1.本发明属于人工智能领域,涉及一种基于置信惩罚正则化的自我知识蒸馏的图像分类方法、设备及存储介质,可用于压缩和加速神经网络,应用于图像分类领域。
背景技术:
2.深度神经网络在解决自然语言处理、语音识别和计算机视觉等许多具有挑战性的人工智能任务方面取得了极大的成功。但深度神经网络的计算复杂度和高内存需求严重阻碍了它在资源有限的平台上的使用,例如智能手机和嵌入式设备等边缘设备。
3.近些年,基于卷积神经网络的表示方式被广泛应用于图像分类领域,但现有的图像应用卷积神经网络进行分类时,不仅需要大量计算,而且会占有大量内存,则当面对受限的边缘计算场景或对实时性要求较高时,这种对计算和内存有着高要求的方法将很难适用。知识蒸馏作为一种典型的模型压缩和加速技术,为深度神经网络在资源有限设备上的部署提供了可能性[hinton g,vinyals o,dean j.distilling the knowledge in a neural network[j].arxiv preprint arxiv:1503.02531,2015.]。随着技术的发展,从各个方面对于原本知识蒸馏方法的改进算法不断提出,其中,自我知识蒸馏是一个研究热点,各种相关方法被不断提出。yuan l等开创性的将标签平滑正则化与知识蒸馏结合,提出了教师自由的自我知识蒸馏框架[yuan l,tay f e h,li g,et al.revisiting knowledge distillation via label smoothing regularization[c]//proceedings of the ieee/cvf conference on computer vision and pattern recognition.2020:3903
‑
3911.]。将正则化方法应用于自我知识蒸馏,可免去训练复杂教师网络的必要性,则在无法获得可靠的教师网络或计算资源有限时,此种方法具有很好的效果与意义。现有的关于正则化方法应用于自我知识蒸馏的研究较少,在图像分类领域的识别精度等方面还有提升的空间。
技术实现要素:
[0004]
针对现有技术的不足,本发明提供了一种基于置信惩罚正则化的自我知识蒸馏的图像分类方法;
[0005]
本发明用于解决传统教师—学生模式的知识蒸馏方法所要求的复杂、学习能力强的教师模型,以及强大计算资源的问题,该方法适用于图像分类领域。
[0006]
本发明利用几种典型的神经网络,将置信惩罚正则化规则与自我知识蒸馏框架融合,通过训练学习让简单的神经网络达到与复杂神经网络相当的图像分类精度。本发明不仅能够在节省计算资源的基础上达到可观的分类精度,还能够省去训练复杂神经网络的必要性,大大提高训练效率。
[0007]
本发明还提供了一种计算机设备及存储介质。
[0008]
术语解释:
[0009]
1、logits:一个事件发生与该事件不发生的比值的对数;
[0010]
2、教师网络:知识蒸馏中,将一个复杂的但是学习能力强的深度神经网络称为教师网络。
[0011]
3、学生网络:知识蒸馏中,将一个精简、复杂度低但学习能力较弱的深度神经网络称为学生网络。本发明中采用的学生网络为mobilenetv2,为现有网络架构,网络结构图如图4。
[0012]
本发明的技术方案为:
[0013]
一种基于置信惩罚正则化的自我知识蒸馏的图像分类方法,用于提升系统整体的效率和精度,具体步骤如下:
[0014]
a、训练过程
[0015]
(1)构建虚拟教师网络,将数据集的图像经过虚拟教师网络处理后,得到虚拟教师网络的输出值
[0016]
(2)将数据集的图像经过学生网络处理后,得到图片属于每个类别的概率输出值,再将此概率输出值经过硬标签式、软标签式两种不同处理,由学生网络输出识别图片样本属于某一类别的概率p(k),和由软化后的学生网络输出的属于某一类别的概率p
τ
(k);
[0017]
(3)先将学生网络硬标签预测输出p(k)与真实分布q(k)加权,数据集中关于每个图片都有自带的类别标签,将这个标签分布记为真实分布q(k);
[0018]
再将虚拟教师网络的输出与学生网络的软标签预测输出p
τ
(k)进行加权,是指虚拟教师网络的输出p
c
(k)在温度τ软化后的输出;
[0019]
最后,将这两个加权的部分用权重参数α进行组合加权,由置信惩罚正则化的有关规则定义损失函数l(θ),如式(i)所示:
[0020][0021]
h(q(k),p(k))为q(k)与p(k)间的交叉熵;为kl散度;
[0022]
b、图像分类
[0023]
将待分类的图像输入虚拟教师网络、训练好的学生网络,输出图像分类结果。
[0024]
根据本发明优选的,步骤(1)中,构建虚拟教师网络,定义函数如式(ii)所示:
[0025][0026]
式(i)中,p
c
(k)来表示虚拟教师网络的预测分布;k是数据集中图片的类别总数,c是正确标签,a是正确分类的概率,当预测的类别k是正确标签时,令输出正确分类的概率a≥0.9,当预测的是错误标签时,让各个错误标签平分余下的概率1
‑
a;
[0027]
根据本发明优选的,步骤(2)中,运用mobilenetv2网络作为学生网络,数据集中的图像经过学生网络处理后,得到图片属于每个类别的概率输出值,再将此概率输出值经过硬标签式(iii)、软标签式(vi)两种不同处理,式(iii)、式(vi)如下所示:
[0028][0029][0030]
式(iii)、式(vi)中,p(k)是学生网络输出的识别图片样本属于第k类的概率,p
τ
(k)是软化后学生网络输出的属于第k类的概率,z
i
是学生网络输出的logits,其中i表示第i类,同样的z
k
表示第k类的logits,k为图片的类别总数,exp()是指数运算;τ为温度参数。
[0031]
根据本发明优选的,步骤(3)中,h(q(k),p(k))为q(k)与p(k)间的交叉熵,具体计算公式如式(v)所示:
[0032][0033]
为kl散度,度量p
τ
(k)和之间的差异,具体计算公式如式(vi)所示:
[0034][0035]
一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现基于置信惩罚正则化的自我知识蒸馏的图像分类方法的步骤。
[0036]
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现基于置信惩罚正则化的自我知识蒸馏的图像分类方法的步骤。
[0037]
本发明的有益效果为:
[0038]
本发明针对深度神经网络应用于移动端或嵌入式设备场景,提出了一种自我知识蒸馏的模型压缩方法。通过将置信惩罚正则化的相关规则应用于自我知识蒸馏,通过训练学习,使简单神经网络在图像分类识别领域能够达到与复杂神经网络相当甚至更甚的精度。并且省去了训练复杂神经网络的必要性,节省计算资源提高训练效率。
附图说明
[0039]
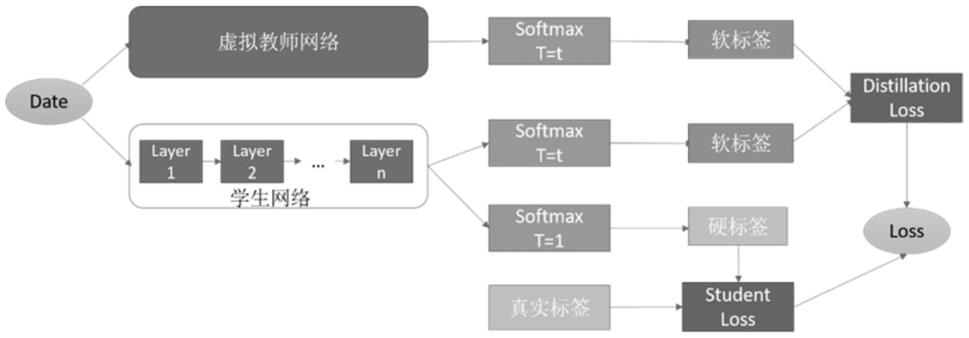
图1是本发明基于置信惩罚正则化的自我知识蒸馏的图像分类方法流程框图;
[0040]
图2是用mobilenetv2作为学生网络、在cifar10数据集上的训练精度示意图。
[0041]
图3是用mobilenetv2作为学生网络、在cifar10数据集上的测试精度示意图。
[0042]
图4是用作为学生网络的mobilenetv2的网络结构示意图。
具体实施方式
[0043]
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
[0044]
实施例1
[0045]
一种基于置信惩罚正则化的自我知识蒸馏的图像分类方法,如图1所示,用于提升系统整体的效率和精度,具体步骤如下:
[0046]
a、训练过程
[0047]
(1)构建虚拟教师网络,定义函数如式(ⅱ)所示:
[0048][0049]
式(ⅰ)中,p
c
(k)来表示虚拟教师网络的预测分布;k是数据集中图片的类别总数,c是正确标签,a是正确分类的概率,当预测的类别k是正确标签时,令输出正确分类的概率a
≥0.9,当预测的是错误标签时,让各个错误标签平分余下的概率1
‑
a;如此,让正确分类的概率远大于错误分类的概率,以此可以当这个人为设定的教师网络的输出分类概率有100%的准确度,以传递给学生网络足够的正确的信息。
[0050]
将数据集的图像经过虚拟教师网络处理后,得到虚拟教师网络的输出值
[0051]
本发明自我知识蒸馏方法不采用复杂神经网络作为教师网络,而是通过自定义的函数的输出代替教师网络的输出,称之为虚拟教师网络。
[0052]
(2)卷积神经网络模型在总体上一般可以分为卷积层、池化层与全连接层,图像数据经过网络各层处理后能完成图像分类任务,输出网络关于图像样本的预测分类概率值和识别精度。运用mobilenetv2网络作为学生网络,数据集中的图像经过学生网络处理后,得到图片属于每个类别的概率输出值,再将此概率输出值经过硬标签式(ⅲ)、软标签式(
ⅵ
)两种不同处理,式(ⅲ)、式(
ⅵ
)如下所示:
[0053][0054][0055]
式(iii)、式(vi)中,p(k)是学生网络输出的识别图片样本属于第k类的概率,pτ(k)是软化后学生网络输出的属于第k类的概率,z
i
是学生网络输出的logits,其中i表示第i类,同样的z
k
表示第k类的logits,k为图片的类别总数,由于logits不是概率值,所以要通过softmax函数进行变换得出最后的分类结果概率,exp()是指数运算;τ为温度参数。值越高,softmax的输出概率分布越趋于平滑,其分布的熵越大,负标签携带的信息会被相对的放大;
[0056]
步骤(2)中,对于图像分类问题而言,在网络的最后的softmax层前,会得到这个图片属于各个类别的大小数值z
i
,某个类别的z
i
值越大,则模型认为样本属于这个类别的可能性越大,通过汇总网络内部的各种信息之后,得出属于各个类别的汇总分值z
i
,就是logits,其中i代表第i类,但是由于logits不是概率值,所以要通过softmax函数进行变换得出最后的分类结果概率。但这样直接输出的是硬标签,所以为了软化标签,引入参数:温度τ,用较大的τ值来训练学生网络,产生更均匀分布的软标签,让学生网络的预测输出分布与教师网络的分布尽可能相似。
[0057]
(3)先将学生网络硬标签预测输出p(k)与真实分布q(k)加权,数据集中关于每个图片都有自带的类别标签,将这个标签分布记为真实分布q(k);
[0058]
再将虚拟教师网络的输出与学生网络的软标签预测输出p
τ
(k)进行加权,是指虚拟教师网络的输出p
c
(k)在温度τ软化后的输出;
[0059]
最后,将这两个加权的部分用权重参数d进行组合加权,由置信惩罚正则化的有关规则定义损失函数l(θ),如式(i)所示:
[0060][0061]
h(q(k),p(k))为q(k)与p(k)间的交叉熵;具体计算公式如式(v)所示:
[0062]
[0063]
为kl散度,度量p
τ
(k)和之间的差异,具体计算公式如式(vi)所示:
[0064][0065]
步骤(3)中,利用kl散度的相关规则辅助损失函数的定义。用kl散度推导出置信惩罚正则化的损失函数:l(θ)=h(t,p(y|x)) βd
kl
(p(y|x)||u),为计算方便u一般采用均匀分布。传统知识蒸馏方法关于损失函数的定义为:其中,α是超参数,q是标签的真实分布,p是学生网络的输出预测分布,p
τ
分别是软化后的学生网络、教师网络的输出预测分布。由于kl散度不是距离,因为d
kl
(p||q)≠d
kl
(q||p)。结合两者的定义,将基于置信惩罚正则化的自我知识蒸馏方法的损失函数定义如式(i),根据定义的损失函数,计算图像数据集进行图像分类的精度。
[0066]
b、图像分类
[0067]
将待分类的图像输入虚拟教师网络、训练好的学生网络,输出图像分类结果。
[0068]
图2是用mobilenetv2作为学生网络、在cifar10数据集上的训练精度示意图。其中,横坐标为训练周期,纵坐标为训练精度;曲线1为使用本发明方法取得的效果,曲线2为单独训练学生网络取得的效果。图3是用mobilenetv2作为学生网络、在cifar10数据集上的测试精度示意图。其中横坐标为训练周期,纵坐标为测试精度,曲线1为使用本发明方法取得的效果,曲线2为单独训练学生网络取得的效果。
[0069]
由图2及图3可知,通过运用此方法,mobilenetv2网络在cifar10数据集上的识别精度随着学习周期的增加不断提高,且比单独训练此模型时的训练精度有明显提高,可见此方法的有效性。
[0070]
实施例2
[0071]
一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现实施例1基于置信惩罚正则化的自我知识蒸馏的图像分类方法的步骤。
[0072]
实施例3
[0073]
一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现实施例1基于置信惩罚正则化的自我知识蒸馏的图像分类方法的步骤。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。