1.本发明涉及文本分类技术领域,特别涉及一种基于最大间隔准则的网页文本分类系统。
背景技术:
2.文本数据作为人们表达和接收信息的主要媒介,在互联网的资源中占绝大多数。因此,高效地从海量的文本数据中挖掘出有价值的信息是非常有必要的。其中,文本分类作为一种文本处理技术,在主题检测、情感分析、垃圾邮件过滤和网页分类等领域有广泛的应用。特别是在网页分类任务中,在如此大的范围内搜索信息是一个很大的挑战,而将文档排列成不同的类别会减少用户查询的搜索空间。
3.基于机器学习技术的文本分类主要包括文本预处理、文本表示和加权以及分类等步骤。词袋模型结合文本的向量空间表示具有高维性和稀疏性,为了避免维数灾难并且获得良好的分类性能,在文本分类任务中进行特征降维是必要的。过滤式特征选择方法因其可解释性以及高效性得到了广泛的研究。在文本分类中,特征项在不同类别中的文档频率经常被用来评估特征项的相关性。rehman等人在“feature selection based on a normalized difference measure for text classification”中提出了归一化差异度量(normalized difference measure,ndm)。该方法通过考虑特征项的相对文档频率大小,解决了特征项类间文档频率相等,但相关性程度不同的问题。rehman等人在“selection of the most relevant terms based on a max
‑
min ratio metric for text classification”中提出了最大最小比方法(max
‑
min ratio,mmr)。mmr通过取特征项类间文档频率最大的方式来降低稀有词的权重。kyoungok kim等人在“trigonometric comparison measure:a feature selection method for text categorization”中提出了三角比较度量(trigonometric comparison measure,tcm)。tcm在考虑了特征项在不同类别中的文档频率的同时,通过参数k来控制提高只出现在一类中特征项的权重。上述算法在文本语料库很大、语料库类高度不平衡或者稀有词较多的情况下,参数的设置是一个挑战。
技术实现要素:
4.本发明要解决的技术问题是提供一种性能好、准确度高的基于最大间隔准则的网页文本分类系统。
5.为了解决上述问题,本发明提供了基于最大间隔准则的网页文本分类系统,其包括以下步骤:
6.文本预处理模块,用于对原始文本数据进行预处理并提取文本数据;
7.文本表示模块,用于结合文本的向量空间表示,计算特征项权重,对提取的文本数据进行表示;
8.特征项排序模块,用于基于最大间隔准则对特征项进行相关性排序;
9.文本分类模块,用于利用特征选择后的训练集文本构建分类模型,并利用所述分类模型对特征选择后的测试集文本进行分类。
10.作为本发明的进一步改进,所述结合文本的向量空间表示,计算特征项权重,对提取的文本数据进行表示,包括:
11.s11、结合文本的向量空间表示,选择词t作为文本的特征项;
12.s12、输入的文本语料库包含n个文档和m个特征项,从文本语料库中统计出文档频次矩阵和词频矩阵;
13.s13、特征项权重采用tf
‑
idf计算方法,得到文本的权重表示矩阵。
14.作为本发明的进一步改进,所述文档频次矩阵所述词频矩阵
15.其中,是第j个特征项在第i个文档中的文档频次,若特征项出现在该文档中则为1,否则为0;是第j个特征项在第i个文档中出现的次数。
16.作为本发明的进一步改进,所述文本的权重表示矩阵为:
[0017][0018]
其中,n
j
是第j个特征项在文本语料库中出现过的文档数量。
[0019]
作为本发明的进一步改进,所述基于最大间隔准则对特征项进行相关性排序,包括:
[0020]
s21、通过对文档频次矩阵进行统计,获得类别在特征项上的文档频率分布以及特征项在类别上的文档频率分布,构建最大间隔准则;
[0021]
s22、通过最大间隔准则计算出文本语料库中每个特征项的判别相关性得分,按照得分降序排列得到特征项重要程度序列。
[0022]
作为本发明的进一步改进,所述文本语料库中每个特征项的判别相关性得分mmc(t)的公式如下:
[0023][0024]
其中,c
i
表示第i个类别,文本语料库共有k个类别;p(c
i
|t)是特征项出现时类别c
i
文档频率,是特征项出现时类别不是c
i
文档频率,p(t|c
i
)是属于c
i
的文档中包含特征项t的文档频率,是不属于c
i
的文档中包含特征项t的文档频率。
[0025]
作为本发明的进一步改进,还包括:
[0026]
分类性能评估模块,用于对分类模型进行性能评估。
[0027]
作为本发明的进一步改进,所述预处理包括文本分词。
[0028]
作为本发明的进一步改进,所述预处理包括文本清洗。
[0029]
作为本发明的进一步改进,所述预处理包括文本标准化。
[0030]
本发明的有益效果:
[0031]
本发明基于最大间隔准则的网页文本分类系统在选择较少数量的特征项时,能够选择出更具有判别性的特征词,提高了网页文本分类的性能,具有适用性强,准确度高的优点。
[0032]
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
[0033]
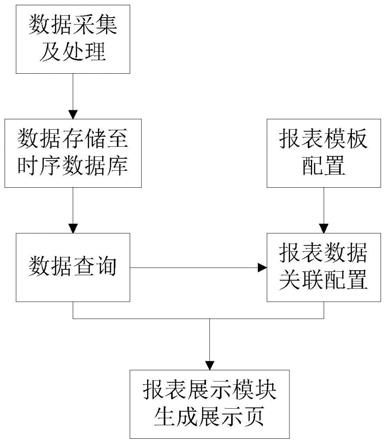
图1是本发明优选实施例中基于最大间隔准则的网页文本分类系统的示意图;
[0034]
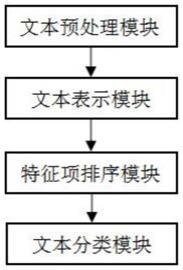
图2是本发明优选实施例中基于最大间隔准则的网页文本分类系统的文本分类流程图。
具体实施方式
[0035]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
[0036]
如图1所示,本发明优选实施例中的基于最大间隔准则的网页文本分类系统包括以下模块:
[0037]
文本预处理模块,用于对原始文本数据进行预处理并提取文本数据;
[0038]
所述预处理包括:
[0039]
文本分词:基于不同语种,结合不同分词算法进行文本分词。
[0040]
文本清洗:结合文本语料库的领域和任务,去除可能干扰文本分析的字符、数字和文本:并且,利用标准停用词表,去除文本中的停用词。
[0041]
文本标准化:词干提取只适用于部分语种文本,最常见的是porters算法,对英语很有效。
[0042]
文本表示模块,用于结合文本的向量空间表示,计算特征项权重,对提取的文本数据进行表示;具体包括:
[0043]
s11、结合文本的向量空间表示,选择词t作为文本的特征项;
[0044]
s12、输入的文本语料库包含n个文档和m个特征项,从文本语料库中统计出文档频次矩阵和词频矩阵
[0045]
其中,是第j个特征项在第i个文档中的文档频次,若特征项出现在该文档中则为1,否则为0;是第j个特征项在第i个文档中出现的次数。
[0046]
s13、特征项权重采用tf
‑
idf计算方法,得到文本的权重表示矩阵:
[0047]
[0048]
其中,n
j
是第j个特征项在文本语料库中出现过的文档数量。
[0049]
特征项排序模块,用于基于最大间隔准则对特征项进行相关性排序;具体包括:
[0050]
s21、通过对文档频次矩阵进行统计,获得类别在特征项上的文档频率分布以及特征项在类别上的文档频率分布,构建最大间隔准则:
[0051][0052]
其中,c
i
表示第i个类别,文本语料库共有k个类别;p(c
i
|t)是特征项出现时类别c
i
文档频率,是特征项出现时类别不是c
i
文档频率,p(t|c
i
)是属于c
i
的文档中包含特征项t的文档频率,是不属于c
i
的文档中包含特征项t的文档频率。
[0053]
s22、通过最大间隔准则计算出文本语料库中每个特征项的判别相关性得分mmc(t),按照得分降序排列得到特征项重要程度序列。
[0054]
文本分类模块,用于利用特征选择后的训练集文本构建分类模型,并利用所述分类模型对特征选择后的测试集文本进行分类。参照图2。
[0055]
其中,文本分类模块是利用已有的分类器来处理上述经过特征选择后的数据集。一般来说,可以由两个阶段构成,分别为学习阶段和分类阶段,其中学习阶段的主要任务是根据特征选择后的训练集文本构建一个分类模型,分类阶段是利用学习阶段构建好的分类模型对特征选择后的测试集文本进行分类。
[0056]
进一步的,该系统还包括:
[0057]
分类性能评估模块,用于对分类模型进行性能评估。
[0058]
在一具体实施例中,选取了webace project中的wap文本数据集进行测试,该数据集被分为20个类别,共包含1560个网页,8460个特征项。同时,wap文本语料库类倾斜度高,适合验证本发明的性能。具体实施步骤如下:
[0059]
一、通过文本预处理模块对原始文本数据进行预处理并提取文本数据,具体包括:
[0060]
(1)文本分词。wap文本数据集用英文表示,利用python第三方库nltk提供的word_tokenize工具对文本进行分词。
[0061]
(2)文本清洗。去除可能干扰文本分析的字符、数字和文本。并且,根据python第三方库nltk提供的标准停用词表,去除wap文本数据集中的停用词。
[0062]
(3)文本标准化。利用porters算法对wap文本数据集进行词干提取,获得8460个特征项(词)。
[0063]
二、通过文本表示模块结合文本的向量空间表示,计算特征项权重,对提取的文本数据进行表示,具体包括:
[0064]
wap文本语料库包含1560个文档和8460个特征项,从文本语料库中统计出文档频次矩阵和词频矩阵其中是第j个特征项在第i个文档中的文档频次,若出现在该文档则为1,否则为0。是第j个特征项在
第i个文档中出现的次数。特征项权重采用tf
‑
idf计算方式,得到文本的权重表示矩阵其中其中n
j
是第j个特征项在文本语料库中出现过的文档数量。
[0065]
三、通过特征项排序模块基于最大间隔准则对特征项进行相关性排序;
[0066]
四、通过文本分类模块利用特征选择后的训练集文本构建分类模型,并利用所述分类模型对特征选择后的测试集文本进行分类。
[0067]
进一步的,为了验证本发明的性能,采用五折交叉验证的方式,将wap数据集随机划分为五份,每次实验选择其中一份作为测试集,其余四份作为训练集进行特征项排序。选择特征项数量为[10,20,100,200,500,1000,1500],利用线性支持向量机、逻辑回归以及多项式分布朴素贝叶斯三种分类器在选择不同数量特征项时对测试集进行分类,对最终结果取五次实验的均值。文本特征选择对比方法包括归一化差异度量(ndm)、最大最小比(mmr)以及三角比较度量(tcm)。采用宏平均f1值(macro
‑
f1)和微平均f1值(micro
‑
f1)两个指标衡量网页文本分类效果,结果如表1和表2所示。在三个分类器上,可以看出本发明相较于其他方法,在选择较少数量的特征项时,能够选择出更具有判别性的特征词,提高了网页文本分类的性能。
[0068]
表1文本特征选择的micro
‑
f1结果对比
[0069][0070]
表2文本特征选择的macro
‑
f1结果对比
[0071][0072]
本发明基于最大间隔准则的网页文本分类系统在选择较少数量的特征项时,能够选择出更具有判别性的特征词,提高了网页文本分类的性能,具有适用性强,准确度高的优点。
[0073]
以上实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。