1.本发明涉及一种分类模型的训练方法,具体涉及一种用于水轮机空化现象识别的分类模型训练方法。
背景技术:
2.水轮机的初生空化是指:液体内局部压强降低到临界值,所含气核急剧增长,空化开始发生的现象。它伴随着噪声与振动,会导致发电效率下降、出力减少、水力振动加剧。不但影响水轮机的使用寿命,还威胁着水电站和电网的安全运行。
3.识别水轮机空化对水电站、电网的运行安全具有重要意义,目前确定模型水泵水轮机水泵工况初生空化的方法还停留在人工观测的阶段,这种方法主观性强,准确度及效率都较低。
4.专利cn113255848a公开了一种基于大数据学习的水轮机空化声信号辨识方法,该专利筛选水轮机组健康状态下稳定工况的声信号特征量,通过大数据学习辨识水轮机空化声信号来判断空化现象,以达到提前预测输出未来短时稳定工况信息的目的。对水轮机是否发生空化现象的识别本质上是一个二分类的问题,而分类模型是数据挖掘、机器学习和模式识别中一个重要的研究领域,分类的目的,就是根据数据集的特点,构造一个分类函数或分类模型model,该模型能把未知类别的样本映射到给定类别中的某一个。
5.分类模型的构造方式有很多,例如神经网络,然而神经网络普遍存在收敛速度慢、计算量大、训练时间长和不可解释等缺点。svm (support vector machine)分类算法是一种小样本学习方法,它的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了高维变量引起的灾难。如果说神经网络方法是对样本的所有因子加权,那么svm 方法则是对只占样本极少数的支持向量样本“加权”。当预报因子与预报对象间蕴涵的复杂非线性关系尚不清楚时,基于关键样本的方法可能优于基于因子的“加权”。少数支持向量决定了最终结果,可以剔除大量冗余样本、抓住关键样本,使得该方法不但算法简单,而且具有较好的鲁棒性。
6.然而svm 方法只对静态物理量构成的二维平面具有较好的线性分类效果,而对于动态变化的物理量,如空化噪音,它不是线性可分的并且噪声较大,采用基础的线性方法无法较好的对其进行二元分类,也就无法训练出准确度高的分类模型用于水轮机转轮空化现象的识别。
技术实现要素:
7.本发明旨在解决现有技术中的分类算法对非线性可分的样本数据分类效果不好的问题,提出了一种用于水轮机空化现象识别的分类模型训练方法,该方法沿用了svm方法的精髓,在核函数和超参数的选择等环节进行了优化,能够更好地适应水轮机空化试验数据的特点,训练出的分类模型具备较好的分类识别效果。
8.为了实现上述发明目的,本发明的技术方案如下:
一种用于水轮机空化现象识别的分类模型训练方法,其特征在于,包括如下步骤:s1、输入带有分类标签的非线性可分的训练样本数据;s2、利用监督学习方法对输入的训练样本进行二元分类并求解最大间距超平面;s3、加入松弛变量,并使用升维函数将低维度输入空间的样本映射到高维度空间使样本变为线性可分,在形成的特征空间中寻找最优分类超平面;s4、使用指数循环递减矩阵搜索法搜索升维函数中的最优超级参数c和γ;s5、使用最优超参数在整个训练集上再次训练,得到最终的分类器;s6、将训练好后的分类模型保存并应用于目标分类对象的分类识别。
9.进一步地,将输入的训练样本数据集表示为:(x1,y1),(x2,y2),(xi,yi)...,(xn,yn),n为样本数量;其中,xi为一个含有d个元素的列向量;yi表示标签,yi∈ 1,
−
1;yi= 1时表示xi属于正类别;yi=
−
1时表示xi属于负类别;分类模型的优化目标表示为:;约束条件为:y
j (w
t
×
f(xi) b)》=1;其中,ω、b为超平面参数向量;f(x)为升维函数,f (x
i,
yj) = e ^(
−
γ|| xiꢀ−ꢀyj || 2
);c为惩罚因子,ξ为松弛因子。
10.进一步地,步骤s4中,超级参数c的确定包括如下步骤:1)在输入矩阵中确认一对参数c0、γ0作为升维函数的初始参数,并确定输入矩阵的维度大小;2)将样本数据集划分成相同大小的q个子集,将其中一个子集作为验证集,剩余的q-1个子集作为训练集训练分类器;3)使用验证集对训练出的分类器进行验证测试,得到正确分类的数量百分比p;遍历所有子集,得到p1、p2......pq,求其平均值,得到pc1;4)按指数递减规律,在网格中更换一对超参数,γ0保持不变,超级参数c按指数递减规律不断下降,重复上述过程直到得到与输入矩阵行数相等的pci。
11.进一步地,步骤s4中,超级参数γ的确定包括如下步骤:1)在输入矩阵中确认一对参数c0、γ0作为升维函数的初始参数,并确定输入矩阵的维度大小;2)将样本数据集划分成相同大小的q个子集,将其中一个子集作为验证集,剩余的q-1个子集作为训练集训练分类器;3)使用验证集对训练出的分类器进行验证测试,得到正确分类的数量百分比p;遍历所有子集,得到p1、p2......p q
,求其平均值,得到pγ1;4)按指数递减规律,在网格中更换一对超参数,c0保持不变,超级参数γ按指数递减规律不断下降,重复上述过程直到得到与输入矩阵行数相等的pγj。
12.进一步地,将pci、pγj组成一个结果矩阵(pci、pγj),在该结果矩阵(pci、pγj)中寻找最大值,最大值所对应下标的c、γ即为找到的最优超参数。
13.综上所述,本发明具有以下优点:1、本发明的svcc算法基于svm小样本学习方法,根据模型转轮空化噪声数据的特点,结合长期水轮机模型试验实践经验,对分类模型的核函数和超参数的选取环节进行了优化,以帮助机器完成对水轮机空化现象的学习和识别,提高了识别效率与识别准确度。
14.2、本发明通过升维函数的运用,将低维度输入空间的样本向高维空间进行映射,解决了非线性的分类问题;升维函数的应用也减少了低维空间映射到高维空间后的极大计算量,减少了内存消耗。
15.3、本训练方法的学习策略是:在分类超平面的正负两边各找到一个离分类超平面最近的点,使得这两个点距离分类超平面的距离和最大。这个分类策略使得在保证对训练数据分类正确的基础上,对噪声设置尽可能多的冗余空间,提高了分类器的鲁棒性。
16.4、本发明的分类模型训练方法使用的样本数量可以较少,训练时间短,并且训练出来的分类模型识别准确度和识别效率高。
17.5、本发明的超参数甄选方法具备高度泛化能力,筛选的最优超参数可以提高学习的性能和效果,建立的模型具有较好的推广能力。
附图说明
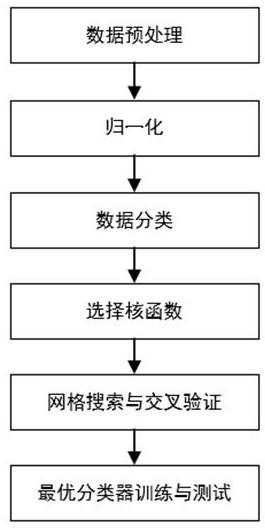
18.图1为本发明的实施流程图。
具体实施方式
19.为了更清楚地说明本发明,下面结合优选实施例和附图对本发明做进一步的说明。本领域技术人员应当理解,下面所具体描述的内容是说明性的而非限制性的,不应以此限制本发明的保护范围。本发明的说明书和权利要求书及上述附图中的属于“第一”、“第二”等是用于区别不同的对象,而不是用于描述特定顺序。此外,术语
“ꢀ
包括”和
“ꢀ
具有”以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法或设备固有的其他步骤或单元。
20.本发明提出了一种用于水轮机空化现象识别的分类模型训练方法,它是一种支持向量模型水轮机空化分类算法,简称svcc(support vector classfication calculation)算法。本方法沿用了svm算法的精髓,在核函数和超参数的选择等环节进行了优化,能够更好地适应水轮机空化噪声数据的特点,训练出的分类模型具备较好的分类识别效果。本方法同样可以拓展应用于对水泵、船用螺旋桨、航空叶片等的无损检测上。具体的,如图1所示,该方法包括以下步骤:步骤一、获取训练样本(一)、数据网格采样开展水轮机模型转轮空化试验,数据采样需要覆盖转轮空化的工作时段,使得机器学习后的模型具备较好的泛用能力。试验选择在典型水头下开展,在每个水头下,确定若干导叶开度,每个导叶开度下,确定若干测功机转速,在每组转速下,通过运行真空泵,改变管道内的压力来调整模型空化状态,使模型转轮空化数在一定范围内变化。
21.在空化发生过程中,对于声音采用水听器和放大器进行连续采样。若采样频率
100khz,采样时长为40s,会得到4000k个数据。记录空化可能发生的时刻,对应的在每个数据中进行标记,每个数据将伴随一个标签(标明是否发生空化)。将这些采样数据统一保存在数据库中,并按不同特征水头、不同开度、不同转速进行分组。
22.(二)、数据预处理1)正负样本均化:对打有分类标签的采样数据进行分组,以使得不同分类(空化/未空化)的样本数据大致相等。舍去某种分类较多的数据,保留模型转轮空化发生时刻前后各 10 秒(共 20 秒)的噪音数据。
23.2)数据分组截断:将正负样本均化后得到的 20s 连续数据进行截断,按照 1s 或2s为周期,划分为多个数据组,每一组的标签取其数据的标签,并分组进行保存。
24.3)计算每组数据的统计特征使用0.97置信概率赋值函数或混频采样函数将采集到的每组噪声数据中的混波信号分解为若干单波信号,分别计算这些单波信号的统计特征,获得相关分析指标参数,这些相关分析指标参数包括时域指标参数、功率谱密度指标参数和频域指标参数。
25.时域分析指标参数包括峰峰值 vpp;四分位频数概率 pvph;均值mean;标准差st;峭度ku;偏度sk;信息熵h。
[0026] 频域分析指标参数包括重心频率psdfc;频率标准差psdrvf;功率谱频段幅值均值 psdh(高频),psdm(中频),psdl(低频)。
[0027]
由于水轮机模型空化噪声信号频谱特性有时并不明显,为防止杂波干扰,引入功率谱密度指标参数(psd)作为修正量。
[0028]
在分类识别应用场景下,频域指标、时域指标和功率谱密度指标一同作为特征向量的一部分,以丰富特征量种类,提升诊断正确率。
[0029]
4)相关性分析对所得相关指标参数进行分析,寻找模型转轮空化与这些指标参数之间的关联特性,在其中挑选出相关性较高的部分特征,将其数据保存至csv表格。经分析,在空化发生前后有显著变化的指标包括:峰峰值vpp、四分位频数概率pvph、标准差st、峭度ku、偏度sk、信息熵h、功率谱密度、重心频率psdfc。
[0030]
5)对上述csv表格中的数据进行归一化变换处理考虑到min-max标准化,也就是离差标准化方法在使用时无法消除量纲对方差的影响,本实施例中采用0均值标准化方法对csv表格中的数据进行归一化变换。具体操作为:将得到的csv表格,计算每类指标的均值mean和标准差st,用公式=(x-mean)/st计算每个数据组的归一化后数据按原有格式存表。经过此步骤处理后的数据符合标准正态分布,避免了不同量纲的选取对距离计算产生的巨大影响。
[0031]
6)针对每组数据,将标准化后的不同单波信号的各项指标参数选择性的映射到矩阵行向量和列向量的不同元素位置(位置可改变),形成特征向量及对应的标签,例如:[vpp, pvph, std, ku, sk, ih, fc] [label] 。这些特征向量就构成了输入分类模型的训练样本。
[0032]
步骤二、训练分类器(一)分类器优化目标和核函数选择1)按照监督学习方法对输入的训练样本数据进行二元分类,并对训练样本求解最
大间距超平面。
[0033]
将输入的训练样本数据集表示为:(x1,y1),(x2,y2),(xi,yj)...,(xn,yn),n为样本数量。其中,xi为一个含有d个元素的列向量;yj表示标签,yi∈ 1,
−
1;yi= 1时表示xi属于正类别(有空泡);yi=
−
1时表示xi属于负类别(无空泡)。
[0034]
无论是图像还是声音,数据点都是三维向量,普通的二维平面上的分类直线已经无法满足这类由三维向量构成的训练样本的分类识别,因此,需要用一个多维平面(超平面)来区分这些数据点。
[0035]
超平面由法向量ω和截距b决定,其方程为:x
t
ω b = 0,其中,ω、b为超平面参数向量。超平面的一个合理选择就是以最大间隔把两个类分开,最大间隔也就是找到一个超平面,使其距离两类数据点的距离最大,这些数据点中离超平面最近的点为支持向量点。
[0036]
2)引入松弛变量和惩罚因子实际操作过程中,由于比较难获取到线性可分的样本数据,同时,训练数据也会存在一些噪声,使得支持向量点到最优分类超平面非常小,或者根本无法找到。因此,可以对每一个样本引入松弛变量,以“放松”样本到超平面的约束,同时加入惩罚因子c。
[0037]
3)使用升维函数将低维度输入空间的样本映射到高维度空间,使样本变为线性可分,就可以在形成的特征空间中寻找最优分类超平面。
[0038]
若用x表示原来的样本点,用
ϕ
(x)表示 x 映射到新的特征空间后的向量。那么分割超平面可以表示为:f(y)= ω
t
ϕ
(x) b。
[0039]
通过使用升维核函数k(x,y)=(
ϕ
(x),
ϕ
(y))可以使xi与yj在特征空间的内积等于它们在原始样本空间中通过函数k(x,y)计算的结果,也就是说,直接通过k(x,y)在低维空间中实现映射到高维空间之后的内积结果,就不需要计算高维的内积了,这样就减少了将低维空间映射到高维空间计算量以及内存的消耗。
[0040]
优化目标即为求解下式:;约束条件为:y
j (ω
t
*f(xi) b)》=1;其中,ω、b为超平面参数向量;f(x)为升维函数,f(xi, yj) = e ^(
−
γ|| xiꢀ−ꢀyj || 2
);c为惩罚因子,ξ为松弛因子;xi、yj为样本向量及其标签。
[0041]
(二)分类器的最优超参数c、γ的选择;网格搜索(grid search)算法是一种通过遍历给定的参数组合,来优化模型表现的方法。即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练模型,从所有的参数中找到在验证集上精度最高的参数。这其实是一个训练和比较的过程。其本质上是穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。
[0042]
交叉验证(cross-validation)就是一种找到最优的(c,γ)的有效方法。在使用交叉验证的方法确定参数(c,γ)时,不同的参数值对(c,γ)被试验,其中一个能够得到最高
的交叉验证准确率。
[0043]
在此基础上,使用指数循环递减矩阵搜索法来搜索升维函数中的超级参数,目标是找到最优的超参数c、γ,使得分类模型能够精确地预测未知数据。具体过程如下:1)在输入矩阵中确认一对参数c0,γ0作为升维函数的初始参数,并确定输入矩阵的维度大小(i,j),i和j分别代表输入矩阵的行数和列数。
[0044]
2)将样本数据集划分成相同大小的q个子集,将其中一个子集作为验证集(vdata),剩余的q-1个子集作为训练集(tdata)训练分类器。
[0045]
3)使用验证集对训练出的分类器进行验证测试,得到正确分类的数量百分比p;遍历所有子集,得到p1、p2......pq,求其平均值,得到pc1;4)按指数递减规律,在网格中更换一对超参数(c1,γ0),其中c1=c0/a,a为设定的递减指数,γ0不变;重复步骤2)至3)的过程,得到另一个数量百分比的平均值pc2;5)γ0保持不变,超级参数c按设定的指数递减规律不断下降,重复上述过程直到得到与输入矩阵行数相等的pci。
[0046]
6)针对超级参数γ,按照同样的方法,γ以按设定的指数规律不断下降,c保持不变,不断重复上述过程,得到与矩阵列数相等的pγj。
[0047]
7)将pci、pγj组成一个结果矩阵(pci、pγj),在该结果矩阵(pci、pγj)中寻找最大值,所对应下标的c,γ即为找到的最优超参数。
[0048]
8)获取最优的超参数c,γ后,用该组参数在整个训练集上再次训练,得到最终的分类器m。
[0049]
9)将训练好后的分类模型保存,在实际运行环境中导入该分类模型,采集新数据,并将数据清理、计算统计特性后,送入分类模型完成分类。
[0050]
在上述过程中,为了减少矩阵搜索的时间,可以先确定一个输入矩阵的大致范围,在粗网格中确定输入矩阵的一个较好区域后,再在这个较好区域中重复上面超参数的搜索过程。
[0051]
虽然结合附图对本发明的具体实施方式进行了详细地描述,但不应理解为对本专利的保护范围的限定。在权利要求书所描述的范围内,本领域技术人员不经创造性劳动即可做出的各种修改和变形仍属本专利的保护范围。
[0052]
以上所述,仅是本发明的较佳实施例,并非对本发明做任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化,均落入本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。