1.本发明涉及数据识别领域,特别涉及一种基于工业互联网的数据识别方法。
背景技术:
2.工业互联网是新一代信息通信技术与工业经济深度融合的新型基础设施、应用模式和工业生态,通过对人、机、物、系统等的全面连接,构建起覆盖全产业链、全价值链的全新制造和服务体系,为工业乃至产业数字化、网络化、智能化发展提供了实现途径,是第四次工业革命的重要基石,工业互联网不是互联网在工业的简单应用,而是具有更为丰富的内涵和外延,它以网络为基础、平台为中枢、数据为要素、安全为保障,既是工业数字化、网络化、智能化转型的基础设施,也是互联网、大数据、人工智能与实体经济深度融合的应用模式,同时也是一种新业态、新产业,将重塑企业形态、供应链和产业链,现有的在对工业互联网的数据进行识别时,识别效率较低,不能通过关键词对敏感数据进行判断,容易出现错误效果的同时会导致数据的分析结果偏差较大。
技术实现要素:
3.本发明的主要目的在于提供一种基于工业互联网的数据识别方法,可以有效解决背景技术中的问题。
4.为实现上述目的,本发明采取的技术方案为:
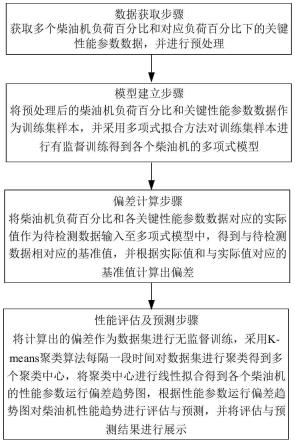
5.一种基于工业互联网的数据识别方法,包括以下操作步骤:
6.s1:基于工业互联网的数据进行数据集的建立:建立数据文本并将其制成模型供观察,此时可对其数据特征进行选择,在数据集中的训练集进行数据的学习,建立分类器,在对其进行后续的测试和性能的评价;
7.s2:将敏感数据库进行预处理:对敏感数据库进行关键特征的设定和提取,通过tfidf算法对其进行向量空间全值的计算,以此形状数据特征的向量;
8.s3:阙值的确定:已知分类的数据库库进行预处理和特征提取之后,通过tfidf算法计算向量空间权值形成数据特征向量,与将敏感数据形成的特征向量进行余弦计算,并统计学习,根据阙值确定方法确定阙值;
9.s4:敏感数据的判断:将待判断的未知分类的数据进行预处理和特征提取,通过tfidf算法计算向量空间权值形成数据特征向量后,与敏感数据的特征向量进行余弦计算,将得到的余弦值与阙值进行比较,判断是否是敏感数据。
10.优选的,所述数据集包括训练集和测试集,所述训练集包括敏感数据库和已知工业数据库,训练集中的敏感数据库可以用于作为机器学习的分类器,已知工业数据库由两个小数据库组成,一个为敏感数据,一个为非敏感数据。
11.优选的,所述数据的预处理的识别过程中,需要先将数据中的单个数据代码进行标注,以便后续特征的提取,将数据代码进行分类,包括单极性码,极性码,双极性码,归零码,不归零码,双相码,曼彻斯特编码,差分曼彻斯特编码,多电平编码。
12.优选的,所述特征提取可通过工业设备的数据接口得到数据分类的数据,此时可以对进行数据的旋转,选择后在对其频率进行统计,并对其数据代码的长度进行分析,以此对其进行选择,即可得到数据的关键特征。
13.优选的,所述数据文本长度的选择时,需要计算每个关键数据文本的长度并删除单个数据文本的关键数据,以此使得只出现一次的文本判断为具有偶然性,使得其不具备代表性,因此剔除统计后的数据本体识别时能更加精准。
14.优选的,所述敏感特征向量的计算时采用tfidf公式,使得某个数据文本出现在数据集的次数越少,那么这个数据文本就包含越多的信息,越能代表数据的类型,相反若在其他数据集中大量出现,那么这个数据文本则不具备代表性。
15.优选的,所述通过余弦公式计算两个特征向量的相似度,以此判断特征向量的分类。
16.优选的,所述余弦相似度计算后,通过对计算结果和阙值进行对比,以此判断数据文本是否为敏感数据,先收集工业设备的数据安全文件和敏感文件的数据文本库,通过处理与敏感集进行余弦计算以此得到值,通过确定相通间隔的阙值,进行是否敏感数据的判断,找到错误率低的阙值作为后面进行未知数据判断的阙值。
17.优选的,所述其中可将数据分为非结构化数据、运营数据、元数据、组织数据、常量数据、主数据,经过特征的分析和计算后,能对所需的数据和录入的数据进行识别和判断,以此根据分类的数据对其进行选择和提取,同时可根据本数据与其它数据交互的行为,配合阙值对其进行其是否为主数据,其次运营数据可视为动词关系,主数据可视为名词关系,以此在进行特征提取后,更加方便后续对数据进行识别。
18.与现有技术相比,本发明具有如下有益效果:
19.本发明中,在基于工业互联网的数据库中,如果将所有数据的文本都作为关键词的话,将导致计算量很大,也引入了过多的冗余信息,导致后期的分析存在很大的偏差,因此将预处理之后的分词结果进行提取,降低向量空间的维度,使其更加具有代表性,对数据识别的计算也更加简便有效,通过采用tfidf公式,其是对对数值权值的计算是衡量特征值的有效方法,其可将数据认为某个词在其它文本中出现的次数越是少,那么这个词就包含越多的信息,越能够代表文档的类型,相反,如果在其它文档中也是大量的出现,那么这个词就不具有代表性,以此可以快速对数据的特征进行观察判断,通过对数据进行预处理,在特征选择过程中,数据选择后复合关键词的比例大大提高,同时大大的减少了冗余的数据,简便了后面的计算,通过与余弦的计算,可知敏感数据和非敏感数据的余弦是可分的,以此可以很好的确定阙值,以此对数据文档进行很好的判断,在将计算出的阙值用于敏感数据的判断时,可将错误率降低至忽略不计,同时可以根据特征词即可将数据进行识别找寻,此方法实用性较高、同时准确性和灵活性较好,可用于数据防泄漏中对敏感数据的识别和访问控制中。
具体实施方式
20.下面将结合本发明的实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施
例,都属于本发明保护的范围。
21.本发明涉及一种基于工业互联网的数据识别方法,包括以下操作步骤:
22.s1:基于工业互联网的数据进行数据集的建立:建立数据文本并将其制成模型供观察,此时可对其数据特征进行选择,在数据集中的训练集进行数据的学习,建立分类器,在对其进行后续的测试和性能的评价,数据集包括训练集和测试集,训练集包括敏感数据库和已知工业数据库,训练集中的敏感数据库可以用于作为机器学习的分类器,已知工业数据库由两个小数据库组成,一个为敏感数据,一个为非敏感数据。
23.s2:将敏感数据库进行预处理:对敏感数据库进行关键特征的设定和提取,通过tfidf算法对其进行向量空间全值的计算,以此形状数据特征的向量,数据的预处理的识别过程中,需要先将数据中的单个数据代码进行标注,以便后续特征的提取,将数据代码进行分类,包括单极性码,极性码,双极性码,归零码,不归零码,双相码,曼彻斯特编码,差分曼彻斯特编码,多电平编码,特征提取可通过工业设备的数据接口得到数据分类的数据,此时可以对进行数据的旋转,选择后在对其频率进行统计,并对其数据代码的长度进行分析,以此对其进行选择,即可得到数据的关键特征,数据文本长度的选择时,需要计算每个关键数据文本的长度并删除单个数据文本的关键数据,以此使得只出现一次的文本判断为具有偶然性,使得其不具备代表性,因此剔除统计后的数据本体识别时能更加精准。
24.s3:阙值的确定:已知分类的数据库库进行预处理和特征提取之后,通过tfidf算法计算向量空间权值形成数据特征向量,与将敏感数据形成的特征向量进行余弦计算,并统计学习,根据阙值确定方法确定阙值。
25.s4:敏感数据的判断:将待判断的未知分类的数据进行预处理和特征提取,通过tfidf算法计算向量空间权值形成数据特征向量后,与敏感数据的特征向量进行余弦计算,将得到的余弦值与阙值进行比较,判断是否是敏感数据,敏感特征向量的计算时采用tfidf公式,使得某个数据文本出现在数据集的次数越少,那么这个数据文本就包含越多的信息,越能代表数据的类型,相反若在其他数据集中大量出现,那么这个数据文本则不具备代表性,通过余弦公式计算两个特征向量的相似度,以此判断特征向量的分类,余弦相似度计算后,通过对计算结果和阙值进行对比,以此判断数据文本是否为敏感数据,先收集工业设备的数据安全文件和敏感文件的数据文本库,通过处理与敏感集进行余弦计算以此得到值,通过确定相通间隔的阙值,进行是否敏感数据的判断,找到错误率低的阙值作为后面进行未知数据判断的阙值,其中可将数据分为非结构化数据、运营数据、元数据、组织数据、常量数据、主数据,经过特征的分析和计算后,能对所需的数据和录入的数据进行识别和判断,以此根据分类的数据对其进行选择和提取,同时可根据本数据与其它数据交互的行为,配合阙值对其进行其是否为主数据,其次运营数据可视为动词关系,主数据可视为名词关系,以此在进行特征提取后,更加方便后续对数据进行识别。
26.本发明在基于工业互联网的数据库中,如果将所有数据的文本都作为关键词的话,将导致计算量很大,也引入了过多的冗余信息,导致后期的分析存在很大的偏差,因此将预处理之后的分词结果进行提取,降低向量空间的维度,使其更加具有代表性,对数据识别的计算也更加简便有效,通过采用tfidf公式,其是对对数值权值的计算是衡量特征值的有效方法,其可将数据认为某个词在其它文本中出现的次数越是少,那么这个词就包含越多的信息,越能够代表文档的类型,相反,如果在其它文档中也是大量的出现,那么这个词
就不具有代表性,以此可以快速对数据的特征进行观察判断,通过对数据进行预处理,在特征选择过程中,数据选择后复合关键词的比例大大提高,同时大大的减少了冗余的数据,简便了后面的计算,通过与余弦的计算,可知敏感数据和非敏感数据的余弦是可分的,以此可以很好的确定阙值,以此对数据文档进行很好的判断,在将计算出的阙值用于敏感数据的判断时,可将错误率降低至忽略不计,同时可以根据特征词即可将数据进行识别找寻,此方法实用性较高、同时准确性和灵活性较好,可用于数据防泄漏中对敏感数据的识别和访问控制中。
27.尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。