源设备2的一部分,使得媒体播放器在设备内执行。在另一方面,媒体播放器可由另一电子设备(例如,其一个或多个经编程处理器)执行。在这种情况下,执行媒体播放器的电子设备可(例如,无线地)将输入音频信号传输给音频源设备。在一些方面,解码器可以能够解码利用任何合适的音频编解码(诸如例如高级音频编码(aac)、mpeg音频层ii、mpeg音频层iii或自由无损音频编解码(flac))进行编码的经编码音频信号。另选地,输入音频源20可包括编解码器,该编解码器将例如来自线路输入的模拟或光学音频信号转换成用于控制器的数字形式。另选地,可存在多于一个输入音频声道,诸如双声道输入,即音乐作品的立体声录音的左声道和右声道,或者可存在多于两个输入音频声道,诸如例如5.1环绕格式的电影胶片或电影的整个音频音轨。在一个方面,输入源20可提供数字输入或模拟输入。
32.控制器21可以是专用处理器诸如专用集成电路(asic)、通用微处理器、现场可编程门阵列(fpga)、数字信号控制器或一组硬件逻辑结构(例如滤波器、算术逻辑单元以及专用状态机)。控制器可被配置为执行声学剂量测定过程操作和自适应音量控制。例如,控制器可被配置为响应于确定扬声器22的估计spl处于(或高于)阈值水平而应用增益来降低输入音频信号的声音水平以产生输出音频信号(具有比输入音频信号减小的声音水平)。在一个方面,当输出音频信号用于驱动扬声器时,扬声器的输出声音水平可处于或低于阈值。本文描述关于由控制器21执行的操作的更多内容。在一个方面,由控制器21执行的操作可在软件中实现(例如,作为存储在音频源设备2的存储器中并由控制器执行的指令)并且/或者可由如本文所述的硬件逻辑结构实现。
33.在一个方面,控制器21可执行一个或多个其它操作,诸如音频信号处理操作。例如,控制器21可被配置为对音频信号执行均衡操作(例如,频谱成形)。
34.在一个方面,音频源设备2可包括更多或更少的部件。例如,源设备可包括被配置为呈现数字图像或视频的显示屏(例如,如图1所示)。又如,源设备可包括被布置为将由在声学环境中传播的声波引起的声能转换成麦克风信号的一个或多个麦克风。在另一方面,音频源设备可包括被配置为与另一电子设备建立通信链路的网络接口。例如,接口可被配置为利用任何无线通信方法(例如,bluetooth协议、无线本地网络链路等)与一个或多个其他设备建立无线连接以交换(例如,音频)数据。
35.如图所示,控制器21可具有一个或多个操作块,所述操作块可包括(第二)标量增益23、用户音量设置24和自适应音量控件25。用户音量设置可为例如表示音频系统的(用户定义的)声音输出水平的音量设置(或水平)值。例如,较高音量设置可对应于用户期望较高声音输出水平用于系统(例如,其扬声器22)(例如,在回放音乐时)的音频回放。在一个方面,用户音量设置可以是值范围内的值诸如零至十之间的数字或百分比值。在另一方面,音量设置可以分贝(db)为单位。在一些方面,用户音量设置可以是用户经由一个或多个音量控件(未示出)限定的。例如,音量设置可对应于在音频系统的显示屏(例如,音频源设备2的显示屏)上显示的用户界面(ui)音量滑块控件的滑块位置。在另一方面,音量控件可以是作为音频源设备的一部分的一个或多个物理按钮。
36.在一个方面,标量增益23被配置为对输入音频信号(的至少一部分)应用标量增益(或增益值)以调节(例如,减小或增大)输入音频信号的电平(或量值),从而产生经增益调节的音频信号。在一个方面,标量增益23可被配置为在模拟域中(例如,当信号是模拟信号
时)将增益应用于信号。在另一方面,标量增益23可被配置为在数字域中应用增益(例如,当信号是数字音频信号时)。在一个方面,标量增益23可调节输入音频信号的某些部分,诸如某些频率。在另一方面,标量增益23可通过执行音频压缩操作诸如动态范围压缩(drc)来对输入音频信号的部分应用一个或多个增益值。
37.在一个方面,用户音量设置24基于音量设置来定义标量增益23(例如,由其应用的增益值)。例如,用户音量设置越高(例如,0%至100%的90%),当信号用于驱动扬声器时,越高的增益值可被标量增益23应用于输入音频信号以增大扬声器22的声音输出水平。类似地,越低的用户音量设置可导致越低的增益值被标量增益应用,从而降低扬声器22的声音输出水平。在一个方面,标量增益23可基于用户音量设置来确定要应用于输入音频信号的增益值。例如,标量增益可利用用户音量设置执行表格查找到将增益值与用户音量设置相关联的数据结构中。在另一方面,标量增益可使用用户音量设置来确定增益值(例如,通过将用户音量设置应用于预定义的函数或算法中)。
38.在一个方面,用户音量设置24可以是软件应用程序中的“软件”用户音量设置,诸如由音频源设备的控制器21执行的媒体播放器软件应用程序。具体地讲,软件音量设置可以是软件应用程序根据音量设置(在标量增益23处)修改(或调节)输入音频信号的设置。例如,响应于确定软件用户音量设置(例如,基于音频源设备的用户设置ui音量控件的滑块位置),控制器执行的软件应用程序对输入音频信号执行音频信号处理操作(例如,由标量增益23执行以应用增益的操作)以调节(增大和/或减小)信号的至少一些频谱部分,从而产生经增益调节的音频信号。
39.自适应音量控件25被配置为基于音频输出设备5的扬声器22的估计声音输出水平来调节音频源设备2的音量控制。例如,自适应音量控件可提供扬声器的声音输出水平不超过(例如,用户定义的)阈值。这确保音频系统的用户(或收听者)不暴露于可能导致暂时或永久性听力损失的过度的声音水平。该控件包括声音输出水平估计器26、增益计算27、(第一)标量增益28和设备数据存储29。
40.在一个方面,设备数据存储29可包括与一个或多个设备相关联的数据作为被存储在音频源设备2中(例如,在其中的存储器内)的数据结构。具体地讲,存储29可包括设备的部件的数据,诸如一个或多个音频输出设备的一个或多个扬声器。例如,存储可包括音频输出设备的一个或多个扬声器(例如,扬声器22)的(预定义的)声音输出灵敏度(单位为db)、阻抗(单位为欧姆)、功率处理(单位为瓦特)和频率响应中的至少一者。
41.在一个方面,音频源设备2可从远程位置获取设备数据。例如,音频源设备2可(通过互联网)从远程服务器获取(与一个或多个设备相关联的)设备数据。又如,源设备可从音频输出设备5获取数据中的至少一些。例如,一旦音频输出设备5与源设备配对(例如,当输出设备通信地耦接时),音频输出设备可(例如,响应于来自音频源设备的请求)将数据传输给源设备。在另一方面,音频输出设备可将唯一地标识音频输出设备的唯一标识符传输给音频源设备,音频源设备使用该标识符获取设备数据(例如,经由到设备数据存储中的表格查找,其可将唯一标识符与设备数据相关联)。如本文所述,可获取设备数据以执行自适应音量控制操作。
42.声音输出水平估计器26被配置为基于输入音频信号、音频系统1的用户音量设置和音频输出设备5的设备数据(例如,声音输出灵敏度)来估计(或确定)音频输出设备的声
音输出水平(例如,spl值)。具体地讲,估计器26获取1)用户音量设置24、2)由标量增益23产生的经增益调节的音频信号以及3)来自设备数据存储29的音频输出设备的设备数据。在一个方面,估计器26可获取设备数据,如本文所述。例如,估计器可从音频输出设备获取唯一标识符,并且执行表格查找到设备数据存储中。在一些方面,如果估计器26不能从音频输出设备获取标识(或设备数据),则估计器可从设备数据存储29检索默认设备数据。
43.在一个方面,为了估计声音输出水平,估计器26可将(经增益调节的)输入音频信号、用户音量设置和设备数据应用于(例如,存储在存储器中的)声音输出水平模型以估计声音输出水平。例如,如果扬声器要输出经增益调节的输入音频信号,则模型的输出可表示扬声器22处的估计声音水平。在一个方面,声音输出水平是扬声器22的输出a加权spl估计。
44.增益计算27被配置为获取spl估计并且被配置为基于spl估计调整音量设置。具体地讲,增益控制被配置为基于spl估计来确定要应用于输入音频信号的标量增益。在一个方面,增益控制可被配置为确定spl估计是否高于阈值。在一个方面,阈值可以是用户定义的。例如,音频系统1的(音频源设备2的)用户可经由在源设备的显示屏上显示的用户界面来在用户设置(例如,父母控制)中定义阈值。在另一方面,阈值可由源设备的制造商或由第三方(例如,基于who听力健康和安全标准,如本文所述)预定义。如果spl估计高于阈值,则增益计算27被配置为通过确定要应用于输入音频信号的标量增益来调节(或调整)音量控制。在一个方面,增益计算27可基于spl估计和阈值之间的差值来确定标量增益。例如,当spl估计比阈值高10%时,增益控制可确定将成比例地减小输入音频信号(或更确切地说,经增益调节的音频信号)的标量增益。在另一方面,增益计算可基于spl估计和阈值之间的差值来执行表格查找到指示增益值(例如,水平降低)的(存储在音频源设备的存储器内的)数据结构中。
45.(第一)标量增益28被配置为(例如,通过应用增益值)调节经增益调节的音频信号的信号电平以产生输出音频信号,该输出音频信号在用于驱动扬声器22时将具有处于(或小于)增益计算27所使用的阈值的声音输出水平。具体地讲,标量增益28获取经增益调节的音频信号(从标量增益23)并获取由增益计算27确定的增益值,并且将增益值应用于经增益调节的音频信号。在一个方面,标量增益28可执行与标量增益23类似的操作。例如,标量增益28可基于增益计算27所确定和获取的增益值来应用音频压缩操作,诸如drc。在另一方面,标量增益28可应用增益值以降低经增益调节的音频信号(的至少一部分)的电平,从而产生输出音频信号,该输出音频信号在用于驱动扬声器22时具有比输入音频信号(和/或经增益调节的音频信号)低的声音输出水平。
46.在一个方面,增益计算27可任选地获取用户音量设置24,并且使用该设置来增强音量控制的调整。具体地讲,增益计算27可根据所确定的标量增益(和/或根据spl估计与阈值之间的差值)来调节设置24。因此,系统可例如通过减小可(例如,在音频源设备2的显示屏上)向用户显示的设置来调整音量设置。
47.图3示出了根据另一方面的执行自适应音量控制的音频系统1的框图。音频系统包括输入音频源20、音频源设备2和音频输出设备6。音频输出设备6包括控制器30、数模转换器(dac)31、音频放大器(amp)32和扬声器33。在一个方面,输出设备可包括更多部件。例如,设备6可包括若干扬声器,诸如当设备是头戴式耳机时可包括左扬声器和右扬声器。在该示例中,每个扬声器的信号路径可包括至少一个dac和至少一个amp。
48.dac 31被布置为接收作为可由控制器30产生(和/或作为数字音频信号从音频源设备2获取)的输出数字音频信号的(例如,输出)音频信号,并且将其转换为模拟信号。amp 32被布置为从dac获取模拟信号并且用于向扬声器33提供驱动信号。在一个方面,amp用于放大模拟信号(例如,放大到高到足以驱动扬声器33的电平)。尽管dac和amp被图示成分开的块,但是在一个方面中,用于这些的电子电路部件可被组合,以便提供驱动信号的更高效的数模转换和放大操作,例如使用d类放大器技术。
49.在一个方面,音频输出设备6可以是“有源”或“通电”设备,其从(外部和/或内部)电源汲取电力以向其部件中的至少一些供电。例如,音频输出设备可以是有线或无线头戴受话器,其在与音频源设备2配对(例如,经由有线和/或无线连接通信地耦接到音频源设备2)时,从内部源(例如,电池存储)汲取电力以对amp 32供电以用于驱动扬声器33。此类音频输出设备的示例可为可经由任何无线协议诸如bluetooth协议与音频源设备配对的一对无线耳机,如图1所示。
50.如图所示,控制器30可具有一个或多个操作块,所述操作块可包括用户音量设置34和标量增益35。在一个方面,控制器30可包括控制器21的至少一些(其他)操作块,诸如存储音频输出设备6的设备数据的设备数据存储。用户音量设置34可为例如表示音频系统的(用户定义的)声音输出水平的音量设置(水平)值。在一个方面,用户音量设定34可以是经由一个或多个音量控件诸如作为音频输出设备6的一部分的一个或多个物理音量控件由用户定义的。在一个方面,用户音量设置34可以是用于输出设备6的硬件部件(例如,dac 31或amp 32)的“硬件”用户音量设置。
51.标量增益35可执行与标量增益23(和/或增益28)类似的操作。具体地讲,标量增益35用于(例如,经由有线或无线连接)从音频源设备(或直接从输入音频源20)获取输入音频信号,并且用于应用增益值以产生输出音频信号。
52.在一个方面,控制器30可执行一个或多个附加音频信号处理操作。例如,控制器可被配置为执行主动噪声消除(anc)操作。在一些方面,音频输出设备6可包括被配置为将由在声学环境中传播的声波导致的声能转换成麦克风信号的一个或多个麦克风(例如,差分压力梯度微机电系统(mems)麦克风)。控制器可获取一个或多个麦克风信号并执行anc操作以产生用于通过扬声器33输出的反噪声,以便降低来自环境的环境噪声。在另一方面,控制器可执行环境声音增强(ase)操作,其中由输出设备回放的声音是由设备的一个或多个麦克风捕获的环境声音的再现。因此,当输出设备为头戴式耳机时,该设备可以“透明”方式操作,例如,好像头戴式耳机没有被用户佩戴那样。为了执行ase操作,控制器可用一个或多个ase滤波器处理一个或多个麦克风信号,这降低由于头戴式耳机佩戴在用户的耳朵上方(上或里)而引起的声学遮蔽。
53.如本文所述,图3示出了被配置为执行自适应音量控制的另一方面的音频系统1。具体地讲,该图例示执行类似和/或不同操作的图2所示操作块中的至少一些以及附加操作块。例如,在图3中,声音输出水平估计器26被配置为基于输入音频信号、(硬件)用户音量设置34和设备数据29来估计音频输出设备的声音输出水平。在一个方面,估计器例如经由无线连接从音频输出设备6获取用户音量设置(例如,作为由输出设备6无线传输并由源设备2接收的数据分组)。在另一方面,估计器从输入音频源20获取输入音频信号。换句话讲,所获取的输入音频信号可不被控制器21修改(例如,没有执行音频处理操作,诸如应用标量增
益)。增益计算27被配置为获取spl估计(以及任选地,获取用户音量设置34),并且被配置为通过基于spl估计确定要应用于输入音频信号的增益值来调整(调节)音量控制(或设置),如本文所述。
54.在一个方面,音频输出设备6被配置为对输入音频信号执行音频信号处理操作,以便自适应地控制系统的音量。具体地讲,音频输出设备6被配置为执行图2的描述中由音频源设备2执行的操作中的至少一些操作,以降低输出设备的扬声器(例如,扬声器33)的声音输出水平。例如,控制器30包括标量增益35,该标量增益被配置为(例如,经由有线或无线连接)从音频源设备获取输入音频信号和(由增益计算27确定的)增益值,并且被配置为将增益值应用于所获取的输入音频信号以产生用于由输出设备输出的输出音频信号。标量增益可将输入音频信号的至少一部分的信号电平减小增益值以产生输出音频信号,如本文所述。在一个方面,音频输出设备可从输入音频源20获取输入音频信号。
55.在另一方面,音频输出设备6可被配置为执行音频信号处理操作以自适应地控制音量,如本文所述。具体地讲,音频输出设备(的控制器30)可执行音频源设备2的所有操作。在这种情况下,音频输出设备的控制器可被配置为从输入音频源20(其可以是音频输出设备的一部分)获取输入音频信号,并且执行本文所述的操作(例如,图2至图4的操作)
56.图4是执行自适应音量控制的过程40的一个方面的流程图。在一个方面,过程40由音频系统1(例如,其音频源设备2的控制器21和/或音频源设备30的控制器30)执行。因此,该图将参考图1至图3来描述。过程40开始于获取输入音频信号(在框41处)。例如,音频源设备2可从输入音频源20获取输入音频信号。过程40基于(所获取的)输入音频信号、音频系统的用户音量设置和输出设备的声音输出灵敏度来确定音频输出设备的声音输出水平(在框42处)。具体地讲,估计器26基于本文所述标准中的至少一者来确定spl估计。过程40确定声音输出水平是否高于阈值(在决策框43处)。如本文所述,阈值可以是用户定义的阈值(例如,基于父母控制)或预定义的阈值。如果是,则过程40基于声音输出水平和阈值来确定标量增益(增益值)(在框44处)。具体地讲,增益计算可基于声音输出水平和阈值之间的差值来确定增益值。例如,如果声音输出水平比阈值高3db,则增益值可为
‑
3db。过程40对输入音频信号应用增益值以产生输出音频信号(在框45处)。例如,标量增益28可响应于spl估计处于或高于阈值而对经增益调节的音频信号应用增益值。过程40通知用户自适应音量控制被激活(在框46处)。例如,音频系统可输出自适应音量控制正在主动减小声音输出的音量的通知。例如,音频系统1可经由扬声器(例如,扬声器22)输出警示音频“音量已减小”。具体地讲,音频源设备可将警示音频作为音频信号传输给音频输出设备5以驱动扬声器22。又如,音频源设备通过(例如,在设备的显示屏上)显示提醒用户音量减小的视觉消息来通过通知输出。
57.一些方面执行图4所示的过程40的变型。例如,这些过程中的至少一些的特定操作可以不以所示出和所描述的确切顺序执行。可不在连续的一系列操作中执行该特定操作,并且可在不同方面中执行不同的特定操作。例如,如本文所述,可任选地执行框46所执行的操作。
58.如本文所述,音频系统1可基于某些标准执行图2至图4所述的操作中的至少一些操作。在一个方面,音频系统可基于音频输出设备是不通电设备还是通电设备来执行操作中的至少一些操作。例如,当音频输出设备是不通电设备时,音频系统1可执行图2的操作,
并且当音频输出设备是通电设备时,音频系统1可执行图3的操作。
59.图5是基于音频输出设备是否是通电设备而执行不同自适应音量控制的过程50的一个方面的流程图。在一个方面,过程50由音频系统1的音频源设备2(和/或音频输出设备,诸如设备6)执行,如本文所述。因此,该图将参考图1至图3来描述。该过程开始于确定音频输出设备是否为通电设备(在决策框51处)。如本文所述,音频系统1可基于源设备2和输出设备之间的通信来进行这个决策。例如,输出设备可传输消息(例如,作为经由有线或无线连接的一个或多个数据分组),该消息指示设备是否通电。例如,输出设备是否为通电设备的指示可以是指示设备数据(例如,灵敏度)和/或唯一标识符的响应(或传输),如本文所述。
60.如果不是,则过程50基于软件用户音量设置对输入音频信号应用第一标量增益以产生经增益调节的音频信号(在框52处)。例如,标量增益23可基于用户音量设置24对输入音频信号应用第一标量增益。过程50基于经增益调节的音频信号、软件用户音量设置和音频输出设备的灵敏度来估计音频输出设备的声音输出水平(在框53处)。如本文所述,声音输出水平估计器26基于这些标准中的至少一者来估计spl。过程50基于所估计的声音输出水平来确定第二标量增益(在框54处)。在一个方面,增益计算27可基于所估计的声音输出水平和阈值来确定第二标量增益,如本文所述。过程40将第二标量增益应用于经增益调节的音频信号以产生输出音频信号(在框55处)。过程50将输出音频信号传输给音频输出设备以驱动音频输出设备的扬声器(在框56处)。在一个方面,由框52
‑
56执行的操作可由音频源设备2执行,如参考图图2所述。
61.然而,如果音频输出设备是通电设备,则过程50从音频输出设备获取硬件用户音量设置(例如,由音量控件设置)(在框57处)。过程50基于输入音频信号、硬件用户音量设置和音频输出设备的灵敏度来估计音频输出设备的声音输出水平(在框58处)。过程50基于所估计的声音输出水平来确定标量增益(在框59处)。过程50将输入音频信号和标量增益传输给音频输出设备,使得音频输出设备将标量增益应用于输入音频信号以产生输出音频信号来驱动音频输出设备的扬声器(在框60处)。在一个方面,由框56
‑
60执行的操作可由音频源设备2执行,如参考图图3所述。
62.一些方面执行图5中所述的过程50的变型。例如,这些过程中的至少一些的特定操作可以不以所示出和所描述的确切顺序执行。可不在连续的一系列操作中执行该特定操作,并且可在不同方面中执行不同的特定操作。在一个方面,音频系统1可基于某些条件执行框52
‑
56(而不是框57
‑
60)的操作。例如,音频系统可基于用户(或系统设置)执行此类操作。例如,系统可默认执行框52
‑
56的操作,这意味着在确定源设备和输出设备配对时,系统可执行这些操作,直到系统确定输出设备是通电设备(例如,基于两个设备之间的通信)。在另一方面,系统可执行这些操作,而无论输出设备是否为通电设备(例如,基于系统设置)。因此,在决策框51处,系统可在确定设置指示执行这些操作时前进至框52。
63.在一个方面,图4和图5的过程40和/或过程50的操作中的至少一些可由机器学习算法来执行,该机器学习算法被配置为估计声音输出水平并根据所估计的水平来调整音量控制,以便确保输出设备的扬声器的输出不超过阈值。在另一方面,机器学习算法可包括被配置为执行本文所述操作的一个或多个神经网络(例如,卷积神经网络、递归神经网络等)。
64.在一个方面,本文所述的操作中的至少一些是可执行或可不执行的操作性操作。
具体地讲,可任选地执行被示出为具有虚线或虚线边界的框。例如,框52可为可操作的,因为由自适应音量控制25获取的音频信号可能已被增益调节。在另一方面,相对于其他框所述的其他操作也可以是任选的。
65.要使用的个人信息应遵循通常公认为满足(和/或超过)维护用户隐私的政府和/或行业要求的实践和隐私政策。例如,任何信息都应该被管理以便降低未经授权或无意访问或使用的风险,并且应清楚地通知用户任何经授权使用的性质。
66.如前所述,本公开的一个方面可为其上存储有指令的非暂态机器可读介质(诸如微电子存储器),所述指令对一个或多个数据处理部件(这里一般性地称为“处理器”)进行编程以执行网络操作、信号处理操作、音频信号处理操作以及自适应音量控制操作。在其他方面,可通过包含硬连线逻辑的特定硬件部件来执行这些操作中的一些操作。另选地,可通过所编程的数据处理部件和固定硬连线电路部件的任何组合来执行那些操作。
67.虽然已经在附图中描述和示出了某些方面,但是应当理解,此类方面仅仅是对广义公开的说明而非限制,并且本公开不限于所示出和所述的具体结构和布置,因为本领域的普通技术人员可以想到各种其他修改型式。因此,要将描述视为示例性的而非限制性的。
68.在一些方面,本公开可包括语言例如“[元素a]和[元素b]中的至少一者”。该语言可以是指这些元素中的一者或多者。例如,“a和b中的至少一者”可以是指“a”、“b”或“a和b”。具体地讲,“a和b中的至少一者”可以是指“a中至少一者和b中至少一者”或者“至少a或b任一者”。在一些方面,本公开可包括语言例如“[元素a]、[元素b]和/或[元素c]”。该语言可以是指这些元素中任一者或其任何组合。例如,“a、b和/或c”可以是指“a”、“b”、“c”、“a和b”、“a和c”、“b和c”或“a、b和c”。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。