1.本发明涉及语音处理技术,特别涉及一种语速调整方法及其系统。
背景技术:
2.影音的音频描述通过特制的音轨提供对角色动作和场景变化等事件的变化进行语音描述。音频描述可为盲人、低视力或其他视力障碍的人改善视觉影图像的可访问性。
3.音频描述的创建既昂贵又麻烦。传统上,影音的制作者雇用脚本编写者和语音人才来创建音频描述。在这种传统方法中,脚本编写者通过观看影音的内容找出需加上音频描述的影像片段,以确定需插入音频描述的时间点并估算音频描述的可用时间,并根据影像片段的内容创建描述性音频的脚本。然后,语音人才再依据脚本录制符合可用时间的音频描述。通常,在可用时间的时间限制下,脚本编写者和语音人才必须多次重复前述过程以优化获得的音频描述。例如,脚本编写者可以修改需要音频描述的影像片段以得到新的可用时间、或者脚本编写者可以重写脚本以适应较短的可用时间,或者语音人才可反复调整其讲话速度以适应可用时间。由于这些挑战,传统的音频描述服务的价格相当高。
技术实现要素:
4.有鉴于上述现有技术的问题,本发明的目的在于提供一种语速调整方法及其系统,适用于调整语音信号的语速,以提供满足时间限制的音档,进而减少重复录音的次数,并大幅减少音档的制作成本。
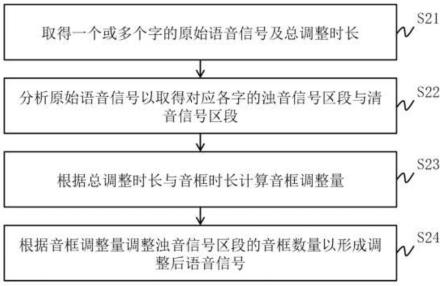
5.本发明一实施例提供一种语速调整方法,其包括:取得多个字的原始语音信号及总调整时长;分析原始语音信号以取得对应各字的浊音信号区段与清音信号区段;根据总调整时长与单位音框时长计算音框调整量;以及根据音框调整量调整至少一浊音信号区段的音框数量以形成调整后语音信号。
6.本发明另一实施例提供一种语速调整系统,其包括:储存单元、分析单元、以及调整单元。分析单元耦接储存单元,且调整单元耦接储存单元与分析单元。储存单元暂存多个字的原始语音信号。分析单元分析原始语音信号以取得对应各字的浊音信号区段与清音信号区段。调整单元根据总调整时长与单位音框时长计算音框调整量,并且根据音框调整量调整至少一浊音信号区段的音框数量以形成调整后语音信号。
7.综上所述,任一实施例的语速调整方法适用于调整语音信号的语速,以提供满足时间限制的音档,进而减少重复录音的次数,并大幅减少音档的制作成本。
8.以下结合附图和具体实施例对本发明进行详细描述,但不作为对本发明的限定。
附图说明
9.图1为一些实施例的语速调整方法的流程图;
10.图2为一些实施例的语速调整系统的功能方框图;
11.图3为一实施例的原始语音信号的示意图;
12.图4为一些实施例的语速调整系统的功能方框图;
13.图5为一些实施例的语速调整方法的流程图;
14.图6为一些实施例的语速调整方法的流程图;
15.图7为一些实施例的语速调整系统的功能方框图;
16.图8为一些实施例的语速调整方法的流程图。
17.其中,附图标记
18.10:语速调整系统
19.110:储存单元
20.120:分析单元
21.130:调整单元
22.140:转换单元
23.150:判断单元
24.160:识别单元
25.170:更新单元
26.180:影音处理单元
27.190:合并单元
28.si:原始语音信号
29.n1:总调整时长
30.so:调整后语音信号
31.wo:字
32.sp1~sp7:字音信号
33.f1:语音波形
34.f2:声音频谱
35.z1:清音信号区段
36.z2:浊音信号区段
37.vi:原始影音视频
38.vo:口述影音视频
39.mi:无声连续图片
40.mo:有声连续图片
41.xl:描述文本
42.tt:无声内容的总时长
43.s21~s27:步骤
44.s11~s15:步骤
45.s14’:步骤
46.s26’:步骤
具体实施方式
47.下面结合附图对本发明的结构原理和工作原理作具体的描述:
48.参照图1与图2,本发明一实施例提供一种语速调整系统10,包括:储存单元110、分
析单元120以及调整单元130。分析单元120耦接储存单元110,并且调整单元130耦接储存单元110与分析单元120。于此,储存单元110暂存至少一字的原始语音信号。其中,本发明还提供一种语速调整方法,其能以语速调整系统实现。为清楚说明,以下以多个字的原始语音信号为例进行说明。
49.于此,语速调整方法可适用于调整单字或句子的发音的语速,或调整影音的音频描述的语速。后续将详述语速调整方法的技术内容。
50.于一实施例中,分析单元120能取得并分析原始语音信号si(步骤s21)以取得对应各字的浊音(voiced sound,又称有声音)信号区段与清音(unvoiced sound,又称无声音)信号区段(步骤s22)。调整单元130能取得总调整时长n1(步骤s21),根据总调整时长n1与单位音框时长计算待移除的音框的数量(即音框调整量)(步骤s23),并且根据音框调整量调整此些字的浊音信号区段其中至少一浊音信号区段的音框数量以形成调整后语音信号so(步骤s24)。其中,音框(speech frame)为进行语音信号处理时的最小信号区段,而单位音框时长即为一个最小信号区段的时间长度。
51.在一些实施例中,原始语音信号si包括此些字wo的字音信号sp1~sp7,如图3所示。各字音信号sp1~sp7包括多个音框(以下称原始音框)。
52.其中,于语言学中,发音时声带振动的音称为浊音,声带不振动的音称为清音,另有辅音,其同时具有清音与浊音,于本案中于遇有辅音的字时,可以先区分出浊音与清音后,再进行语速调整。
53.在步骤s22的一些实施例中,分析单元120会分析原始语音信号si以找出原始语音信号si中每个字wo的字音信号sp1~sp7(即对应每个字的信号区段),然后再分析每个字wo的字音信号sp1~sp7以找出每个字音信号sp1~sp7中浊音信号区段(即对应浊音发音的信号区段)与清音信号区段(即对应清音发音的信号区段)。举例来说,搭配参照图3,分析单元120能将原始语音信号si从时间对振幅的语音波形f1转换成时间对频率的声音频谱f2,并根据能量分布状态识别出每个字wo的字音信号sp1~sp7。在图3中,对于语音波形f1,横轴为时间(秒),纵轴为振幅(分贝);对于声音频谱f2,横轴为时间(秒);纵轴为频率(赫兹(hz))。然后,分析单元120再根据每个字wo的字音信号sp中的能量分布状态识别出浊音信号区段z2与清音信号区段z1。
54.在步骤s23的一实施例中,调整单元130是以固定间隔移除一个原始音框的方式从浊音信号区段z2移除音框调整量的原始音框,以形成相对于原始语音信号si语速变快的调整后语音信号so。其中,调整单元130是对其音框总量大于音框调整量的浊音信号区段z2进行音框删除的声音信号处理。
55.举例来说,假设音框调整量为每个字删除20个原始音框。当一个字wo的字音信号sp1的浊音信号区段z2有100个原始音框时,调整单元130即对此浊音信号区段z2进行每间隔5个原始音框删除1个原始音框的声音信号处理。
56.在一些实施例中,调整单元130可依据总调整时长、单位音框时长以及处理数量(即字音信号sp1~sp7中具有浊音信号区段z2的字音信号的数量)来计算出每个字wo待移除的原始音框的音框调整量,然后再从每个具有浊音信号区段z2的字音信号中删除音框调整量的原始音框。在一些实施例中,在音框调整量后,调整单元130会先确认具有浊音信号区段z2的字音信号其浊音信号区段z2的音框数量是否均大于当前的音框调整量。于均大于
时,调整单元130才进行音框删除。反之,调整单元130排除小于的字音信号以获得新的处理数量并重新计算音框调整量。
57.在步骤s23的另一实施例中,调整单元130是以固定间隔插入一音框(以下称补充音框)的方式插入音框调整量的补充音框至浊音信号区段z2,以形成相对于原始语音信号si语速变慢的调整后语音信号so。
58.举例来说,假设音框调整量为每个字增加20个补充音框。当一个字wo的字音信号sp1的浊音信号区段z2有100个原始音框时,调整单元130即对此浊音信号区段z2进行每5个原始音框插入1个补充音框的声音信号处理。
59.在一些实施例中,插入的补充音框相关于此浊音信号区段z2中与插入位置相邻的至少一原始音框。在一实施例中,插入的补充音框可为此浊音信号区段z2中与插入位置相邻的原始音框的平均。例如,承前例,调整单元130在浊音信号区段z2的第5个原始音框与第6个原始音框之间插入由第5个原始音框与第6个原始音框平均所获的补充音框。在另一实施例中,插入的补充音框可为此浊音信号区段z2中插入位置的前一原始音框。例如,承前例,调整单元130在浊音信号区段z2的第5个原始音框与第6个原始音框之间插入通过复制第5个原始音框所得的补充音框。在又一实施例中,插入的补充音框可为此浊音信号区段z2中插入位置的下一原始音框。例如,承前例,调整单元130在浊音信号区段z2的第5个原始音框与第6个原始音框之间插入通过复制第6个原始音框所得的补充音框。换言之,调整单元130可以视实际情况调整每间隔多少音框移除或插入一至多个音框的方式,本发明并非为限制。
60.在一些实施例中,语速调整系统10可进一步根据调整后语音信号so与一动态影像生成一口述影像。其中,调整后语音信号对应于动态影像中的无声内容。在一些实施例中,动态影像可以是无声连续图片(如,gif等)或是原始影音视频(如,电影或动画等),而产生的口述影像则对应为有声连续图片(如,有声gif等)或是口述影音视频(如,口述电影或口述动画等)。
61.在一些实施例中,原始语音信号si与调整后语音信号so个别可用以提供原始影音视频中的一段无声影像的影像内容(即,无声内容)的事件描述。于此,无声影像是指影像内容中没有人在讲话也没有具有剧情上意义的音效声(如,开门声、或车辆靠近声等)。换言之,原始语音信号si与调整后语音信号so是以不同语速提供对此段无声影像中角色动作及/或场景变化等事件的变化进行语音描述。
62.在一些实施例中,请参照图4,语速调整系统10可更包括:影音处理单元180。影音处理单元180耦接储存单元110与调整单元130。于此,参照图4及图5,影音处理单元180能根据调整后语音信号so与原始影音视频vi生成口述影音视频vo(步骤s26)。
63.在步骤s21的一些实施例中,原始语音信号vi与总调整时长n1可由耦接语速调整系统10的外部装置提供,及/或使用者经由使用者介面输入至语速调整系统10。
64.在一些实施例中,请参照图4,语速调整系统10可更包括:转换单元140以及判断单元150。转换单元140耦接储存单元110,且判断单元150耦接转换单元140、分析单元120与调整单元130。
65.在步骤s21的一些实施例中,参照图4及图5,转换单元140接收对应无声内容的描述文本xl(步骤s11),并且将描述文本xl转换为原始语音信号si(步骤s12)。其中,描述文本
xl内记录有以此些字wo所构成的事件描述,并且此事件描述是叙述原始影音视频vi中的无声内容。
66.于转换后,转换单元140会将生成的原始语音信号si暂存于储存单元110,并且判断单元150会比较原始语音信号si的总时长与无声内容的总时长tt(步骤s13)。
67.在一些实施例中,判断单元150通过比较步骤(步骤s13)确认原始语音信号si的总时长是否大于无声内容的总时长tt(步骤s14)。
68.于原始语音信号si的总时长大于无声内容的总时长tt时,判断单元150会计算原始语音信号si的总时长与无声内容的总时长tt之间的时间差以得到总调整时长n1(步骤s15),并提供给调整单元130。并且,判断单元150还会致能分析单元120开始对生成的原始语音信号si进行分析,让调整单元130根据总调整时长n1及分析结果生成相对于原始语音信号si语速较快的调整后语音信号so(即,接续执行步骤s22~s24)。
69.于原始语音信号si的总时长不大于无声内容的总时长tt时,判断单元150则不会致能分析单元120(即不接续执行步骤s22~s24)。此时,若语速调整系统10具有影音处理单元180,判断单元150则会致使影音处理单元180根据原始语音信号si与原始影音视频vi生成口述影音视频vo(步骤s26)。
70.在一些实施例中,参照图4及图6,判断单元150通过比较步骤(步骤s13)确认原始语音信号si的总时长是否等于无声内容的总时长tt(步骤s14’)。
71.于原始语音信号si的总时长不等于无声内容的总时长tt时,判断单元150会计算原始语音信号si的总时长与无声内容的总时长tt之间的时间差以得到总调整时长n1(步骤s15),并提供给调整单元130。并且,判断单元150还会致能分析单元120开始对生成的原始语音信号si进行分析,以致于调整单元130根据总调整时长n1及分析结果生成调整后语音信号so(即,接续执行步骤s22~s24)。其中,于原始语音信号si的总时长大于无声内容的总时长tt时,调整单元130会生成相对于原始语音信号si语速较快的调整后语音信号so(步骤s24)。于原始语音信号si的总时长小于无声内容的总时长tt时,调整单元130会生成相对于原始语音信号si语速较慢的调整后语音信号so(步骤s24)。
72.于原始语音信号si的总时长等于无声内容的总时长tt时,判断单元150则不会致能分析单元120(即不接续执行步骤s22~s24)。此时,若语速调整系统10具有影音处理单元180,判断单元150则会致使影音处理单元180根据原始语音信号si与原始影音视频vi生成口述影音视频vo(步骤s26)。
73.在一些实施例中,影音处理单元180能以混音、取代、或关联等方式将语音信号(即原始语音信号si或调整后语音信号so)与原始影音视频vi结合而形成以语音信号作为无声内容的音频的口述影音视频vo。
74.在一实施例中,影音处理单元180接收原始影音视频vi并将原始影音视频vi分离为原始音轨与无声影像视频。接着,影音处理单元180将原始音轨与语音信号(即原始语音信号si或调整后语音信号so)混音以形成调整后音轨,然后通过同步调整后音轨与无声影像视频来将调整后音轨与无声影像视频结合成口述影音视频vo。
75.在另一实施例中,影音处理单元180接收原始影音视频vi并将原始影音视频vi分离为原始音轨与无声影像视频。接着,影音处理单元180以语音信号取代原始音轨中对应无声内容的播放时间的音轨区段以形成调整后音轨,然后通过同步调整后音轨与无声影像视
频来将调整后音轨与无声影像视频结合成口述影音视频vo。
76.在又一实施例中,影音处理单元180接收原始影音视频vi并找出原始影音视频vi中无声内容对应的音轨区段。接着,影音处理单元180建立语音信号对此音轨区段的替代信号,并产生含有原始影音视频vi、语音信号以及替代信号的口述影音视频vo。假设无声内容对应的音轨区段在原始音轨中的第一播放时间到第二播放时间之间。此时,在口述影音视频vo的播放过程中,在第一播放时间时会触发替代信号而由执行原始音轨改为执行语音信号,直到第二播放时间再切回从原始音轨中第二播放时间的位置接续执行原始音轨。
77.在一些实施例中,于调整后语音信号so生成后可先进行语义识别,并且于调整后语音信号so的语义可识别时才输出调整后语音信号so。
78.在一些实施例中,请参照图4,语速调整系统10可更包括:识别单元160与更新单元170。识别单元160耦接调整单元130与更新单元170。
79.参照图4与图5或图4与图6,于调整单元130生成调整后语音信号so后,识别单元160会先侦测调整后语音信号so的语义(步骤s25),以确认语义是否可识别(即确认调整后语音信号so后所播放出的语音的内容是否能识别)。于此,语义侦测技术为本领域的技术人员所熟知,故于此不再赘述。
80.于语义不为可识别时,识别单元160不输出调整后语音信号so,并且致使更新单元170更新描述文本以减少构成事件描述的字数(步骤s27)。然后,更新单元170将更新后的描述文本提供给转换单元140进行转换(即接续执行步骤s12)。此时,若语速调整系统10具有影音处理单元180,识别单元160则不会将生成的调整后语音信号so输出给影音处理单元180。
81.于语义可识别时,识别单元160才输出调整后语音信号so。此时,若语速调整系统10具有影音处理单元180,识别单元160会将调整后语音信号so输出给影音处理单元180以进行影音处理(即执行步骤s26)。
82.在一些实施例中,储存单元110、分析单元120、调整单元130、转换单元140、判断单元150、识别单元160、更新单元170以及影音处理单元180能以单个或多个处理组件实现。
83.在一些实施例中,原始语音信号si与调整后语音信号so可提供无声连续图片中的无声内容的对应语音。换言的,原始语音信号si与调整后语音信号so是提供相同内容但不同语速的语音。举例来说,无声连续图片可呈现单字或句子的发音的口型变化,而原始语音信号si与调整后语音信号so则提供此单字或句子的发音。
84.在一些实施例中,请参照图7,语速调整系统10可更包括:合并单元190。合并单元190耦接调整单元130。参照图7及图8,合并单元190接收一无声连续图片mi,并且通过同步调整后语音信号so与无声连续图片mi来将调整后语音信号so与无声连续图片mi结合成一有声连续图片mo(步骤s26’)。
85.在一些实施例中,储存单元110、分析单元120、调整单元130以及合并单元190能以单个或多个处理组件实现。
86.在一些实施例中,储存单元110能由单个或多个记忆体实现。前述的处理组件可为微处理器、微控制器、中央处理器、可编程逻辑控制器、逻辑电路、类比电路、数位电路或任何基于操作指令操作信号的类比和/或数位装置。
87.在一些实施例中,任一实施例的语速调整方法可由一电脑程式产品实现,以致于
当电脑载入程式并执行后可完成任一实施例的语速调整方法。在一些实施例中,电脑程式产品可为非暂态记录媒体,而上述程式则储存在非暂态记录媒体中供电脑载入。在一些实施例中,上述程式本身即可为电脑程式产品,并且经由有线或无线的方式传输至电脑中。
88.综上所述,任一实施例的语速调整方法适用于调整语音信号的语速,以提供满足时间限制的音档,进而减少重复录音的次数,并大幅减少音档的制作成本。
89.当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。