1.本发明涉及区块链技术领域,具体涉及一种基于区块链的调研数据上链方法及系统。
背景技术:
2.区块链是基于去中心化的对等网络,用开源软件把密码学原理、时序数据和共识机制相结合来保障分布式数据库中各节点的连贯和持续,使信息能即时验证、可追溯,且难以篡改和无法屏蔽。随着区块链应用场景的增加,越来越多的数据需要上链,目前都是将数据的结果上链,不能实现数据的结构化上链,也即不能在区块链上展现业务数据的变化过程。
3.对此,中国现有技术公开了一种基于区块链的业务数据上链系统及方法,应用于区块链系统中,包括至少一个区块链节点,其中,方法包括:区块链节点接收业务服务器发送的业务结构数据,业务结构数据包括业务id、业务关联属性、业务非关联属性以及创建者id;区块链节点将业务结构数据打包成第一区块;在区块链系统对第一区块验证通过后,第一区块上链;区块链节点接收业务服务器发送的业务数据上链请求,业务数据包括业务id、时间戳、用户id、业务数据属性;区块链节点对业务数据进行打包成第二区块;在区块链系统对第二区块验证通过后,第二区块上链。
4.在上述技术方案中,能够让业务数据的过程上链,在区块链系统中,业务数据的历史通过业务数据的id进行对应,用户能够查询业务的历史信息。由于数据以块为单位存储在链上,对链上数据进行结构化存储的过程中,进程可能会因为各种原因中断,导致数据重复或者缺失,难以保证数据结构化存储过程中数据一致性。
技术实现要素:
5.本发明提供一种基于区块链的调研数据上链方法及系统,解决了现有技术难以保证数据结构化存储过程中数据一致性的技术问题。
6.本发明提供的基础方案为:一种基于区块链的调研数据上链系统,包括:
7.至少一个区块链节点,区块链节点用于接收调研数据和上链指令,并在接收到上链指令后将调研数据进行上链;
8.获取模块,用于获取区块链当前的最大区块高度;
9.设置模块,用于设置当前处理高度的初始值;
10.判断模块,用于判断当前处理高度与最大区块高度的大小:
11.若当前处理高度小于、等于最大区块高度,根据当前处理高度以及区块高度标志位从区块链上获取一个区块,区块高度标志位包含区块链上每一区块对应高度的第一标志位和第二标志位;并判断调研数据的样本数量与统计阈值的大小,如果样本数量大于或者等于统计阈值,发送上链指令到区块链节点;
12.若当前处理高度大于最大区块高度,发送重新获取区块链当前的最大区块高度的
指令到获取模块;
13.处理模块,用于设置区块的对应高度的第一标志位,将区块发送给储存模块;并设置区块的对应高度的第二标志位,对当前处理高度执行加一操作,发送再次判断当前处理高度与最大区块高度的大小的指令到判断模块;
14.储存模块,用于将调研数据解析为结构化数据,处理并储存结构化数据。
15.本发明的工作原理及优点在于:
16.(1)统计阈值由实际经验得到,只有调研数据的样本数量比较多时,调研数据才具有统计学意义,才有必要进行打包和上链,这样可以尽可能少打包、上链没有实际意义的调研数据;
17.(2)在区块链的区块生成过程中,不同节点可能在短时间内同时生成区块,随着后续区块的不断产生,区块链会按照最长链原则将最长的分叉链作为主链,所有节点在主链基础上继续工作,被放弃的分叉链成为侧链,侧链上的区块为孤块;通过控制区块高度的第二个标志位实现在出现孤块的时候自动地回退和更新数据,确保了数据结构化存储过程中数据一致性。
18.本发明既可以保证数据的正确性和完整性,又可以在出现孤块的时候自动地回退和更新数据以确保数据结构化存储过程中数据一致性,解决了现有技术难以保证数据结构化存储过程中数据一致性的技术问题。
19.进一步,判断模块用于根据调研数据的样本量与字段量确定中断数,并判断中断数与中断阈值的大小,如果中断数大于或者等于中断阈值,判断当前处理高度与最大区块高度的大小;如果中断数小于中断阈值,发送直接将调研数据解析为结构化数据,并储存结构化数据的指令到储存模块。
20.有益效果在于:如果中断数小于中断阈值,不会出现侧链成为主链的情形,故而直接将调研数据解析为结构化数据,可节省处理的时间。
21.进一步,中断数=α
×
log(样本量) β
×
log(字段量),α、β为预先设定的系数,α为样本量对区块长度的影响系数,β为字段量对区块长度的影响系数。
22.有益效果在于:由于α为样本量对区块长度的影响系数、β为字段量对区块长度的影响系数,可综合考虑两者对中断数的影响。
23.进一步,判断模块用于对调研数据进行动态调整,将内容在预设时间段内随着时间发生变化的调研数据定义为可变动信息,将内容在预设时间段内不随着时间发生变化的调研数据定义为固定信息;并发送只对固定信息进行上链的上链指令到区块链节点。
24.有益效果在于:通过这样的方式,仅对固定信息进行上链,可确保所上链的调研数据具有信息稳定性,从而具备统计意义与参考意义。
25.进一步,判断模块用于对调研数据进行真伪验证,将具备事实符合性的调研数据定义为保真信息,将不具备事实符合性的调研数据定义为非保真信息;并发送只对保真信息进行上链的上链指令到区块链节点。
26.有益效果在于:通过这样的方式,可确保所上链的调研数据具有信息保真性,剔除掉重复性内容和笔误内容对统计分析的干扰。
27.基于上述一种基于区块链的调研数据上链系统,本发明还提供一种基于区块链的调研数据上链方法,应用于区块链系统中,区块链系统包括至少一个区块链节点;包括步
骤:
28.s1、区块链节点接收调研数据;
29.s2、获取区块链当前的最大区块高度,并设置当前处理高度的初始值;
30.s3、判断当前处理高度与最大区块高度的大小:
31.若当前处理高度小于、等于最大区块高度,根据当前处理高度以及区块高度标志位从区块链上获取一个区块,区块高度标志位包含区块链上每一区块对应高度的第一标志位和第二标志位;并判断调研数据的样本数量与统计阈值的大小,如果样本数量大于或者等于统计阈值,发送上链指令到区块链节点;
32.若当前处理高度大于最大区块高度,返回s2重新获取区块链当前的最大区块高度;
33.s4、设置区块的对应高度的第一标志位,进行s5;并设置区块的对应高度的第二标志位,对当前处理高度执行加一操作,返回s3再次判断当前处理高度与最大区块高度的大小;
34.s5、将调研数据解析为结构化数据,处理并储存结构化数据。
35.本发明的工作原理及优点在于:统计阈值由实际经验得到,只有调研数据的样本数量比较多时,调研数据才具有统计学意义,才有必要进行打包和上链,这样可以尽可能少打包、上链没有实际意义的调研数据;同时,对区块高度设置双标志位,可控制处理的完整性,通过对比区块高度的两个标志位,可以知道某个区块的处理情况是已经处理完成或尚未完成,以保证数据的正确性和完整性。
36.进一步,s3中,根据调研数据的样本量与字段量确定中断数,并判断中断数与中断阈值的大小,如果中断数大于或者等于中断阈值,判断当前处理高度与最大区块高度的大小;如果中断数小于中断阈值,进行s5。
37.有益效果在于:当不会出现侧链成为主链的情形时,可直接将调研数据解析为结构化数据,可节省处理的时间。
38.进一步,s3中,中断数=α
×
log(样本量) β
×
log(字段量),α、β为预先设定的系数,α为样本量对区块长度的影响系数,β为字段量对区块长度的影响系数。
39.有益效果在于:可以综合考虑样本量和字段量对区块长度的影。
40.进一步,s3中,对调研数据进行动态调整,将内容在预设时间段内随着时间发生变化的调研数据定义为可变动信息,将内容在预设时间段内不随着时间发生变化的调研数据定义为固定信息;并发送只对固定信息进行上链的上链指令到区块链节点。
41.有益效果在于:对固定信息进行上链,可确保所上链的调研数据具有信息稳定性。
42.进一步,s3中,对调研数据进行真伪验证,将具备事实符合性的调研数据定义为保真信息,将不具备事实符合性的调研数据定义为非保真信息;并发送只对保真信息进行上链的上链指令到区块链节点。
43.有益效果在于:可确保所上链的调研数据具有信息保真性,剔除掉重复性内容和不符内容对统计分析的干扰。
附图说明
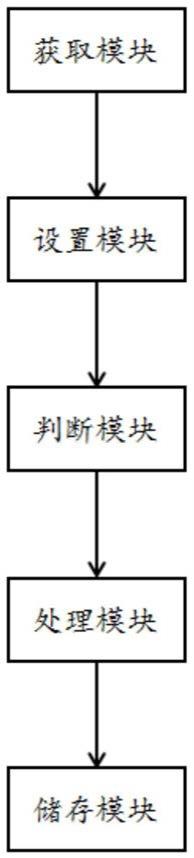
44.图1为本发明一种基于区块链的调研数据上链系统实施例的系统结构框图。
具体实施方式
45.下面通过具体实施方式进一步详细的说明:
46.实施例1
47.实施例基本如附图1所示,包括至少一个区块链节点,区块链节点接收调研数据,区块链节点将调研数据打包成第一区块,在区块链系统对第一区块验证通过后,第一区块上链;区块链节点接收调研数据的上链请求,区块链节点将调研数据打包成第二区块,在区块链系统对第二区块验证通过后,第二区块上链;还包括:
48.获取模块,用于获取区块链当前的最大区块高度;
49.设置模块,用于设置当前处理高度的初始值;
50.判断模块,用于判断当前处理高度与最大区块高度的大小:
51.若当前处理高度小于、等于最大区块高度,根据当前处理高度以及区块高度标志位从区块链上获取一个区块,区块高度标志位包含区块链上每一区块对应高度的第一标志位和第二标志位;
52.若当前处理高度大于最大区块高度,发送重新获取区块链当前的最大区块高度的指令到获取模块;
53.处理模块,用于设置区块的对应高度的第一标志位,将区块发送给储存模块;并设置区块的对应高度的第二标志位,对当前处理高度执行加一操作,发送再次判断当前处理高度与最大区块高度的大小的指令到判断模块;
54.储存模块,用于将调研数据解析为结构化数据,处理并储存结构化数据。
55.在本实施例中,区块链系统、获取模块、设置模块、判断模块、处理模块以及储存模块均集成在服务器上,通过软件/程序/代码/计算机指令实现其功能。
56.具体实施过程如下:
57.s1、区块链节点接收调研数据,将调研数据打包成第一区块,在区块链系统对第一区块验证通过后,第一区块上链。
58.s2、区块链节点接收调研数据的上链请求,将调研数据打包成第二区块,在区块链系统对第二区块验证通过后,第二区块上链。
59.s3、获取模块获取区块链当前的最大区块高度,同时,设置模块设置当前处理高度的初始值。
60.s4、判断模块判断当前处理高度与最大区块高度的大小:
61.若当前处理高度小于、等于最大区块高度,根据当前处理高度以及区块高度标志位从区块链上获取一个区块,区块高度标志位包含区块链上每一区块对应高度的第一标志位和第二标志位;
62.若当前处理高度大于最大区块高度,返回s3,获取模块重新获取区块链当前的最大区块高度。
63.在本实施例中,根据当前处理高度以及区块高度标志位从区块链上获取一个区块,具体步骤如下:
64.判断当前处理高度的第一标志位是否已经设置:
65.如果当前处理高度的第一标志位已经设置,则接着判断当前处理高度的第二标志位是否已经设置:若当前处理高度的第二标志位也已经设置,对当前处理高度执行加一操
作,并再次判断当前处理高度与最大区块高度的大小;反之,若当前处理高度的第二标志位没有设置,发送处理当前处理高度对应的结构化数据的指令到储存模块,以进行s6;
66.如果当前处理高度的第一标志位没有设置,从区块链上获取当前处理高度对应的区块。
67.s5、处理模块设置区块的对应高度的第一标志位,发送处理当前处理高度对应的结构化数据的指令到储存模块,进行s6;同时,处理模块设置区块的对应高度的第二标志位,并对当前处理高度执行加一操作,返回s4,判断模块再次判断当前处理高度与最大区块高度的大小。
68.s6、储存模块将调研数据解析为结构化数据,处理并储存结构化数据。在本实施例中,首先,储存模块会生成包括第三时效的第三区块,在第三时效到达时,将第三区块和第三区块之前且与第三区块处于同一支链的所有区块确定为无效数据,并将无效数据之外的区块确定为有效数据;接着,储存模块会生成包括第四时效的第四区块,在第四时效到达时,将第四区块和第四区块之前且与第四区块处于同一支链的所有区块进行删除的处理。
69.实施例2
70.与实施例1不同之处仅在于,储存模块将区块链节点分为主区块链节点和从区块链节点,并将主区块链节点用于同步有效数据,将从区块链节点用于同步无效数据。
71.实施例3
72.与实施例2不同之处仅在于,针对调研数据的类型确定不同事物上链方式。在本实施例中,具体包括两个方面,如下:
73.首先,对于第一区块上链来说:在区块链节点接收到调研数据之后,判断模块判断调研数据的样本数量与统计阈值的大小,如果样本数量大于、等于统计阈值,将调研数据打包成第一区块,在区块链系统对第一区块验证通过后,第一区块上链;反之,则不进行调研数据打包、对第一区块验证、第一区块上链。在本实施例中,统计阈值为30个,由实际经验得到,只有调研数据的样本数量多于30个,调研数据才具有统计学意义,才有必要进行打包和上链,这样可以尽可能少打包、上链没有实际意义的调研数据。
74.其次,对于第二区块上链来说:在区块链节点接收调研数据的上链请求之后,判断模块根据调研数据的样本量与字段量确定中断数,并判断中断数与中断阈值的大小,如果中断数大于、等于中断阈值,判断当前处理高度与最大区块高度的大小,进行接下来的操作;反之,如果中断数小于中断阈值,储存模块就直接将调研数据解析为结构化数据,处理并储存结构化数据。在本实施例中,样本量为调研数据中总的数据个数,字段量为调研数据中单个数据的大小,中断数=α
×
log(样本量) β
×
log(字段量),其中,α、β为预先设定的系数,α为样本量对区块长度的影响系数,β为字段量对区块长度的影响系数。基于这样的事实,区块链按照最长链原则将最长的分叉链作为主链,不同节点可能在短时间内同时生成区块,随着后续区块的不断产生,侧链可能会成为主链。这样,如果中断数小于中断阈值,不会出现侧链成为主链的情形,故而直接将调研数据解析为结构化数据,可节省处理的时间;反之,如果中断数大于、等于中断阈值,极有可能出现侧链成为主链的情形,这时判断当前处理高度与最大区块高度的大小,确保在当前处理高度小于、等于最大区块高度的情况下,将调研数据打包成第二区块,在区块链系统对第二区块验证通过后,第二区块上链,以保证数据的正确性和完整性。
75.实施例4
76.与实施例3不同之处仅在于,对调研数据进行上链之前,对调研数据进行动态调整以及真伪验证。在本实施例中,具体包括两个方面,如下:
77.首先,对调研数据进行动态调整,也即,辨别调研数据中哪些为固定信息,只对固定信息进行上链。在本实施例中,调研数据可分为可变动信息和固定信息,对于可变动信息和固定信息的区分,关键在于调研数据的内容是否在预设时间段内发生变化。具体而言,对于可变动信息来说,其内容在预设时间段内可以随着时间发生变化,比如说,对于零食的消费店铺而言,在一年之中可能会发生变化,零食的消费店铺则为可变动信息;反之,对于固定信息来说,其内容在预设时间段内并不随着时间发生变化,比如说,对于零食的消费种类而言,在半年之中不会发生变化,零食的消费种类则为固定信息。通过这样的方式,仅对固定信息进行上链,可确保所上链的调研数据具有信息稳定性,从而具备统计意义与参考意义。
78.然后,对调研数据进行真伪验证,也即,挑选出调研数据中的保真信息,并仅对保真性信息进行上链。在本实施例中,调研数据可分为保真信息和非保真信息,对于保真信息和非保真信息的区分,关键在于调研数据的内容是否具有事实符合性。具体而言,保真信息具有事实符合性,与实际情况相符合,比如说,通过现有查重算法对调研数据进行检测,没有发现重复性内容,同时,通过现有笔迹识别算法对调研数据进行检测,没有发现笔误性内容,或者,根据调研数据所属领域制定检测方法,如满意度调研中,如果受访者对各细项服务都非常满意,总体也是非常满意,那么调研数据就具备事实符合性,就为保真信息;反之,非保真信息不具有事实符合性,与实际情况也不相符合,比如说,通过现有查重算法对调研数据进行检测,发现了重复性内容,或者,根据调研数据所属领域制定检测方法,如满意度调研中,如果受访者对各细项服务都非常满意,总体却是不满意,或者,通过现有笔迹识别算法对调研数据进行检测,发现了笔误性内容,那么调研数据就不具备事实符合性,就为非保真信息。通过这样的方式,可确保所上链的调研数据具有信息保真性,剔除掉重复性内容和笔误内容对统计分析的干扰。
79.以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本技术给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本技术的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本技术要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。