:
1.本发明涉及人工智能领域,直接应用于污水处理领域。
背景技术:
2.氨氮是指在水中以游离氨和铵离子形式存在的氮,是水体中最为常见的污染物之一。其主要来源与生活污水中含氮有机物分解的产物以及焦化、合成氨等工业废水。在污水处理过程中,出水氨氮浓度是衡量出水水质优劣的一个重要参数指标。当水体在氨氮浓度过高时,会对水生生物以及周围的生态环境产生严重的危害。因此,实现对水体氨氮浓度进行及时有效测量显得尤为重要。
3.目前,国内外污水处理厂对氨氮浓度的测定方法有很,包括仪器分析法,电化学分析法,以及分光光度计等。采用这些方法的优点是测量精度高,但由于检测过程繁琐、检测时间长、成本高等,无法完成对出水氨氮浓度的实时监测。虽然部分在线监测仪器可以实现水体中氨氮浓度的实时测量,但需要采用化学试剂辅助检测,且容易受到干扰,通用性差。因此,如何高精度、高效率、低成本的对出水氨氮浓度进行实时预测,仍是目前研究的一个关键问题。
4.近年来,随着软测量技术的快速发展,数据驱动的软测量技术以其成本低、易操作等优势成为实现对水体氨氮实时监测的一个重要途径。然而,值得注意的是,在实际工业生产过程中采集到的出水氨氮浓度往往以数据流的形式存在,这些数据具有高维非线性、动态时序性、未知性、海量性等特点。传统的神经网络模型大多都基于静态数据或数据流稳定的假设下设计的,未考虑数据流中样本统计特性的不稳定性,导致无法有效学习动态非平稳数据的变化特性。因此,如何分析和利用数据流中蕴含的有效信息是数据驱动建模的难点。为此,本发明提出了一种具有自主学习特性的在线自学习随机配置网络结构动态优化算法来根据实时到达的数据流调整网络自身的参数及结构。该算法基于误差反馈策略通过基于实时样本对构建好的模型进行在线参数调整和网络结构修正,以使网络具有良好的持续学习能力,更好的处理非平稳动态数据建模问题,进而提高污水处理过程出水氨氮浓度的实时预测性能。
技术实现要素:
5.本发明提出了一种具有自主学习特性的在线自学习随机配置网络出水氨氮浓度预测方法。通过自身的在线参数学习机制与网络结构修正机制使得构建的模型具有良好的持续学习能力。该方法解决了污水处理过程中出水氨氮浓度测量的问题,实现了对出水氨氮浓度的实时有效预测,进一步提高了出水氨氮浓度的预测性能。
6.由于污水处理过程的高复杂性,不稳定性等特点,获取到的水质数据的分布特性往往随时间的推移不断发生变化。它导致基于历史数据训练的模型无法对实时获取的数据进行有效学习。为了从实时变化的动态数据流中获取到有价值的信息和模式,本发明提出了一种具有自学习特性的在线自学习随机配置网络。值得注意的是,网络的自学习特性不
仅意味着网络参数的在线更新,还意味着网络拓扑结构的动态改变。具体来说,该方法能够根据实时数据输出的误差大小选择在线参数更新机制或者网络结构修正机制来对网络模型进行在线调整,使scns具有良好的持续学习能力以适应实际系统需求。具体内容如下。
7.在线参数更新机制
8.给定一个初始训练集基于初始训练集构建随机配置网络,假设构建的scns具有l个隐节点,网络隐含层神经元激活函数g(
·
)采用sigmoid激活函数,此时第j个隐节点的输出为
[0009][0010]
其中,
[0011][0012]
此时网络的输出权值可由(2)计算得出
[0013][0014]
其矩阵描述如下:
[0015][0016]
其中,分别为隐含层的输出矩阵与目标期望值矩阵, 为初始输出权值矩阵。此时t=1即,第一组新样本到达时,网络输出权值为:
[0017][0018]
其矩阵描述如下:
[0019][0020]
其中,
[0021][0022][0023]
则此时,网络的输出权值为:
[0024][0025]
以此类推,当t=k,即组第k组样本到达时,网络输出权值的调整公式如下:
[0026][0027]
其中,
[0028]
[0029]
令,pk=g
k-1
则,第k个样本到达时,网络权值调整如下。
[0030][0031]
值得注意的是,当新样本到达时,若网络输出误差较小,则我们可以假设scns监督机制选取的节点仍然有效。因此,这里根据(11-12)对网络参数进行在线修正。
[0032]
网络结构修正机制
[0033]
在实际工业应用中获取到的数据流往往分布差异较大,简单的在线参数调整无法有效提升网络的学习能力以适应数据的变化。因此,为了对实时到达的数据流进行有效的分析处理,更好的提高模型的在线学习和自主调节能力,我们提出了一种采用融合灵敏度分析与随机配置算法的scn结构动态调整策略。这部分主要分为两个阶段对网络结构进行调整,分别为剪枝阶段与网络构建阶段。
[0034]
1:剪枝阶段
[0035]
首先,假设基于历史样本已构建了具有l个隐含层节点的scns,因此当新时间窗口t 的样本到达时网络的输出为:
[0036][0037]
假设删除第l个神经元节点,则网络输出为:
[0038][0039]
网络输出残差
[0040][0041]
因此,定义第i个隐含层节点相对于输出残差变化的灵敏度为:
[0042][0043]
s越大,表明第i个神经元对网络输出的贡献度越大。因此,通过灵敏度分析可以对隐含层神经元节点的贡献度进行排序s
′1≥s
′2≥
…
≥s
′
l
。由于隐含层神经元节点删除越多,模型输出残差变化越大,因此网络规模适应度定义为:
[0044][0045]ji
越大,网络结构规模越大,学习残差越小。因此,与学习样本相匹配的网络规模可通过网络结构适应度定义为:
[0046]
j=min{iji≥γ,1≤i≤l}
ꢀꢀ
(18)
[0047]
其中,γ(0《γ《1)为网络规模适应度阈值,j为网络保留隐含层节点数量。
[0048]
2:网络构建阶段
[0049]
为避免因隐含层节点删除造成样本信息的丢失,需对保留的网络结构进行进一步的优化调整以更好的学习新的样本。这里,采用随机配置算法iii,基于新到达的样本在删
减后的网络基础上重新进行节点构建。
[0050]
假定删减m个节点后网络的输出为:
[0051][0052]
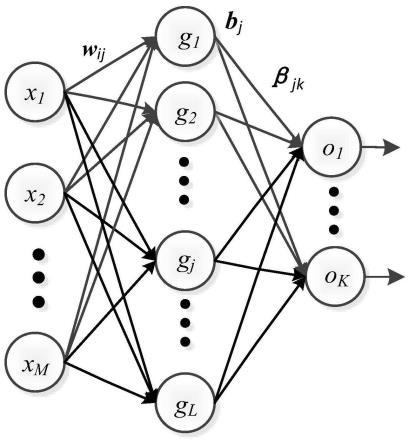
当前网络的残差为:
[0053]el-m
=f-f
′
l-m
=[e
l,1
,e
l,2
,...,e
l-m,k
].
ꢀꢀ
(20)
[0054]
若当前网络的输出残差||e
l-m
||没能满足预设误差容忍要求,则该网络会根据不等式约束条件来选出新的隐含层神经元节点,得到第l-m 1个隐含层节点参数g
l-m 1
(w
l-m 1
和 b
l-m 1
)。其中,网络选取隐含层节点参数的不等式约束条件为:
[0055][0056]
式中:h
l-m 1
=g
l-m 1
(<w
l-m 1
,x> b
l-m 1
)表示第l-m 1个隐含节点的输出,0<r<1 其可在参数选取的过程中适时变化,μ
l-m 1
≤(1-r)为非负实数序列且此时网络隐含层节点的最优输出权值可由下式计算。
[0057][0058]
第l-m 1个隐含层节点建立后,网络的输出为:
[0059][0060]
然后,判断网络的输出误差||e
l-m 1
||是否满足预设误差要求(||e
l-m 1
||≤e
p
),若满足则 scns构建完成;否则继续按照不等式约束条件(21)增加新的隐含层节点来构建网络,减少网络的输出误差,直至满足终止条件(当前网络的输出误差||e||≤e
p
或l≥l
max
)。
[0061]
本发明与传统神经网络预测方法,具有如下特点:
[0062]
本发明针对污水处理过程高度复杂的特点,致使采集到的数据存在高度非线性,动态时序性,以及非平稳等特点。为有效解出水氨氮浓度预测性低的问题,提出了一种具有自主学习特性的在线随机配置网络结构动态优化算法来根据实时到达的数据流调整网络自身的参数及结构,进而提高了出水氨氮的实时预测性能。因此,所提方法具有以下优点:
[0063]
1)能够根据污水处理厂获取的数据流的特点实时在线动态调整网络的结构和参数;
[0064]
2)自然继承了scns所具备的通用逼近能力;
[0065]
3)通过对网络参数、结构的自学习,使得该网络具有持续学习的能力,更好的适应在线数据流预测。
附图说明
[0066]
图1为随机配置网络基本结构图;
[0067]
图2为本发明模型算法框架示意图
[0068]
图3为本实例出水氨氮测试结果图;
[0069]
图4为本实例出水氨氮测试误差图
具体实施方式:
[0070]
实验数据来自北京市某污水处理厂水质分析数据,获得498组数据。通过对污水处理过程中出水氨氮浓度进行机理分析,选取
①
温度、
②
ph值、
③
好氧前端溶解氧浓度do、
④
进水总磷浓度tp、
⑤
厌氧末端氧化还原电位orp
⑥
出水硝态氮浓度no3-n共6个变量作为出水氨氮浓度nh
3-n的输入变量,选取出水nh
3-n浓度作为输出变量。这里按照序列的方式选取前75%的样本作为训练集,其余25%的样本作为测试集。主要步骤如下:
[0071]
步骤1:数据预处理
[0072]
选取输入变量,记为x={x
ip
|p=1,2,
…
,p,i=1,2,
…
,n},p为输入特征维数,这里p= 6;n为样本个数。x
ip
表示为第i个数据的第p个特征。选取出水nh
4-n浓度作为输出变量,记为y={yi|i=1,2,
…
,n},yi表示第i个输出样本。由于采集到的不同水质参数具有不同的量纲,且采集到的不同参数的数据值差别很大,为了消除数据值大小和不同量纲对模型性能的影响,这里对采集到的数据进行归一化操作。将输入变量x和输出变量y按照如下公式进行归一化处理:
[0073][0074][0075]
x和y表示经过归一化处理后的数据,取值范围为[0,1]。
[0076]
步骤2:设计基于在线自学习随机配置网络的出水氨氮浓度实时预测模型;
[0077]
步骤2.1:基于系统采集的数据,设置一个固定大小的初始时间窗t0,基于窗口内的数据建立随机配置网络模型。
[0078]
随机配置网络scn是一个三层前向神经网络,主要包括输入层、隐含层、输出层。输入层将样本导入网络,包含6个神经元。网络初始时隐含层包含1个神经元,用l表示网络隐层的神经元个数,初始时l=1。值得注意的是:与传统的单隐含层前馈神经网络不同, scn可在人为很少干预的情况下,从一个小型网络开始,随机的选取输入权值和阈值,逐渐增加隐含层神经元节点的数量直到网络的输出精度满足终止条件。此外,scn的突出贡献是针对随机参数增加了不等式约束条件,并根据随机参数的选取自适应的选择随机参数的取值范围,进一步确保了随机化学习模型的通用逼近性。这里,隐含层神经元激活函数采用sigmoid激活函数,即,
[0079][0080]
此时第j个隐节点的输出:
[0081][0082]
其中,《
·
》表示欧式空间的内积运算。wj和bj是第j个隐含层神经元的输入权值和偏置,其在[-λ,λ]中随机生成并受随机配置算法的不等式约束(8)的限制,为正实
数。βj是第j个隐藏节点的输出权重向量,当前网络的输出为:
[0083][0084]
当前网络的残差为:
[0085]el
=f-f
l
=[e
l,1
,e
l,2
,...,e
l,k
]
ꢀꢀ
(29)
[0086]
若当前网络的输出残差||e
l
||,这里||
·
||指l2范数,即没能满足网络预设的误差容忍要求,即||e
l
||≤e
p
,e
p
为预设容忍误差阈值且设定e
p
=0.001,则该网络会根据随机配置算法来选出新的隐含层节点用于网络构建,此时l=l 1,直至满足终止条件||e
l
||≤e
p
或 l≥l
max
,l
max
=150为预设最大隐节点数。其中,随机配置算法可简单描述如下:
[0087]
假设γ:={h1,h2,h3,
…
}表示一组实值函数,span(γ)表示由γ组成的函数空间且在l2空间是稠密的。0≤||h||≤bh,其中为正实数。给定0<r<1以及一个非负实值序列{μ
l
},且μ
l
≤(1-r),.对于l=1,2,...,定义
[0088][0089]
且生成的隐节点满足条件
[0090][0091]
隐含层和输出层之间的输出权重通过以下方式计算
[0092][0093]
则,可以得到其中
[0094]
假设t=0的初始训练集为n0为初始样本个数,m,k分别为网络的输入输出维数,基于初始训练集构造了一个具有l个隐藏节点的随机配置网络。网络的最优初始输出权值可通过公式(32)计算得出,其矩阵描述如下:
[0095][0096]
其中,分别为隐含层的输出矩阵与目标期望值矩阵, β(0)=[β1(0),β2(0),...,β
l
(0)]
t
,为初始输出权值矩阵。
[0097]
步骤2.2:基于构建的网络对新时间窗内获取的数据进行测试,计算网络的输出误差。
[0098]
假设基于历史样本已构建了具有l个隐含层节点的scns,新时间窗t时的数据为 xt={x
tp
|p=1,2,
…
,p,t=1,2,
…
,n
t
},yt={y
t
|t=1,2,
…
,n
t
},n
t
为t时刻窗口内的新样
本数。因此当新样本到达时网络的输出为:
[0099][0100]
通过公式(29)计算当前网络的输出误差e(t),e(t)为t时刻网络的输出误差;
[0101]
步骤2.3:当误差值||e(t)||处于预设误差区间[e
min
,e
max
]时,利用在线学习机制对scn参数进行在线更新,这里设置e
min
=3
×
e(t-1),e
max
=5
×
e(t-1),e(t-1)为t-1时刻网络的输出误差;
[0102]
当第t=k,即第k组样本到达时,网络输出权值的调整公式如下:
[0103][0104]
其中,
[0105][0106]
令,pk=g
k-1
则,第k个样本到达时,则网络权值调整如下。
[0107][0108]
其中,hk=[h1,h2...,h
nt
]
t
为第k时刻网络隐含层的输出矩阵,yk为第k时刻窗口内样本的期望输出值。
[0109]
步骤2.4:当误差值||e(t)||大于预设误差区间上界,e
max
时,基于灵敏度分析与随机配置算法对网络结构进行动态修正。
[0110]
基于新时间窗t内样本,通过公式(34)计算当前网络的输出。然后删除第l个神经元节点,则网络输出为:
[0111][0112]
网络输出残差的变化为:
[0113][0114]
因此,第l个隐含层节点相对于输出残差变化的灵敏度s
l
为:
[0115][0116]
通过灵敏度分析可以对隐含层神经元节点的贡献度进行排序s1′
≥s2′
≥
…
≥s
l
′
,其中sj′
为重要性排在第j位的隐含层节点的灵敏度。计算网络规模适应度ji[0117][0118]
得到满足条件的节点个数j
[0119]
j=min{i|ji≥γ,1≤i≤l}
ꢀꢀ
(42)
[0120]
基于(41),(42)选择灵敏度较高的前j个节点进行保留,γ为人为设置的网络规模适应度阈值,这里取0.8。为避免因隐含层节点删除造成样本信息的丢失,需对保留的网络结构进行进一步的优化调整以更好的学习新的样本。这里,采用随机配置算法,基于新到达
的样本在删减后的网络基础上重新进行节点构建。
[0121]
假定删减m个节点后网络的输出为:
[0122][0123]
当前网络的残差为:
[0124]el-m
=f-f
′
l-m
=[e
l,1
,e
l,2
,...,e
l-m,k
].
ꢀꢀ
(44)
[0125]
若当前网络的输出残差||e
l-m
||没能满足预设误差容忍要求(||e
l-m
||≤e
p
),则该网络会根据不等式约束条件来选出新的隐含层神经元节点,得到第l-m 1个隐含层节点参数 g
l-m 1
(w
l-m 1
和b
l-m 1
)。其中,网络选取隐含层节点参数的不等式约束条件为:
[0126][0127]
式中:h
l-m 1
=g
l-m 1
(<w
l-m 1
,x> b
l-m 1
)表示第l-m 1个隐含节点的输出,0<r<1 其可在参数选取的过程中适时变化,μ
l-m 1
≤(1-r)为非负实数序列且则此时网络隐含层节点的最优输出权值为:
[0128][0129]
第l-m 1个隐含层节点建立后,网络的输出为:
[0130][0131]
然后,判断网络的输出误差||e
l-m 1
||是否满足预设误差要求(||e
l-m 1
||≤e
p
),若满足则 scns构建完成;否则继续按照不等式约束条件(45)增加新的隐含层节点来构建网络,减少网络的输出误差,直至满足终止条件(当前网络的输出误差||e||≤e
p
或l≥l
max
)。步骤2.5:当新样本到达时t=t 1,返回步骤2.2,直至训练结束,即窗口t内的样本数为0。步骤2.6:将测试样本输入到构建好的网络中,通过与训练集相同的方式选取窗口t内的样本进行预测,返回步骤2.2基于构建好的网络计算网络的输出值并记录。最后,反归一化后得到出水氨氮浓度的预测值,然后基于新获取到的样本,通过步骤2.3-2.5对网络进行实时修正。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。