从分布式跟踪中学习异常检测和根本原因分析
背景技术:
1.本公开涉及计算设备,更具体地,涉及使用分布式跟踪数据来促进异常检测和/或根本原因分析的技术。
技术实现要素:
2.以下提供概述以提供对本发明的一个或多个实施例的基本理解。本概述不旨在标识关键或重要元素,或描绘特定实施例的任何范围或权利要求的任何范围。其唯一目的是以简化形式给出概念,作为稍后给出的更详细说明的序言。在本文描述的一个或多个实施例中,描述了便于使用分布式跟踪数据进行异常检测和/或根本原因分析的系统、设备、计算机实现的方法和/或计算机程序产品。
3.根据实施例,系统可以包括执行存储在存储器中的计算机可执行组件的处理器。计算机可执行组件包括:预处理组件;以及监控组件。预处理组件可以生成跟踪帧,跟踪帧包括由微服务应用的微服务产生的文本跟踪数据的向量表示。监控组件可以使用跟踪帧来标识微服务应用的状态。
4.根据另一实施例,一种计算机实现的方法可以包括由可操作地耦合到处理器的系统生成跟踪帧,该跟踪帧包括由微服务应用的微服务产生的文本跟踪数据的向量表示。计算机实现的方法还可以包括由系统使用跟踪帧来标识所述微服务应用的状态。
5.根据另一实施例,一种计算机程序产品可以包括计算机可读存储介质,该计算机可读存储介质具有包含在其中的程序指令。程序指令可由处理器执行以使处理器执行操作。操作可以包括由处理器生成跟踪帧,该跟踪帧包括由微服务应用的微服务产生的文本跟踪数据的向量表示。操作还可以包括由处理器使用跟踪帧来标识微服务应用的状态。
附图说明
6.图1示出了根据本文所描述的一个或多个实施例的可便于使用分布式跟踪数据进行异常检测和/或根本原因分析的示例非限制性系统的框图。
7.图2示出了根据本文描述的一个或多个实施例的描绘电子业务微服务应用的微服务之间的依赖性的示例非限制性依赖图。
8.图3示出了根据本文所述的一个或多个实施例的描绘跟踪的示例非限制性甘特图。
9.图4示出了根据本文所述的一个或多个实施例的示例非限制性文本跟踪数据。
10.图5示出了根据本文描述的一个或多个实施例的描绘跟踪的示例非限制性调用图。
11.图6示出了根据本文描述的一个或多个实施例的跨度名称的示例非限制性列表。
12.图7示出了根据本文描述的一个或多个实施例的描绘微服务应用的跟踪的示例非限制性有向无环图(dag)。
13.图8示出了根据本文描述的一个或多个实施例的描绘微服务应用的变型跟踪的示
例非限制性dag。
14.图9示出了根据本文描述的一个或多个实施例的描绘微服务应用的另一变型跟踪的示例非限制性dag。
15.图10示出了根据在此描述的一个或多个实施例的用于实现用于通过微服务应用检测异常行为的帧的示例非限制性架构。
16.图11示出了根据本文描述的一个或多个实施例的找到表示跟踪的跨度的d维向量的示例非限制性高级概念概观。
17.图12示出了根据本文描述的一个或多个实施例的应用于微服务应用的跟踪的反向深度优先搜索(dfs)和1跳宽度优先搜索(bfs)图遍历算法的示例非限制性应用。
18.图13示出了根据本文描述的一个或多个实施例的多路径dfs(mpdfs)和1跳bfs图遍历算法到微服务应用的跟踪的示例非限制性应用。
19.图14示出了根据本文描述的一个或多个实施例的mpdfs和1跳bfs图遍历算法到微服务应用的跟踪的另一示例非限制性应用。
20.图15示出了根据本文所描述的一个或多个实施例的示例非限制性跟踪框。
21.图16示出了根据本文所述的一个或多个实施例的示例非限制性卷积长短期存储器(convlstm)单元。
22.图17示出了根据本文描述的一个或多个实施例的示例非限制性的基于convlstm的自动编码器模型。
23.图18示出了根据本文描述的一个或多个实施例的λ个跟踪帧的示例性非限制性序列。
24.图19示出了根据本文所述的一个或多个实施例的通过堆叠多对编码和解码convlstm单元实现的示例性非限制性的基于convlstm的自动编码器模型。
25.图20示出根据本文所述的一个或多个实施例的描绘示例演示的结果的示例非限制性表格。
26.图21示出了根据本文描述的一个或多个实施例的描绘重建损失相对于时间的示例非限制性曲线图。
27.图22示出了根据本文描述的一个或多个实施例的描绘相对于ia-3注入异常改变嵌入维度(d)和上下文窗口大小(w)的影响的示例非限制性曲线图。
28.图23示出了根据本文描述的一个或多个实施例的描绘相对于ia-5注入异常改变嵌入维度d和上下文窗口w的大小的影响的示例非限制性曲线图。
29.图24示出了根据本文所述的一个或多个实施例的描绘变化的时间步长λ相对于ia-3注入异常的影响的示例非限制性曲线图。
30.图25示出了根据本文所述的一个或多个实施例的描绘变化的时间步长λ相对于ia-5注入异常的影响的示例非限制性曲线图。
31.图26示出了根据本文所述的一个或多个实施例的描绘示例演示的诊断性能的示例非限制性表格。
32.图27示出了根据本文所述的一个或多个实施例的描绘示例演示的相对诊断性能的示例非限制性曲线图。
33.图28示出了根据本文所述的一个或多个实施例的使用分布式跟踪数据来促进异
常检测和根本原因分析的示例性非限制性计算机实现的方法的流程图。
34.图29示出了其中促进本文所述的一个或多个实施例的示例非限制性操作环境的框图。
具体实施方式
35.以下详细描述仅是说明性的,并不旨在限制实施例和/或实施例的应用或使用。此外,无意受前面的背景技术或发明内容部分或详细说明部分中呈现的任何表达或暗示的信息的约束。
36.现在参考附图描述一个或多个实施例,其中相同的附图标记始终用于表示相同的元素。在以下描述中,出于解释的目的,阐述了许多具体细节以便提供对一个或多个实施例的更透彻理解。然而,显然,在各种情况下,可以实践一个或多个实施例而没有这些具体细节。
37.当设计软件应用时,微服务架构越来越普及,因为它们使得开发者能够在独立的时间表上操作并且以高速交付,从而缩短上市时间。对于在混合云环境中部署的应用,微服务架构是特别吸引人的,因为微服务应用的松散耦合的组件提供改进的可缩放性、灵活性、可维护性和加速的开发者生产率。结果,许多公司已经从传统的单片设计切换到微服务架构。维护微服务应用的健康状态已经成为信息技术(it)专业人员的挑战,例如devops和站点可靠性工程师(sre)。然而,为单片系统设计的现有异常检测和根本原因分析(rca)方法对于微服务应用的使用可能是无效的。
38.为了有效地处理包括微应用的大量微服务,devops和sre通常集中于测量和监视被认为准确地反映微应用的状态的应用或系统度量(例如,中央处理单元(cpu)使用,远程过程调用(rpc)等待时间等)。然而,当应用中的组合服务的复杂度增加时,度量监控方法通常不能很好地缩放。此外,现代云本机服务可以部署在虚拟机(vm)或基于容器的集群中,其中多个虚拟化层和硬件异质性可使得难以标识健康服务的关键度量。同样,用于单个微服务的rpc的数目可以从一个或几个rpc到几百个rpc。这些微服务形成了用于该应用的令人困惑的服务网格,因此来自严重依赖于工作负载的聚集的或分离的度量的监视结果可能使这样的度量不适用于检测到的异常的rca。
39.除了度量之外,多种监控方法已经利用日志来检测异常状态,以合理的多样性显示出针对异常的良好性能。这种基于日志的方法首先将非结构化日志解析成结构化格式,然后将它们分组用于不同的任务或线程。之后,基于日志的方法可以在良好行为的日志上构建统计或机器学习模型,并且通过计算与良好模式的偏差来检测与新日志相关联的异常。然而,这种基于日志的方法难以处理由微服务器强加的复杂并发模式,这可能导致受训模型的精度下降。因此,检测和诊断微服务应用的异常的问题在很大程度上仍未解决。
40.与以单个服务或组件为中心的度量和日志不同,作为it可观测性的三个支柱中的一个支柱的跟踪提供分布式系统的全面视图。分布式跟踪可以通过在跨过程边界的跟踪点处产生的因果相关事件来组装。这样,分布式跟踪可以帮助开发者解决细微的软件错误、发现性能瓶颈、以及理解大规模分布式系统的资源使用。然而,出于许多原因,利用分布式跟踪进行异常检测和rca是具有挑战性的。例如,由于跟踪事件包含文本和数字格式的异构内容两者,简单地将字嵌入应用于原始文本数据通常不能捕捉跟踪上下文中这些事件之间的
完整关系集。作为另一示例,学习正常跟踪的特征不仅涉及对单个跟踪内的事件序列中的依赖性建模,而且涉及跟踪上的更复杂的依赖性。
41.图1示出了根据本文描述的一个或多个实施例的示例非限制性系统100的框图,该系统可以使用分布式跟踪数据来促进异常检测和/或根本原因分析。系统100包括用于存储计算机可执行组件的存储器110和经由一个或多个通信总线130可操作地耦合到存储器110以执行存储在存储器110中的计算机可执行组件的一个或多个处理器120。如图1所示,计算机可执行组件包括:预处理组件140;以及监控组件150。
42.预处理组件140可以生成跟踪帧,跟踪帧包括由微服务应用的微服务产生的文本跟踪数据的向量表示。在一个实施例中,预处理组件可以利用使用图形遍历算法,字嵌入技术或其组合训练的机器学习模型来生成跟踪帧。
43.监控组件150可以使用跟踪帧来标识微服务应用的状态。在一个实施例中,监控组件可以通过将跟踪帧与由机器学习模型生成的重建跟踪帧进行比较来标识微服务应用的状态。在一个实施例中,当在正常状态下操作时,机器学习模型可以捕捉微服务应用的微服务之间的空间依赖性和时间依赖性。
44.在一个实施例中,监控组件可以通过将跟踪帧序列与由机器学习模型生成的重建跟踪帧序列进行比较来标识微服务应用的状态。跟踪帧序列可以包括跟踪帧。在一个实施例中,机器学习模型可以是基于卷积长短期存储器(convlstm)的自动编码器模型。
45.在一个实施例中,存储在存储器110中的计算机可执行组件还可以包括诊断组件160。诊断组件160可以通过评估每个微服务对给定重建损失的贡献来执行rca。下面将更详细地覆盖实施例所利用的计算机可执行组件的功能。
46.图2示出了根据本文描述的一个或多个实施例的描绘电子业务微服务应用的微服务之间的依赖性的示例非限制性依赖图200。如图2所示,电子业务微服务应用被构造为被称为微服务的小的、明确定义的无状态服务的松散耦合的集合。在图2中,松散耦合的微服务集合包括:前端微服务210;结账微服务220;产品目录微服务230;货运微服务240;以及广告微服务250。每个微服务包括定义明确的应用编程接口(api),微服务的松散耦合集合经由该api进行通信,以生成对用户从电子业务微服务应用的前端微服务210触发的请求的响应。
47.图3示出了根据本文所述的一个或多个实施例的描绘跟踪的示例非限制性甘特图300。如这里针对微服务应用所使用的,“跟踪”是指处理由用户触发的从前端微服务(例如,webui)到后端微服务(例如,数据库)的一个请求的端到端执行流程,包括所有中间微服务。在图3中,由甘特图300描绘的跟踪对应于由用户从前端微服务触发的单个结账请求。根据定义,跟踪的端到端执行流是跨度和它们的因果排序的组合。“跨度”是指具有属性集(例如,持续时间,主机/进程标识符(id))以描述端到端执行流的单个单元的命名的操作。如图3所示,跟踪可以由多个微服务上的操作组成。例如,甘特图300所描绘的跟踪由对前端微服务、结账微服务、产品目录微服务和装运微服务的操作组成。跨度通常可以指形成发生在因果排序之前的其它跨度。例如,涉及在端到端执行流中的跨度之前的另一跨度的跨度可以被称为子跨度。在该示例中,在端到端执行流中的子跨度之前的其它跨度可以被称为父跨度。甘特图300的跨度320和330分别表示父跨度和子跨度。没有父跨度的跨度可以被称为根跨度。甘特图300的跨度310表示根跨度。
48.图4示出了根据本文所述的一个或多个实施例的示例非限制性文本跟踪数据400。文本跟踪数据400通常表示对应于结账请求的甘特图300所描绘的跟踪的文本视图。如图4所示,文本跟踪数据400包括跟踪id410和较早跨度的开始时间420。文本跟踪数据400还包括包含由甘特图300描绘的跟踪的跨度阵列,诸如跨度430和跨度440。在图4中,跨度阵列按开始时间排序,并且跨度阵列中相邻跨度之间的插入是双垂直线符号“||”。文本跟踪数据400中的每个跨度包括由双分号符号分隔的微服务名称和操作名称。操作名称引用正在执行的操作,微服务名称引用正在执行操作的电子业务微服务应用的微服务。例如,跨度430包括“frontend”的微服务名称和“sent.hipstershop.checkoutservice.placeorder”。作为另一示例,跨度440包括微服务名称“productcatalogservice”和操作名称“recv.hipstershop.productcatalogservice.getproduct”。
49.图5示出了根据本文所述的一个或多个实施例的描绘跟踪的示例非限制性调用图500。特别地,调用图500表示对应于结账请求的甘特图300所描绘的跟踪。调用图500的每个节点表示由电子业务微服务应用的微服务执行的操作。例如,节点510表示“sent.hipstershop.checkoutservice.placeorder”操作由对应于文本跟踪数据400的跨度430的电子业务微服务应用的前端微服务执行。如图5所示,调用图500的每个节点包括由该节点表示的操作的多个属性,诸如持续时间、cpu利用率、存储器利用率等。例如,节点530指示由电子业务微服务应用的结账微服务执行的“sent.hipstershop.cartservice getcart”操作的持续时间是4.8毫秒(ms)。图5进一步示出了电子业务微服务应用的一些微服务可以在处理结账请求时在端到端执行流中执行多个操作。例如,分别由节点510和520表示的“sent.hipstershop.checkoutservice.placeorder”“和”sent.hipstershop.currencyservice.getsupportedcurrencies”各自由电子业务微服务应用的前端微服务执行。
50.图7示出了根据本文所述的一个或多个实施例的描绘跟踪的示例非限制性有向无环图(dag)。在图7中,根据命名跨度的因果排序,跟踪由命名跨度形成并且被描绘为dag。具体地,图7的dag包括描绘购物车添加项请求的跟踪(t1)的dag 700和描绘结账请求的跟踪(t2)的dag 750。如图7所示,跟踪t1包括来自图6所示的跨度名称列表600的三个命名的跨度。这三个命名的跨度包括:(i)前端-添加项跨度a;(ii)目录-得到产品跨度b;以及(iii)购物车-添加项跨度c。dag 700将包括跟踪t1的三个命名跨度的因果排序描述为前端-添加项跨度a后面跟着目录-得到产品跨度b,目录-得到产品跨度b后面跟着购物车-添加项跨度c。图7还示出了跟踪t2包括来自跨度名称列表600的四个命名跨度。这四个指定跨度包括:(i)前端-结账跨度e;(ii)结账-下订单跨度f;(iii)目录-得到产品跨度b;以及(iv)支付-收费跨度g。dag 750将包括跟踪t2的四个命名跨度的因果排序描述为前端结账跨度e,其后是结账-下订单跨度f,其后是目录-得到产品跨度b和支付-收费跨度g。共同地,命名跨度和它们的因果排序的组合可以对开发者所设计的程序逻辑具有强烈的影响。当系统管理员观察到跟踪偏离其正常形状时,微服务应用可以处于异常状态。因此,学习跟踪模式可以用于确定应用状态。
51.考虑如图7中的时间t处的跟踪的出现,并且假设可以观察到跟踪t1和t2的两个变体,如分别在图8和9的dag 800和900中所描绘的。初看起来,图8的dag 800中描述的跟踪由于额外的货币转换跨度d而在与图7的dag 700中描述的跟踪t1相比时是有问题的,然而,
跟踪中的货币转换跨度d的添加可以与跟踪的执行流中的先前跨度(即,前端添加向跨度a和目录-得到产品跨度b)的等待时间相关。例如,前端-添加项跨度a中的高延迟可能是由于将异常的导入的项添加到购物车而引起的。如图7和图8之间的比较所示,前端-添加项跨度a的延迟从轨迹t1中的4ms增加到轨迹中的60ms,这是跟踪中的前端-添加项跨度a的相对高的延迟可能需要将异常导入项的价格转换为当地货币。因此,跟踪是正常的。该因素可以被称为请求内依赖性。
52.图9示出了可影响跟踪的执行流的另一因素。对于由各个跟踪的序列训练的模型,如果用于训练该模型的训练数据包含比图9的dag 900中描绘的踪迹t2更多的图7的dag 750中描绘的跟踪的样本,则该模型将报告跟踪为异常跟踪。事实上,跟踪是正常的,并且偏差是由在购物车中添加项的先前请求引起的。例如,当先前的请求已经将两个项添加到购物车时,通常从目录微服务中提取产品细节(例如,价格、颜色、大小)两次以满足结账请求。换言之,跟踪中的目录-得到产品跨度b的数目取决于在跟踪的结账请求之前发生的添加项请求的数目(例如,轨迹t1的迭代的数目)。这个因素是请求间依赖性。
53.如上所述,微服务架构对于设计要部署在混合云环境中的应用是有吸引力的,因为松散耦合的组件(例如,微服务)提供优于单片服务架构的各种益处。示例性益处包括更好的可扩展性、灵活性、可维护性、加速的开发者生产率等。异常检测和诊断可以是建立可靠和可靠的微服务应用的重要方面。例如,避免服务级协定(sla)违规和潜在的相应影响涉及有效并且高效地检测异常,使得it专业人员(例如,devop和/或sre可以采取进一步的动作来及时地解决潜在的问题。
54.分布式跟踪作为现代云本地服务的核心组成部分,通过学习健康微服务应用的特性,为标识异常行为提供了极好的来源。由于文本和数值的异质混合,从通常与微服务应用相关联的大量跟踪数据中学习可能是有挑战性的。由于单个跟踪内以及跨多个跟踪的复杂依赖性,可能出现附加的挑战。现有方法通常不考虑可能导致假阳性增加的微服务之间的这种空间和时间依赖性。
55.本公开的实施例通过提供表征来自健康微服务应用的跟踪数据中的请求间和请求内依赖性以执行异常检测以及标识根本原因集的帧来解决上述挑战。为此,以下公开提供了便于微服务应用中的异常检测和/或rca的技术,微服务应用基于具有诸如神经网络的机器学习模型的请求上下文数据。这样,本公开的实施例建立机器学习模型,该机器学习模型可以从正常跟踪数据联合地学习请求内和请求间依赖性,以有效地检测微服务应用的异常行为。
56.所公开的框架的一个方面涉及嵌入算法,该嵌入算法使用应用于跟踪上的图形遍历的神经语言模型在低维向量空间中编码文本跟踪事件。字嵌入技术通常将文本转换为低维向量以在低维空间中创建字的表示。这样的表示可以通过考虑其与上下文(例如,句子)中的其他词的关系来捕捉词的含义,假设上下文中的更接近的词在统计上彼此更相关。在自然语言处理(nlp)中,嵌入模型(例如,word2vec、glove和bert)可以学习各种语料库中的词之间的句法和语义关系。微服务应用的跟踪中的跨度可以承载自然语言文本中的类似单词的含义。这样,所公开的框架的实施例可以实现用于文本跟踪数据中的命名跨度的嵌入机制。
57.所公开的帧的另一方面涉及用于异常检测和诊断的深度学习模型,其经由卷积长短期存储器(convlstm)编码器合并请求内和请求间依赖性。深度学习模型的实施例经由convlstm解码器产生重建的输入。在一个实施例中,深度学习模型的输入与由深度学习模型输出的重建输入之间的重建损失包含健康应用的跟踪数据中的特征,导致异常检测和诊断的一定等级的可解释性。
58.convlstm网络促进时间序列分析和序列建模任务,例如降水广播和视频分析。convlstm结合了两个神经网络的强项:卷积神经网络(cnn)和长短期存储器(lstm)。结果,convlstm不仅可以学习输入的时间序列内的时间依赖性,而且还可以学习跨多个时间序列的空间依赖性。这种由convlstm实现的空间-时间分析可应用于单个跟踪中的跨度(例如,请求内依赖性)以及跨多个跟踪(例如,请求间依赖性)之间的依赖性。
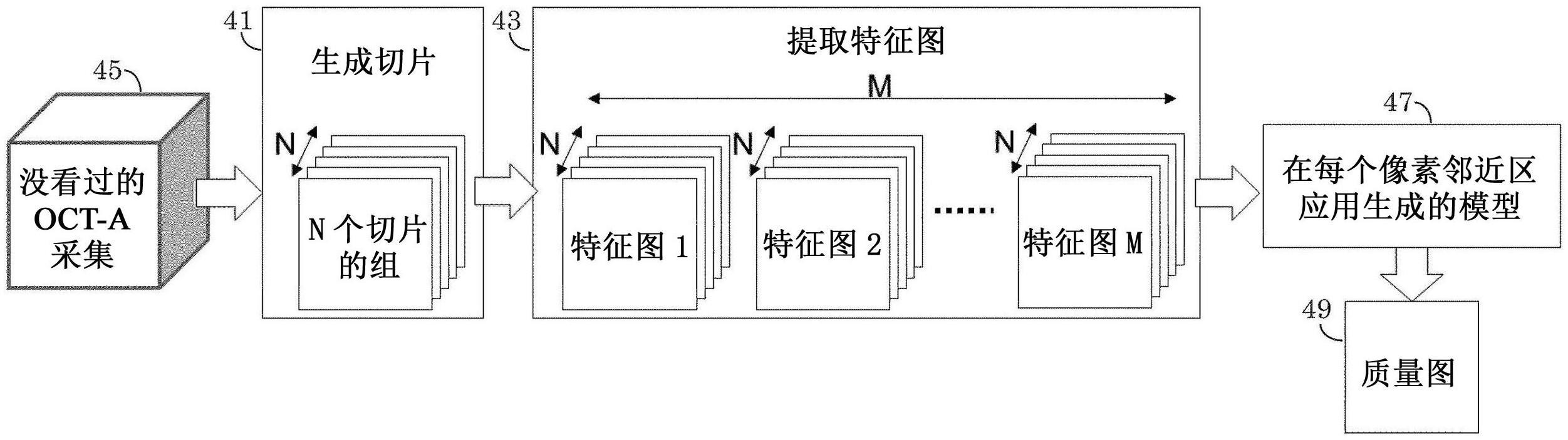
59.图10示出了根据在此描述的一个或多个实施例的用于实现用于由微服务应用检测异常行为的帧的示例非限制性架构1000。架构1000包括:模型训练阶段1010;以及异常检测和诊断阶段1050。模型训练阶段1010可以建立两个机器学习模型,以便于捕捉健康微服务应用1015的分布式跟踪数据中的请求内和请求间依赖性。如图10所示,由模型训练阶段1010构建的两个机器学习模型包括:嵌入模型1020;以及状态模型1030。在模型训练阶段1010中,嵌入算法1025(span2vec)可以使用神经语言模型来学习低维空间中的文本跨度名称的表示。利用向量的跨度名称和其它跨度属性,可以在模型训练阶段1010中使用基于convlstm的自动编码器算法1035来训练基于convlstm的自动编码器状态模型1030。在异常检测和诊断阶段1050中,嵌入模型1020和状态模型1030可与诊断过程1040一起使用以检测异常和/或提供描述性诊断结果。
60.令u∈u表示跨度名称,表示跨度的数字属性,其中u表示应用的跨度名的全集,而是f维向量。具有n个跨度的轨迹t可以写为并且轨迹t的文本部分可以使用由等式1定义的函数来表示:
61.{ui|1≤i≤n∧ui∈u}
62.等式1
63.如果问题被定义为给定从健康应用收集的m个踪迹的历史数据,即和跨度名集合u,则目标可以被定义为:(i)tm之后检测异常跟踪;以及(ii)标识指向根本原因的异常跟踪中的跨距。
64.由span2vec嵌入算法输出的嵌入模型的实施例(span2vec嵌入模型)可以涉及中的文本span名称的学习向量表示,其中span序列可以被认为是“句子”并且序列内的span作为“单词”,从nlp借用术语。更具体地,给定的文本表示(例如,等式1)的集合,span2vec嵌入模型的目标可以被定义为找到span的d维向量u∈u,使得相关的span位于向量空间附近。图11示出了span2vec嵌入模型的目标的示例、非限制性高级概念概述。如图11所示,span2vec嵌入模型1110的实施例可以接收描述微服务应用的轨迹的dag 1120作为输入,并且输出嵌入轨迹的每个跨距的d维向量。
65.构建语言模型通常包括两个输入:语料库和词汇表v。虽然让v=u是清楚的,但是由等式1定义的跨度序列不能用作字面意义上的语料库。由图12的dag1200描绘的跟踪的跨度序列可以由构成跟踪的每个跨度的相应创建时间来排序。在这种情况下,由dag 1200描
述的跟踪的跨度序列可以是(a,b,c,d,e,f)。然而,该跨度序列提供了dag1200中跨度关系的不完整表示。例如,跨度d和跨度f之间的父-子连接在该跨度序列中是缺失的。此外,由于在b处分叉的跟踪的两个分支可以并行运行,所以该顺序可以变得不稳定,这可以导致非确定性结果。
66.span2vec嵌入模型的实施例可以使用考虑跟踪dag中的跨度之间的顺序和并行关系的图遍历算法来解决该问题。作为示例,span2vec嵌入模型可以利用修改的深度优先搜索(dfs)和宽度优先搜索(bfs)图遍历算法的组合。在该示例中,反向dfs图遍历算法可以用叶节点(例如,dag1200的叶节点e和d)来初始化图12的dag1200所描绘的跟踪的跨度序列,并且将其父节点递归地添加到跨度序列,直到反向dfs图遍历算法遇到根节点(例如,根节点a)。反向dfs图遍历算法的操作在图12中由虚线箭头表示。图12示出了应用于由dag1200描绘的跟踪的反向dfs图遍历算法的示例非限制性输出1210。然后,对于具有多于两个子节点的dag 1200的每个节点,1跳bfs图遍历算法可以初始化以该节点为第一元素的新跨度序列,并且将该节点的所有子节点连接到该新跨度序列。在1跳bfs图遍历算法的应用中涉及的dag 1200的节点由图12中的阴影顶点表示。图12还示出了应用于由dag1200描绘的跟踪的1跳bfs图遍历算法的示例非限制性输出1220。
67.图13示出了根据本文描述的一个或多个实施例的将多路径dfs(mpdfs)和1跳bfs图遍历算法非限制性地应用于微服务应用的跟踪的示例。图14示出了根据这里描述的一个或多个实施例的另一示例,即mpdfs和1跳bfs图遍历算法非限制性地应用于微服务应用的跟踪。嵌入算法(例如,图10的嵌入算法1025)可以从输入踪迹集构建跨度词汇表,以便为包括输入踪迹集的每个踪迹生成序列,如图13至图14所示。dag中的每个节点可以表示跨度(或微服务上的操作,其具有一个或多个特征,诸如持续时间,dag中两个节点之间的边可以指示由两个节点表示的两个操作之间的调用关系。基于dag,嵌入算法可以为dag中的每个节点生成跨度序列,其可类似于nlp中的单词。为了保持逻辑关系(例如,nlp中的语义),示例嵌入算法可以使用图13至14中所示的两种策略(mpdfs和1-hop bfs图遍历算法)来遍历dag。嵌入算法可以将跨度-上下文序列提供给跳字(skip-gram)网络,并可以提取隐藏层作为嵌入权重。
68.在一个实施例中,可以使用算法1生成用于词汇表v的嵌入矩阵以建立语言模型:
69.70.算法1
71.如上所示,算法1可以基于包括跟踪集跨度名的词汇v和两个嵌入参数的输入来输出词汇v的嵌入矩阵:d和w。在循环中,算法1可以对跟踪集合中的所有跟踪进行迭代。对于每个跟踪t,算法1可以首先构建dag,其中顶点是跨度名称,并且边是跨度之间的父子引用(例如,算法1的第2行)。随后,算法1可以在dag上运行反向dfs和1跳bfs图遍历算法,并且将序列附加到语料库x(例如,算法1的第3-4行)。在该实施例中,算法1可以使用神经语言工具包(例如,genism)来生成用于跨度词汇表v的嵌入模型(例如,算法1的第5行)。嵌入维度(d)和上下文窗口(w)输入参数的大小的影响将在下面参考图22至图23更详细地评估。
72.在学习了向量化跨度表示之后,以下公开描述了输入数据准备和应用状态模型(例如,图10的状态模型1030),以使用历史踪迹数据学习健康微服务应用的踪迹中的依赖性。首先,历史跟踪数据可被划分成一行跟踪帧,诸如图15的示例非限制性跟踪帧1500。图15示出了跟踪帧1500可以由l条跟踪形成,并且所有跟踪可以被填充或截断以具有n个跨度。在嵌入(例如,通过span2vec嵌入模型)之后,文本跨度名称可以由d维向量表示,并且可以与其他数字属性连接,因此具有n个跨度的轨迹的表示变为:
[0073][0074]
在等式2中,f是跨度的数值属性的维数。给定等式2,跟踪帧x可以被写为由等式3定义:
[0075][0076]
根据等式3,跟踪帧1500可以是从可以表征微服务应用的状态的历史踪迹数据构建的矩阵。跟踪帧1500的每行表示微服务应用的轨迹,跟踪帧1500的每列表示跟踪的跨度。由跟踪帧1500形成的矩阵的每个元素是给定跨度的d维向量嵌入。就跟踪帧1500包括l个跟踪而言,个跟踪帧可以从历史跟踪数据中总共形成。
[0077]
所公开的框架的实施例还包括建立基于convlstm的自动编码器模型,以使用包括历史跟踪数据的训练数据来学习请求内和请求间依赖性。基于convlstm的自动编码器模型将λ跟踪帧序列x=(x1,x2,...,x
λ
)作为输入,诸如图18中所示的非限制性的λ跟踪帧序列1800。基于convlstm的自动编码器模型可以将λ跟踪帧序列编码成降维的维度,并且将该序列解码为x
′
=(x
′1,x
′2,...,x
′
λ
),其目标函数是最小化x与x'之间的重构损失。基于convlstm的自动编码器模型的构件块可以是如图16所示的convlstm单元1600。convlstm单元1600包括cnn层1610和lstm层1620。对convlstm单元1600的输入可以是跟踪帧x和来自λ跟踪帧序列中的前一跟踪帧的隐藏状态。如图17所示,在每个时间步(即,基于convlstm的自动编码器模型1700的每个convlstm单元),卷积层可以通过保持跨度及其邻居之间的空间关系来捕获请求内和请求间依赖性两者,跨度及其邻居是相同跟踪和先前或后续跟踪的跨度。基于convlstm的自动编码器模型1700的lstm层可以学习λ个跟踪帧序列中的时间依赖性。下面将参考图24至图25更详细地讨论时间步长λ的影响。
[0078]
虽然图17将基于convlstm的自动编码器模型1700图示为包括一对编码和解码convlstm单元,但是可以堆叠多对编码和解码convlstm单元以实现根据本公开的实施例的基于convlstm的自动编码器模型。图19示出了根据本文所述的一个或多个实施例的通过堆叠多对编码和解码convlstm单元来实现的示例性非限制性的基于convlstm的自动编码器模型1900。在图19中,基于convlstm的自动编码器模型1900包括10个跟踪帧的时间步长λ。如上所述,向基于convlstm的自动编码器模型提供输入的每个跟踪帧包括在每个跟踪中具有n个跨度的l个跟踪。在图19中,l和n各自被设置为256。嵌入每个跨度的d维向量的嵌入大小d是30。
[0079]
如图19所示,基于内容的自动编码器模型1900包括输入层1910、空间编码器1920、时间编码器1930、瓶颈状态层1940,时间解码器1950、空间解码器1960和输出层1970。空间编码器1920可以捕捉产生嵌入在提供给输入层1910的跟踪帧中的文本跟踪数据的微服务应用的微服务之间的空间依赖性。时间编码器1930可以捕捉微服务应用的微服务之间的时间依赖性。提供给输入层1910的跟踪帧的维数可以在瓶颈状态层1940处减小。时间解码器1950可以重建微服务应用的微服务之间的时间依赖性。空间解码器1960可以重建微服务应用的微服务之间的空间依赖性。在输出层1970处提供与提供给输入层1910的跟踪帧具有相同维数的重建跟踪帧。
[0080]
等式4定义了测量时间t处的输入序列x
t
和输出序列x
′
t
之间的重建误差的损失函数,用于训练基于convlstm的自动编码器模型。
[0081][0082]
根据等式4,e(
·
)可以计算两个跟踪帧之间的误差。给定等式2和等式3,e(
·
)可以写为:
[0083][0084][0085]
根据等式5,l是帧中的跟踪的数目,n是跟踪中的跨度的数目,并且||
·
||2表示l2范数。
[0086]
在训练之后,如等式5所定义的span2vec嵌入和状态模型可以通过重构损失来检测包括历史跟踪数据的测试数据中的异常和/或诊断根本原因,首先,span2vec嵌入模型可以将测试数据中的文本跨度名称转换为向量,并且可以如等式2和3所定义的以跟踪帧的格式准备测试数据,实际上,跟踪帧可以被应用于具有跨距s=1的λ个帧的滑动窗口(即,随着滑动窗口进行的跳过帧的数目)。滑动窗中的λ
×
l跟踪可以形成对状态模型的一批输入,并且生成重建损失,如等式5所定义。被分类为“正常”的跟踪的重建损失值应该在[hu,h
l
]的范围内。具有在该范围之外的重构损耗值的跟踪的重构损耗值应当被分类为“异常”。存在
定义hu和h
l
用于异常检测的各种方式。在一个实施例中,hu和h
l
可以分别定义为hu=95
th
个百分位和h
l
=5
th
个百分位其中是训练数据中的损失。
[0087]
基于为基于convlstm的自动编码器模型计算的重构损失,诊断过程(例如,图10的诊断过程1040)可以贪婪地选择与跟踪帧序列的总损失相加最多的跟踪帧:e
*
=arg max
x
e(xi,x
′i),xi∈x
t
),其中x
t
是分类为异常的跟踪帧序列(即)。然后,在所选择的跟踪帧e
*
中,我们递归地选择前k个跟踪,并且可以按照它们的相加顺序递归地选择跨度,如等式5中所定义的那样,这样,可以引导和缩小根情况的搜索空间。
[0088]
以下公开内容描述了用于微服务应用中的异常检测和/或rca的所公开的帧的实现的示例性演示的设置,微服务应用将在下面被称为deep跟踪。示例演示利用了部署在5节点kubernetes集群中的三个微服务应用,包括:乘坐共享应用,电子业务web应用;以及社交网络应用。
[0089]
乘坐共享应用包括服务于用户请求并且对后端微服务器进行rpc调用的web用户界面(ui)。乘坐共享应用允许两种类型的用户请求:(i)浏览ui;以及(ii)请求乘坐。为了请求乘坐,乘坐共享应用的用户选择目的地地址,并且乘坐共享应用调度驾驶员。在包括乘坐共享应用的所有微服务处生成跟踪。
[0090]
电子业务web应用包括比具有12种微服务和7种编程语言的乘坐共享应用更复杂的架构。电子业务web应用允许6种类型的用户请求,诸如将项添加到购物车,结帐和设置货币。每个请求类型涉及微服务的子集,导致跟踪的不同组合。电子业务web应用的三个微服务不产生跟踪,因为它们不配备跟踪库。
[0091]
社交网络应用包括36个微服务。与乘坐共享应用和电子业务web应用不同,社交网络web应用中的大多数微服务具有其专用数据存储,包括:用于高速缓存的memcached或用于持久存储的mongodb。考虑用于示例演示的7中请求类型,诸如注册新用户、认证登录、编写消息、浏览时间线。在社交网络应用的所有微服务处生成跟踪。
[0092]
在示例演示中使用开环工作负载生成器(例如,locust 2019),其仿真用户行为以将请求驱动到三个微服务应用。假设微服务应用是健康的,则利用变化数量的仿真用户来收集开环工作负载生成器的训练数据。该训练数据包括分别来自乘坐共享应用,电子业务web应用和社交网络web应用的50k、57k、76k跟踪。
[0093]
示例演示的测试数据由注入异常生成,包含25k跟踪。示例演示中使用的注入异常如下表1所示。表1列出了如何为每个微服务应用定制注入异常以诱发异常60秒。
[0094][0095][0096]
表1
[0097]
在ia-0注入异常的情况下,微服务应用是健康的并且经历用户请求的突发,但是没有违反任何sla。这样,ia-0注入异常用于评估基于convlstm的自动编码器模型的稳健性。在ia-1注入异常下,微服务应用的微服务具有增加的等待时间,这导致对请求的缓慢响应。在ia-2注入异常的情况下,微服务应用的微服务被禁用,导致一些用户请求失败。ia-1和ia-2注入的异常影响微服务应用的性能,因为一些用户请求由于受损的微服务而以错误或缓慢响应返回。
[0098]
在ia-3注入异常下,微服务应用的两个微服务之间的通信受到一些网络事件的影响,导致高分组丢失率。ia-3注入异常具有性能和执行异常的合并效应。在ia-4注入异常下,微服务应用的某些高速缓存服务或副本被破坏,这产生非典型的跟踪。在ia-5注入异常下,微服务应用接收对应于ddos攻击形式的重复请求的激增(例如,用欺诈性信用卡结账),其打破了典型用户的请求模式。ia-4和ia-5注入的异常产生由异常请求模式或执行路径引起的非典型跟踪模式。
[0099]
示例演示将微服务应用中的deeptrace(即,所公开的框架的实现)与许多不同方法进行比较。在张量流中实现了实例演示的所有机器学习模型,在go中实现了span2vec嵌入算法中的图形遍历。该示例演示将deeptrace与包括基于利用的方法和tr-pca的第一方法集进行比较。基于使用的方法监视群集节点的cpu和存储器使用。当任何使用超过特定阈值(例如,平均值
±
3.偏差)时,基于使用的方法发出警报信号。第一方法集中的另一方法tr-pca将跟踪中跨度的持续时间作为日志的有序列表,并且应用主成分分析以找到跨度之间的依赖性。tr-pca方法通过使用马哈拉诺比斯(mahalanobis)距离对正常数据进行聚类来找到跨度之间的依赖性。如果测试数据到正常类的马哈拉诺比斯距离超过阈值,则tr-pca方法将跟踪标识为异常。
[0100]
该示范性展示还将deeptrace与基于深度学习的方法集对比,包括:tr-ed和tr-led。基于深度学习的方法集的两种方法使用与tr-pca相同的输入数据。tr-ed方法训练由
多层密集网络堆叠的自动编码器,而tr-led方法的自动编码器使用lstm网络来捕捉请求内依赖性。
[0101]
实例演示还比较了deeptrace与deeptrace的两种变型,以证明span2vec嵌入算法和基于convlstm的自动编码器模型的有效性。deeptrace的第一变型dt-no-s2v使用张量流中的嵌入层来代替span2vec嵌入算法。deeptrace的第二变型dt-lstm用lstm单元代替基于convlstm的自动编码器模型的convlstm单元。
[0102]
以下公开内容描述了上述示例演示的结果。示例显示使用精度、召回、和f得分来测量异常检测的性能。当每次注入一个异常时,示例演示分别计算每个异常的度量,并且还计算这些异常上的f得分的平均值。
[0103]
根据输入/输出形状,异常检测方法以各种粒度标记跟踪数据。deeptrace和deeptrace的第一变型(dt-no-s2v)采用λ个跟踪帧的序列,每个跟踪帧由l个跟踪形成,因此它们共同考虑λ
×
l个跟踪:所有或无异常。利用lstm的两个基线,即tr-led和第二变型跟踪(dt-lstm),标记具有相同状态的跟踪序列。通过示例演示测试的其余方法单独报告状态——基于利用率的方法,tr-pca方法和tr-ed方法。尽管粒度不同,但在这些方法中始终在总跟踪上计算度量。
[0104]
示例性演示给出了所公开的框架及其两个变型的实现的结果,其中d=64,w=5,λ=10,并且l=16。对于其它基线,示例性演示探索其参数空间并且报告最佳结果。图20示出了表2000,其呈现了以下示例呈现的结果,其中在每列处的最高(最低)得分以灰色背景(下划线)突出显示。由于ia-0注入异常没有异常数据,因此示例演示报告准确度(表2000的最后一列),因为在这种情况下精度,召回和f得分没有意义(真阳性的#为0)。表2000中呈现的结果是从随机生成的数据获得的示例演示的仿真结果。本领域技术人员将理解,表2000中呈现的结果的各方面可以针对非仿真实现中的不同数据集来调整。
[0105]
从表2000可以得到若干观察结果。例如,两个非深度学习基线(即,基于利用的方法和tr-pca方法)不能有效地处理异常检测任务。表2000示出了相比于基于深度学习的方法集;传统方法在跟踪中捕捉较不复杂的关系。直观上,当资源未被充分利用时,基于利用的方法难以检测异常。
[0106]
从表2000可以看出,经由lstm网络结合时间关系的基于深度学习的方法组的性能优于密集网络。该观察指示应当考虑单个跟踪中的请求内依赖性。具体地,尽管通过相同的输入数据进行训练,但tr-led方法在大多数列中优于tr-ed方法。对于ia-3,ia-4和ia-5注入异常尤其如此,其中异常是由于单个跟踪内的不规则执行路径。
[0107]
从表2000可以得出的另一观察结果是,所公开的框架的实现方式deeptrace在所评估的所有方法中具有最好的总体性能,其中所有f得分》0.8。deeptrace的两个修改版本还实现了乘坐共享应用和电子业务web应用的良好性能。然而,这两种变型的平均f得分对于具有更复杂架构的社交网络web应用是下降的。例如,对于ia-5注入异常,由于请求内依赖性几乎不受重复的对手请求的影响,所以这两个变型错过了社交网络web应用的许多异常跟踪(召回=0.37和0.59)。相反,deptrace可以报告大多数异常(召回=0.7),这证实了捕捉请求间和请求内依赖性的重要性以及span2vec嵌入算法的有效性。
[0108]
为了进一步理解如何标记异常跟踪,图21示出了描绘针对社交网络web应用计算的相对于时间的失踪重建损失的示例非限制性曲线图2100。在线2100中,水平线定义了重
建损失在上限(hu)和下限(h
l
)之间的正常范围。此外,图2100中的灰色带指示注入异常的相应持续时间。
[0109]
图表2100示出了deeptrace成功地标识出在工作量变型(ia-0)期间社交网络应用是健康的,因为损失在正常范围内。图2100还示出了针对每个注入异常(即,注入异常ia-1至ia-5)的4个尖峰和一个超出正常范围。值得注意的是,图2100示出ia-5注入异常的重建损失低于下限,其不同于其他注入异常。由于用户注册跟踪比大多数其它请求短,大量零填充的注册跟踪向量可以导致重建损失低于阈值。这证实了在异常检测方法中设置重建损失的正常范围的下限是有益的。另一观察结果是尖峰和下降相对于相应的注入异常在时间轴上向左偏斜。在数量上,这些未对准可导致假阳性和假阴性。在一些情况下,这种未对准可能是因为deeptrace在跟踪帧序列的粒度中对状态进行分类,所以在尖峰开始处的异常跟踪帧中的正常跟踪可能被错误地标记为异常。然而,大多数跟踪被正确标记。
[0110]
实例演示研究了deeptrace参数的变化,所公开的框架的实现如何影响其对异常检测的性能。为此,当ia-3和ia-5注入的异常的重建损失在图21的曲线图2100中不同地变化时,该示例演示对ia-3和ia-5注入的异常进行实验。尽管图2100描绘社交网络web应用的结果,但结果类似于实例演示中所使用的其它应用。
[0111]
嵌入算法的span2vec的输出可以取决于两个参数:嵌入维度(d)和上下文窗口的大小(w)。图22至图23示出了描绘根据f得分改变d和w的效果的示例非限制性曲线图。图22的曲线图2200示出了增加嵌入维度(d)或窗口维度(w)对ia-3注入异常的f得分具有边际改善,这表明结果对两个参数不敏感。相反,图23的曲线图2300示出了对于ia-5注入异常将d=4增加到d=32使性能提高了大于10%,但是在d=32之后,由于过拟合,增益是不显著的或下降的。另外,可以注意到,增加窗口大小(w)可以降低关于ia-5注入异常的性能。回想在ia-5注入异常下,异常是由重复请求的激增引起的,这打破了请求间的依赖性。由于较大的上下文窗口大小考虑了跨度的更多依赖性,所以对丢失计数更多的添加以使它们高于较低阈值,从而降低了召回率和f得分。因此,在某些情况下,选择大于词汇大小的嵌入维度(d)和诸如5的小窗口大小(w)可能是有益的。
[0112]
图24至图25示出了描绘增加λ的影响的示例非限制性曲线图,所公开的框架的实施例将时间步长用作输入到基于convlstm的自动编码器模型的跟踪帧的数量。特别地,图2400和2500分别描绘了变化的时间步长λ相对于ia-3和ia-5注入异常的影响。如图2400和2500所示,较大的时间步长λ可以导致较高的召回率但较低的精度。两种注入异常的趋势相似。图2400和2500进一步示出了中值时间步长(λ=10)可以产生关于f得分的改进的总体性能。
[0113]
图26说明描绘通过实例演示获得的社交网络web应用的诊断结果的表2600。如上所述,一旦滑动窗口中的跟踪帧序列被分类为异常,诊断过程可以首先选择对重建损失具有最大贡献的帧,然后诊断过程可以递归地检查其跟踪和跨度以寻找有故障的微服务。表2600第2列中的前2条选定跟踪与异常类型高度相关。对于诸如ia-1注入异常之类的某些异常,在标识出可疑跟踪之后,可以直接从这些跟踪的可视化甘特图中精确定位故障微服务。对于其它异常,来自所选跟踪的跨度可以按照跨度相应地添加到重建损失的顺序来检查,并且可以筛选那些跨度中所涉及的微服务。表2600中的第3列显示了前两种或三种微服务。在表2600的第3列中,以粗体突出显示被标识为故障的微服务。所观察到的示例性演示是,
所公开的帧的实现可以包括针对所有异常的列表中的故障微服务。
[0114]
图27示出了示例性非限制性曲线图2700,其描绘了示例性演示中所利用的所有三个微服务应用的相对诊断性能。图表2700描述了所有异常中acc@k的相对诊断性能。如本文所使用的,acc@k指的是实际故障微服务被包括在前k个报告的微服务中的概率。在影响诊断结果的实例演示中,一些基线法的异常检测性能较差。照此,图2700仅呈现tr-led方法(即,除deeptrace的两个变型之外的最佳基线方法)的诊断性能并且应用相同的诊断方法。如图27所示,图2700描绘了k=1、3的诊断性能结果。通过比较图2700中的deeptrace(@3)和deeptrace(@1)可以观察到,deeptrace的诊断准确度随着k的增加而提高。从曲线图2700中还可以看出,跨所有三个微服务应用,deeptrace优于tr-led方法。
[0115]
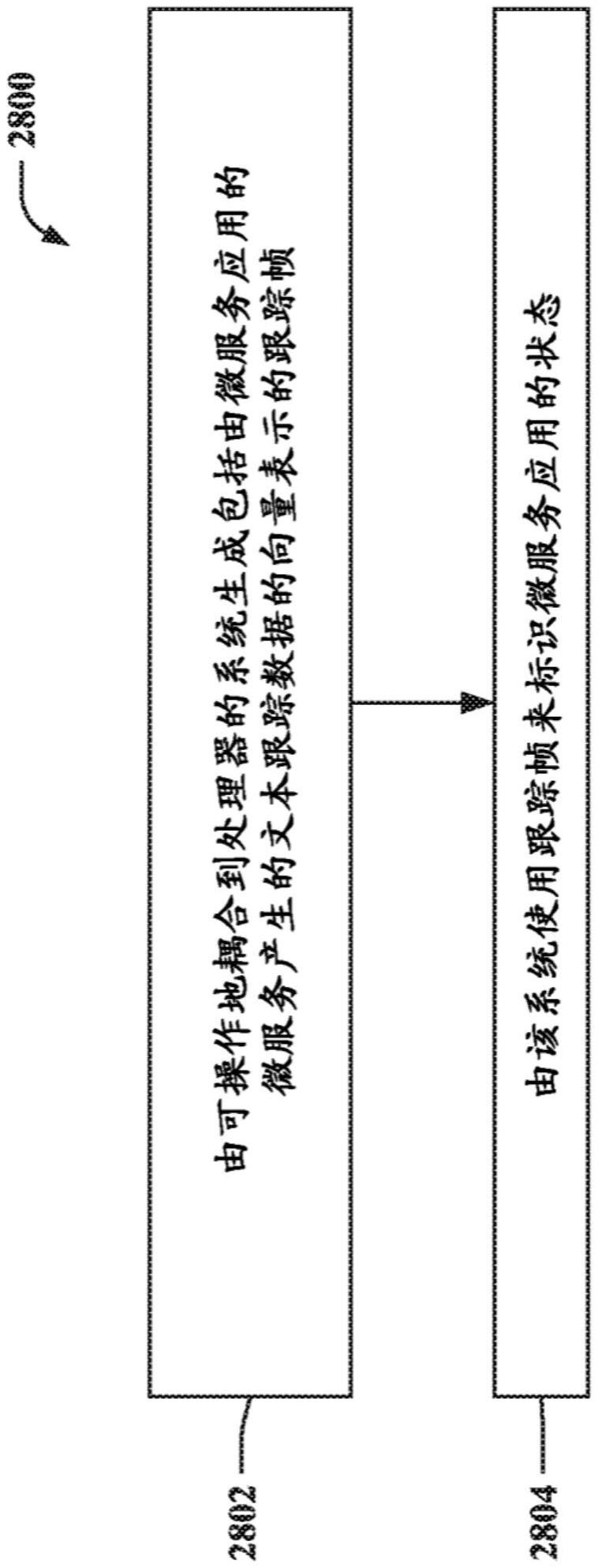
图28示出了根据本文所述的一个或多个实施例的便于使用分布式跟踪数据进行异常检测和根本原因分析的示例性非限制性计算机实现的方法2800的流程图。为了简洁起见,省略了对本文所述的其它实施例中采用的类似元素的重复描述。在2802处,计算机实现的方法2800可以包括由可操作地耦合到处理器(例如,利用预处理组件140)的系统生成包括由微服务应用的微服务产生的文本跟踪数据的向量表示的跟踪帧。在一个实施例中,系统可以利用使用图形遍历算法、字嵌入技术或其组合训练的机器学习模型来生成跟踪帧。
[0116]
在2804处,计算机实现的方法2800可以包括由该系统(例如,利用监控组件150)使用跟踪帧来标识微服务应用的状态。在一个实施例中,系统可以通过将跟踪帧与由机器学习模型生成的重建跟踪帧进行比较来标识微服务应用的状态。在一个实施例中,当在正常状态下操作时,机器学习模型可以捕捉微服务应用的微服务之间的空间依赖性和时间依赖性。在一个实施例中,系统可以通过将跟踪帧序列与由机器学习模型生成的重建跟踪帧序列进行比较来标识微服务应用的状态。跟踪帧序列可以包括跟踪帧。在一个实施例中,机器学习模型可以是基于convlstm的自动编码器模型。在一个实施例中,该计算机实现的方法2800可以进一步包括:由系统通过评估每个微服务对给定重建损失的贡献来执行rca。
[0117]
为了提供所公开的主题的各方面的上下文,图29以及以下讨论旨在提供其中可实现所公开的主题的各方面的合适环境的一般描述。图29示出用于实现本公开的各方面的合适的操作环境2900还可包括计算机2912。计算机2912还可以包括处理单元2914、系统存储器2916和系统总线2918。系统总线2918将包括但不限于系统存储器2916的系统组件耦合到处理单元2914。处理单元2914可以是任何各种可用处理器。双微处理器和其它多处理器架构也可用作处理单元2914。系统总线2918可以是任何若干类型的总线结构,包括存储器总线或存储器控制器、外围总线或外部总线、和/或使用任何种类的可用总线架构的局部总线、所述总线架构包括但不限于工业标准架构(isa)、微通道架构(msa)、扩展isa(eisa)、智能驱动电子设备(ide)、vesa局部总线(vlb)、外围组件互连(pci)、卡总线、通用串行总线(usb)、高级图形端口(agp)、火线(ieee1094)和小型计算机系统接口(scsi)。系统存储器2916还可以包括易失性存储器2920和非易失性存储器2922。包含诸如在启动期间在计算机2912内的元素之间传送信息的基本例程的基本输入/输出系统(bios)被存储在非易失性存储器2922中。作为说明而非限制,非易失性存储器2922可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)、闪存或非易失性随机存取存储器(ram)(例如,铁电ram(feram))。易失性存储器2920还可以包括用作外部高速缓冲存储器的随机存取存储器(ram)。作为说明而非限制,ram可以许多形式获得,例如静态ram
(sram)、动态ram(dram)、同步dram(sdram)、双数据速率sdram(ddrsdram)、增强型sdram(esdram)、同步链路dram(sldram)、直接rambusram(drram)、直接rambus动态ram(drdram)和rambus动态ram。
[0118]
计算机2912还可以包括可移动/不可移动、易失性/非易失性计算机存储介质。例如,图29示出了磁盘存储器2924。磁盘存储器2924还可以包括,但不限于,诸如磁盘驱动器、软盘驱动器、磁带驱动器、jaz驱动器、zip驱动器、ls-100驱动器、闪存卡或记忆棒之类的设备。磁盘存储器2924还可包括单独的存储介质或与其它存储介质组合的存储介质,其它存储介质包括但不限于,诸如紧致盘rom设备(cd-rom)、cd可记录驱动器(cd-r驱动器)、cd可重写驱动器(cd-rw驱动器)或数字多功能盘rom驱动器(dvd-rom)等光盘驱动器。为了便于将磁盘存储器2924连接到系统总线2918,通常使用可移动或不可移动的接口,诸如接口2926。图29还示出了用作用户和在合适的操作环境2900中描述的基本计算机资源之间的中介的软件。这样的软件还可以包括例如操作系统2928。操作系统2928可以存储在磁盘存储器2924上,用于控制和分配计算机2912的资源。系统应用2930通过例如存储在系统存储器2916或磁盘存储器2924上的程序模块2932和程序数据2934利用操作系统2928对资源的管理。应当理解,本公开可以用各种操作系统或操作系统的组合来实现。用户通过输入设备2936将命令或信息输入到计算机2912。输入设备2936包括但不限于,诸如鼠标、跟踪球、指示笔、触摸垫等定点设备、键盘、话筒、操纵杆、游戏垫、圆盘式卫星天线、扫描仪、tv调谐卡、数码相机、数码摄像机、web相机等等。这些和其它输入设备经由接口端口2938通过系统总线2918连接到处理单元2914。接口端口2938包括,例如,串行端口、并行端口、游戏端口和通用串行总线(usb)。(多个)输出设备2940使用与(多个)输入设备2936相同类型的端口中的一些端口。因此,例如,usb端口可以用于向计算机2912提供输入,以及从计算机2912向输出设备2940输出信息。提供输出适配器2942以说明除了其它输出设备2940之外,还存在一些输出设备2940,如监视器、扬声器和打印机,它们需要特殊的适配器。输出适配器2942包括,作为说明而非限制,提供输出设备2940和系统总线2918之间的连接手段的视频卡和声卡。可以注意到,其它设备和/或设备的系统提供输入和输出能力,诸如(多个)远程计算机2944。
[0119]
计算机2912可以使用与一个或多个远程计算机,如远程计算机2944的逻辑连接,在网络化环境中操作。(多个)远程计算机2944可以是计算机、服务器、路由器、网络pc、工作站、基于微处理器的装置、对等设备或其它常见的网络节点等,并且通常还可包括许多或相对于计算机2912所描述的元素。为了简洁起见,仅存储器存储设备2946与远程计算机2944一起示出。(多个)远程计算机2944通过网络接口2948逻辑上连接到计算机2912,然后通过通信连接2950物理地连接。网络接口2948包括有线和/或无线通信网络,诸如局域网(lan)、广域网(wan)、蜂窝网络等。lan技术包括光纤分布式数据接口(fddi)、铜线分布式数据接口(cddi)、以太网、令牌环等。wan技术包括,但不限于,点对点链路、像综合业务数字网(isdn)及其变体那样的电路交换网络、分组交换网络、以及数字用户线(dsl)。(多个)通信连接2950是指用于将网络接口2948连接到系统总线2918的硬件/软件。虽然为了清楚说明,通信连接2950被示出在计算机2912内部,但是它也可以在计算机2912外部。仅出于示例性目的,用于连接到网络接口2948的硬件/软件还可以包括内部和外部技术,诸如包括常规电话级调制解调器、电缆调制解调器和dsl调制解调器的调制解调器、isdn适配器和以太网卡。
[0120]
本发明可以是任何可能的技术细节集成水平的系统、方法、装置和/或计算机程序产品。计算机程序产品可以包括其上具有计算机可读程序指令的计算机可读存储介质(或多个介质),所述计算机可读程序指令用于使处理器执行本发明的各方面。计算机可读存储介质可以是能够保留和存储由指令执行设备使用的指令的有形设备。计算机可读存储介质可以是例如但不限于电子存储设备、磁存储设备、光存储设备、电磁存储设备、半导体存储设备或前述的任何合适的组合。计算机可读存储介质的更具体示例的非穷举列表还可以包括以下:便携式计算机磁盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或闪存)、静态随机存取存储器(sram)、便携式光盘只读存储器(cd-rom)、数字多功能盘(dvd)、记忆棒、软盘、诸如上面记录有指令的打孔卡或凹槽中的凸起结构的机械编码装置,以及上述的任何适当组合。如本文所使用的计算机可读存储介质不应被解释为暂态信号本身,诸如无线电波或其他自由传播的电磁波、通过波导或其他传输介质传播的电磁波(例如,通过光纤线缆的光脉冲)、或通过导线传输的电信号。
[0121]
本文描述的计算机可读程序指令可以从计算机可读存储介质下载到相应的计算/处理设备,或者经由网络,例如互联网、局域网、广域网和/或无线网络,下载到外部计算机或外部存储设备。网络可以包括铜传输电缆、光传输光纤、无线传输、路由器、防火墙、交换机、网关计算机和/或边缘服务器。每个计算/处理设备中的网络适配卡或网络接口从网络接收计算机可读程序指令,并转发计算机可读程序指令以存储在相应计算/处理设备内的计算机可读存储介质中。用于执行本发明的操作的计算机可读程序指令可以是汇编指令、指令集架构(isa)指令、机器相关指令、微代码、固件指令、状态设置数据、集成电路的配置数据,或者以一种或多种编程语言(包括面向对象的编程语言,例如smalltalk、c 等)和过程编程语言(例如“c”编程语言或类似的编程语言)的任何组合编写的源代码或目标代码。计算机可读程序指令可以完全在用户的计算机上执行,部分在用户的计算机上执行,作为独立的软件包执行,部分在用户的计算机上并且部分在远程计算机上执行,或者完全在远程计算机或服务器上执行。在后一种情况下,远程计算机可以通过任何类型的网络连接到用户的计算机,包括局域网(lan)或广域网(wan),或者可以连接到外部计算机(例如,使用互联网服务提供方通过互联网)。在一些实施例中,为了执行本发明的各方面,包括例如可编程逻辑电路、现场可编程门阵列(fpga)或可编程逻辑阵列(pla)的电子电路可以通过利用计算机可读程序指令的状态信息来执行计算机可读程序指令以使电子电路个性化。
[0122]
本文参考根据本发明实施例的方法、装置(系统)和计算机程序产品的流程图和/或框图描述本发明的各方面。将理解,流程图和/或框图的每个框以及流程图和/或框图中的框的组合可以由计算机可读程序指令来实现。这些计算机可读程序指令可以被提供给通用计算机、专用计算机或其他可编程数据处理装置的处理器以产生机器,使得经由计算机或其他可编程数据处理装置的处理器执行的指令创建用于实现流程图和/或框图的一个或多个框中指定的功能/动作的装置。这些计算机可读程序指令还可以存储在计算机可读存储介质中,其可以引导计算机、可编程数据处理装置和/或其他设备以特定方式工作,使得其中存储有指令的计算机可读存储介质包括制品,该制品包括实现流程图和/或框图的一个或多个框中指定的功能/动作的各方面的指令。计算机可读程序指令还可以被加载到计算机、其他可编程数据处理装置或其他设备上,以使得在计算机、其他可编程装置或其他设备上执行一系列操作动作,以产生计算机实现的过程,使得在计算机、其他可编程装置或其
他设备上执行的指令实现流程图和/或框图的一个或多个框中指定的功能/动作。
[0123]
附图中的流程图和框图示出了根据本发明的各种实施例的系统、方法和计算机程序产品的可能实现的架构、功能和操作。在这点上,流程图或框图中的每个框可以表示指令的模块、段或部分,其包括用于实现指定的逻辑功能的一个或多个可执行指令。在一些替代实施方案中,框中所注明的功能可不按图中所注明的次序发生。例如,连续示出的两个框实际上可以基本上同时执行,或者这些框有时可以以相反的顺序执行,这取决于所涉及的功能。还将注意,框图和/或流程图图示的每个框以及框图和/或流程图图示中的框的组合可以由执行指定功能或动作或执行专用硬件和计算机指令的组合的专用的基于硬件的系统来实现。
[0124]
尽管以上在运行在一个和/或多个计算机上的计算机程序产品的计算机可执行指令的一般上下文中描述了本主题,但是本领域的技术人员将认识到,本公开也可以结合其它程序模块来实现或可以结合其它程序模块来实现。通常,程序模块包括执行特定任务和/或实现特定抽象数据类型的例程、程序、组件、数据结构等。此外,本领域的技术人员可以理解,本发明的计算机实现的方法可以用其它计算机系统配置来实施,包括单处理器或多处理器计算机系统、小型计算设备、大型计算机、以及计算机、手持式计算设备(例如,pda、电话)、基于微处理器的或可编程的消费或工业电子产品等。所示的各方面也可以在其中任务由通过通信网络链接的远程处理设备执行的分布式计算环境中实践。然而,本公开的一些方面,如果不是所有方面,可以在独立计算机上实践。在分布式计算环境中,程序模块可以位于本地和远程存储器存储设备中。例如,在一个或多个实施例中,计算机可执行组件可以从存储器执行,该存储器可以包括一个或多个分布式存储器单元或由一个或多个分布式存储器单元组成。如本文所用,术语“存储器”和“存储器单元”可互换。此外,本文描述的一个或多个实施例可以以分布式方式执行计算机可执行组件的代码,例如,多个处理器组合或协同工作以执行来自一个或多个分布式存储器单元的代码。如本文所使用的,术语“存储器”可以包含在一个位置处的单个存储器或存储器单元或者在一个或多个位置处的多个存储器或存储器单元。
[0125]
如本技术中所使用的,术语“组件”、“系统”、“平台”、“接口”等可以指代和/或可以包括计算机相关的实体或与具有一个或多个特定功能的操作机器相关的实体。这里公开的实体可以是硬件、硬件和软件的组合、软件、或执行中的软件。例如,组件可以是,但不限于,在处理器上运行的进程、处理器、对象、可执行文件、执行线程、程序和/或计算机。作为说明,在服务器上运行的应用程序和服务器都可以是组件。一个或多个组件可以驻留在进程和/或执行的线程内,并且组件可以位于一个计算机上和/或分布在两个或更多计算机之间。在另一示例中,相应组件可以从其上存储有各种数据结构的各种计算机可读介质执行。这些组件可以经由本地和/或远程进程进行通信,例如根据具有一个或多个数据分组的信号(例如,来自一个组件的数据,该组件经由该信号与本地系统、分布式系统中的另一组件进行交互和/或通过诸如互联网之类的网络与其它系统进行交互)。作为另一示例,组件可以是具有由电气或电子电路操作的机械部件提供的特定功能的装置,该电气或电子电路由处理器执行的软件或固件应用程序操作。在这种情况下,处理器可以在装置的内部或外部,并且可以执行软件或固件应用的至少一部分。作为又一示例,组件可以是通过电子组件而不是机械部件来提供特定功能的装置,其中电子组件可以包括处理器或其他装置以执行至
少部分地赋予电子组件的功能的软件或固件。在一方面,组件可经由虚拟机来仿真电子组件,例如在云计算系统内。
[0126]
此外,术语“或”旨在表示包含性的“或”而不是排他性的“或”。也就是说,除非另外指定,或者从上下文中清楚,否则“x采用a或b”旨在表示任何自然的包含性排列。也就是说,如果x使用a;x采用b;或者x采用a和b两者,则在任何前述实例下都满足“x采用a或b”。此外,除非另外指定或从上下文中清楚是指单数形式,否则如在本说明书和附图中使用的冠词“一”和“一个”一般应被解释为表示“一个或多个”。如本文所使用的,术语“示例”和/或“示例性的”用于表示用作示例、实例或说明。为了避免疑惑,本文公开的主题不受这些示例限制。此外,本文中描述为“示例”和/或“示例性”的任何方面或设计不一定被解释为比其它方面或设计优选或有利,也不意味着排除本领域普通技术人员已知的等效示例性结构和技术。
[0127]
如在本说明书中所采用的,术语“处理器”可以指基本上任何计算处理单元或设备,包括但不限于单核处理器;具有软件多线程执行能力的单处理器;多核处理器;具有软件多线程执行能力的多核处理器;具有硬件多线程技术的多核处理器;平行平台;以及具有分布式共享存储器的并行平台。另外,处理器可以指被设计为执行本文描述的功能的集成电路、专用集成电路(asic)、数字信号处理器(dsp)、现场可编程门阵列(fpga)、可编程逻辑控制器(plc)、复杂可编程逻辑器件(cpld)、分立门或晶体管逻辑、分立硬件组件或其任意组合。此外,处理器可以采用纳米级架构,例如但不限于基于分子和量子点的晶体管、开关和门,以便优化空间使用或增强用户设备的性能。处理器也可以实现为计算处理单元的组合。在本公开中,诸如“存储”、“数据库”以及与组件的操作和功能相关的基本上任何其他信息存储组件之类的术语被用来指代“存储器组件”、“在”存储器“中体现的实体”或包括存储器的组件。应了解,本文所描述的存储器和/或存储器组件可为易失性存储器或非易失性存储器,或可包括易失性和非易失性存储器两者。作为说明而非限制,非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除rom(eeprom)、闪存或非易失性随机存取存储器(ram)(例如,铁电ram(feram),易失性存储器可包括ram,ram可用作外部高速缓存存储器,例如作为说明而非限制,ram可以许多形式获得,诸如同步ram(sram)、动态ram(dram)、同步dram(sdram)、双倍数据率(ddr sdram)、增强型sdram(esdram)、同步链路dram(sldram)、直接rambus ram(drram)、直接rambus动态ram(drdram)和rambus动态ram(rdram)。
[0128]
以上描述的内容仅包括系统和计算机实现的方法的示例。当然,不可能为了描述本公开而描述组件或计算机实现的方法的每个可想到的组合,但是本领域的普通技术人员可以认识到,本公开的许多进一步的组合和置换是可能的。此外,就在详细描述、权利要求书、附录和附图中使用术语“包括”、“具有”、“拥有”等来说,这些术语旨在以与术语“包含”在权利要求书中用作过渡词时所解释的类似的方式为包含性的。
[0129]
已经出于说明的目的呈现了对各种实施例的描述,但是不旨在是穷举的或限于所公开的实施例。许多修改和变化对于本领域的普通技术人员将是清楚的而不背离所描述的实施例的范围。选择本文所使用的术语以最好地解释实施例的原理、实际应用或对市场上存在的技术改进,或使本领域的其他普通技术人员能够理解本文所公开的实施例。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。