1.本发明涉及智慧园区领域,具体涉及一种基于数字孪生的复杂光照下人的动作识别方法。
背景技术:
2.随着经济高速发展,各个园区从数字化向智能化快速演进,随着区域内安防监控、信息交互、行为识别等管理需求的增加,数据量爆炸式增长,园区管理者的决策难度大大增加,迫切需要智慧管理手段给予辅助。数字孪生技术作为一种创新发展的新模式和新理念成为了提升园区建设的现代化、精细化治理能力的必由之路。
3.根据国际定义,数字孪生(digital twin)是充分利用物理模型、传感器更新、运行历史等数据,集成多学科、多物理量、多尺度、多概率的仿真过程,在虚拟空间中完成映射,从而反映相对应的实体装备的全生命周期过程。5g、人工智能、云计算等新一代信息技术的快速发展使得人像识别、动作识别、活体检测、视频分析和数据分析等技术不断完善,为园区的数字孪生提供全面的、直观的场景支撑。
4.智慧园区系统作为提升园区管理效率的一种辅助手段,要想实现真正的“智慧”,就必须借助ai智能分析技术和联动具备融合通信能力的ar载具,围绕状态、位置、事件和资源四大要素,实现人的不安全行为与物的不安全状态的事前预警与事后处置的闭环。在智慧园区系统中,利用深度学习技术对监控视频进行人的动作识别是该系统的重要功能之一,该功能能够起到对人的不安全行为进行事后处理的作用。在此之前动作识别已应用于各个领域,但当前的动作识别方法大多集中在正常光照下拍摄的视频。复杂的室外场景光线条件如在夜间、逆光拍摄等各种场景是不可避免的,同时,鉴于视频注释的高成本,此类视频不太可能在现实场景中被详尽地标记。因此,如何能够利用正常光照下拍摄的大规模标记视频稳健的应对这些场景的问题是亟待解决的。
5.本发明的目的就在于提高深度模型应对复杂光照条件下进行人的动作分类的鲁棒性,所以提出一种联合非线性变换和深度学习网络将各种光照条件下的视频图像变换到相同分布的方法,并利用变换后的正常光照拍摄的大规模标记视频进行人的动作分类。
技术实现要素:
6.为解决上述技术问题,本发明提供一种基于数字孪生的复杂光照下人的动作识别方法,分为训练和推理两阶段,具体的:
7.一种基于数字孪生的复杂光照下人的动作识别方法,其特征在于,分为训练和推理两阶段:
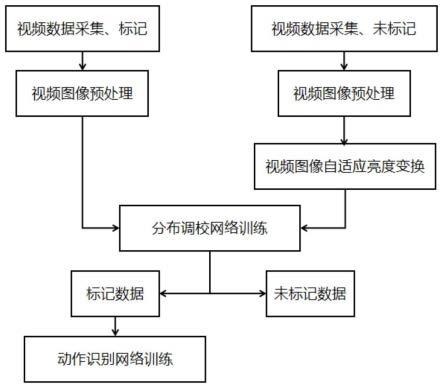
8.训练阶段的步骤为:
9.步骤s1:对深度学习的输入数据进行视频图像预处理;
10.步骤s2:对监控视频图像进行自适应的亮度变换;
11.步骤s3:将变换亮度后的图像作为输入,将不同光照条件下的图像分布进一步拉
近,使得无标签的不同光照下的视频数据具有和带标签的数据拥有更加相接近的数据分布,训练得到一个分布调校模型;
12.步骤s4:对经过步骤s3变换后的有标签数据进行分类训练,得到一个动作分类模型;
13.推理阶段的步骤为:
14.步骤s5:对监控视频图像进行自适应的亮度变换;
15.步骤s6:将预处理后的图像依次输入所述分布调校模型和所述动作分类模型进行推理,实现动作识别。
16.在一个实施方式中,所述视频图像预处理方法为精细化裁切,具体包括以下两个步骤:
17.步骤s11:通过目标检测网络yolov5,对n帧图像中人的坐标进行定位,得到目标的左上角和右下角坐标;
18.步骤s12:将n帧视频取坐标的车辆检测区域取并集。
19.在一个实施方式中,自适应亮度变换的具体步骤如下:
20.步骤s21:计算裁切图像加权平均亮度;
21.步骤s22:利用所述加权平均亮度hist_mean计算得到非线性变换参数gamma值,图像亮度越暗,gamma越小,图像经过非线性变换后越亮,反之,图像越亮,gamma值越大,图像经过非线性变换后越暗,gamma值的计算公式为:
[0022][0023]
步骤s23:对原始图像进行非线性gamma变换,变换公式为:步骤s23:对原始图像进行非线性gamma变换,变换公式为:i取值范围为从1至totalpixel,对从1至totalpixel的每一个i值,按照从小到大的顺序根据所述变换公式进行非线性gamma变换,其中totalpixel为所有像素点的个数,new_pixel[i]为像素i进行线性变换后的像素值,old_pixel[i]为像素i的像素值,hist_mean为s21得到的加权平均亮度。
[0024]
在一个实施方式中,训练分布调校模型需要将经过自适应亮度变换处理后的大量未标记视频图像以及正常光照的视频图像作为输入,对gan模型进行训练,得到分布调校模型,将未标记视频图像和正常光照视频图像的分布进一步拉近。
[0025]
在一个实施方式中,所述分布调校模型的网络结构为两个镜像对称的gan,两个gan共享两个生成器,并各自带一个鉴别器。
[0026]
在一个实施方式中,所述分布调校模型的损失函数为:
[0027]
l
total
(g,f,dx,dy)=l
gan
(g,dy,x,y) l
gan
(f,dx,x,y) θl
cyc
(g,f);
[0028]
其中,λ为权重系数,l
gan
(g,dy,x,y)和l
gan
(f,dx,x,y)为可使生成图像更真实的生成图像损失函数,l
cyc
(g,f)为可使生成器的输出图片与输入图片内容相同而风格不同的循环一致性损失函数,其计算公式分别为:
[0029]
l
gan
(g,dy,x,y)=e
y~pdata(y)
[log dy(y)] e
x~pdata(x)
[log(1-dy(g(x)))];
[0030]
l
cyc
(g,f)=e
x~pdata(x)
[‖f(g(x))-x‖] e
y~pdata(y)
[‖g(g(y))-y‖];。
[0031]
式中,x为在数据集x中所取的样本,y为在数据集y中所取的样本,g、f分别为两个生成器,dx、dy分别为两个判别器,dx、dy输出值均为[0,1],dx=1指输出来自x空间,dy=1指输出来自y空间,e
y~pdata(y)
为在y空间中所取样本,dy(y)指判别器dy判断y是否是取自y空间样本的概率,e
x~pdata(x)
为在x空间中所取样本,dy(g(x))为判别器dy判断生成器g生成的图片是否是取自y空间样本的概率,g(x)为生成器g所生成的图片,f(g(x))是对生成器g生成的图像通过生成器f再次生成,g(g(y))是对生成器g生成的图像通过生成器g再次生成。
[0032]
在一个实施方式中,所述分类训练是将带标记的正常光照视频图像经过分布调校模型变换后输入到动作识别分类网络进行训练。
[0033]
在一个实施方式中,所述动作识别分类网络的网络输入为(1,n,3,h,w),其中n为待识别动作序列抽样后的长度,h和w分别为图像的高和宽,网络结构采用3d resnet50作为分类网络,损失函数为softmax cross entropy。
[0034]
在一个实施方式中,所述动作识别分类网络的网络输入为(1,n,3,h,w),其中n为32。
[0035]
本发明的有益效果在于:
[0036]
通过对视频图像进行精细化裁切能够将图像中不利于分类的部分数据去除掉,更精确的定位人物动作的关键帧以及关键区域,这样的视频图像预处理方法能够提高模型的准确率。另外,通过自适应的亮度变化能够将非正常光照条件下的视频图像变换到均值相接近的视频图像域附近,这种通过非线性gamma变换的方法相比于其他提亮图像的方法(直方图均衡等)能够尽可能的提亮图像的同时保留图像细节不损失,但此时标记域和未标记域的图像分布还是有一定差距,所以再通过深度学习网络进一步拉近标记视频图像和未标记视频图像相分布,这样分成两步的方式能够在尽量不改变图像纹理细节的同时尽可能的拉近标记视频图像和未标记视频图像分布;本发明的另一个优点是相比有些方法只能对固定黑暗条件下的未标记视频图像进行动作识别,本方法对各种光照条件下的视频图像进行动作识别都可以达到较好的鲁棒性。
附图说明
[0037]
为了更清楚地说明本发明或现有技术中的技术方案,下面将对本发明或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0038]
图1为训练阶段系统流程图;
[0039]
图2为推理阶段系统流程图;
[0040]
图3为精细化裁切示意图一;
[0041]
图4为精细化裁切示意图二;
[0042]
图5为分布调校模型示意图;
[0043]
图6为动作识别分类网络结构示意图.
具体实施方式
[0044]
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施
例是本发明一部分实施例,而不是全部的实施例。
[0045]
本发明提供一种基于数字孪生的复杂光照下人的动作识别方法,分为训练和推理两阶段。如图1所示,训练阶段包括对深度学习的输入数据进行视频图像预处理,对监控视频图像进行自适应的亮度变换,将变换亮度后的图像作为输入训练一个分布调校模型,将不同光照条件下的图像分布进一步拉近,使得无标签的不同光照下的视频数据具有和带标签的数据拥有更加相接近的数据分布,最后对经过变换后的有标签数据进行分类训练。如图2所示,推理阶段包括对深度学习的输入数据进行视频图像预处理,对视频图像进行自适应的亮度变换,利用训练好的分布调教模型和动作分类模型进行推理。
[0046]
准备视频数据,并对视频数据实施以下步骤:
[0047]
步骤s1:对标记和未标记视频图像进行预处理:精细化裁切;
[0048]
步骤s11:如图3所示,通过目标检测网络yolov5,对n帧(例如:n=32)图像中人的坐标进行定位,得到目标的左上角和右下角坐标。
[0049]
步骤s12:如图4所示,将n帧视频取坐标的车辆检测区域取并集。
[0050]
步骤s2:图像进行自适应的亮度变换,具体步骤如下:
[0051]
步骤s21:计算裁切图像加权平均亮度;
[0052]
步骤s211:将步骤2中裁切的图像的rgb转化成yuv,转化公式如下:
[0053]
y=0.299r 0.587g 0.114b
[0054]
步骤s212:对图像上所有像素点的饱和度进行直方图(hist)的统计,计算直方图的公式为:hist[int(y[i])] =1,i取值范围为从1至totalpixel,j取值范围为从0至255,对从1至totalpixel的每一个i值和从0至255的每一个j值,按照从小到大的顺序根据所述计算直方图的公式进行像素点饱和度的直方图(hist)统计。
[0055]
步骤s213:通过直方图(hist)计算加权平均亮度,加权平均亮度计算公式为:hist_mean =hist[i]*i/totalpixel,i取值范围为从0至255,对从0至255的每一个i值,按照从小到大的顺序根据所述加权平均亮度计算公式进行加权平均亮度的计算。
[0056]
步骤s22:利用步骤3得到的加权平均亮度计算hist_mean得到非线性变换参数gamma值,图像亮度越暗,gamma越小,图像经过非线性变换后越亮,反之,图像越亮,gamma值越大,图像经过非线性变换后越暗,gamma值的计算公式为:
[0057][0058]
步骤s23:对原始图像进行非线性gamma变换,变换公式为:步骤s23:对原始图像进行非线性gamma变换,变换公式为:i取值范围为从1至totalpixel,对从1至totalpixel的每一个i值,按照从小到大的顺序根据所述变换公式进行非线性gamma变换,其中totalpixel为所有像素点的个数,new_pixel[i]为像素i进行线性变换后的像素值,old_pixel[i]为像素i的像素值,hist_mean为s21得到的加权平均亮度。
[0059]
步骤s3:如图5所示,分布调校模型主要作用为实现了领域自适应,可以使用例如cycle gan领域自适应模型来达到这一效果,训练分布调校模型需要将经过步骤3处理的大
量未标记视频图像以及正常光照的视频图像作为输入,对gan模型进行训练,得到分布调校模型,将未标记视频图像和正常光照视频图像的分布进一步拉近。
[0060]
网络输入:
[0061]
input a是标记数据,形状为(1,3,h,w),input b是经过步骤3处理后的未标记数据,形状为(1,3,h,w)。
[0062]
网络结构:两个镜像对称的gan,两个gan共享两个生成器g(generator),并各自带一个鉴别器d(discriminator)
[0063]
损失函数:
[0064]
l
total
(g,f,dx,dy)=l
gan
(g,dy,x,y) l
gan
(f,dx,x,y) θl
cyc
(g,f);
[0065]
其中,λ为权重系数,l
gan
(g,dy,x,y)和l
gan
(f,dx,x,y)为可使生成图像更真实的生成图像损失函数,l
cyc
(g,f)为可使生成器的输出图片与输入图片内容相同而风格不同的循环一致性损失函数,其计算公式分别为:
[0066]
l
gan
(g,dy,x,y)=e
y~pdata(y)
[log dy(y)] e
x~pdata(x)
[log(1-dy(g(x)))];
[0067]
l
cyc
(g,f)=e
x~pdata(x)
[‖f(g(x))-x‖] e
y~pdata(y)
[‖g(g(y))-y‖];
[0068]
l
total
(g,f,dx,dy)=l
gan
(g,dy,x,y) l
gan
(f,dx,x,y) λl
cyc
(g,f)
[0069]
式中,x为在数据集x中所取的样本,y为在数据集y中所取的样本,g、f分别为两个生成器,dx、dy分别为两个判别器,dx、dy输出值均为[0,1],dx=1指输出来自x空间,dy=1指输出来自y空间,e
y~pdata(y)
为在y空间中所取样本,dy(y)指判别器dy判断y是否是取自y空间样本的概率,e
x~pdata(x)
为在x空间中所取样本,dy(g(x))为判别器dy判断生成器g生成的图片是否是取自y空间样本的概率,g(x)为生成器g所生成的图片,f(g(x))是对生成器g生成的图像通过生成器f再次生成,g(g(y))是对生成器g生成的图像通过生成器g再次生成。
[0070]
步骤s4:带标记的正常光照视频图像经过步骤4变换后输入到动作识别分类网络进行训练,网络结构如图6所示。
[0071]
网络输入:大小为(1,n,3,h,w),其中n为待识别动作序列抽样后的长度,一般为32,h、w分别为图像的高和宽。
[0072]
网络结构:采用3d resnet50作为分类网络;
[0073]
损失函数:softmax cross entropy;
[0074]
步骤s5:对未标记视频图像推理过程重复1-2步骤,并将结果作为gan模型的输入推理得到变换后的视频图像,将变换后的视频图像输入到步骤5训练好的网络中进行分类。
[0075]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。