1.本发明属于知识图谱数据挖掘领域,具体涉及一种利用动态次优最小生成树来同时兼顾查找内容的重要性与多样性的推荐方法。
背景技术:
2.随着网络社交平台与娱乐平台的多样化,根据用户的喜好或者用户输入的查询指令为用户提供高质量的推荐内容或查找结果成为了推荐系统的主要目标,一些著名的平台如知乎,哔哩哔哩,都拥有自己的推荐算法,尽管已经是一项相对成熟的技术,推荐系统仍然是如今的研究热点之一,而现有的推荐算法仅仅注意推荐内容的质量与热度,常常会出现推荐的内容相似而不相同的情况,即两个内容并不完全一样,但内容上存在极大相似性(如哔哩哔哩推荐了不同用户上传的同一段视频)的问题,进而降低了用户体验。
3.此外,目前很多数据库往往使用知识图谱这一数据结构对数据进行存储,而在知识图谱中进行查询的过程可以抽象为寻找同构子图的过程,由于查找同构子图的过程是np难的,且现有的推荐算法往往是先查找出全部的符合要求的元组,再在其中按照预设的算法进行筛选,最后返回其中的高质量部分,因而推荐系统在工作时往往会出现一定的延迟,这样的延迟会进一步降低用户体验。
技术实现要素:
4.为了克服现有的推荐算法推荐内容重复且有延迟的问题,本发明的目的在于提供一种基于动态次优最小生成树的知识图谱数据挖掘与推荐方法,可以同时兼顾推进内容的重要性与多样性的方法,而且能够减少用户的等待时间。
5.本发明的目的通过如下的技术方案来实现:
6.一种基于动态次优最小生成树的知识图谱数据挖掘与推荐方法,其步骤为:
7.1)根据查询条件对应的子图,在知识图谱进行同构子图匹配,得到若干查询结果;然后将每一查询结果抽象为一个结点;
8.2)将每一查询结果的重要程度作为该查询结果中各个实体的重要程度之和作为对应结点的权值,以查询结果之间的相异程度作为边权值,构建查询结果的最小生成树;
9.3)对该最小生成树中的边进行切割,形成多个不同的连通分支,每个连通分支分别返回该连通分支中重要程度最高的结点作为查询结果输出。
10.进一步的,采用增量的方式动态更新最小生成树,其方法为:根据查询条件对应的子图在知识图谱进行同构子图匹配,按照时间顺序获取多批查询结果,利用第一批查询结果构建一最小生成树并输出查询结果;然后对于后续的第i批查询结果,将第i批查询结果中的每一查询结果抽象为一个结点并加入到当前的最小生成树中,得到一棵新的最小生成树,然后从该新的最小生成树中寻找一条与原最小生成树距离最短的边进行连接,作为新的最小生成树,然后对当前最小生成树中的边进行切割,形成多个不同的连通分支,每个连通分支分别返回该连通分支中重要程度最高的结点作为查询结果输出。
11.进一步的,寻找该距离最短的边的方法为:首先随机地从原最小生成树中选择一些点,找这些点与该新的最小生成树之间最短距离的边,当多次选出来的点都不能再降低已找到的最短距离或查找次数到达阈值之后,将当前找到的最短距离的边作为连接该新的最小生成树与原最小生成树的边。
12.进一步的,两查询结果中相同的结点越少,则该两查询结果的相异程度越大。
13.进一步的,步骤3)中,对该最小生成树中的边进行切割时,切割所选用的边a切割后产生的新的连通分支中点权值最高,则将该边a对该最小生成树中的边进行切割,形成多个不同的连通分支。
14.进一步的,利用计算各边的概率,选取概率最高的边进行切割;其中w为新的连通分支中权值最大结点的权值,d为边的权值,maxw为整棵最小生成树中权值最大结点的权值,n为用户搜索的同构子图包含的结点数,α为反应用户偏好的常数。
15.整体上本发明基于聚类的思想,希望相似的查询结果可以聚在一起,随后在每一类中查找出热度最高重要性最大的结果推荐给用户,这样一来通过聚类,可以消除重复,通过在每一类中查找热度最高的结果,但是现有的聚类算法如(k-means)如果想要实现上述功能,往往需要先将全部符合查询要求的结果得到再进行聚类,而无法解决延迟的问题。
16.由于重要性通过在每个聚类中分别查找最重要的结果就可以保证,这一问题的主要难点在于如何在降低延迟的同时完成聚类保证多样性,针对此问题,本发明将每个查询结果抽象为一个点,以查询结果的重要程度作为点权值,以查询结果之间的相异程度作为边权值(查询出的两个同构子图中相同的结点越少,则相异度越大),希望可以构建查询结果的最小生成树来暂时存储查询结果,随后将最小生成树中的边进行切割,在考虑对重要性影响的前提下选择一些相异性最高的边进行切割,形成多个不同的连通分支,每个连通分支即为一个聚类,在每个连通分支分别返回其中最重要的点即可,由于生成的是最小生成树,所以每个点必然倾向于与相异度低的点相连接,由此实现了聚类的目的。
17.注意到现有的最小生成树算法无论是prime还是krustal都与聚类一样需要提前拥有全部的查询结果,仍然无法解决延迟的问题,故而本发明采用增量添加的方式,来动态生成一棵次优的最小生成树来近似最小生成树,即先对查询的部分结果精确生成最小生成树,这棵树经过切割之后得到第一批推荐内容首先推荐给用户,随后一批一批的向树中添加新挖掘出的查询结果,每一批查询结果会现在内部形成一棵最小生成树,随后寻找一条与原来的树之间最小的边,来连接两棵树,生成一棵新的树(即当前的总树),然后对当前的总树进行切边,找重要程度最高的结点作为输出结果的过程,为用户提供第二批推荐内容,通过这一动态生成的方式可以有效降低推荐系统的延迟时间。
18.注意到现有的在知识图谱中挖掘同构子图的过程中,相邻返回的匹配结果之间往往具有较高的相似性(如一般的深度优先搜索加回溯的方法),故而在本方法中选择在每次的增量中先形成最小生成树,然后去和原来的总树之间寻找边相连的生成方式将十分接近于真正的最小生成树。
19.本发明的有益效果:
20.通过增量更新的方式,动态生成次优的最小生成树可以在查询的过程当中同步完成聚类任务,保证了可以无需等待全部同构子图匹配完成,降低了算法的延迟,同时切边分
成多个聚类,再在多个聚类当中返回每一类中重要性最高的结果这一方式可以有效解决现有推荐算法推荐内容重复的问题,根据本发明的调研结果,这是目前首个关注于兼顾重要性与多样性的推荐算法。
附图说明
21.图1是一个知识图谱示意图。
22.图2是一个查询指令所希望查询的元组。
23.图3是将一已有的树切分得到多个连通分支并在每个分支当中选取最重要的匹配的过程。
24.图4是一个将新得到的匹配形成的最小生成树与原来的树合并的过程。
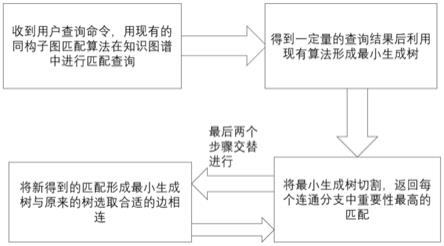
25.图5是本发明的整体流程图。
具体实施方式
26.为了使得本发明的目的,技术方案以及优点更加清楚明白,以下结合附图当中的实例对本发明进行更进一步详细说明。应当理解,此处所描述的具体实例仅仅用以解释本发明,并不用于限定本发明。
27.图1是一个知识图谱,结点上的数字代表其重要性。图2是一个模拟用户进行查询的过程,用户希望查找电影题材为浪漫题材的电影-导演-导演国籍的三元组,过往推荐算法往往会查询到(电影一,导演一,国籍一)和(电影一,导演二,国籍二),这样便造成了推荐内容的重复,事实上(电影一,导演一,国籍一)和(电影二,导演二,国籍二)是更好的推荐结果因为同时兼顾了重要性与多样性。
28.本发明的整体流程图如图5所示,首先根据查询条件对应的子图,在知识图谱进行同构子图匹配,得到若干查询结果;然后将每一查询结果抽象为一个结点,将每一查询结果的重要程度作为该查询结果中各个实体的重要程度之和作为对应结点的权值,以查询结果之间的相异程度作为边权值;然后本发明基于动态次优最小生成树,可以完成快速的兼顾查询结果多样性与重要性的知识图谱查询结果推荐,具体实现步骤如下:在对知识图谱进行同构子图匹配的过程中,采用已有算法得到不同的匹配结果作为查询结果,将每个查询结果抽象为一个点,以查询结果中各个实体的重要程度之和作为点权值,如对于上述电影-导演-导演国籍的三元组,我们以电影评分,导演知名程度的和作为点权值,以查询结果之间的相异程度作为边权值(本发明认为查询出的两个同构子图中相异的结点越多,则相异度越大),在得到一定数量的查询结果后,本发明首先利用传统的prime算法(参考rc.prime shortest connection networks and some generalizations the bell system technical journal;volume:36,issue:6,nov.1957)生成一棵小规模的最小生成树,再在这棵树中选择合适的边进行切开,对每个连通分支返回重要性最高的点作为查询结果,如图3所示,曲线为被选中切开的边,黑色结点为每一个连通分支中被选中的重要程度最高的匹配结果,进而快速为用户提供第一批推荐内容进行浏览,从而缩减用户的等待时间,提高用户体验。至于该如何选择合适的边进行切割,由于本发明希望切割操作得到的连通分支之间相似性较低,故而应尽量选取权值高的边进行切割,然而这样的问题在于在应用场景中,边权值的取值空间相对较小,很可能会出现边权相同的情况,同时边权相同的不同边很
可能切分后得到的连通分支其重要性会有较大差异,因此在切边的时候同时考察切了这条边后带来的新的连通分支中重要性最高的点的点权值(点权值指的是新的连通分支中权值最高的点的权值),点权值越高同样越可能切这条边,;或者利用计算各边的概率,选取概率最高的边进行切割,其中w为新的连通分支中权值最大点的权值,d为边的权值,即边两个端点的相异程度,maxw为整棵生成树中权值最大点的权值,n为用户搜索的同构子图包含的结点数(如对于电影-导演-导演国籍的三元组,则n=3),α为反应用户偏好的常数,用于决定在推荐过程中我们更关注于多样性还是重要性,此处可以结合现有的利用机器学习来学习出用户偏好的办法,通过用户的过往浏览来探究用户在多样性与重要性之间的偏好(如部分用户的兴趣点很单一,往往喜欢看相似的内容),进而可以根据用户偏好决定具体的切边方式以及要切多少条边。
29.在用户浏览本发明第一批推荐内容的过程中,对知识图谱的挖掘过程仍然在进行,本发明采用增量的方式动态更新原来的树,即一批一批的向树中添加新挖掘出的查询结果,每一批查询结果会现在内部形成一棵最小生成树,随后寻找一条与原来的树之间距离最短的边,用找到的边来连接两棵树,生成一棵新的树,具体过程如图4所示,新的树可以重复进行切边,找对重要程度最高的结点作为输出结果的过程,为用户提供第二批推荐内容,通过这一动态生成的方式可以有效降低推荐系统的延迟时间。
30.对于寻找合适的边连接两棵树,本发明采取的方案是随机选取看下降趋势,即随机地从原来的最小生成树中选择一些点,找这些点与新加入的树之间的最短距离,当多次选出来的点都不能再降低现有的最短距离或查找次数到达阈值之后,便用目前找到的最小边连接两棵树,这样可以保证选择的边接近于最优,同时预设的阈值可以保证不在这一过程消耗太多的时间。
31.注意到现有的在知识图谱中挖掘同构子图的过程中,相邻返回的匹配结果之间往往具有较高的相似性(如一般的深度优先搜索加回溯的方法),故而在本方法中选择在每次的增量中先形成最小生成树在去和原来的总树之间寻找边相连的生成方式将十分接近于真正的最小生成树。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。