技术特征:
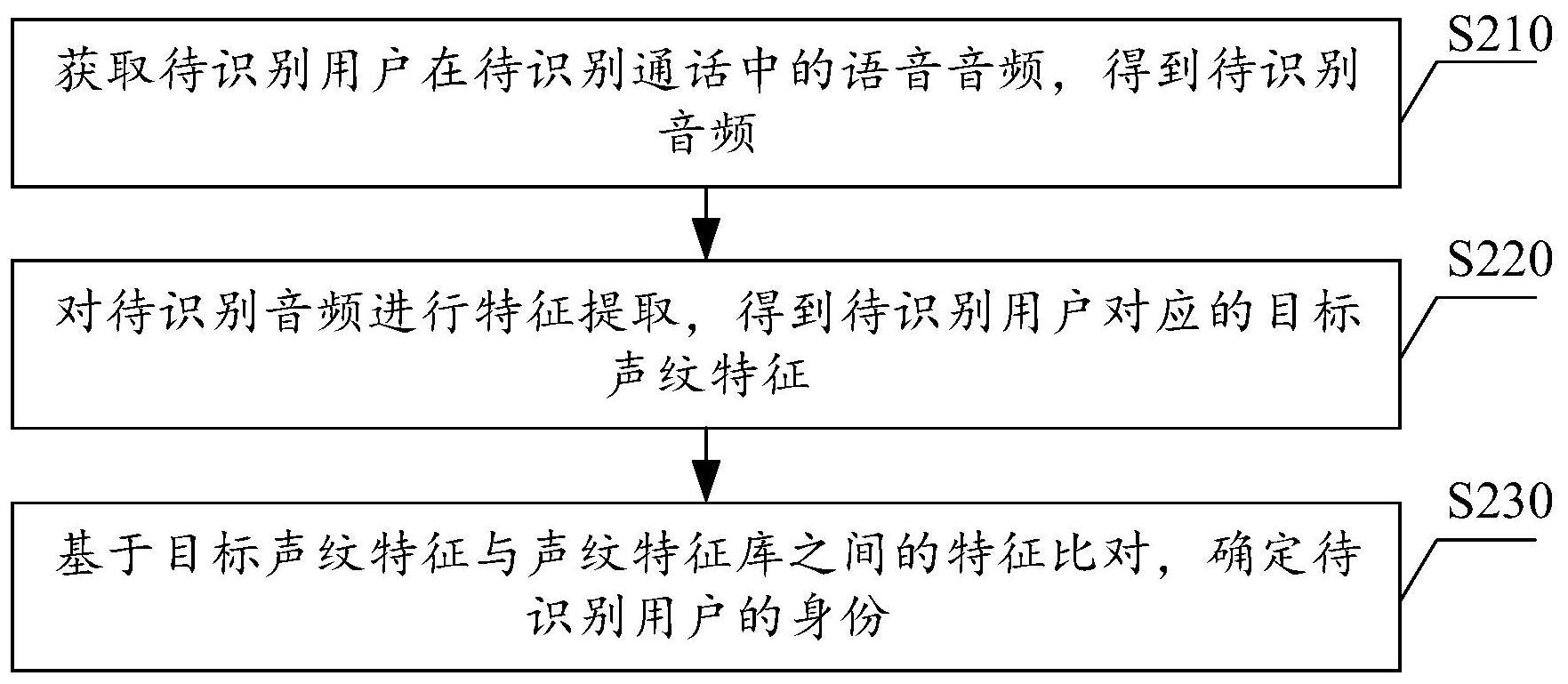
1.一种基于语音的身份识别方法,其中,所述方法包括:获取待识别用户在待识别通话中的语音音频,得到待识别音频;对所述待识别音频进行特征提取,得到所述待识别用户对应的目标声纹特征;基于所述目标声纹特征与声纹特征库之间的特征比对,确定所述待识别用户的身份。2.根据权利要求1所述的方法,其中,所述声纹特征库为第一声纹特征库,所述第一声纹特征库中存储有对应于多个用户的声纹特征,所述多个用户均属于目标身份的用户;所述基于所述目标声纹特征与声纹特征库之间的特征比对,确定所述待识别用户的身份,包括:分别计算所述目标声纹特征与所述第一声纹特征库中多个声纹特征之间的第一相似度;在所述第一相似度的最大值大于或等于第一预设值的情况下,确定所述待识别用户的身份为所述目标身份;在所述第一相似度的最大值大于或等于第二预设值且小于所述第一预设值的情况下,确定所述待识别用户的身份为潜在目标身份,其中,所述第一预设值大于所述第二预设值。3.根据权利要求2所述的方法,其中,在所述分别计算所述目标声纹特征与所述第一声纹特征库中多个声纹特征之间的第一相似度之后,所述方法还包括:在所述第一相似度的最大值大于或等于所述第一预设值的情况下,在所述声纹特征库中确定出相对应的声纹特征,所述相对应的声纹特征对应于目标用户;将所述待识别用户对应的目标声纹特征,关联至所述第一声纹特征库中的目标用户。4.根据权利要求2所述的方法,其中,所述方法还包括:将身份为所述目标身份的第i用户的声纹特征作为第i种子声纹特征,i取值为正整数;将所述第i种子声纹特征与所述第i用户的身份标识关联后存储,以构建所述第一声纹特征库。5.根据权利要求1所述的方法,其中,所述声纹特征库为第二声纹特征库,所述第二声纹特征库中存储有对应于多个用户的声纹特征,所述多个用户均属于非目标身份的用户;所述基于所述目标声纹特征与声纹特征库之间的特征比对,确定所述待识别用户的身份,包括:分别计算所述目标声纹特征与所述第二声纹特征库中多个声纹特征之间的第二相似度;在所述第二相似度的最大值大于或等于第三预设值的情况下,确定所述待识别用户的身份为所述非目标身份。6.根据权利要求5所述的方法,其中,所述方法还包括:在非目标身份的用户在进行系统用户注册时,获取所述非目标身份的第j用户的声纹特征,得到第j种子声纹特征,j取值为正整数;将所述第j种子声纹特征与所述第j用户的身份标识关联后存储,以构建所述第二声纹特征库。7.根据权利要求1至5中任意一项所述的方法,其中,在所述对所述待识别音频进行特征提取,得到所述待识别用户对应的目标声纹特征之前,所述方法还包括:根据所述待识别音频中包含的语音停顿信息以及预设的语音片段长度,对所述待识别
音频进行分片处理,得到具有时序的分片音频表;其中,所述具有时序的分片音频表用于进行特征提取。8.根据权利要求7所述的方法,其中,所述对所述待识别音频进行特征提取,得到所述待识别用户对应的目标声纹特征,包括:对所述具有时序的分片音频表中的每个分片音频进行特征提取,得到所述具有时序的分片音频表对应的音频特征序列;将所述音频特征序列输入深度特征提取模型,并将所述深度特征提取模型的输出确定为所述待识别用户对应的目标声纹特征。9.根据权利要求8所述的方法,其中,所述深度特征提取模型,包括:卷积层、编码层、池化层以及全连接层;其中,所述卷积层用于获取所述音频特征序列的深层次特征,得到深层次特征序列;所述编码层用于对所述深层次特征序列进行编码处理;所述池化层和全连接层用于:对所述编码处理之后的深层次特征序列分别进行池化处理和全连接处理,得到声纹特征序列;其中,所述声纹特征序列用于确定所述目标声纹特征。10.根据权利要求9所述的方法,其中,所述深度特征提取模型,还包括:在全连接层后的嵌入层;所述待识别音频进行特征提取,得到所述待识别用户对应的目标声纹特征,包括:通过所述嵌入层对所述得到声纹特征序列进行压缩处理,得到一条关于所述待识别用户的声纹特征,得到所述目标声纹特征。11.根据权利要求9所述的方法,其中,所述待识别音频进行特征提取,得到所述待识别用户对应的目标声纹特征,包括:将所述声纹特征序列确定为所述目标声纹特征。12.一种基于语音的身份识别装置,其中,所述装置包括:音频获取模块,用于获取待识别用户在待识别通话中的语音音频,得到待识别音频;特征提取模块,用于对所述待识别音频进行特征提取,得到所述待识别用户对应的目标声纹特征;身份识别模块,用于基于所述目标声纹特征与声纹特征库之间的特征比对,确定所述待识别用户的身份。13.一种电子设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其中,所述处理器执行所述计算机程序时实现如权利要求1至11中任一项所述的基于语音的身份识别方法。14.一种计算机可读存储介质,其中,所述计算机可读存储介质中存储有指令,当所述指令在计算机或处理器上运行时,使得所述计算机或处理器执行如权利要求1至11中任一项所述的基于语音的身份识别方法。15.一种包含指令的计算机程序产品,其中,当所述计算机程序产品在计算机或处理器上运行时,使得所述计算机或处理器执行如权利要求1至11中任一项所述的基于语音的身份识别方法。
技术总结
本说明书实施例提供一种基于语音的身份识别方法、基于语音的身份识别装置以及电子设备,该方法包括:对于某次语音通话(待识别通话),获取需要进行身份识别的一方(待识别用户在)的语音音频,并将其确定为待识别音频。然后,对上述待识别音频进行特征提取,以得到上述待识别用户对应的声纹特征(目标声纹特征)。进一步地,基于上述目标声纹特征与声纹特征库之间的特征比对,来确定上述待识别用户的身份。份。份。
技术研发人员:吴凯凯 熊永福 刘勇 李凤
受保护的技术使用者:重庆蚂蚁消费金融有限公司
技术研发日:2022.08.30
技术公布日:2023/7/26
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。