1.本发明属于计算机视觉研究技术领域,特别是涉及到一种应用于复杂场景中的基于多尺度注意力机制的图像语义分割方法。
背景技术:
2.语义分割是计算机理解图像的基础,目的是为图像中的每个像素提供一个语义类别标签,实现图像中不同类别的分割,并将不同类别用不同颜色表示,相同类别用相同颜色表示。图像语义分割是计算机视觉技术领域的主流任务之一,在无人驾驶汽车、医疗影像、遥感图像等领域有着广泛应用。传统的语义分割方法根据图像的灰度、颜色、结构、纹理等特点设计合理的准则,将图像中的像素点逐个与一个或多个阈值进行比较,从而将图像分割成互不重叠的区域。而传统的语义分割方法对人工的依赖较大且分割精度不高。近年来,人工智能的应用推动了计算机视觉技术的快速发展。深度学习的出现为语义分割技术提供了新的研究思路。目前,语义分割的主要框架有基于卷积神经网络的编解码结构、金字塔结构。编码器通过卷积和池化操作获取深层语义特征,解码器将编码器学习到的低分辨率特征投影到像素空间,得到密集分类。金字塔结构的空间金字塔池化模块可获取多尺度特征和更多的语义信息。这些基于深度学习的语义分割技术与传统语义分割技术相比,计算更快,精度更高。fcn首次实现了端到端,像素到像素的语义分割,在精度方面有了很大提升,但由于固定的感受野和简单的跳跃连接结构,导致大目标被误标,小目标被忽略和边缘细节等信息丢失。u-net是基于fcn的基础上改进的,是完全对称的编解码结构,只适用于医疗图像分割,不适用于复杂的街道场景分割。deeplab系列的网络结构通过改进卷积(膨胀卷积)和使用多尺度模块(空间金字塔池化)获取更大的感受野和多尺度信息。danet通过计算通道和空间位置的权重,更好的关注目标分割。但是,由于卷积核具有局限性,实际感受野小于理论感受野,导致网络提取上下文信息有限,而上下文信息对于场景理解任务又至关重要。且卷积和池化操作会损失空间信息,导致上采样恢复分辨率的过程中损失边缘细节信息和小目标特征,而简单的融合方式并不能很好的实现特征融合。所以,对于设计一种多尺度注意力机制的语义分割网络很有必要。
技术实现要素:
3.本发明所要解决的技术问题是:提供基于多尺度注意力机制的图像语义分割方法,综合网络多尺度性、自适应性、全局性这三个特性,提出一种全新的基于多尺度注意力机制的分割网络,用以解决在复杂场景分割中,同一物体存在不同尺度导致分类困难,解决小尺度目标漏割,大尺度目标误割,目标分割边缘不清晰等问题,优化分割效果。
4.基于多尺度注意力机制的图像语义分割方法,包括以下步骤,且以下步骤顺次进行,
5.步骤一、将复杂场景图像数据集分为训练集、测试集以及验证集,对训练集的图像及对应的标签数据进行预处理,获得同一尺寸图像;
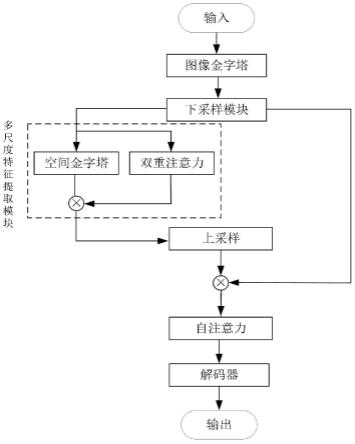
6.步骤二、构建语义分割网络模型,包括下采样模块、多尺度特征提取模块、特征融合模块以及上采样模块;将所述步骤一获得图像经过高斯卷核生成不同分辨率的图像,构成图像金字塔;
7.步骤三、所述步骤二中获得的图像金字塔作为分割网络的输入,通过下采样模块获得原图1/4分辨率的特征图,下采样模块的输出信息分为两路,其中一路作为多尺度特征提取模块的输入,另一路保持高分辨率的细粒度特征;
8.步骤四、所述步骤三输入至多尺度特征提取模块的信息,经由空间金字塔获取多尺度语义信息,且在提取时加入双重注意力,通过特征融合模块获得融合注意力的高级多尺度语义信息;
9.步骤五、所述步骤四得到融合注意力的高级多尺度语义信息经上采样模块与高分辨率特征融合,进行较小目标的分割,获得优化目标边缘和细节的多尺度语义信息;
10.步骤六、所述步骤五获得的获得优化目标边缘和细节的多尺度语义信息与所述步骤三获得的另一路保持高分辨率的细粒度特征融合后的多个特征图输入自注意力模块,计算多个特征图彼此的自注意力,建立空间长距离的像素关系,获得多个含有自注意力的特征图;
11.步骤七、将所述步骤六获得的多个含有自注意力的特征图经解码器再融合,生成分割结果图;
12.至此,基于多尺度注意力机制的图像语义分割方法完成。
13.所述步骤五上采样模块采用上池化方法获得稀疏高分辨率特征图,采用反卷积方法将稀疏特征图转换为密集特征图;分辨率恢复采用保留池化索引将空间信息保留,提高分割精度,进行小目标分割。
14.所述步骤二图像金字塔采用高斯金字塔,将源图像与高斯卷积核卷积,删除卷积后的偶数行和偶数列,得到缩小后的图像。
15.通过上述设计方案,本发明可以带来如下有益效果:基于多尺度注意力机制的图像语义分割方法,使用空洞空间金字塔结构提取高级多尺度语义特征,在高级多尺度语义特征中加入通道注意力和空间注意力,可以选择聚合不同类别的上下文信息,使得目标表征更加高效。图像金字塔中图像是并行输入网络的,保证了网络的分割效率,其中,大分辨率的图像有利于小目标的分割,小分辨率的图像有利于大目标的分割。整个分割网络有多个输出,通过使用自注意力机制来融合不同尺度的输出特征,自注意机制建模全局像素与像素之间的关系,获取更多有效的上下文特征,在一定程度上,保留了有用信息,滤除了无用信息,降低了网络的计算量。采用上池化和反卷积的上采样方式,可以很好的重建目标结构,通过使用池化索引,保留了空间信息,增加了分割精度,反卷积使得稀疏的低分辨率特征变得密集。各个模块相互协作,在复杂的街景场景分割中取得较好的分割效果。
附图说明
16.以下结合附图和具体实施方式对本发明作进一步的说明:
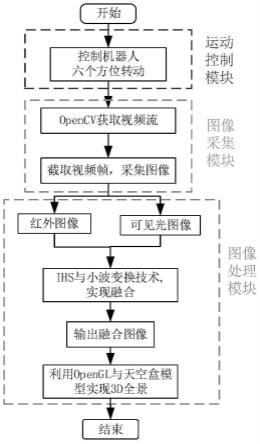
17.图1为本发明基于多尺度注意力机制的图像语义分割方法流程示意框图。
具体实施方式
18.基于多尺度注意力机制的图像语义分割方法,设计图像金字塔,用以捕捉图像中存在的不同尺度的特征,大尺度图像有利于捕获小目标特征,小尺度图像有利于捕获大尺度特征。图像金字塔中每个图像并行的经过分割网络产生多个分割结果,使用自注意力机制将其融合,得到最后的预测图。
19.具体的,如图1所示,包含以下步骤,并按以下步骤依次执行:
20.步骤一,将街道场景数据集分为训练集、测试集、验证集。对训练集的图像及对应的标签数据预处理,得到同一尺寸的图像,扩大训练样本的数量,使得分割模型更具鲁棒性。其中,数据预处理的方式包括图像切割、数据平衡、数据增强。
21.步骤二,构建语义分割网络模型。该模型包含下采样模块、多尺度特征提取模块、特征融合模块、上采样模块。
22.步骤三,训练图像经梯次下采样操作得到不同分辨率的图像,构成图像金字塔,用以捕获不同尺度的目标信息。
23.本发明具体采用高斯金字塔,是源图像与高斯卷积核卷积,并删除卷积后的偶数行和偶数列,得到缩小后的图像,表达式如下:
[0024][0025]
式中,gi、g
i 1
分别表示第i、i 1层高斯图像,表示卷积,k表示高斯卷积核,高斯卷积核一般选3
×
3或5
×
5大小,d表示删除卷积后图像的偶数列与偶数行。
[0026]
步骤四,步骤三中得到的图像金字塔作为分割网络的输入,通过下采样模块得到原图1/4分辨率的特征图,该模块的输出可分为两路,一路作为多尺度特征提取模块的输入,另一路保持高分辨率的细粒度特征。
[0027]
步骤五,多尺度特征提取模块的核心是空间金字塔和双重注意力机制(通道注意力与空间注意力),通过步骤四的输入获取图像的浅层多尺度信息,双重注意力机制保证特征的提取,减少融合时的参数计算量;浅层多尺度信息作为多尺度特征提取模块的输入,利用空间金字塔结构来提取更加深层的、更高级的多尺度语义信息,并通过双重注意力机制来计算原始浅层多尺度信息的注意力,然后将注意力与生成的深层多尺度语义信息融合,去除冗余,以便更好的关注目标区域。
[0028]
复杂场景图像经分割网络后生成较为深层的语义特征图,在语义分割领域中,多数采用交叉熵损失来优化网络,交叉熵通常是逐像素预测分类结果,具体表达式如下:
[0029][0030]
其中,l表示交叉熵损失函数,n表示像素点的数量,其中n∈n,m表示类别数量,其中c∈m,yc表示该像素属于c类别的标签,pc表示属于该类别的概率。
[0031]
步骤六,由步骤五得到融合注意力的高级多尺度语义信息经上采样模块与高分辨率特征融合,实现较小目标的分割,且目标边缘和细节信息得以优化。上采样模块我们采用上池化的方式得到稀疏的高分辨率特征图,并采用反卷积的方式,使得稀疏的特征图变密集。在分辨率恢复的过程中,通过保留池化索引使空间信息得以保留,提高分割精度。
[0032]
步骤七,步骤三中提到的图像金字塔是并行输入分割网络的,对于整个分割网络的多个输出,采用在transformer中常用的自注意力机制来实现多路特征的融合融合,实现
不同尺度空间下全局信息的交互,保留了更加有效的特征,进一步提高语义分割网络的精度。
[0033]
具体的,自注意力机制具体工作过程:由输入获取查询矩阵q,被查询矩阵k,计算输入特征之间的注意力a1,由softmax函数将相似度转化为概率,并与键值矩阵v相乘,得到注意后的结果o,实现特征增强;表达式如下:
[0034]
a=k
t
·q[0035]
a1=softmax(a)
[0036]
o=v
·
a1[0037]
其中,k,q,v分别表示输入k,q,v的集合。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。