一种基于加权融合的loc2vec模型的重复数据检测方法
技术领域
1.本发明属于自然语言处理技术领域,具体涉及一种重复数据检测方法。
背景技术:
2.在自然语言处理、数据挖掘等领域,重复数据检测一直是学者们关注的重要主题,同时随着大数据时代的到来,信息增长迅速,对于信息数据的检索与匹配的需求越来越多,重复数据检测这一关键技术也发挥着越来越重要的作用。基于字符串的重复数据检测方法是直接对数据文本进行比较,主要包括最小编辑距离、最长公共子序列(lcs)等算法,基于字符串的检测方法的算法原理简单,实现较为方便,并且对文本直接进行比较,可用于文本快速匹配任务之中,但由于这类算法只考虑了字符串的结构特征,未进行语义内容的分析,重复数据检测准确率较低,且无法执行数据内容较为复杂的任务。
3.自2013年分布式词向量问世以来,基于深度学习的方法在重复性数据检测领域有了更多的成果,无监督的学习方法不需要依赖于标签数据信息就可以计算文本间的语义相似度,这类方法更加通用。doc2vec是一种无监督式的学习算法,是word2vec模型的拓展。计算出来的向量可以通过计算向量之间的距离来判定句子、短语以及文件之间的相似性。使用大规模的语料库进行模型训练,模型对于重复性数据的检测准确率较高,但也存在训练时间过长,检测效率低等问题。
技术实现要素:
4.为了克服现有技术的不足,本发明提供了一种基于加权融合的loc2vec模型的重复数据检测方法,首先,在数据处理层,将语料文件进行分词处理,将其用于doc2vec模型的训练,同时对待检测的源数据进行分词处理,用于下一阶段的重复数据检测;随后在编码分析层,构建出训练后的doc2vec模型,将该模型与lcs算法加权融合,得到用于核心字段重复性检测的加权相似度计算模型loc2vec模型,使用loc2vec模型对分词后的待检测数据进行相似度计算;最后,对数据相似度计算结果进行分析,相似度大于80%认定为重复数据,从而实现重复性数据项的检测。本发明使用大规模语料库对深度神经网络模型doc2vec进行无监督训练,可以充分使用语料库内的语义信息,大大减少了人工标记的工作量,提升了重复数据检测的效率与准确率。
5.本发明解决其技术问题所采用的技术方案包括如下步骤:
6.步骤1:数据处理阶段:
7.对于待检测的源数据项和语料库,使用分词工具,进行分词处理,将处理后的语料库用于doc2vec基础模型训练,处理后的待检测源数据项用于下一阶段模型编码处理分析,同时对doc2vec基础模型进行参数设定,设定结果如表1所示;
8.表1 doc2vec基础模型参数
[0009][0010]
步骤2:编码分析阶段;
[0011]
将步骤1中分词处理后的待检测源数据项使用doc2vec基础模型进行编码处理分析,处理的过程如下所示:
[0012]
步骤2
‑
1:定义源数据集为d{d1,d2...dn};
[0013]
步骤2
‑
2:使用doc2vec模型对源数据集进行训练,得到文本向量集为v{v(d1),v(d2)...v(dn)};
[0014]
步骤2
‑
3:采用余弦相似度计算公式,计算两个文本向量之间的语义相似度simdoc,计算公式如式(2):
[0015][0016]
步骤2
‑
4:使用lcs算法对源数据集内数据项之间的最长公共子序列算法相似度进行检测,如式(2):
[0017][0018]
其中,simlcs表示lsc算法计算出的文本相似度,len(d1)表示待检测字符串的长度,lcs(d1,d2)表示两个字符串的最长公共子序列长度;
[0019]
步骤2
‑
4:将式(1)和式(2)进行加权融合,得到加权相似度计算模型,如式(3),根据式(3)来计算数据项之间的相似度值的大小;
[0020]
simloc2vec(x,y)=α
·
simlcs (1
‑
α)
·
simdoc
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)其中α∈[0,1],x、y分别为待检测的两条数据;
[0021]
步骤3:重复数据判别阶段:
[0022]
使用loc2vec模型对待检测源数据项的相似度进行计算,对于数据项之间相似度大于f%的数据项认定其为重复数据,最终获取得到重复数据集合。
[0023]
优选地,所述分词工具为jieba分词工具。
[0024]
优选地,所述a=100,b=3,c=200,d=1,e=4。
[0025]
优选地,所述α=0.6,f=80。
[0026]
本发明的有益效果如下:
[0027]
本发明将深度学习网络模型与基于字符串的检测算法相结合,doc2vec模型采用无监督学习的模式,不需要人工标注就可对语料数据进行训练学习,大大减少了传统人工标记工作方式的工作量,同时结合lcs算法,针对字符串的结构特征进行分词,两个算法加权融合后的loc2vec模型大大提升了重复数据检测的效率,与直接使用两种算法进行重复数据检测相比,本发明提出的检测模型提升了重复性数据检测的准确率,保证了数据的可
靠性。
附图说明
[0028]
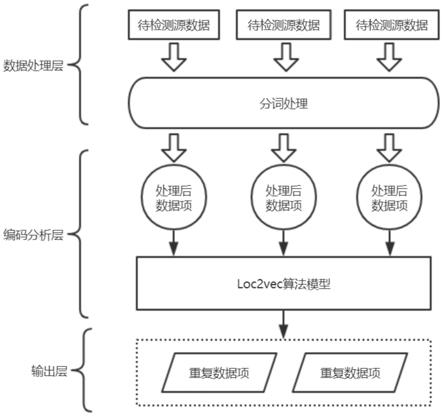
图1为本发明进行重复数据检测的架构图。
[0029]
图2为本发明加权融合的loc2vec模型构建流程。
[0030]
图3为本发明实施例α取值对检测准确度影响示意图。
具体实施方式
[0031]
下面结合附图和实施例对本发明进一步说明。
[0032]
本发明的整体架构如图1所示,对重复数据的检测主要分为三个阶段,数据处理层对数据进行分词处理,以及模型初始化,编码分析层对loc2vec模型进行构建,并使用loc2vec模型进行数据相似度检测,最后在数据输出层根据数据之间的相似度值来判别重复数据项。
[0033]
一种基于加权融合的loc2vec模型的重复数据检测方法,包括如下步骤:
[0034]
步骤1:数据处理阶段:
[0035]
对于待检测的源数据项和大规模语料库,使用分词工具,进行jieba工具进行分词处理,将处理后的语料库用于doc2vec基础模型训练,处理后的待检测源数据项用于下一阶段模型编码处理分析,同时对doc2vec基础模型进行参数设定,设定结果如表1所示;
[0036]
表1 doc2vec基础模型参数
[0037][0038]
步骤2:编码分析阶段;
[0039]
将步骤1中分词处理后的待检测源数据项使用doc2vec基础模型进行编码处理分析,处理的过程如下所示:
[0040]
步骤2
‑
1:定义源数据集为d{d1,d2...dn};
[0041]
步骤2
‑
2:使用doc2vec模型对源数据集进行训练,得到文本向量集为v{v(d1),v(d2)...v(dn)};
[0042]
步骤2
‑
3:采用余弦相似度计算公式,计算两个文本向量之间的语义相似度simdoc,计算公式如式(2):
[0043][0044]
步骤2
‑
4:使用lcs算法对源数据集内数据项之间的最长公共子序列算法相似度进行检测,如式(2):
[0045][0046]
步骤2
‑
4:如图2所示,将式(1)和式(2)进行加权融合,得到加权相似度计算模型,如式(3),根据式(3)来计算数据项之间的相似度值的大小;
[0047]
simloc2vec(x,y)=α
·
simlcs (1
‑
α)
·
simdoc
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0048]
其中α∈[0,1],使用人工标记的标准重复数据集,针对α取值范围,取0到1范围内数值进行对照实验,如图3所示,根据对照实验结果,可知α取0.6时检测准确率最高,因此将α设定为0.6;式(3)中x,y分别为待检测的两条数据,将两个数据项进行lcs算法相似度计算以及doc2vec模型相似度计算,并通过权重α进行加权计算,得到loc2vec模型计算出的数据相似度值。
[0049]
步骤3:重复数据判别阶段:
[0050]
使用loc2vec模型对待检测源数据项的相似度进行计算,对于数据项之间相似度大于80%的数据项认定其为重复数据,最终获取得到重复数据集合。
再多了解一些
本文用于企业家、创业者技术爱好者查询,结果仅供参考。