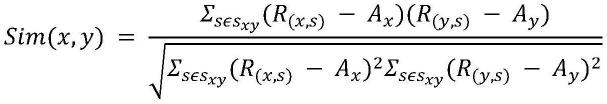
1.本发明属于推荐系统领域,具体的说涉及一种基于知识图谱并融合协同过滤的推荐方法。
背景技术:
2.大数据时代,移动互联网飞速发展,网络的普及给普通用户带来了大量的信息。随着时代的发展,网络上的信息量大幅增长,人们享受着快速获取信息的便利。但是随着音乐、购物、新闻、视频平台等网络服务提供商的快速发展,用户每天都要接受来自这些服务商推送的海量信息,用户不得不花费大量时间在这些海量信息中选择他们自己喜欢的内容。虽然现有的搜索引擎,如百度、谷歌等能解决一部分问题,但对于那些上网只是来打发时间,并没有特定目标,只是随便看看的用户,如何留住用户是这些在线服务商需要解决的问题。如果不能向用户提供他们感兴趣的内容,那么就很难留住用户。因此,通过互联网技术与大数据,为用户提供他们感兴趣的内容,具有极高的商业价值,也成为了当前研究的热点。
3.推荐系统的发展时信息化发展的必然,通过结合推荐系统与搜索引擎和用户的信息来满足用户的个性化需求。传统的推荐算法,借助用户与物品的交互信息,如用户对物品的打分矩阵,没有考虑其他信息,因此推荐效果不太理想,且存在冷启动和数据稀疏的问题。
技术实现要素:
4.为了解决现有技术中推荐不理想以及存在的冷启动和数据系数问题,本发明提供了一种基于知识图谱的推荐算法,该方法同时融合了传统的协同过滤算法,相较于现有算法,在推荐准确率、召回率、f值上具有更好的表现。
5.为了达到上述目的,本发明是通过以下技术方案实现的:
6.本发明是一种基于知识图谱并融合协同过滤的推荐方法,该方法包括以下步骤:
7.步骤1、收集用户已经评价的项目信息。在电影推荐中,一般是收集用户对电影的浏览次数,用户对电影的评分,用户对电影打的标签等。
8.步骤2、通过基于用户的协同过滤算法,计算用户之间的相似度矩阵,记为sim1。使用下面的公式,计算用户之间的相似度:
[0009][0010]
其中,sim(x,y)表示用户x和用户y之间的相似度,s
xy
=s
x
∩sy,表示用户x和用户y共同评过分的电影集合,r
(x,s)
表示用户x对电影s的评分,a
x
表示在s
xy
中用户x对电影的平均评分,r
(y,s)
表示用户y对电影s的评分,ay表示在s
xy
中用户y对电影的平均评分。
[0011]
步骤3、根据评分矩阵,构建知识图谱。对于一个典型的知识图谱,它是由若干个有
向图表示的三元组,以及这些三元组的相互联系构成。这些三元组承载着实体与关系的语义信息,实体充当节点,实体间的关系充当边。将电影信息构建知识图谱时,实体主要包括:电影,演员,题材等,电影之间的关系主要包括:act in、direcitor、belong to等。还有就是用户对电影的偏好。当用户对某个电影的评分大于其平均评分时,就认为用户喜欢该电影,即(用户,喜欢,电影1);当用户对某个电影的评分小于其平均评分时,就认为用户讨厌该电影,即(用户,讨厌,电影2)。当用户观看某题材的数量占其观看总数量的一半时,就认为用户喜欢该题材,即(用户,喜欢,题材1)。在模型构建中,这些实体和关系都被表现为n维向量,其中实体为k维向量,关系表现为d维向量,k与d不一定相同。
[0012]
步骤4、在知识图谱中,添加多模态信息。获取电影图片和用户对电影的评价,抽取图片和文本信息的实体、属性和关系,与知识图谱进行数据融合后得到多模态知识图谱。
[0013]
步骤5、使用transr模型嵌入实体和关系。transr模型是在transe与transh模型的基础上,逐渐演化出来的。基于思想是:对于每个三元组(h,r,t),将实体通过矩阵mr投影到关系空间r中,通过投影得到hr,tr,使得hr r=tr,打分函数为fr(h,t)。
[0014]hr
=hmr,tr=tmr[0015]fr
(h,t)=||hr r-tr||2[0016]
步骤6、根据训练得到的实体向量,根据余弦相似度计算用户的相似度sim2。
[0017][0018]
步骤7、调整融合比例,生成融合相似度矩阵sim。
[0019]
sim(a,b)=α*sim1(a,b) (1-α)*sim2(a,b)
[0020]
α∈(0,1]为融合比例。举例来说,当α取0.5时,假设siml(a,b)=0.6,sim2(a,b)=0.4,那么sim(a,b)=0.5*0.6 0.5*0.4=0.5。
[0021]
步骤8、根据相似度矩阵,对目标用户对电影的评分进行推荐,选取评分最高的若干项目做出推荐结果。
[0022][0023]
其中:tu表示用户u对电影的平均评分,c表示用户u的邻居数目,ri表示u的邻居用户i对当前电影的评分,ti表示用户i对电影的平均评分,sim(i,u)表示用户i和用户u的相似度,pu表示用户u对当前电影的评分,计算出目标用户的预测评分后将预测评分最高的top-n项目推荐给用户。
[0024]
本发明的有益效果是:
[0025]
(1)本发明的电影推荐基于知识图谱进行,并且还融合了传统的协同过滤,在一定程度上解决了数据稀疏和冷启动的问题;
[0026]
(2)结合知识图谱自身的特点,能够更加挖掘电影本身的语义信息,在推荐准确率、召回率、f值上具有更好的表现;
[0027]
(3)本发明中设置的融合比例α,能够灵活调节协同过滤与知识图谱所占的比例,从而达到最佳的推荐效果。
附图说明
[0028]
图1是本发明的总体流程图。
[0029]
图2是本发明方法对于知识图谱的嵌入过程图。
具体实施方式
[0030]
以下将以图式揭露本发明的实施方式,为明确说明起见,许多实务上的细节将在以下叙述中一并说明。然而,应了解到,这些实务上的细节不应用以限制本发明。也就是说,在本发明的部分实施方式中,这些实务上的细节是非必要的。
[0031]
本发明是一种融合知识图谱和协同过滤的电影推荐方法,本发明将物品的内涵信息和之间的联系等辅助信息,添加到推荐系统中。基本组成单位是“实体—关系—实体”三元组的知识图谱,恰好可以作为推荐系统的辅助内容。在知识图谱中,即考虑了物体自身的信息及关联,也考虑了用户兴起的主观性,与传统的协同过滤推荐相比,增强了推荐效果,具体的,该电影推荐方法包括如下步骤:
[0032]
步骤1、收集用户已经评价的项目信息,在电影推荐中,一般是收集用户对电影的浏览次数,用户对电影的评分,用户对电影打的标签等。
[0033]
步骤2、通过基于用户的协同过滤算法,计算用户之间的相似度矩阵,记为sim1,
[0034]
假设收集的数据有:
[0035]
表1用户对电影的评价表
[0036] item1item2item3user1345user2324
[0037]
使用下面的公式,计算用户之间的相似度:
[0038][0039]
其中,sim(x,y)表示用户x和用户y之间的相似度,s
xy
=s
x
∩sy,表示用户x和用户y共同评过分的电影集合,r
(x,s)
表示用户x对电影s的评分,a
x
表示在s
xy
中用户x对电影的平均评分,r
(y,s)
表示用户y对电影s的评分,ay表示在s
xy
中用户y对电影的平均评分。
[0040]
通过计算:a
x
=4,ay=3,=3,通过计算,得到用户x和用户y的相似度为0.5。也即是步骤2中的sim1。
[0041]
步骤3、根据步骤2得到的评分矩阵,构建知识图谱,本发明更关心的是用户喜欢还是讨厌某电影,定义:如果用户对某电影的评分大于其平均评分即为喜欢该电影,用知识图谱表示即是(用户a,喜欢,电影1),如果对电影的评分小于其平均评分,即为讨厌该电影,用知识图谱表示即(用户a,讨厌,电影2)。
[0042]
步骤4、在知识图谱中,添加多模态信息。获取电影图片和用户对电影的评价,抽取图片和文本信息的实体、属性和关系,与知识图谱进行数据融合后得到多模态知识图谱。
[0043]
步骤5、使用transr模型嵌入实体和关系。transr模型是在transe与transh模型的
基础上,逐渐演化出来的。基于思想是:对于每个三元组(h,r,t),将实体通过矩阵mr投影到关系空间r中,通过投影得到hr,tr。使得hr r=tr,打分函数为fr(h,t)。训练模型如图1。
[0044]hr
=hmr,tr=tmr[0045]fr
(h,t)=||hr r-tr||2[0046]
步骤6、根据训练得到的实体向量,根据余弦相似度计算用户的相似度sim2。
[0047][0048]
举例来说,用户1=[0,1,1,1,2,1,0,2,1,1],用户2=[1,01,1,2,1,1,1,1,0]。计算相似度:0*1 1*0 1*1 1*1 2*2 1*1 0*1 2*1 1*1 1*0=10,02 12 12 12 22 12 02 22 12 12=14,12 02 12 12 22 12 12 12 12 02=11。
[0049][0050]
步骤7、调整融合比例,生成融合相似度矩阵sim。
[0051]
sim(a,b)=α*sim1(a,b) (1-α)*sim2(a,b)
[0052]
α∈(0,1]为融合比例。将sim1和sim2融合得到最终相似度sim。距离来说sim1=0.4,sim2=0.6,α取0.5,则sim=0.4*0.5 0.6*0.5=0.5。这是计算某用户与用户u的相似度,可以重复该过程,计算多个用户与用户u的相似度。
[0053]
步骤8、根据相似度,计算对目标用户对电影的评分进行推荐,选取评分最高的若干项目做出推荐结果。
[0054][0055]
其中:tu表示用户u对电影的平均评分,c表示用户u的邻居数目,ri表示u的邻居用户i对当前电影的评分,ti表示用户i对电影的平均评分,sim(i,u)表示用户i和用户u的相似度。pu表示用户u对当前电影的评分,计算出目标用户的预测评分后将预测评分最高的top-n项目推荐给用户即可。
[0056]
举例来说,用户u对电影平均评分tu为3,邻居个数c设为3。r1,r2,r3分别为4,5,4,即用户1、用户2、用户3对该电影的评分分别为4分、5分和4分。sim(1,u),sim(2,u),sim(3,u)分别为0.5,0.2,0.3,即用户1、用户2、和用户3与用户u的相似度分别为0.5,0.2,0.3。则用户u对该电影的评分是:
[0057]
上述是计算用户对某个电影的评分,可以重复上述过程计算用户对若干电影的评分,计算出目标用户的预测评分后,将预测评分最高的top-n项目推荐给用户即可。
[0058]
本发明的推荐算法,同时融合了传统的协同过滤推荐算法,由于知识图谱自身的特点,一定程度上解决了冷启动和数据稀疏问题。在推荐准确率、召回率、f值上具有更好的表现。
[0059]
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。