用于双耳音频录制的感知增强
1.相关申请的交叉引用
2.本技术要求2020年1月20日提交的美国临时申请no.63/139,329和2021年12月9日提交的美国临时申请63/287,730以及2020年12月22日提交的pct申请no.pct/cn2020/138221的优先权,所有的这些申请通过引用整体并入本文。
技术领域
3.本公开涉及音频处理,并且特别地涉及噪声抑制。
背景技术:
4.除非本文另外指示,否则这一节中描述的方法不是这个申请中的权利要求的现有技术,并且不因包括在这一节中而被承认是现有技术。
5.用于视听捕获的设备正在变得更受消费者欢迎。这样的设备包括便携式相机,诸如sony action cam
tm
相机和gopro
tm
相机,以及具有集成的相机功能的移动电话。一般地,设备与捕获视频并发地捕获音频,例如通过使用单耳或立体声麦克风。视听内容共享系统,诸如youtube
tm
服务和twitch.tv
tm
服务,在受欢迎度上也正在增长。用户然后与捕获并发地广播捕获的视听内容或将捕获的视听内容上传到内容共享系统。因为这个内容是由用户生成的,所以它被称为用户生成的内容(ugc),与通常由专业人员生成的专业生成的内容(pgc)形成对比。ugc常常与pgc的不同在于ugc是使用可以比专业装备便宜并且具有更少的特征的消费者装备创建的。ugc与pgc之间的另一个差异是ugc常常在不受控制的环境(诸如室外)中被捕获,而pgc常常在受控制的环境(诸如录制室)中被捕获。
6.双耳音频包括使用位于用户的耳朵位置的两个麦克风录制的音频。捕获的双耳音频在经由耳机重放时导致沉浸式的收听体验。与立体声音频相比,双耳音频还包括用户的头部和耳朵的头部阴影,从而导致双耳音频在捕获时的耳间时间差和耳间声级差。
技术实现要素:
7.现有的视听捕获系统具有若干问题。一个问题是许多现有的捕获设备仅包括单声道或立体声麦克风,这使得双耳音频的捕获尤其具有挑战性。另一个问题是ugc音频常常具有在pgc音频中不存在(由于pgc常常在受控制的环境中被捕获)的平稳和非平稳噪声。另一个问题是独立的音频和视频捕获设备会导致与使用眼睛和耳朵的人类感知不一致的音频和视频流。
8.实施例涉及与双耳音频并发地捕获视频并且对捕获的双耳音频执行感知增强,诸如噪声减少。所得到的双耳音频然后在与捕获的视频组合地消费时与立体声或单耳音频不同地被感知。
9.根据实施例,一种计算机实现的音频处理的方法包括由音频捕获设备捕获具有包括左声道和右声道的至少两个声道的音频信号。该方法还包括由机器学习系统对至少两个声道中的每个声道计算多个噪声减少增益。该方法还包括基于每个声道的多个噪声减少增
益计算多个共享的噪声减少增益。该方法还包括通过将多个共享的噪声减少增益应用到至少两个声道中的每个声道来生成经修改的音频信号。
10.作为结果,在捕获的双耳音频中可以减少噪声。
11.机器学习系统可以使用单耳模型、双耳模型、或者单耳模型和双耳模型两者。
12.该方法还可以包括由视频捕获设备与捕获音频信号同时地捕获视频信号。该方法还可以包括在前置相机与后置相机之间切换,其中切换包括使用第一平滑参数对音频信号的左/右校正进行平滑、以及使用第二平滑参数对音频信号的前/后校正进行平滑。与捕获音频信号同时地捕获视频信号可以包括对音频信号执行校正,其中校正包括左/右校正、前/后校正、以及立体声图像宽度控制校正中的至少一个。立体声图像宽度控制校正可以包括从音频信号的左声道和右声道生成中间声道和侧边声道,通过宽度调整因子使侧边声道衰减,以及从中间声道和已被衰减的侧边声道生成经修改的音频信号。
13.根据另一个实施例,一种装置包括处理器。该处理器被配置为控制该装置实现本文描述的方法中的一个或多个。该装置可以附加地包括与本文描述的方法中的一个或多个的细节类似的细节。
14.根据另一个实施例,一种非暂时性计算机可读介质存储计算机程序,该计算机程序在由处理器执行时控制装置执行包括本文描述的方法中的一个或多个的处理。
15.下面的具体实施方式和附图提供了对各种实现的性质和优点的进一步理解。
附图说明
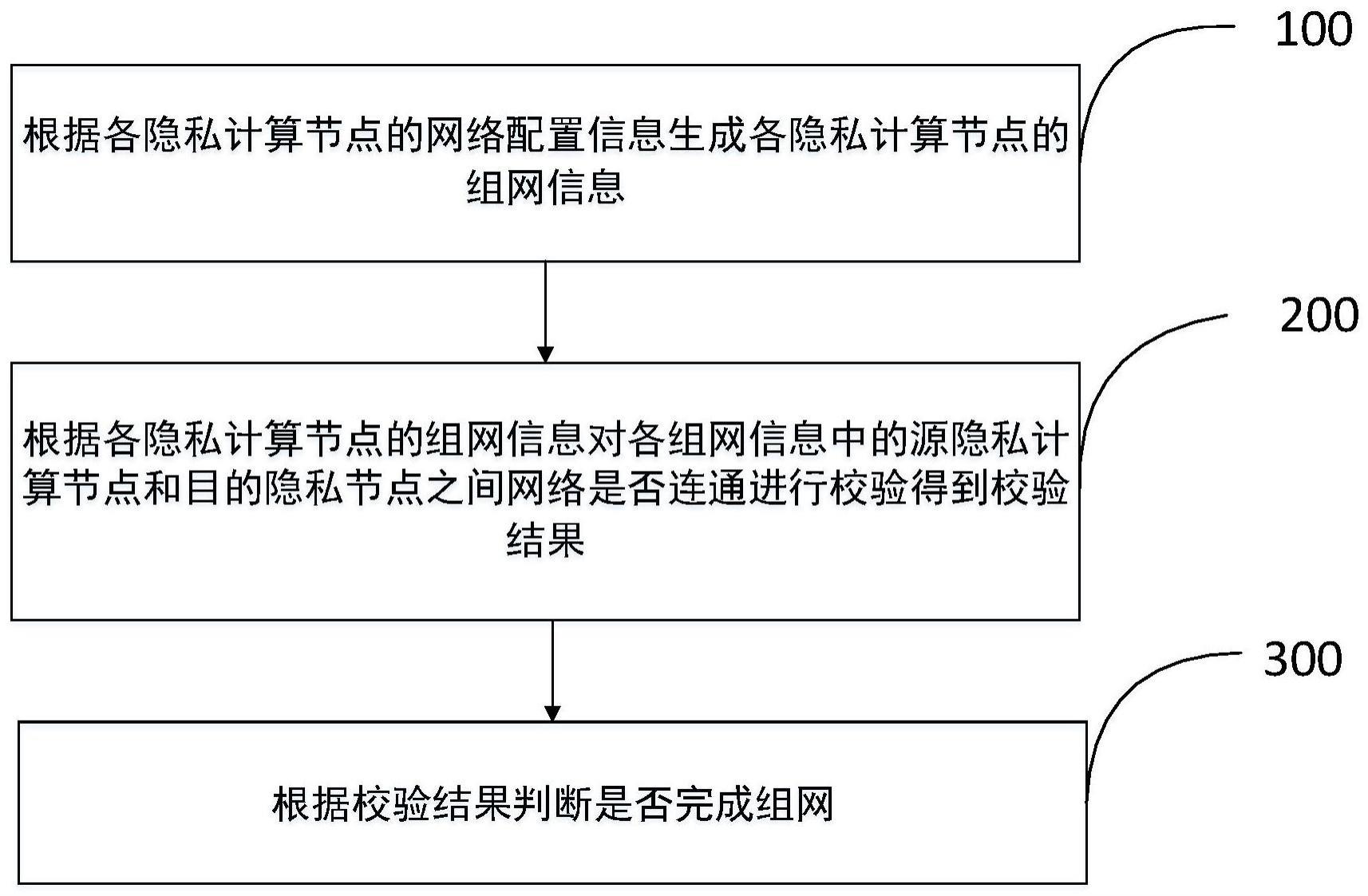
16.图1是视听捕获系统100的程式化俯视图。
17.图2是音频处理系统200的框图。
18.图3是音频处理系统300的框图。
19.图4是音频处理系统400的框图。
20.图5是音频处理系统500的框图。
21.图6是图示使用视频捕获系统100(参见图1)在自拍模式下的双耳音频捕获的程式化俯视图。
22.图7是示出使用双二阶滤波器实现的高架滤波器的幅度响应的示例的示图。
23.图8是示出在自拍模式下的各种音频捕获角度的程式化俯视图。
24.图9是对于不同焦距f的衰减因子a的示图。
25.图10是图示使用视频捕获系统100(参见图1)在正常模式下的双耳音频捕获的程式化俯视图。
26.图11是根据实施例的用于实现本文描述的特征和过程的设备架构1100。
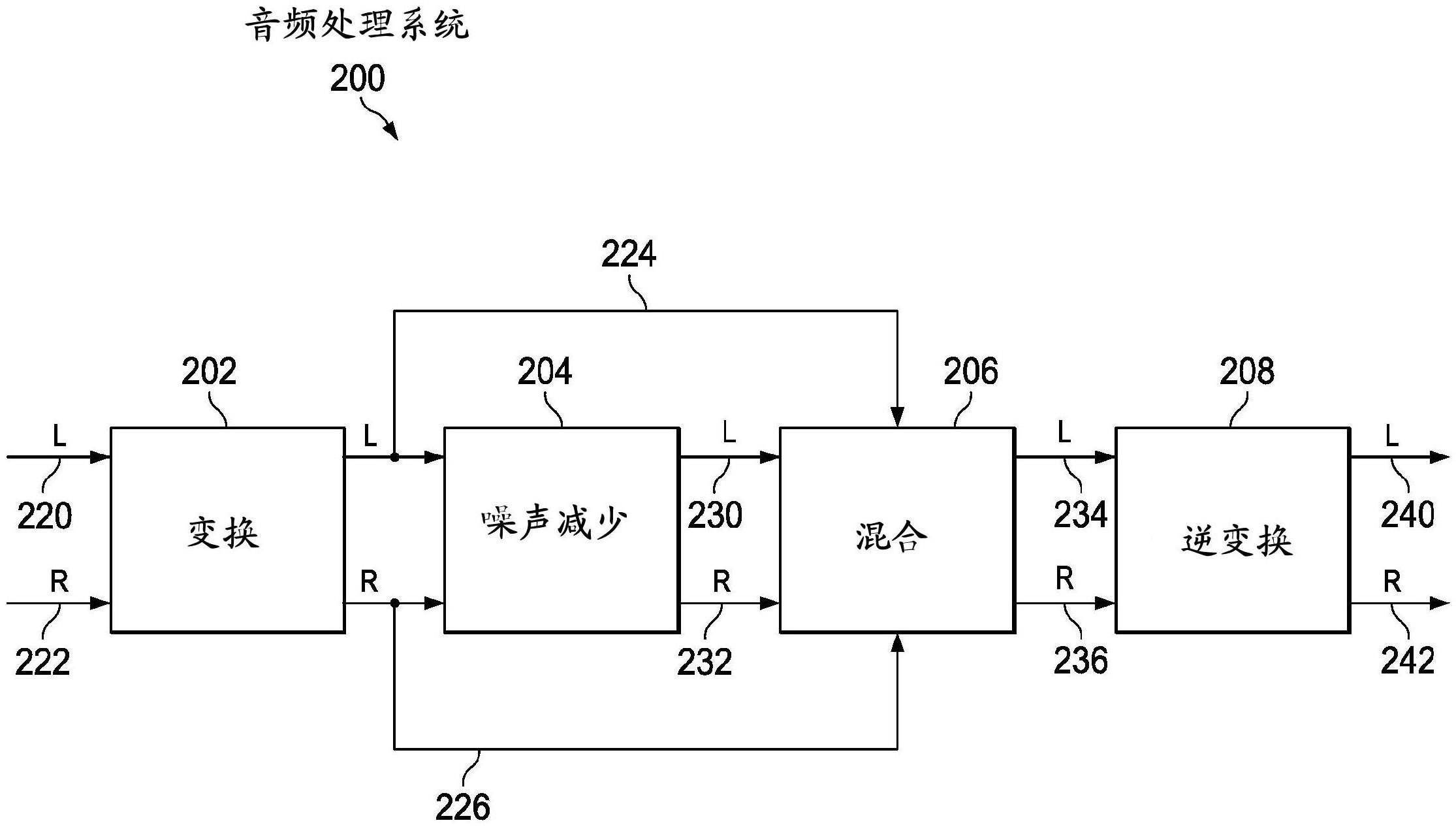
27.图12是音频处理的方法1200的流程图。
28.图13是音频处理的方法1300的流程图。
具体实施方式
29.本文描述的是与音频处理相关的技术。在下面的描述中,出于解释的目的,阐述了大量的示例和具体细节以便提供对本公开的透彻理解。然而,对于本领域技术人员将清楚的是,如权利要求所限定的本公开可以单独地或者与下面描述的其它特征组合地包括这些
示例中的特征中的一些或全部,并且还可以包括本文描述的特征和概念的修改和等同物。
30.在以下的描述中,详述了各种方法、过程和规程。尽管特定的步骤可以按某一次序进行描述,但是这样的次序主要是为了方便和清楚。特定的步骤可以重复多于一次,可以在其它步骤之前或之后发生,即使那些步骤按另一次序进行描述,并且可以与其它步骤并行地发生。仅当第一步骤必须在第二步骤开始之前完成时,才需要第二步骤跟在第一步骤后面。这样的情形在从上下文不清楚时将特别地指出。
31.在这个文档中,使用术语“和”、“或”以及“和/或”。这样的术语要被解读为具有包含性含义。例如,“a和b”可以意指至少以下内容:“a和b两者”、“至少a和b两者”。作为另一个示例,“a或b”可以意指至少以下内容:“至少a”、“至少b”、“a和b两者”、“至少a和b两者”。作为另一个示例,“a和/或b”可以意指至少以下内容:“a和b”、“a或b”。当意图异或时,将特别地注明,例如,“要么a要么b”、“最多a和b中的一个”等。
32.这个文档描述了与诸如块、元件、组件、电路等的结构相关联的各种处理功能。一般地,这些结构可以由被一个或多个计算机程序控制的处理器实现。
33.图1是视听捕获系统100的程式化俯视图。用户一般使用视听捕获系统100在不受控制的环境中捕获音频和视频,例如捕获ugc。视听捕获系统100包括视频捕获设备102、左耳塞104和右耳塞106。
34.视频捕获设备102一般包括捕获视频数据的相机。视频捕获设备102可以包括两个相机,称为前置相机和后置相机。前置相机,也称为自拍相机,一般位于视频捕获设备102的一侧,例如包括显示屏或触摸屏的那一侧。后置相机一般位于与前置相机相对的那一侧。视频捕获设备102可以是移动电话,因此可以具有若干附加组件和功能,诸如处理器、易失性和非易失性存储器和存储装置、收音机、麦克风、扬声器等。例如,视频捕获设备102可以是诸如apple iphone
tm
移动电话、samsung galaxy
tm
移动电话等的移动电话。视频捕获设备102一般可以由用户用手拿着、安装在用户的自拍杆或三脚架上、安装在用户的肩托上、附接到空中无人机等。
35.左耳塞104定位在用户的左耳中,包括麦克风并且一般捕获左双耳信号。左耳塞104将左双耳信号提供给视频捕获设备102以用于与视频数据并发地捕获音频数据。左耳塞104可以无线地连接到视频捕获设备102,例如经由ieee 802.15.1标准协议,诸如bluetooth
tm
协议。替代地,左耳塞104可以连接到未示出的另一个设备,该设备从视频捕获设备102接收捕获的音频数据和捕获的视频数据两者。
36.右耳塞106定位在用户的右耳中,包括麦克风并且一般捕获右双耳信号。右耳塞104以类似于上面关于左耳塞104描述的方式的方式将右双耳信号提供给视频捕获设备102。右耳塞106可以在其它方面类似于左耳塞104。
37.视听捕获系统100的示例用例是用户走在街上并且与使用耳塞104和106捕获双耳音频并发地使用视频捕获设备102捕获视频。视听捕获系统100然后广播捕获的内容或存储捕获的内容以供以后编辑或上传。另一个示例用例是对播客、采访、新闻报道以及在会议或活动期间录制讲话。在这样的情形下,双耳录制可以提供期望的宽敞感;然而,由于压倒性的噪声的存在,环境噪声的存在以及其它感兴趣源与戴着耳塞104和106的人的距离常常导致不是最优的回放体验。适当减少过多的噪声,同时保持录制的空间线索,在实践中具有挑战性但是具有极高的价值。
38.下面的章节详述由视听捕获系统100实现的附加音频处理技术,以例如执行捕获的双耳音频中的噪声减少。
39.1.捕获的双耳音频中的噪声减少
40.图2是音频处理系统200的框图。音频处理系统200可以被实现为视听捕获系统100(参见图1)的组件,例如实现为由视频捕获设备102的处理器执行的一个或多个计算机程序。音频处理系统200包括变换系统202、噪声减少系统204、混合系统206和逆变换系统208。
41.变换系统202接收左输入信号220和右输入信号222,执行信号变换,并且生成经变换的左信号224和经变换的右信号226。左输入信号220一般与由左耳塞104捕获的信号对应,并且右输入信号222一般与由右耳塞106捕获的信号对应。换句话说,输入信号220和222与双耳信号对应,其中左输入信号220与左双耳信号对应,并且右输入信号222与右双耳信号对应。经变换的左信号224与已被变换的左输入信号220对应,并且经变换的右信号226与已被变换的右输入信号222对应。
42.信号变换一般将输入信号从第一信号域变换到第二信号域。第一信号域可以是时间域。第二信号域可以是频率域。信号变换可以是以下中的一个或多个:傅立叶变换,诸如快速傅立叶变换(fft)、短时傅立叶变换(stft)、离散时间傅立叶变换(dtft)、离散傅立叶变换(dft)、离散位点变换(dst)、离散余弦变换(dct)等;正交镜像滤波器(qmf)变换;复数正交镜像滤波器(cqmf)变换;混合复数正交镜像滤波器(hcqmf)变换;等等。变换系统202可以在执行变换之前执行输入信号的成帧,其中变换按每帧执行。帧大小可以在5和15ms之间,例如10ms。变换系统202可以输出在变换域中被分组到频带中的经变换的信号224和226。频带的数量可以在15和25之间,例如20个频带。
43.噪声减少系统204接收经变换的左信号224和经变换的右信号226,执行增益计算,并且生成左增益230和右增益232。噪声减少系统204一般实现一个或多个机器学习系统以计算噪声减少增益230和232。特别地,左增益230与要应用到经变换的左信号224的噪声减少增益对应,并且右增益232与要应用到经变换的右信号226的噪声减少增益对应。噪声减少增益可以是应用到左信号和右信号两者的共享的噪声减少增益,例如应用到两个信号的单组增益。下面特别参考图3-5提供机器学习系统和噪声减少增益的进一步的细节。
44.混合系统206接收经变换的左信号224、经变换的右信号226、左增益230和右增益232,执行混合,并且生成经混合的左信号234和经混合的右信号236。混合系统206一般混合经变换的左信号224和左增益230以生成经混合的左信号234,并且混合经变换的右信号226和右增益232以生成经混合的右信号236。下面特别参考图3-5提供混合的进一步的细节。
45.逆变换系统208接收经混合的左信号234和经混合的右信号236,执行逆信号变换,并且生成经修改的左信号240和经修改的右信号242。逆信号变换一般与由变换系统202执行的信号变换的逆对应,以将信号从第二信号域变换回到第一信号域中。例如,逆变换系统208可以将经混合的信号234和236从qmf域变换到时间域。经修改的左信号240然后与左输入信号220的噪声减少的版本对应,并且经修改的右信号242与右输入信号222的噪声减少的版本对应。
46.视听捕获系统100然后可以与捕获的视频信号一起输出经修改的左信号240和经修改的右信号242作为生成ugc的一部分。下面特别参考图3-5提供音频处理系统200的附加细节。
47.图3是音频处理系统300的框图。音频处理系统300是音频处理系统200(参见图2)的更特定的实施例。音频处理系统300可以被实现为视听捕获系统100(参见图1)的组件,例如实现为由视频捕获设备102的处理器执行的一个或多个计算机程序。音频处理系统300包括变换系统302a和302b、噪声减少系统304a和304b、增益计算系统306、混合系统308a和308b、以及逆变换系统310a和310b。
48.变换系统302a和302b接收左输入信号320和右输入信号322,执行信号变换,并且生成经变换的左信号324和经变换的右信号326。特别地,变换系统302a基于左输入信号320生成经变换的左信号324,并且变换系统302b基于右输入信号322生成经变换的右信号326。输入信号320和322与由耳塞104和106(参见图1)捕获的双耳信号对应。由变换系统302a和302b执行的信号变换一般与如上面关于变换系统202(参见图2)讨论的信号变换对应。
49.噪声减少系统304a和304b接收经变换的左信号324和经变换的右信号326,执行增益计算,并且生成左增益330和右增益332。特别地,噪声减少系统304a基于经变换的左信号324生成左增益330,并且噪声减少系统304b基于经变换的右信号326生成右增益332。噪声减少系统304a接收经变换的左信号324,对经变换的左信号324执行特征提取以提取一组特征,通过将该组特征输入到经训练的模型中来处理该组特征,并且生成左增益330作为处理该组特征的结果。通过将特征输入到经训练的模型中来处理它们也可以被称为“分类”。噪声减少系统304b接收经变换的右信号326,对经变换的右信号326执行特征提取以提取一组特征,通过将该组特征输入到经训练的模型中来处理该组特征,并且生成右增益332作为处理该组特征的结果。
50.特征可以包括时间特征、谱特征、时间-频率特征等中的一个或多个。时间特征可以包括自动校正系数(acc)、线性预测编码系数(lpcc)、过零率(zcr)等中的一个或多个。谱特征可以包括谱质心、谱滚降、谱能量分布、谱平坦度、谱熵、梅尔频率倒谱系数(mfcc)等中的一个或多个。时间-频率特征可以包括谱通量、色度等中的一个或多个。特征还可以包括上述其它特征的统计量。这些统计量可以包括均值、标准偏差和高阶统计量(例如,偏度、峰度等)。例如,特征可以包括谱能量分布的均值和标准偏差。
51.经训练的模型可以作为机器学习系统的一部分实现。机器学习系统可以包括一个或多个神经网络,诸如递归神经网络(rnn)、卷积神经网络(cnn)等。经训练的模型接收提取的特征作为输入,处理提取的特征,并且输出增益作为处理提取的特征的结果。注意的是,噪声减少系统304a和304b两者使用相同的经训练的模型,例如每个噪声减少系统实现经训练的模型的副本。如下面进一步描述的,经训练的模型已使用单耳训练数据离线训练。
52.增益计算系统306接收左增益330和右增益332,根据数学函数组合增益330和332,并且生成共享增益334。数学函数可以是最大值、平均值、范围函数、比较函数等中的一个或多个。作为示例,假设左增益330、右增益332和共享增益334各自是增益的增益向量,例如20个频带的向量。对于最大值,共享增益334的频带1中的增益是左增益330的频带1中的增益和右增益332的频带1中的增益的最大值;并且对于其它19个频带类似。对于平均值,共享增益334的频带1中的增益是左增益330的频带1中的增益和右增益332的频带1中的增益的平均值;并且对于其它19个频带类似。
53.范围函数基于增益330和332的每个频带中的增益的范围将不同的函数应用到每个频带。例如,当增益330和332中的每一个的频带1中的增益小于x1时,计算最大值;当增益
从x1到x2时,计算平均值;并且当增益大于x2时,计算最大值。
54.差异函数基于增益330和332的每个频带中的增益之间的差异的比较将不同的函数应用到每个频带。例如,当增益330和332的频带1中的增益差异小于x1时,计算平均值;当增益差异为x1或更大时,计算最大值。
55.音频处理系统300使用共享增益334,而不是将左增益330应用到经变换的左信号324和将右增益332应用到经变换的右信号326,以便减少可能存在于快速攻击声音中的伪影。由于左麦克风与右麦克风之间的耳间时间差,双耳捕获的快速攻击声音可以跨越输入信号320和322的帧边界(作为变换系统302a和302b的操作的一部分)。在这样的情况下,用于快速攻击声音的增益将在一个声道中的帧x中以及在另一个声道中的帧x 1中被处理,这会导致伪影。计算共享增益(例如,每个声道的特定频带中的增益的最大值)导致伪影的感知减少。
56.噪声减少系统304a和304b以及增益计算系统306可以在其它方面类似于噪声减少系统204(参见图2)。
57.混合系统308a和308b接收经变换的左信号324、经变换的右信号326和共享增益334,将共享增益334应用到信号324和326,并且生成经混合的左信号336和经混合的右信号338。特别地,混合系统308a将共享增益334应用到经变换的左信号324以生成经混合的左信号336,并且混合系统308b将共享增益334应用到经变换的右信号326以生成经混合的右信号338。例如,经变换的左信号324可以具有20个频带,共享增益334可以是具有20个频带的增益向量,并且经混合的左信号336的给定频带中的幅度值得自将经变换的左信号324中的给定频带中的幅度值乘以共享增益334中的给定频带的增益值。混合系统308a和308b可以在其它方面类似于混合系统206(参见图2)。
58.逆变换系统310a和310b接收经混合的左信号336和经混合的右信号338,执行逆信号变换,并且生成经修改的左信号340和经修改的右信号342。特别地,逆变换系统310a对经混合的左信号336执行逆信号变换以生成经修改的左信号340,并且逆变换系统310b对经混合的右信号338执行逆信号变换以生成经修改的右信号342。由逆变换系统310a和310b执行的逆变换一般与由变换系统302a和302b执行的变换的逆对应,以将信号从第二信号域变换回到第一信号域中。经修改的左信号340然后与左输入信号320的噪声减少的版本对应,并且经修改的右信号342与右输入信号322的噪声减少的版本对应。逆变换系统310a和310b可以在其它方面类似于逆变换系统208(参见图2)。
59.单耳模型训练
60.如上面讨论的,噪声减少系统304a和304b使用经训练的模型以从经变换的左信号324和经变换的右信号326生成左增益330和右增益332。这个经训练的模型已使用单耳训练数据离线训练。离线训练过程也可以被称为训练阶段,该训练阶段与在正常操作期间音频处理系统300使用经训练的模型时的操作阶段形成对比。训练阶段一般具有四步。
61.第一,生成一组训练数据。该组训练数据可以通过将各种单耳音频数据源样本与各种噪声样本以各种信噪比(snr)混合来生成。单耳音频数据源样本一般与无噪声音频数据(也称为干净音频数据)对应,包括讲话、音乐等。噪声样本与有噪声音频数据对应,包括交通噪声、风扇噪声、飞机噪声、建筑噪声、警报声、婴儿哭声等。训练数据可以从将大约1-2小时的源样本与15-25个噪声样本以5-10snr混合而导致大约100-200小时的语料库。每个
源样本可以在15-60秒之间,并且snr的范围可以从-45到0db。例如,讲话的给定的源样本可以是30秒,并且给定的源样本可以与交通噪声的噪声样本以-40、-30、-20、-10和0db的5个snr混合,从而导致训练数据的语料库中的600秒的训练数据。
62.第二,从该组训练数据提取特征。一般地,特征提取过程将与在音频处理系统(例如200(参见图2)或300(参见图3)等)的操作期间要使用的过程相同,诸如执行变换和提取第二信号域中的特征。提取的特征也将与在音频处理系统的操作期间要使用的特征对应。
63.第三,在该组训练数据上训练模型。一般地,通过响应于将模型的输出与理想的输出进行比较而调整模型中的节点的权重来发生训练。理想的输出与调整有噪声输入以变为无噪声输出所需的增益对应。
64.最后,一旦模型已被充分地训练,所得到的模型就被提供给音频处理系统,例如图2中的200或图3中的300,以供在操作阶段中使用。
65.如上面讨论的,训练数据是单耳训练数据。这个单耳训练数据导致音频处理系统300在每个输入声道上使用的单个模型。具体地,噪声减少系统304a使用以经变换的左信号324作为输入的经训练的模型,并且噪声减少系统304b使用以经变换的右信号326作为输入的经训练的模型;例如,系统304a和304b可以各自实现经训练的模型的副本。如下面关于图4-5讨论的,模型也可以使用双耳训练数据进行训练。
66.图4是音频处理系统400的框图。音频处理系统400是音频处理系统200(参见图2)的更特定的实施例。音频处理系统400可以被实现为视听捕获系统100(参见图1)的组件,例如实现为由视频捕获设备102的处理器执行的一个或多个计算机程序。如下面详述的,音频处理系统400类似于音频处理系统300(参见图3),其中差异与经训练的模型相关。音频处理系统400包括变换系统402a和402b、噪声减少系统404、混合系统406a和406b、以及逆变换系统408a和408b。
67.变换系统402a和402b接收左输入信号420和右输入信号422,执行信号变换,并且生成经变换的左信号424和经变换的右信号426。变换系统402a和402b以类似于变换系统302a和302b(参见图3)的方式的方式操作,并且为了简洁不重复描述。
68.噪声减少系统404接收经变换的左信号424和经变换的右信号426,执行增益计算,并且生成联合增益430。联合增益430基于经变换的左信号424和经变换的右信号426两者。噪声减少系统404对经变换的左信号424和经变换的右信号426执行特征提取以提取联合的一组特征,通过将该联合的一组特征输入到经训练的模型中来处理该联合的一组特征,并且生成联合增益430作为处理该联合的一组特征的结果。联合增益430因此与共享增益对应,并且也可以被称为共享增益430。噪声减少系统404在其它方面类似于噪声减少系统304a和304b(参见图3),并且为了简洁不重复描述。例如,该联合的一组特征可以是类似于上面关于噪声减少系统304a和304b讨论的特征的特征。如下面进一步描述的,经训练的模型类似于上面关于噪声减少系统304a和304b讨论的经训练的模型,除了由噪声减少系统404实现的经训练的模型已使用双耳训练数据离线训练之外。
69.注意的是,与音频处理系统300(参见图3)不同,音频处理系统400不需要具有增益计算系统,因为噪声减少系统404输出共享增益430作为已使用双耳训练数据进行训练的结果。
70.混合系统406a和406b接收经变换的左信号424、经变换的右信号426和共享增益
430,将共享增益430应用到信号424和426,并且生成经混合的左信号434和经混合的右信号436。特别地,混合系统406a将共享增益430应用到经变换的左信号424以生成经混合的左信号434,并且混合系统406b将共享增益430应用到经变换的右信号426以生成经混合的右信号436。混合系统406a和406b在其它方面类似于混合系统308a和308b(参见图3),并且为了简洁不重复描述。
71.逆变换系统408a和408b接收经混合的左信号434和经混合的右信号436,执行逆信号变换,并且生成经修改的左信号440和经修改的右信号442。特别地,逆变换系统408a对经混合的左信号434执行逆信号变换以生成经修改的左信号440,并且逆变换系统408b对经混合的右信号436执行逆信号变换以生成经修改的右信号442。由逆变换系统408a和408b执行的逆变换一般与由变换系统402a和402b执行的变换的逆对应,以将信号从第二信号域变换回到第一信号域中。经修改的左信号440然后与左输入信号420的噪声减少的版本对应,并且经修改的右信号442与右输入信号422的噪声减少的版本对应。逆变换系统408a和408b可以在其它方面类似于逆变换系统310a和310b(参见图3)。
72.双耳模型训练
73.如上面讨论的,噪声减少系统404使用经训练的模型以从经变换的左信号424和经变换的右信号426生成共享增益430。经训练的模型已使用双耳训练数据离线训练。双耳训练数据的使用与在对噪声减少系统304a和304b(参见图3)训练模型时使用的单耳训练数据的使用形成对比。使用双耳训练数据训练模型一般类似于上面关于图3讨论的使用单耳训练数据训练模型,并且训练阶段一般具有四步。
74.第一,生成一组训练数据。音频数据源样本是双耳音频数据源样本,而不是上面关于图3讨论的单耳音频数据源样本。将双耳音频数据源样本与噪声样本以各种snr混合导致类似的大约100-200小时的语料库。
75.第二,从该组训练数据提取特征。特征被组合地从双耳声道(例如,组合地从左声道和右声道)提取。组合地从双耳声道提取特征与在对噪声减少系统304a和304b(参见图3)训练模型时使用的从单个声道进行提取形成对比。
76.第三,在该组训练数据上训练模型。训练过程一般类似于在对噪声减少系统304a和304b(参见图3)训练模型时使用的训练过程。
77.最后,一旦模型已被充分地训练,所得到的模型就被提供给音频处理系统,例如图4中的400,以供在操作阶段中使用。
78.图5是音频处理系统500的框图。音频处理系统500是音频处理系统200(参见图2)的更特定的实施例。音频处理系统500可以被实现为视听捕获系统100(参见图1)的组件,例如实现为由视频捕获设备102的处理器执行的一个或多个计算机程序。如下面详述的,音频处理系统500类似于音频处理系统300(参见图3)和音频处理系统400(参见图4)两者,其中差异与经训练的模型相关。音频处理系统500包括变换系统502a和502b,噪声减少系统504a、504b和504c,增益计算系统506,混合系统508a和508b,以及逆变换系统510a和510b。
79.变换系统502a和502b接收左输入信号520和右输入信号522,执行信号变换,并且生成经变换的左信号524和经变换的右信号526。变换系统502a和02b以类似于变换系统302a和302b(参见图3)或402a和402b(参见图4)的方式的方式操作,并且为了简洁不重复描述。
80.噪声减少系统504a、504b和504c接收经变换的左信号524和经变换的右信号526,执行增益计算,并且生成左增益530、右增益532和联合增益534。特别地,噪声减少系统504a基于经变换的左信号524生成左增益530,噪声减少系统504b基于经变换的右信号326生成右增益532,并且噪声减少系统504c基于经变换的左信号524和经变换的右信号526生成联合增益534。噪声减少系统504a接收经变换的左信号524,对经变换的左信号524执行特征提取以提取一组特征,通过将该组特征输入到经训练的单耳模型中来处理该组特征,并且生成左增益530作为处理该组特征的结果。噪声减少系统504b接收经变换的右信号526,对经变换的右信号526执行特征提取以提取一组特征,通过将该组特征输入到经训练的单耳模型中来处理该组特征,并且生成右增益532作为处理该组特征的结果。噪声减少系统504c接收经变换的左信号524和经变换的右信号526,对经变换的左信号524和经变换的右信号526执行特征提取以提取联合的一组特征,通过将该联合的一组特征输入到经训练的双耳模型中来处理该联合的一组特征,并且生成联合增益534作为处理该联合的一组特征的结果。噪声减少系统504a和504b在其它方面类似于噪声减少系统304a和304b(参见图3),并且噪声减少系统504c在其它方面类似于噪声减少系统404(参见图4);为了简洁不重复描述。
81.总之,噪声减少系统504a和504b使用类似于音频处理系统300(参见图3)的单耳模型的单耳模型来实现机器学习系统,并且噪声减少系统504c使用类似于音频处理系统400(参见图4)的双耳模型的双耳模型来实现机器学习系统。音频处理系统500因此可以被视为音频处理系统300和400的组合。
82.增益计算系统506接收左增益530、右增益532和联合增益534,根据数学函数组合增益530、532和534,并且生成共享增益536。数学函数可以是最大值、平均值、范围函数、比较函数等中的一个或多个。增益530、532和534可以是频带化增益的增益向量,其中数学函数被分别应用到增益530、532和534中的给定频带。增益计算系统506可以在其它方面类似于增益计算系统306(参见图3),并且为了简洁不重复描述。
83.混合系统508a和508b接收经变换的左信号524、经变换的右信号526和共享增益536,将共享增益536应用到信号524和526,并且生成经混合的左信号540和经混合的右信号542。特别地,混合系统508a将共享增益536应用到经变换的左信号524以生成经混合的左信号540,并且混合系统508b将共享增益536应用到经变换的右信号526以生成经混合的右信号542。混合系统508a和508b可以在其它方面类似于混合系统308a和308b(参见图3),并且为了简洁不重复描述。
84.逆变换系统510a和510b接收经混合的左信号540和经混合的右信号542,执行逆信号变换,并且生成经修改的左信号544和经修改的右信号546。特别地,逆变换系统510a对经混合的左信号540执行逆信号变换以生成经修改的左信号544,并且逆变换系统510b对经混合的右信号542执行逆信号变换以生成经修改的右信号546。由逆变换系统510a和510b执行的逆变换一般与由变换系统502a和502b执行的变换的逆对应,以将信号从第二信号域变换回到第一信号域中。经修改的左信号544然后与左输入信号520的噪声减少的版本对应,并且经修改的右信号546与右输入信号522的噪声减少的版本对应。逆变换系统510a和510b可以在其它方面类似于逆变换系统310a和310b(参见图3)或408a和408b(参见图4)。
85.模型训练
86.如上面讨论的,噪声减少系统504a、504b和504c使用经训练的单耳模型和经训练
的双耳模型从经变换的左信号524和经变换的右信号526生成增益530、532和534。训练单耳模型一般类似于训练由噪声减少系统304a和304b使用的模型(参见图3),并且训练双耳模型一般类似于训练由噪声减少系统404使用的模型(参见图4),并且为了简洁不重复描述。
87.2.组合的双耳音频和视频捕获
88.如上面提到的,ugc常常包括组合的音频和视频捕获。视频和双耳音频的并发捕获尤其具有挑战性。一个这样的挑战是在双耳音频捕获和视频捕获由分开的设备执行(例如其中移动电话捕获视频并且耳塞捕获双耳音频)时。移动电话一般包括前置相机(也称为自拍相机)和后部相机(也称为主相机)这两个相机。当后部(主)相机在使用中时,这可以称为正常模式;当前置(自拍)相机在使用中时,这可以称为自拍模式。在正常模式下,拿着视频捕获设备的用户在视频上捕获的场景后面。在自拍模式下,拿着视频捕获设备的用户存在于在视频上捕获的场景中。
89.当双耳音频捕获和视频捕获由分开的设备执行时,在与利用眼睛和耳朵对环境的人类感知相比时,可能存在捕获的视频数据与捕获的双耳音频数据之间的不匹配。这样的不匹配的一个示例包括在正常模式下与视频并发地捕获的双耳音频的感知相对于在自拍模式下与视频并发地捕获的双耳音频的感知。这样的不匹配的另一个示例包括在正常模式与自拍模式之间切换时引入的不连续性。以下的章节描述了校正这些不匹配的各种过程。
90.3.自拍模式下的双耳音频捕获
91.图6是图示使用视频捕获系统100(参见图1)在自拍模式下的双耳音频捕获的程式化俯视图。视频捕获设备102处于自拍模式并且使用前置相机以捕获包括场景中的用户的视频。用户正在戴着耳塞104和106以捕获场景的双耳音频。视频捕获设备102在用户的前方约0.5和1.5米之间,这取决于是否用户正在用手拿着视频捕获设备102、正在使用自拍杆以拿着视频捕获设备102,等等。视频捕获设备102还可以捕获用户附近的其它人,例如用户后面的在用户的左边的人(称为左边的人)和用户后面的在用户的右边的人(称为右边的人)。因为音频是双耳捕获的,所以收听者会将由左边的人发出的声音感知为源自后面且向左,并且收听者会将由右边的人发出的声音感知为源自后面且向右。这涉及自拍模式下的若干校正。
92.3.1左/右校正
93.戴着耳塞104和106的用户以及视频捕获设备102的前置(自拍)相机的相对朝向将导致捕获的双耳音频内容的左/右翻转。捕获的视听内容的消费者会将来自右耳塞的声音感知为来自出现在视频的左侧的源,并且将来自左耳塞的声音感知为来自出现在视频的右侧的源,这与我们利用眼睛看物体和利用耳朵听它们时的体验不一致。
94.左/右校正涉及从输入取出左声道并且将它发送到输出的右声道,或者作为等式表达为r
′
=l;以及从输入取出右声道并且将它发送到输出的左声道,或者作为等式表达为l
′
=r。
95.3.2前/后校正
96.为了在使用前置(自拍)相机时录制同一场景中的其它讲话者,时常戴着耳塞104和106并且拿着视频捕获设备102的用户站在其它讲话者的前方一点,即,更靠近相机。因此,对于捕获的双耳音频,其它讲话者的讲话将来自消费该内容的收听者后面。另一方面,捕获的视频将示出前方的所有讲话者。
97.为了总体上校正这一点,并且为了增强音频与视频之间的感知一致性,实施例可以实现前/后校正,该前/后校正进行操作以修改来自收听者的后面的声音的谱形状,使得声音以类似于来自前方的声音的方式被感知。
98.本文公开的实施例可以使用高架滤波器来实现谱形状修改。可以以各种方式构建高架滤波器。例如,它可以使用无限脉冲响应(iir)滤波器(例如,双二阶滤波器)来实现。
99.图7是示出使用双二阶滤波器实现的高架滤波器的幅度响应的示例的示图。在图7中,x轴是以khz为单位的频率,并且y轴是滤波器对信号应用的响度调整的幅度。考虑到人头部的阴影效果,这个示例中的高架频率约为3khz,这是个典型值。因为后方捕获的音频在较高频率(诸如5khz及更高,如图7中所示)处衰减,所以当音频被校正到前方时,滤波器实现高架以提升这些频率。
100.本文公开的实施例还可以使用均衡器来实现谱形状修改。均衡器以不同的增益提升或衰减一个或多个频带中的输入音频,并且可以通过iir滤波器或有限脉冲响应(fir)滤波器来实现。均衡器可以以较高的准确度使谱成形,并且典型配置是对于前/后校正在3到8khz的频率范围中提升8到12db。
101.3.3立体声图像宽度控制
102.图8是示出在自拍模式下的各种音频捕获角度的程式化俯视图。角度θ1与由视频捕获设备102上的麦克风捕获的右边的人的声音的角度(参见图6)对应,并且角度θ2与由右耳塞106捕获的右边的人的声音的角度对应。与麦克风在视频捕获设备102上的情况相比,耳塞104和106通常更靠近其它讲话者将正常站立的线,因此我们具有θ2>θ1,这意味着其它讲话者的讲话来自更靠近侧边的方向,而基于视频场景,观看者将期待讲话来自更靠近中间的方向。
103.为了解决这个问题,实施例可以通过压缩双耳音频的感知宽度来实现立体声图像宽度控制以提高视频与双耳音频录制之间的一致性。在一个实现中,压缩通过衰减双耳音频的侧边分量来实现。首先,根据等式(1.1)和(1.2)将输入的双耳音频转换成中间-侧边表示:
104.m=0.5(l r)(1.1)
105.s=0.5(l-r)(1.2)
106.在等式(1.1)和(1.2)中,l和r是输入音频的左声道和右声道,例如图2中的左输入信号220和右输入信号222,而m和s是从转换得到的中间和侧边分量。
107.然后侧边声道s通过衰减因子a衰减,并且经处理的输出音频l
′
和r
′
由等式(2.1)和(2.2)给出:
108.l
′
=m αs(2.1)r
′
=m-αs(2.2)
109.衰减因子a可以是前置(自拍)相机的焦距f的函数,其由等式(3)给出:
[0110][0111]
在等式(3)中,fc是我们期待a=1(即,不应用侧边分量s的衰减)的焦距,也称为基线焦距;并且γ是侵袭因子,如参考图9进一步详述的。
[0112]
图9是对于不同焦距f的衰减因子a的示图。在图9中,x轴是焦距f,其范围在10和35mm之间,y轴是衰减因子α,基线焦距fc是70mm,并且侵袭因子γ可从[1.2 1.5 2.0 2.5]选择。侵袭因子γ可以可由设备制造商选择以便为相机提供各种选项。对于f=30mm的智能电话上的典型前置(自拍)相机,a在0.5到0.7的范围中。
[0113]
总之,当以较小的焦距捕获视频时,它将出现缩小并且捕获的左边的人和右边的人的音频将全部似乎源自视频的中心,因此宽度控制通过收缩音频场景以匹配视频场景来校正捕获的音频。
[0114]
4.正常模式下的双耳音频捕获
[0115]
图10是图示使用视频捕获系统100(参见图1)在正常模式下的双耳音频捕获的程式化俯视图。视频捕获设备102处于正常模式并且使用后置相机以捕获不包括场景中的用户的视频。用户正在戴着耳塞104和106以捕获场景的双耳音频。与用户常常在视频场景中被捕获的自拍模式(参见图6和8)相反,在正常模式下,用户不常常在视频场景中被捕获。在正常模式下,戴着耳塞104和106并且拿着视频捕获设备102的用户通常在视频场景后面。其它人通常在前方,以在视频中被捕获,如对于左边的人和右边的人所示的那样。角度θ1与由视频捕获设备102上的麦克风捕获的右边的人的声音的角度对应,并且角度θ2与由右耳塞106捕获的右边的人的声音的角度对应。
[0116]
在正常模式下,音频处理系统不需要执行在自拍模式下可能执行的左/右校正或前/后校正。至于立体声图像宽度控制,与麦克风在视频捕获设备102上的情况相比,耳塞104和106通常更远离其它讲话者将正常站立的线,因此我们具有θ2<θ1,所以在这种模式下,可以使双耳音频的感知宽度更宽一点。然而,与自拍模式相比,θ1与θ2之间的差异不那么显著,因此为了简单,典型的方法是要按原样保持双耳音频。
[0117]
5.正常模式与自拍模式之间的切换
[0118]
与自拍模式相比,在正常模式下将常常应用不同的音频处理。例如,左/右校正在自拍模式下执行,但是在正常模式下不执行。当用户切换模式时,音频处理系统平滑地执行切换是有益的。切换可以在实时操作期间执行,例如在捕获内容以用于广播或流传输时,以及在非实时操作期间执行,例如在捕获内容以用于后面的处理或上传时。
[0119]
5.1对于左/右校正和立体声图像宽度控制的平滑
[0120]
回顾第3节,我们具有l
′
=r和r
′
=l作为用于执行左/右校正的等式。这些可以重写为等式(4.1-4.4):
[0121]
m=0.5(l r)(4.1)
[0122]
s=0.5(l-r)(4.2)
[0123]
l
′
=m αs(4.3)
[0124]r′
=m-αs(4.4)
[0125]
在等式(4.1-4.4)中,对于自拍模式下的左/右校正,衰减因子α=-1。
[0126]
因为对于正常模式不需要左/右校正,所以在那个模式下α=-1。因此,在正常模式与自拍模式之间的切换期间,a在1与-1之间切换。为了确保切换平滑,a应当逐渐改变它的值。等式(5)给出了用于执行平滑过渡的等式的一个示例:
[0127][0128]
在等式(5)中,ts是执行切换的时间,并且1秒的过渡时间对于左/右校正切换工作得很好。因此,对于非实时情况,过渡开始于t
s-0.5并且结束于ts 0.5。对于实时情况,可以修改等式(5)以开始于ts并且结束于1秒。1秒的值可以根据需要(例如,在0.5到1.5秒的范围中)进行调整。
[0129]
立体声图像宽度控制使用如由等式(6.1-6.4)表示的类似的一组表达式:
[0130]
m=0.5(l r)(6.1)
[0131]
s=0.5(l-r)(6.2)l
′
=m αs(6.3)r
′
=m-αs(6.4)
[0132]
然而,在等式(6.1-6.4)中,衰减因子a对于自拍模式在0.5到0.7的范围中,并且对于正常模式为1.0。
[0133]
换句话说,立体声图像宽度控制包括生成中间声道m和侧边声道s,通过宽度调整因子a衰减侧边声道,并且从中间声道和已被衰减的侧边声道生成经修改的音频信号l
′
和r
′
。宽度调整因子是基于视频捕获设备的焦距计算的,并且宽度调整因子可以响应于视频捕获设备实时地改变焦距而实时地更新。
[0134]
将对于立体声图像宽度控制的平滑和左/右校正组合在一起,我们对于自拍模式具有在-0.5到-0.7的范围中的a,并且对于正常模式为1.0。作为示例假设α=-0.5导致等式(7):
[0135][0136]
在等式(7)中,ts是执行切换的时间,并且1秒的过渡时间对于组合的左/右校正切换和立体声图像宽度控制切换工作得很好。因此,对于非实时情况,过渡开始于ts-0.5并且结束于ts 0.5。对于实时情况,可以修改等式(7)以开始于ts并且结束于1秒。1秒的值可以根据需要(例如,在0.5到1.5秒的范围中)进行调整。
[0137]
5.2对于前/后校正的平滑
[0138]
如第3节和第4节中描述的,在自拍模式下,应用前/后校正作为谱整形,并且在正常模式下,不应用前/后校正。
[0139]
令x
orig
是前/后校正的输入,并且x
fb
表示前/后校正的输出。于是前/后校正的经平滑的输出由等式(8)给出:
[0140]
x
smoothed
=αx
orig
(1-α)x
fb
(8)
[0141]
在等式(8)中,α=0是对于自拍模式的情况,并且α=1是对于正常模式的情况。等式(9)给出了平滑过渡的等式的示例:
[0142][0143]
在等式(9)中,t%是执行切换的时间,并且6秒的过渡时间对于前/后校正工作得很好。因此,对于非实时情况,过渡开始于ts-3并且结束于ts 3。对于实时情况,可以修改等式(9)以开始于ts并且结束于6秒。6秒的值可以根据需要(例如,在3到9秒的范围中)进行调整。
[0144]
前/后平滑使用比用于左/右和立体声图像宽度平滑(例如,1秒)长的过渡时间(例如,6秒),因为前/后过渡涉及音色改变,这通过使用较长的过渡时间来使得不太可感知到。
[0145]
6.示例设备架构
[0146]
图11是根据实施例的用于实现本文描述的特征和过程的设备架构1100。架构1100可以在任何电子设备中实现,包括但不限于:桌面计算机、消费者音频/视频(av)装备、无线电广播装备、移动设备,例如智能电话、平板计算机、膝上型计算机、可穿戴设备等。在所示的示例实施例中,架构1100是针对移动电话。架构1100包括处理器1101、外围设备接口1102、音频子系统1103、扬声器1104、麦克风1105、传感器1106(例如,加速度计、陀螺仪、气压计、磁力计、相机等)、位置处理器1107(例如,gnss接收器等)、无线通信子系统1108(例如,wi-fi、蓝牙、蜂窝等)、以及i/o子系统1109(其包括触摸控制器1110和其它输入控制器1111)、触摸表面1112和其它输入/控制设备1113。也可以使用具有更多或更少组件的其它架构以实现公开的实施例。
[0147]
存储器接口1114耦合到处理器1101、外围设备接口1102和存储器1115(例如,闪存、ram、rom等)。存储器1115存储计算机程序指令和数据,包括但不限于:操作系统指令1116、通信指令1117、gui指令1118、传感器处理指令1119、电话指令1120、电子消息传递指令1121、web浏览指令1122、音频处理指令1123、gnss/导航指令1124和应用/数据1125。音频处理指令1123包括用于执行本文描述的音频处理的指令。
[0148]
根据实施例,架构1100可以与捕获视频数据并且连接到捕获双耳音频数据的耳塞的移动电话(参见图1)对应。
[0149]
图12是音频处理的方法1200的流程图。方法1200可以由实现视频捕获系统100(参见图1)、音频处理系统200(参见图2)等的功能的具有图11的架构1100的组件的设备(例如,膝上型计算机、移动电话等)例如通过执行一个或多个计算机程序来执行。
[0150]
在1202处,由音频捕获设备捕获音频信号。音频信号具有至少两个声道,包括左声道和右声道。例如,左耳塞104(参见图1)可以捕获左声道(例如,图2中的220),并且右耳塞106可以捕获右声道(例如,图2中的222)。
[0151]
在1204处,由机器学习系统计算至少两个声道中的每个声道的噪声减少增益。机器学习系统可以执行特征提取,可以通过将提取的特征输入到经训练的模型中来处理提取的特征,并且可以输出噪声减少增益作为处理特征的结果。经训练的模型可以是单耳模型、双耳模型、或者单耳模型和双耳模型两者。在1206处,基于每个声道的噪声减少增益计算共
享的噪声减少增益。
[0152]
步骤1204和1206可以作为单独的步骤或作为组合操作的子步骤执行。例如,噪声减少系统204(参见图2)可以计算左增益230和右增益232作为共享的噪声减少增益。作为另一个示例,噪声减少系统304a(参见图3)可以生成左增益330,并且噪声减少系统304b可以生成右增益332;增益计算系统306然后可以通过根据数学函数组合增益330和332来生成共享增益334。作为另一个示例,噪声减少系统404(参见图4)可以计算联合增益430作为共享的噪声减少增益。作为另一个示例,噪声减少系统504a(参见图5)可以生成左增益530,噪声减少系统504b可以生成右增益532,并且噪声减少系统504c可以生成联合增益534;增益计算系统506然后可以通过根据数学函数组合增益530、532和534来生成共享增益536。
[0153]
在1208处,通过将多个共享的噪声减少增益应用到至少两个声道中的每个声道来生成经修改的音频信号。例如,混合系统206(参见图2)可以通过将左增益230和右增益232应用到经变换的左信号224和经变换的右信号226来生成经混合的左信号234和经混合的右信号236。作为另一个示例,混合系统308a(参见图3)可以通过将共享增益334应用到经变换的左信号324来生成经混合的左信号336,并且混合系统308b可以通过将共享增益334应用到经变换的右信号326来生成经混合的右信号338。作为另一个示例,混合系统406a(参见图4)可以通过将共享增益430应用到经变换的左信号424来生成经混合的左信号434,并且混合系统406b可以通过将共享增益430应用到经变换的右信号426来生成经混合的右信号436。作为另一个示例,混合系统508a(参见图5)可以通过将共享增益536应用到经变换的左信号524来生成经混合的左信号540,并且混合系统508b可以通过将共享增益536应用到经变换的右信号526来生成经混合的右信号542。
[0154]
方法1200可以包括与如本文描述的音频处理系统的其它功能对应的附加步骤。一个这样的功能是将音频信号从第一信号域变换到第二信号域,在第二信号域中执行音频处理,并且将经处理的音频信号变换回到第一信号域中,例如,使用图2的变换系统202和逆变换系统208。另一个这样的功能是同时的视频捕获和音频捕获,包括前/后校正、左/右校正和立体声图像宽度控制校正中的一个或多个,例如,如第3-4节中讨论的。另一个这样的功能是自拍模式与正常模式之间的平滑切换,包括使用第一平滑参数平滑左/右校正和使用第二平滑参数平滑前/后校正,例如,如第5节中讨论的。
[0155]
7.替代实施例
[0156]
尽管上面组合地讨论了许多特征,但这主要是由于从组合得到的协同作用。许多特征可以独立于其它特征实现,同时仍然导致相对于现有系统的优点。
[0157]
7.1单相机系统
[0158]
尽管本文的特征中的一些是在具有两个相机的视频捕获设备的背景下描述的,但是许多特征也可应用到具有单个相机的视频捕获设备。例如,单相机系统仍然受益于如第4节中描述的在正常模式下执行的双耳调整。
[0159]
7.2视频捕获模式的平滑切换
[0160]
图13是音频处理的方法1300的流程图。尽管方法1200(参见图12)执行噪声减少,其中如第5节中描述的平滑切换作为附加功能,但是平滑切换可以独立于噪声减少被执行。方法1300描述独立于噪声减少执行平滑切换。方法1300可以由实现视频捕获系统100(参见图1)等的功能的具有图11的架构1100的组件的设备(例如,膝上型计算机、移动电话等)例
如通过执行一个或多个计算机程序来执行。
[0161]
在1302处,由音频捕获设备捕获音频信号。音频信号具有至少两个声道,包括左声道和右声道。例如,左耳塞104(参见图1)可以捕获左声道(例如,图2中的220),并且右耳塞106可以捕获右声道(例如,图2中的222)。
[0162]
在1304处,与捕获音频信号(参见1302)同时地由视频捕获设备捕获视频信号。例如,视频捕获设备102(参见图1)可以与耳塞104和106捕获双耳音频信号同时地捕获视频信号。
[0163]
在1306处,音频信号被校正以生成经校正的音频信号。校正可以包括前/后校正、左/右校正和立体声图像宽度校正中的一个或多个。
[0164]
在1308处,视频信号被从第一相机模式切换到第二相机模式。例如,视频捕获设备102(参见图1)可以从自拍模式(参见图6和8)切换到正常模式(参见图10),或者从正常模式切换到自拍模式。
[0165]
在1310处,与切换视频信号(参见1308)同时地执行经校正的音频信号的平滑切换。平滑切换可以使用第一平滑参数来对一种类型的校正进行平滑(例如,左/右平滑使用等式(5),或者组合的左/右和立体声图像宽度平滑使用等式(7)),并且使用第二平滑参数来对另一种类型的校正进行平滑(例如,前/后校正使用等式(9))。
[0166]
实现细节
[0167]
实施例可以以硬件、存储在计算机可读介质上的可执行模块、或者两者的组合(例如,可编程逻辑阵列等)来实现。除非另外指定,否则由实施例执行的步骤不需要固有地与任何特定的计算机或其它装置相关,但是它们可以在某些实施例中。特别地,各种通用机器可以与根据本文的教导编写的程序一起使用,或者构造更专用的装置(例如,集成电路等)以执行所需的方法步骤可以更方便。因此,实施例可以在一个或多个可编程计算机系统上执行的一个或多个计算机程序中实现,该一个或多个可编程计算机系统各自包括至少一个处理器、至少一个数据存储系统(包括易失性和非易失性存储器和/或存储元件)、至少一个输入设备或端口、以及至少一个输出设备或端口。程序代码被应用到输入数据以执行本文描述的功能并且生成输出信息。输出信息以已知的方式应用到一个或多个输出设备。
[0168]
每个这样的计算机程序优选地存储在或下载到可由通用或专用可编程计算机读取的存储介质或设备(例如,固态存储器或介质、磁性或光学介质等)上,以用于在存储介质或设备由计算机系统读取时配置和操作计算机以执行本文描述的规程。创新性的系统也可以考虑被实现为配置有计算机程序的计算机可读存储介质,其中这样配置的存储介质使计算机系统以特定和预定义的方式操作以执行本文描述的功能。软件本身以及无形或暂时性的信号在它们是不可授予专利的主题的程度上被排除。
[0169]
本文描述的系统的方面可以在用于处理数字或数字化音频文件的适当的基于计算机的声音处理网络环境中实现。自适应音频系统的部分可以包括一个或多个网络,该一个或多个网络包括任何期望的数量的个体机器,包括用于缓冲和路由在计算机之间传输的数据的一个或多个路由器(未示出)。这样的网络可以构建在各种不同的网络协议上,并且可以是互联网、广域网(wan)、局域网(lan)或其任何组合。
[0170]
组件、块、过程或其它功能组件中的一个或多个可以通过控制系统的基于处理器的计算设备的执行的计算机程序来实现。还应当注意的是,本文公开的各种功能就它们的
行为、寄存器传送、逻辑组件和/或其它特性而言,可以使用硬件、固件的任何数量的组合和/或作为包含在各种机器可读或计算机可读介质中的数据和/或指令来描述。可以包含这样的格式化数据和/或指令的计算机可读介质包括但不限于各种形式的物理、非暂时性、非易失性存储介质,诸如光学、磁性或半导体存储介质。
[0171]
上面的描述与本公开的方面可以如何实现的示例一起说明了本公开的各种实施例。上面的示例和实施例不应当被视为仅有的实施例,而是被呈现以说明如随附的权利要求所限定的本公开的灵活性和优点。基于上面的公开和随附的权利要求,其它布置、实施例、实现和等同物对于本领域技术人员将是清楚的并且可以在不脱离如权利要求所限定的本公开的精神和范围的情况下被采用。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。