1.本发明属于计算机视觉领域,尤其涉及一种结合可学习注意力机制的人群计数方法。
背景技术:
2.人群计数在拥挤估计、视频监控和人群管理中起着至关重要的作用。实时人群检测和计数越来越受到关注。所以密集人群计数已经成为计算机视觉领域的一个研究热点。这项研究在现实世界有着广泛的应用,如安防监控、交通控制和智能交通。然而,由于监控场景受到尺度变化、背景噪声、遮挡等因素的影响,精确有效地预测人群数量仍然是一个严峻的挑战。在人群计数与密度估计问题上,基于cnn的人群计数技术的研究取得了显著的性能。许多研究者致力于通过各种先进的深度学习方法来提高预测精度,如注意机制模块、多尺度模块、特征提取、特征融合。从而显著提升网络模型的性能。但是由于视角、密度和规模变化较大,人群计数仍然是一项具有挑战性的任务。
3.近年来,典型的计数方法利用卷积神经网络(cnn)作为主干,并回归密度图来预测总人群计数。然而,由于摄像机的视角很宽。在2d透视投影中,人群图像中经常存在大规模变化。具有固定大小卷积核的传统神经网络难以处理这些变化,并且计数性能受到严重限制。为了缓解这一问题,采用了多尺度机制,如多尺度块、金字塔网络和多列网络。这些方法引入了直观的局部结构感应偏置,表明相应的场应适应对象的大小。
技术实现要素:
4.发明目的:本发明的目的在于提供一种结合可学习注意力机制的人群计数方法来解决人群计数网络模型在尺度变化和人头位置偏差的问题。
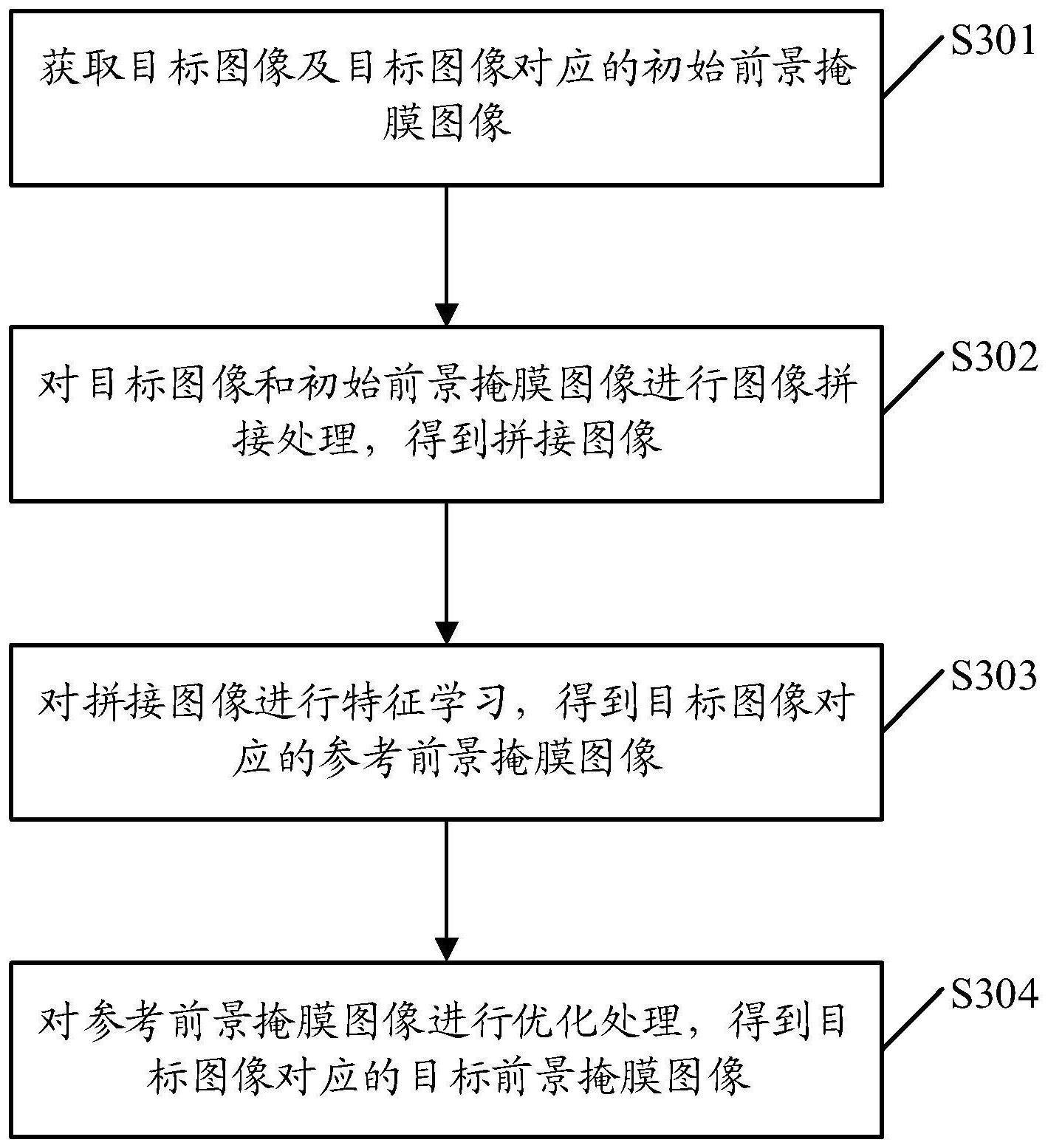
5.技术方案:本发明的结合可学习注意力机制的人群计数方法,采集目标区域的图像以及真实点阵图,通过执行以下步骤,训练获得可学习注意力机制网络模型,并基于该模型获得目标区域的预测密度分布图,进而获得目标区域的最终人群计数图;
6.步骤1:获取目标区域的图像以及目标区域的真实点阵图;
7.步骤2:对目标区域的图像进行预处理后构建数据集,将数据集按比例划分为训练集和测试集;
8.步骤3:将目标区域的真实点阵图经过高斯核的卷积后,输入自注意力模块,生成目标区域的真实密度分布图;
9.步骤4:初始化可学习注意力机制网络模型参数,将训练集中的图像作为输入,目标区域的预测密度分布图作为输出,通过比较目标区域的预测密度分布图与真实密度分布图之间的误差,训练可学习注意力机制网络模型,并通过测试集测试模型精度,获得训练完成的可学习注意力机制网络模型;
10.步骤5:基于可学习注意力机制网络模型获得目标区域的预测密度分布图,使用损失函数联合训练预测密度分布图和真实密度分布图,得到最终人群计数图。
11.进一步的,步骤2中,所述对目标区域的图像进行预处理为统一图像大小,采用填充边缘处理将其转化为统一大小的格式,对数据依次进行裁剪、水平翻转和亮度调节。
12.进一步的,步骤4中,所述可学习注意力机制网络模型采用vgg-19作为卷积神经网络骨干网络,该网络在imagenet上进行预训练,采用lra替换关注模块,回归解码器由一个上采样层和三个具有激活relu功能的卷积层组成,前两层的核尺寸为3
×
3,后一层的核大小为1
×
1,其中比较重要的超参数如训练学习率lr设置为5e-7,权重衰减weight_decay设置为1e-4。
13.进一步的,步骤4中,所述训练可学习注意力机制网络模型具体包括如下步骤:
14.步骤41:提取目标区域图像的局部特征;
15.步骤42:基于可学习注意力模块确定每个特征位置所关注的局部区域;
16.步骤43:采用密度图细化框架对密度图细化进行训练和细化,输出特征与可学习区域注意传输到变压器编码器;
17.步骤44:经过解码器解码后,得到目标区域的预测密度图。
18.进一步的,步骤41中,提取特征f∈rc
×w×
h,其中c、w和h分别是通道、宽度和高度,然后将特征图展平。
19.进一步的,步骤42中,可学习注意力模块具体结构如下:
20.首先确定位置p=(x
p
,y
p
),其中0≤x
p
《w,0≤y
p
《h。标注点位置预测如下:
[0021][0022][0023]
给定两个预测顶点左下(bl)和右上(ur):对于特定特征,b=(xb,yb),u=(xu,yu),其过滤区域通过以下公式计算:
[0024][0025]
两个滤波区域的乘积表示为:
[0026][0027]
当采用全球注意力时,r表示为全1矩阵。
[0028]
进一步的,步骤43中,所述密度图细化框架联合细化密度图并从细化密度图训练计数器,让(xi,yi)作为第i张图像和传统密度图对,将f(xi)表示为图像xi的预测密度图,g(yi)作为yi的细化密度图,对使用密度图细化进行训练,然后使用lra将其传输到变压器编码器,以学习不同尺度的特征f
′
。然后,利用回归解码器从f
′
预测最终密度图d∈rw
′×h′
。
[0029]
进一步的,所述编码器层数t设置为4。
[0030]
进一步的,步骤5中,所述损失函数l如下
[0031][0032]
其中,是计数器预测密度图,mi是的真实密度图,和mi′
是向量化版本的和mi,是两个向量之间的余弦相似性;
[0033][0034]
其中ε=10-8.使用余弦相似性对密度图进行空间正则化,标准化向量和m
′i/||m
′i||2表示人群的空间分布,与计数无关,上述公式中的余弦相似性鼓励了gt和预测密度图之间人群和非人群的相似空间分布。
[0035]
有益效果:与现有技术相比,本发明具有如下显著优点:
[0036]
本算法使每个特征学习关注应该注意的范围,在局部注意力模块以捕获多尺度上下文信息,提高了计数准确性;缓解在人群计数图像中由尺度变化引起的计数不准确问题:并且生成了高质量的密度估计图。通过人群密度预测图和人群真实密度图相结合的方法,采用自适应密度图生成框架,解决人与人之间的遮挡,复杂的背景等会导致人群计数性能下降的问题。该算法降低人群杂乱分布对密度图质量影响的同时,进一步提升算法的计数性能与泛化能力。
附图说明
[0037]
图1为本发明的总体流程图;
[0038]
图2为本发明的网络结构图;
[0039]
图3为可学习注意力模块中特征学习注意范围的确定;
[0040]
图4可学习注意力模块;
[0041]
图5为本发明方法的真实密度图和预测密度图的结果对比。
具体实施方式
[0042]
下面结合附图对本发明的技术方案作进一步说明。
[0043]
本发明的一种结合可学习注意力机制的人群计数方法,如图1所示,主要包括以下步骤:
[0044]
(1)图像预处理:由于要进行训练与测试部分数据集需要统一图片大小,所以采用填充边缘处理将其转化为统一大小的格式,进行下一步工作,然后对数据进行裁剪,水平翻转,亮度调节等处理。然后用python相应的程序将标注文件即.mat文件和对应的图片信息处理成.h5py格式。
[0045]
(2)图像的局部特征提取:在vgg19的基础上,针对每个特征学习应该注意的区域,采用了可学习注意力机制,主要是应对在同一张图片中由于远近关系人头大小可能差异很大的尺度差异问题。
[0046]
(3)自适应密度图生成:如图2所示,主要是从点注释图生成密度图。使用此密度图生成框架,可以在没有任何中间密度图的情况下对整个系统进行端到端训练。该方法自适应地将从不同内核构建的密度图融合在一起,然后对其进行细化以生成新的密度图。
[0047]
(4)可学习区域注意力:如图3所示,可学习注意力机制可以灵活地确定每个特征位置应该关注的局部区域。局部关注模块提供了针对尺度变化提取最相关局部信息的有效方式。通过该机制,每个特征都可以学习到最适合的局部区域。由于矩形区域可以由两个顶点识别,因此我们从区域过滤机制开始,以获得每个位置的专属区域。可学习注意力模块具
体结构如下:
[0048]
首先确定位置p=(x
p
,y
p
),其中0≤x
p
《w,0≤y
p
《h。标注点位置预测如下:
[0049][0050][0051]
给定两个预测顶点左下(bl)和右上(ur):对于特定特征,b=(xb,yb),u=(xu,yu),其过滤区域通过以下公式计算:
[0052][0053]
两个滤波区域的乘积表示为:
[0054][0055]
当采用全球注意力时,r表示为全1矩阵。
[0056]
本发明使用vgg-19作为主干,提取特征f∈rc
×w×
h,其中c、w和h分别是通道、宽度和高度。然后将特征图展平,并用所提出的lra将其传输到变压器编码器,以学习不同尺度的特征f
′
。然后,利用回归解码器从f
′
预测最终密度图d∈rw
′×h′
。
[0057]
实施例
[0058]
本发明所提方法采用vgg-19作为卷积神经网络骨干网络,该网络在imagenet上进行了预训练。采用lra替换关注模块。回归解码器由一个上采样层和三个具有激活relu功能的卷积层组成。前两层的核尺寸为3
×
3,后一层的核大小为1
×
1。其中比较重要的超参数如训练学习率lr设置为5e-7,权重衰减weight_decay设置为1e-4;
[0059]
验证本发明所提方法预测性能时选取shanghaitech a、shanghaitech b、ucf-qnrf公开数据集。覆盖了常见的稀疏、密集、街道、广场等各类人群聚集场。
[0060]
在训练阶段,首先对每个训练图像采用随机缩放和水平翻转,然后我们随机裁剪大小为512
×
512的图像块。由于shanghaitech a中的一些图像包含较小的分辨率,因此该数据集的裁剪大小变为256
×
256。我们还将所有数据集中每个图像的短边限制在2048像素以内。使用学习率为10-5的adam算法来优化参数。我们将编码器层数t设置为4,损耗平衡参数λ设置为100。
[0061]
利用平均绝对误差(mae)和均方根误差(rmse)来评价本发明所提方法的预测精度和鲁棒性。
[0062]
本发明方法对比的常用轻量级网络为:
[0063]
方法1:yingying zhang,desen zhou,siqin chen,shenghua gao等人提出了一种简单但有效的多列卷积神经网络(mcnn)架构,融合三列不同尺度的特征去生成密度图,可适用于任意的拍摄角度以及任意的场景密集程度,能够从任意人群密度和任意视角的单个图像中准确估计人群数量。但对实际场景中背景遮挡严重问题难以解决。
[0064]
方法2:vishwanath a.sindagi and vishal m.patel等人提出了一种主要解决人群密度估计中人群场景变化大、人在场景中的尺度和外观变化范围大问题的网络架构。该网络主要通过将一个高级先验与网络合并,学习出一个满足数据集中各种密度等级的模型。高级先验先根据图中人的数量分为不同的带标签的组。利用标签,这个高级先验能大致
估计整个图片中的人数,而不受尺度变化的影响,从而使网络能学到更多的判别全局特征。利用高级先验和cnn网络共同进行密度图的估计。
[0065]
方法3:deepak babu sam,shiv surya,等人提出switch-cnn(cvpr 2017),该网络通过switch layer将不同的图块送入到相应的卷积神经网络回归器中,使得每一个卷积神经网络回归器只针对特定规模的人群进行处理。该模型存在与mcnn同样的问题,即到底应该选择几个子网络。但该方法通过网络学习来确定patch输入的路径,给patch做分类还是比较新颖的。
[0066]
从表1可以看出,相对于其他轻网络,本发明提出的方法在大部分数据集上得到了更低的mae和mse,表明本发明方法更能适应场景中的尺度变化。
[0067]
表1
[0068]
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。