1.本发明涉及计算机视觉应用技术领域,尤其涉及一种基于孪生网络在线更新的单目标跟踪方法及装置。
背景技术:
2.视觉目标跟踪是计算机视觉中一个重要研究方向,在军事无人飞行器、精确制导、空中预警、民用视频监控、人机交互和无人驾驶等众多领域有着极其广泛的应用。随着图像处理器(gpu)技术愈发成熟,深度学习在图像处理众多任务中均取得突破性进展,而基于深度学习的目标跟踪算法发展十分迅速,对于解决目标跟踪算法因尺度变化、遮挡、背景复杂、目标消失等原因导致跟踪失败的情况提供了相对于传统方法更好的方案。其中,孪生网络在基于深度学习的单目标跟踪领域得到了广泛的应用。但是孪生网络也存在一个明显的弊端,它始终采用的是序列的第一帧目标作为跟踪对象,在跟踪过程中没有考虑到目标的变化,当目标发生比较大的形变时,容易产生漂移导致跟踪失败。
技术实现要素:
3.为解决现有技术中存在的技术问题,本发明提供一种基于孪生网络在线更新的单目标跟踪方法及装置。
4.第一方面,本发明提供一种基于孪生网络在线更新的单目标跟踪方法,所述基于孪生网络在线更新的单目标跟踪方法包括:
5.训练过程:
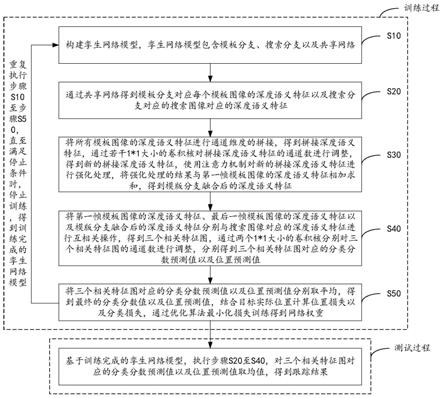
6.步骤s10,构建孪生网络模型,孪生网络模型包含模板分支、搜索分支以及共享网络;
7.步骤s20,通过共享网络得到模板分支对应每个模板图像的深度语义特征以及搜索分支对应的搜索图像对应的深度语义特征;
8.步骤s30,将所有模板图像的深度语义特征进行通道维度的拼接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整,得到新的拼接深度语义特征,使用注意力机制对新的拼接深度语义特征进行强化处理,将强化处理的结果与第一帧模板图像的深度语义特征相加求和,得到模版分支融合后的深度语义特征;
9.步骤s40,将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图,通过两个1*1大小的卷积核分别对三个相关特征图的通道数进行调整,分别得到三个相关特征图对应的分类分数预测值以及位置预测值;
10.步骤s50,将三个相关特征图对应的分类分数预测值以及位置预测值分别取平均,得到最终的分类分数值以及位置预测值,结合目标实际位置计算位置损失以及分类损失,通过优化算法最小化损失训练得到网络权重;
11.重复执行步骤s10至步骤s50,直至满足停止条件时,停止训练,得到训练完成的孪
生网络模型;
12.测试过程:
13.基于训练完成的孪生网络模型,执行步骤s20至s40,对三个相关特征图对应的分类分数预测值以及位置预测值取均值,得到跟踪结果。
14.可选的,在训练过程中,模板分支对应的模板图像包括从样本视频中随机选择的4张图像,搜索分支对应的搜索图像为样本视频中选定的一张随机图像;在测试过程中,当测试第一帧模板图像时,模板分支对应的4张模板图像均为第一帧图像,之后跟踪目标的过程中会逐步将当前图像替换进去,替换规则为:假设模板分支对应的图片样本集为w
i
,上一帧所跟踪目标w
c
得到的最大响应分数为score,分数替换阈值为t,当score≥t,将w1替换为w
c
,如果score<t,样本集不变,保持w0不被替换,其他的图像则是最久没有被替换的优先替换,搜索分支对应的搜索图像则为当前图像。
15.可选的,所述将所有模板图像的深度语义特征进行通道维度的拼接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整的步骤包括:
16.采用3个1*1的卷积核对拼接深度语义特征的通道数进行调整,卷积核通道数分别是1024,128,256,过程如下:
[0017][0018]
其中,concat为拼接操作,w0,w1,w2,w3分别为每个模板图像对应的深度语义特征,通过concat对每个模板图像对应的深度语义特征进行拼接,得到拼接深度语义特征,conv1对应第一个通道数为1024的1*1卷积核,conv2对应第二个通道数为128的1*1卷积核,conv3对应第三个通道数为256的1*1卷积核,利用conv1、conv2、conv3将拼接深度语义特征的通道数调整成256。
[0019]
可选的,所述注意力机制包含三个分支,对于第一个分支,输入特征经过z
‑
pool,再接着7x7卷积,最后sigmoid激活函数生成通道注意力权重;对于第二个分支,输入特征先经过permute操作将维度调整为h*c*w维度特征,接着在h维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;对于第三个分支,输入特征先经过permute操作变为w*h*c维度特征,接着在w维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;其中z
‑
pool对应如下:
[0020]
z
‑
pool(χ)=[maxpool
0d
(χ),avgpool
0d
(χ)]
[0021]
其中,maxpool
0d
为针对第一维进行最大池化操作,avgpool
0d
为针对第一维进行平均池化操作,χ对应的是输入特征。
[0022]
可选的,所述将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图的步骤包括:
[0023]
将第一帧模板图像对应的深度语义特征w0和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0024]
将最后一帧模板图像对应的深度语义特征w3和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0025]
将模版分支融合后的深度语义特征m和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络。
[0026]
第二方面,本发明还提供一种基于孪生网络在线更新的单目标跟踪装置,所述基于孪生网络在线更新的单目标跟踪装置包括:
[0027]
训练模块,用于进行训练过程,训练过程包括:
[0028]
步骤s10,构建孪生网络模型,孪生网络模型包含模板分支、搜索分支以及共享网络;
[0029]
步骤s20,通过共享网络得到模板分支对应每个模板图像的深度语义特征以及搜索分支对应的搜索图像对应的深度语义特征;
[0030]
步骤s30,将所有模板图像的深度语义特征进行通道维度的拼接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整,得到新的拼接深度语义特征,使用注意力机制对新的拼接深度语义特征进行强化处理,将强化处理的结果与第一帧模板图像的深度语义特征相加求和,得到模版分支融合后的深度语义特征;
[0031]
步骤s40,将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图,通过两个1*1大小的卷积核分别对三个相关特征图的通道数进行调整,分别得到三个相关特征图对应的分类分数预测值以及位置预测值;
[0032]
步骤s50,将三个相关特征图对应的分类分数预测值以及位置预测值分别取平均,得到最终的分类分数值以及位置预测值,结合目标实际位置计算位置损失以及分类损失,通过优化算法最小化损失训练得到网络权重;
[0033]
重复执行步骤s10至步骤s50,直至满足停止条件时,停止训练,得到训练完成的孪生网络模型;
[0034]
测试模块,用于进行测试过程,测试过程包括:
[0035]
基于训练完成的孪生网络模型,执行步骤s20至s40,对三个相关特征图对应的分类分数预测值以及位置预测值取均值,得到跟踪结果。
[0036]
可选的,在训练过程中,模板分支对应的模板图像包括从样本视频中随机选择的4张图像,搜索分支对应的搜索图像为样本视频中选定的一张随机图像;在测试过程中,当测试第一帧模板图像时,模板分支对应的4张模板图像均为第一帧图像,之后跟踪目标的过程中会逐步将当前图像替换进去,替换规则为:假设模板分支对应的图片样本集为w
i
,上一帧
所跟踪目标w
c
得到的最大响应分数为score,分数替换阈值为t,当score≥t,将w1替换为w
c
,如果score<t,样本集不变,保持w0不被替换,其他的图像则是最久没有被替换的优先替换,搜索分支对应的搜索图像则为当前图像。
[0037]
可选的,所述将所有模板图像的深度语义特征进行通道维度的拼接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整的步骤包括:
[0038]
采用3个1*1的卷积核对拼接深度语义特征的通道数进行调整,卷积核通道数分别是1024,128,256,过程如下:
[0039][0040]
其中,concat为拼接操作,w0,w1,w2,w3分别为每个模板图像对应的深度语义特征,通过concat对每个模板图像对应的深度语义特征进行拼接,得到拼接深度语义特征,conv1对应第一个通道数为1024的1*1卷积核,conv2对应第二个通道数为128的1*1卷积核,conv3对应第三个通道数为256的1*1卷积核,利用conv1、conv2、conv3将拼接深度语义特征的通道数调整成256。
[0041]
可选的,所述注意力机制包含三个分支,对于第一个分支,输入特征经过z
‑
pool,再接着7x7卷积,最后sigmoid激活函数生成通道注意力权重;对于第二个分支,输入特征先经过permute操作将维度调整为h*c*w维度特征,接着在h维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;对于第三个分支,输入特征先经过permute操作变为w*h*c维度特征,接着在w维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;其中z
‑
pool对应如下:
[0042]
z
‑
pool(χ)=[maxpool
0d
(χ),avgpool
0d
(χ)]
[0043]
其中,maxpool
0d
为针对第一维进行最大池化操作,avgpool
0d
为针对第一维进行平均池化操作,χ对应的是输入特征。
[0044]
可选的,所述将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图的步骤包括:
[0045]
将第一帧模板图像对应的深度语义特征w0和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0046]
将最后一帧模板图像对应的深度语义特征w3和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0047]
将模版分支融合后的深度语义特征m和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络。
[0048]
本发明中,考虑到孪生网络存在一个明显的弊端,它始终采用的是序列的第一帧目标作为跟踪对象,在跟踪过程中没有考虑到目标的变化,当目标发生比较大的形变时,容易产生漂移导致跟踪失败。为了解决这种目标形变问题,本发明动态的将跟踪过程中的其他帧加入进来在线更新卷积滤波器,以此缓解目标形变导致的跟踪漂移问题,从而使得跟踪精度得到了巨大提升。
附图说明
[0049]
图1为本发明基于孪生网络在线更新的单目标跟踪方法一实施例的流程示意图。
[0050]
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0051]
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0052]
第一方面,本发明实施例提供了一种基于孪生网络在线更新的单目标跟踪方法。
[0053]
一实施例中,参照图1,图1为本发明基于孪生网络在线更新的单目标跟踪方法一实施例的流程示意图。如图1所示,基于孪生网络在线更新的单目标跟踪方法包括:
[0054]
训练过程:
[0055]
步骤s10,构建孪生网络模型,孪生网络模型包含模板分支、搜索分支以及共享网络;
[0056]
步骤s20,通过共享网络得到模板分支对应每个模板图像的深度语义特征以及搜索分支对应的搜索图像对应的深度语义特征;
[0057]
进一步地,一实施例中,在训练过程中,模板分支对应的模板图像包括从样本视频中随机选择的4张图像,搜索分支对应的搜索图像为样本视频中选定的一张随机图像;在测试过程中,当测试第一帧模板图像时,模板分支对应的4张模板图像均为第一帧图像,之后跟踪目标的过程中会逐步将当前图像替换进去,替换规则为:假设模板分支对应的图片样本集为w
i
,上一帧所跟踪目标w
c
得到的最大响应分数为score,分数替换阈值为t,当score≥t,将w1替换为w
c
,如果score<t,样本集不变,保持w0不被替换,其他的图像则是最久没有被替换的优先替换,搜索分支对应的搜索图像则为当前图像。
[0058]
本实施例中,考虑到图片过多会导致跟踪速度变慢,太少则不能充分利用上下文信息,因此,训练过程中选择5张图像作为一个训练对,其中前四张作为模板分支对应的模板图像,最后一张作为搜索分支对应的搜索图像。
[0059]
步骤s30,将所有模板图像的深度语义特征进行通道维度的拼接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整,得到新的拼接深度语义特征,使用注意力机制对新的拼接深度语义特征进行强化处理,将强化处理的结果与第一帧模板图像的深度语义特征相加求和,得到模版分支融合后的深度语义特征;
[0060]
进一步地,一实施例中,所述将所有模板图像的深度语义特征进行通道维度的拼
接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整的步骤包括:
[0061]
采用3个1*1的卷积核对拼接深度语义特征的通道数进行调整,卷积核通道数分别是1024,128,256,过程如下:
[0062][0063]
其中,concat为拼接操作,w0,w1,w2,w3分别为每个模板图像对应的深度语义特征,通过concat对每个模板图像对应的深度语义特征进行拼接,得到拼接深度语义特征,conv1对应第一个通道数为1024的1*1卷积核,conv2对应第二个通道数为128的1*1卷积核,conv3对应第三个通道数为256的1*1卷积核,利用conv1、conv2、conv3将拼接深度语义特征的通道数调整成256。
[0064]
进一步地,一实施例中,所述注意力机制包含三个分支,对于第一个分支,输入特征经过z
‑
pool,再接着7x7卷积,最后sigmoid激活函数生成通道注意力权重;对于第二个分支,输入特征先经过permute操作将维度调整为h*c*w维度特征,接着在h维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;对于第三个分支,输入特征先经过permute操作变为w*h*c维度特征,接着在w维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;其中z
‑
pool对应如下:
[0065]
z
‑
pool(χ)=[maxpool
0d
(χ),avgpool
0d
(χ)]
[0066]
其中,maxpool
0d
为针对第一维进行最大池化操作,avgpool
0d
为针对第一维进行平均池化操作,χ对应的是输入特征。
[0067]
步骤s40,将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图,通过两个1*1大小的卷积核分别对三个相关特征图的通道数进行调整,分别得到三个相关特征图对应的分类分数预测值以及位置预测值;
[0068]
进一步地,一实施例中,所述将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图的步骤包括:
[0069]
将第一帧模板图像对应的深度语义特征w0和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0070]
将最后一帧模板图像对应的深度语义特征w3和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0071]
将模版分支融合后的深度语义特征m和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络。
[0072]
步骤s50,将三个相关特征图对应的分类分数预测值以及位置预测值分别取平均,得到最终的分类分数值以及位置预测值,结合目标实际位置计算位置损失以及分类损失,通过优化算法最小化损失训练得到网络权重;
[0073]
重复执行步骤s10至步骤s50,直至满足停止条件时,停止训练,得到训练完成的孪生网络模型;
[0074]
测试过程:
[0075]
基于训练完成的孪生网络模型,执行步骤s20至s40,对三个相关特征图对应的分类分数预测值以及位置预测值取均值,得到跟踪结果。
[0076]
本实施例中,考虑到孪生网络存在一个明显的弊端,它始终采用的是序列的第一帧目标作为跟踪对象,在跟踪过程中没有考虑到目标的变化,当目标发生比较大的形变时,容易产生漂移导致跟踪失败。为了解决这种目标形变问题,本发明动态的将跟踪过程中的其他帧加入进来在线更新卷积滤波器,以此缓解目标形变导致的跟踪漂移问题,从而使得跟踪精度得到了巨大提升。
[0077]
第二方面,本发明实施例还提供一种基于孪生网络在线更新的单目标跟踪装置。
[0078]
一实施例中,基于孪生网络在线更新的单目标跟踪装置包括:
[0079]
训练模块,用于进行训练过程,训练过程包括:
[0080]
步骤s10,构建孪生网络模型,孪生网络模型包含模板分支、搜索分支以及共享网络;
[0081]
步骤s20,通过共享网络得到模板分支对应每个模板图像的深度语义特征以及搜索分支对应的搜索图像对应的深度语义特征;
[0082]
步骤s30,将所有模板图像的深度语义特征进行通道维度的拼接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整,得到新的拼接深度语义特征,使用注意力机制对新的拼接深度语义特征进行强化处理,将强化处理的结果与第一帧模板图像的深度语义特征相加求和,得到模版分支融合后的深度语义特征;
[0083]
步骤s40,将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图,通过两个1*1大小的卷积核分别对三个相关特征图的通道数进行调整,分别得到三个相关特征图对应的分类分数预测值以及位置预测值;
[0084]
步骤s50,将三个相关特征图对应的分类分数预测值以及位置预测值分别取平均,得到最终的分类分数值以及位置预测值,结合目标实际位置计算位置损失以及分类损失,通过优化算法最小化损失训练得到网络权重;
[0085]
重复执行步骤s10至步骤s50,直至满足停止条件时,停止训练,得到训练完成的孪生网络模型;
[0086]
测试模块,用于进行测试过程,测试过程包括:
[0087]
基于训练完成的孪生网络模型,执行步骤s20至s40,对三个相关特征图对应的分
类分数预测值以及位置预测值取均值,得到跟踪结果。
[0088]
进一步地,一实施例中,在训练过程中,模板分支对应的模板图像包括从样本视频中随机选择的4张图像,搜索分支对应的搜索图像为样本视频中选定的一张随机图像;在测试过程中,当测试第一帧模板图像时,模板分支对应的4张模板图像均为第一帧图像,之后跟踪目标的过程中会逐步将当前图像替换进去,替换规则为:假设模板分支对应的图片样本集为w
i
,上一帧所跟踪目标w
c
得到的最大响应分数为score,分数替换阈值为t,当score≥t,将w1替换为w
c
,如果score<t,样本集不变,保持w0不被替换,其他的图像则是最久没有被替换的优先替换,搜索分支对应的搜索图像则为当前图像。
[0089]
进一步地,一实施例中,所述将所有模板图像的深度语义特征进行通道维度的拼接,得到拼接深度语义特征,通过若干1*1大小的卷积核对拼接深度语义特征的通道数进行调整的步骤包括:
[0090]
采用3个1*1的卷积核对拼接深度语义特征的通道数进行调整,卷积核通道数分别是1024,128,256,过程如下:
[0091][0092]
其中,concat为拼接操作,w0,w1,w2,w3分别为每个模板图像对应的深度语义特征,通过concat对每个模板图像对应的深度语义特征进行拼接,得到拼接深度语义特征,conv1对应第一个通道数为1024的1*1卷积核,conv2对应第二个通道数为128的1*1卷积核,conv3对应第三个通道数为256的1*1卷积核,利用conv1、conv2、conv3将拼接深度语义特征的通道数调整成256。
[0093]
进一步地,一实施例中,所述注意力机制包含三个分支,对于第一个分支,输入特征经过z
‑
pool,再接着7x7卷积,最后sigmoid激活函数生成通道注意力权重;对于第二个分支,输入特征先经过permute操作将维度调整为h*c*w维度特征,接着在h维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;对于第三个分支,输入特征先经过permute操作变为w*h*c维度特征,接着在w维度上进行z
‑
pool,再接着7x7卷积,然后sigmoid激活函数生成通道注意力权重,最后经过permute操作变为c*h*w维度特征,方便进行element
‑
wise相加;其中z
‑
pool对应如下:
[0094]
z
‑
pool(χ)=[maxpool
0d
(χ),avgpool
0d
(χ)]
[0095]
其中,maxpool
0d
为针对第一维进行最大池化操作,avgpool
0d
为针对第一维进行平均池化操作,χ对应的是输入特征。
[0096]
进一步地,一实施例中,所述将第一帧模板图像的深度语义特征、最后一帧模板图像的深度语义特征以及模版分支融合后的深度语义特征分别与搜索图像对应的深度语义特征进行互相关操作,得到三个相关特征图的步骤包括:
[0097]
将第一帧模板图像对应的深度语义特征w0和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0098]
将最后一帧模板图像对应的深度语义特征w3和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络;
[0099]
将模版分支融合后的深度语义特征m和搜索图像对应的深度语义特征进行互相关操作,用函数ψ表示互相关操作,则得到的相关特征图为其中ξ对应共享网络。
[0100]
其中,上述基于孪生网络在线更新的单目标跟踪装置中各个模块的功能实现与上述基于孪生网络在线更新的单目标跟踪方法实施例中各步骤相对应,其功能和实现过程在此处不再一一赘述。
[0101]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0102]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
[0103]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备执行本发明各个实施例所述的方法。
[0104]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。