1.本公开内容关于一种数据标注系统,其能对文字文件进行标注,并根据标注后的结果调整数据分析模型。
背景技术:
2.在机器学习与深度学习领域中,电脑利用数据分析模型对文件进行分析与解读。由于数据分析模型的建立需要大量的训练数据,而训练数据的品质好坏对于模型的准确率至关重要。因此,在不耗费大量成本的情境下,要如何有效率且有系统地整合训练数据,将是一个值得探究的重要课题。
技术实现要素:
3.本公开内容的一实施例为一种数据标注方法,包括下列步骤:建立标注规范,根据标注规范产生至少一个问题。通过终端装置,根据问题在文字文件中标注至少一个答案。根据标注格式,将些问题及答案转换为标注数据。判断标注数据中的问题的数量是否大于或等于门槛值。若问题的数量大于或等于门槛值,根据标注数据产生阅读理解数据集。
4.本公开内容的一实施例为一种数据标注方法,包括下列步骤:通过终端装置,根据标注规范在原始数据中标注至少一组分析数据,其中每一组分析数据包含至少一个问题及至少一答案。根据标注格式,将所述分析数据转换为标注数据。通过服务器,判断标注数据中的该至少一组分析数据的数量是否大于或等于门槛值。将标注数据作为数据分析模型的训练数据,以对数据分析模型进行训练。
5.本公开内容的一实施例为一种数据标注系统,包含服务器及终端装置。服务器存储原始数据及标注规范。终端装置连线于服务器,以接收原始数据及标注规范。终端装置用以根据标注规范及原始数据产生至少一个问题,且于原始数据中标注至少一个答案。终端装置还用以将问题及该答案转换为标注数据。在标注数据中的问题的数量大于或等于门槛值时,服务器根据标注数据产生阅读理解数据集。
6.据此,通过标注规范,即可确保终端装置产生的分析数据、问题及答案的标注方式具有统一的水准,使得服务器产生的阅读理解数据集能有效地对数据分析模型进行训练。
附图说明
7.图1为根据本公开内容的部分实施例的数据标注系统的示意图。
8.图2a及图2b为根据本公开内容的部分实施例的原始文件及分析数据的示意图。
9.图3为根据本公开内容的部分实施例的数据标注方法的步骤流程图。
10.其中,附图标记说明如下:
11.100:数据标注系统
12.110:服务器
13.111:处理器
14.111a:数据分析模型
15.112:存储单元
16.112a:标注规范
17.112b:门槛值
18.120:终端装置
19.d1:原始数据
20.d2:测试数据
21.d3:分析数据
22.s301-s311:步骤
23.p1:测试程序
24.p2:标注程序
具体实施方式
25.以下将以附图说明本发明的多个实施方式,为明确说明起见,许多实务上的细节将在以下叙述中一并说明。然而,应了解到,这些实务上的细节不应用以限制本发明。也就是说,在本发明部分实施方式中,这些实务上的细节是非必要的。此外,为简化附图起见,一些现有惯用的结构与元件在附图中将以简单示意的方式示出。
26.于本文中,当一元件被称为“连接”或“耦接”时,可指“电性连接”或“电性耦接”。“连接”或“耦接”亦可用以表示两个或多个元件间相互搭配操作或互动。此外,虽然本文中使用“第一”、“第二”、
…
等用语描述不同元件,该用语仅是用以区别以相同技术用语描述的元件或操作。除非上下文清楚指明,否则该用语并非特别指称或暗示次序或顺位,亦非用以限定本发明。
27.请参阅图1所示,是本公开内容的部分实施例的数据标注系统100的示意图。数据标注系统100包含服务器110及至少一个终端装置120。服务器110存储有原始数据d1及标注规范112a。在部分实施例中,服务器110包含处理器111及存储单元112。处理器111用以执行数据运算。处理器160可为中央处理器(central processing unit,cpu)、系统单芯片(system on chip,soc)、应用处理器或特定功能的处理芯片或控制器。此外,处理器111可通过数据分析模型111a,对文件进行分析判读。
28.存储单元112用以存储原始数据d1、测试数据d2、标注规范112a及门槛值112b。在部分实施例中,存储单元112可以被实作为只读存储器、快闪存储器、软盘、硬盘、u盘、可由网络存取的数据库或本领域技术人员可轻易思及具有相同功能的存储媒体或装置。原始数据d1包含文字文件,例如一篇文章或一个网页的文字内容。在其他实施例中,原始数据d1还可包含图文件、音频文件或影片文件。
29.终端装置120连线至服务器110,以接收原始数据d1及标注规范112a。每个终端装置120根据标注规范112a及原始数据d1产生至少一组分析数据。每组分析数据包含问题及对应的答案。意即,终端装置120用以产生至少一个问题及至少一个答案,且每个问题将对应到至少一个答案。
30.标注规范112a包含多个分析原始数据d1的规则,使终端装置产生的分析数据能具有一致的水准。在部分实施例中,标注规范112a包含问题撷取规则、答案撷取规则、答案标
注规则、字符整理规则、格式编排规则。标注规范112a能以程序指令的形式建立,使终端装置120能据以对原始数据d1进行分析。在其他部分实施例中,标注规范112a亦可包含口语化的描述文字,使终端装置的使用者能进行人工检查。
31.在此举例说明标注规范112a的内容,“问题撷取规则”可包含“问题需明确”、“不可单纯地将文句转换为问句”等。此外,在部分实施例中,终端装置120将针对分析数据中的任一个问题(或所有问题),撷取文字文件中的对应内容。举例而言,对于一段“运动控制器”相关的文字文件,终端装置120撷取出的问题为“客户在改造卧式包装机时,于哪些功能上存在无法解决的技术问题?”,且对应的答案为“旋切、啮合及物料长度偏移补偿功能”。此时,终端装置120会同时在文字文件中标注出“客户欲利用运动控制器来改造卧式包装机,自行完成伺服轴的原点复归、寸动、定点运动功能,但再进阶运用旋切、啮合及物料长度偏移补偿功能时有技术上的问题无法解决
…”
的文字段落。在一实施例中,因为该段文字段落是用以说明该问题的最相关内容,所以答案亦会出现于该段文字段落中。
32.此外,在部分实施例中,“答案撷取规则”可包含“答案简洁且明确”、“必须出现于标注出的文字段落中”。此外,由于答案可能于文字文件中多次出现,因此,“答案标注规则”可包含答案于文字文件或文字段落中的出现位置。意即,终端装置120将标注出答案位于原始数据d1中的出现位置。“出现位置”可为答案在文字段落中的排列顺序,亦可为答案在文字文件中出现的顺序(如:“物料长度偏移补偿功能”一词第三次出现)。终端装置120用以计算答案出现于文字文件中的次数,再标注出答案对应于文字段落的次序(如:第三次出现的位置,对应于答案)。
33.在前述实施例中,终端装置120系标记出原始数据d1中对应于问题的文字段落,且在文字文件中标注出答案的出现位置。在其他部分实施例中,若原始数据d1并非文字文件,则终端装置120可标注与问题相对应的音讯段落或者图片坐标。同理,终端装置120亦可标注答案出现的影片播放时刻。
[0034]“字符整理规则”可包含“将所有数字以阿拉伯数字呈现”,使终端装置120产生的内文格式统一。同样地,“格式编排规则”可包含:“撷取的文字段落、问题、答案中间以分行符号隔开”。前述说明仅为标注规范112a的举例说明,本公开内容并不以此为限。此外,前述实施例是以口语化描述呈现,在其他实施例中,可转换为程序语言或其他终端装置120可辨识的指令集。
[0035]
在产生多组分析数据后,终端装置120可根据预先存储的标注格式(或由服务器110提供),将多组分析数据中的问题及答案转换为标注数据。接着,终端装置120会将标注数据传送给服务器110。在服务器110判断接收到的标注数据中的问题数量大于门槛值112b(如:500笔或2000笔)时,服务器110根据标注数据产生阅读理解数据集。阅读理解数据集为根据数据分析模型111a的文件格式,整合标注数据中所有问题与对应的答案的数据集合。标注数据或阅读理解数据集可作为数据分析模型111a的训练数据,使服务器110得以对数据分析模型111a进行调整与训练。
[0036]
在一实施例中,前述“标注格式”是指文件的格式,亦为跨装置、跨程序语言之间得以沟通的通用标准,例如:json格式、html格式等。通过标注格式,服务器110与终端装置120之间即可通过相同的解析程序或解析模块(如:网页、app、分析程序等)传输及分析数据,避免读取上的错误。
[0037]
据此,由于数据标注系统100先根据标注规范112a对原始数据d1进行整理,以产生问题及答案组成的分析数据d3,因此,不同终端装置120之间产生的分析数据d3将能根据标注规范112a而维持相同的分析水准,使得服务器110能有效率且省时地产生阅读理解数据集,以对数据分析模型111a进行机器学习与深度学习,提升其分析的准确性。
[0038]
在部分实施例中,数据分析模型111a是用以执行机器阅读与分析处理。意即,服务器110接收到文字文件后(如:使用者上传一份论文),可通过数据分析模型111a对该文字文件进行运算。接着,当服务器110收到一个针对文字文件的问题时(如:使用者提出一个该论文内的疑问),服务器110可再通过数据分析模型111a,对该问题进行解析,并从文字文件中取得对应的答案。
[0039]
数据分析模型111a需要大量的训练数据,进行机器学习或深度学习,以建立其运算数据库。一种训练方法是以人工来对原始数据d1进行标注。然而,人工标注的方式产生的分析数据(即,问题与答案),常会有水准落差太大、格式不统一等问题,导致无法有效地训练数据分析模型111a。如果聘用专业人士进行标注,则又存在成本过高的问题。本公开内容系通过建立标注规范112a,使得终端装置110能据以产生分析数据,进而确保了分析数据中问题、答案的水准。同样地,在本公开内容的其他部分实施例中,可根据类似概念,由终端装置120的使用者检阅原始文件,再通过终端装置120标注出问题、答案及对应的文字段落,以产生分析数据。
[0040]
请参考图2a及图2b所示,是原始数据d1中文字文件的示意图,以及分析数据d3的示意图。举例而言,原始数据d1是一篇关于“小行星卫星”的短文。终端装置120接收到原始数据d1后,将根据标注规范112a,产生多个问题(如:“小行星卫星的定义?”)。接着,针对问题,在原始数据d1中标注出对应的答案(如:“环绕另一颗小行星运行的小行星”)。在部分实施例中,终端装置120标注出的问题与答案可能不是口语化的描述,但这幷不影响数据标注系统100产生标注数据。数据标注系统100是根据标注数据(或由标注数据整合而成的阅读理解数据集)训练数据分析模型111a。因此,只要服务器110的处理器111能辨识出分析数据d3中的问题与答案,即可对数据分析模型111a训练。
[0041]
在一实施例中,终端装置120是根据文意解析模块,在原始数据d1中标注分析数据d3。文意解析模块设定有文意解析参数,用以分析原始数据d1内的文字内容。举例而言,当终端装置120接收到原始数据d1后,终端装置120将根据文意解析参数,对原始数据d1中的文字文件进行分析,以撷取出多个关键句。接着,终端装置120根据标注规范112a对些关键句进行分析,以取得多组分析数据d3。由于本领域人士理解文意解析模块的组成及运作方式,故在此即不另赘述。
[0042]
承上,在终端装置120将分析数据d3转换为标注数据,且将标注数据传送给服务器110后,服务器110将先判断标注数据是否符合标注规范112a(因为终端装置120的标注结果仍可能存在不符合标注规范112a的问题或答案)。在标注数据不符合标注规范112a的情况下,服务器110将调整文意解析参数。终端装置120将根据标注规范112a及调整后的文意解析参数,更新所述问题(即,再次根据标注规范112a,重新产生新的分析数据d3)。
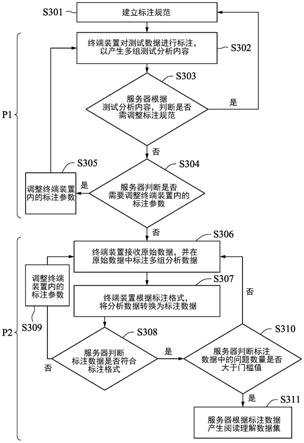
[0043]
请参阅图3,是本公开内容的部分实施例的数据标注方法的流程图。数据标注方法包含步骤s301~s311。在步骤s301中,服务器110先建立标注规范112a。如前所述,标注规范112a可包含问题撷取规则、答案撷取规则、答案标注规则、字符整理规则、格式编排规则。在
部分实施例中,标注规范112a可由专家通过其中的一个终端装置120编辑产生,并上传至服务器110的存储单元。
[0044]
在部分实施例中,数据标注方法包含检测程序p1与标注程序p2。在进行正式的标注程序p2前,为了确保终端装置120的标注能力符合标准,可先通过检测程序p1,测试终端装置120的标注能力。在步骤s302中,服务器110传送测试数据d2至终端装置120。测试数据d2与前述原始文件相似,可包含文字文件、图文件、音频文件或影片文件。终端装置120对测试数据d2进行标注,以产生多组测试分析内容。每组测试分析内容包含测试问题及测试答案。
[0045]
在步骤s303中,在终端装置120对测试数据d2进行标注后,服务器110接收终端装置120回传的测试分析内容,以分析终端装置120的标注能力。若标注能力不如预期,则很可能是标注规范112a不够完整,因此服务器110还将判断是否需要调整标注规范112a。在部分实施例中,服务器110内可存储有事先以人工标注完成的多组人工分析内容,使服务器110可比对人工分析内容与测试分析内容的相似性,判断出终端装置120的标注能力。在其他实施例中,服务器110则可根据每一组测试分析内容彼此间的相似性,来判断终端装置120的标注能力是否稳定且统一。
[0046]
在服务器110分析终端装置120的标注能力后,若服务器110判断须调整标注规范112a,则回到步骤s301,重新调整标注规范112a,例如是调整标注规范112a的参数范围。若服务器110判断无须调整标注规范112a,则在步骤s304中,进一步判断是否需要调整终端装置120内的标注参数?因为终端装置120内用以执行标注功能的参数亦将影响其标注能力。
[0047]
若服务器110判断需要调整终端装置120内的标注参数,则进入步骤s305,对终端装置120进行调整。在部分实施例中,终端装置120是根据文意解析模块中的文意解析参数,对测试数据d2中的文字文件进行分析,以产生测试问题与答案。因此,服务器110是重新调整文意解析参数(如:重新更新数据库、重新对文意解析模块进行深度学习)。
[0048]
若服务器110判断无需调整终端装置120内的标注参数,则代表通过“测试程序p1”,而可执行正式的“标注程序p2”。在步骤s306中,终端装置120接收服务器110传来的原始数据d1,并在原始数据d1(如:文字文件、图文件、音文件或影片)中标注至少一组分析数据d3。每一组分析数据d3包含至少一个问题及至少一个答案。如前所述,本公开内容的数据标注系统100用以根据问题与答案产生标注数据,并依据标注数据(或阅读理解数据集)作为数据分析模型111a的训练数据,使服务器110得以对数据分析模型111a进行调整与训练。标注数据可分别由多个终端装置120产生,再统一由服务器110对数据分析模型111a进行机器学习与深度学习。因此,在步骤s306中,每个终端装置120是用以标注至少一组分析数据d3,而服务器110则可由多个终端装置120接收到多组分析数据d3。
[0049]
在其他实施例中,终端装置120可针对一个问题标注出多个对应的候选答案,例如:列出三个答案,并分别列出分析后的预测正确率(如:答案a的正确机率80%、答案b正确机率60%
…
等)。
[0050]
在部分实施例中,终端装置120是先根据标注规范112a产生多个问题。接着,再由原始内容中标注出对应的答案,以取得多组分析数据d3。
[0051]
在步骤s307中,终端装置120将根据标注格式,将分析数据d3中的所有问题及对应的答案转换为标注数据,并将标注数据上传至服务器110。
[0052]
在部分实施例中,“原始数据d1”是包含有多个待分析的文字文件(或图文件、音频文件),且终端装置120能根据每个文字文件(或图文件、音频文件),产生多组分析数据d3。举例而言,服务器110传送5000个文件(即“原始数据d1”,可包含有文字文件、图文件、音频文件)给终端装置120。终端装置120则会对每一个文件分别产生至少一个问题与答案。
[0053]
在步骤s308中,服务器110先判断标注数据是否符合标注格式?虽然终端装置120是根据标注格式,将分析数据d3转换为标注数据,但在实际运作上,终端装置120仍可能在转换时产生误差,这误差可能是因为步骤s306产出的分析数据d3品质不佳所致。因此,服务器110接收到标注数据后,将会再进行格式的检查。若服务器110判断标注数据不符合标注格式,则进入到步骤s309,调整终端装置120内的标注参数(如:文意解析参数),再回到步骤s306,终端装置120基于调整后的标注参数重新产生分析数据d3,转换成标注数据后再上传至服务器110重新进行步骤s308检查。
[0054]
若服务器110判断标注数据符合标注格式,则在步骤s310中,服务器110进一步判断标注数据中的所述问题的数量是否大于门槛值112b。在部分实施例中,服务器110是判断所有问题的总数量(如:是否大于5000笔)。在其他实施例中,若原始数据d1包含3000笔文字文件,服务器110将判断每一个文字文件的问题是否大于5个。
[0055]
在步骤s310中,若服务器110判断标注数据中问题的数量小于门槛值112b,代表服务器110判断终端装置120尚未完成标注数据流程,回到步骤s306;若服务器110判断标注数据中问题的数量大于门槛值112b,则进入步骤s311中,服务器110根据标注数据产生阅读理解数据集。服务器110可将标注数据作为数据分析模型111a的训练数据,以对数据分析模型111a进行训练。
[0056]
前述各实施例中的各项元件、方法步骤或技术特征,是可相互结合,而不以本公开内容中的文字描述顺序或附图呈现顺序为限。
[0057]
虽然本公开内容已以实施方式公开如上,然其并非用以限定本发明内容,任何本领域专业人士,在不脱离本公开内容的精神和范围内,当可作各种变动与润饰,因此本公开内容的保护范围当视后附的权利要求所界定者为准。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。