内存故障的修复方法、cpu、os、bios及服务器
技术领域
1.本技术涉及服务器技术领域,具体而言,本技术涉及一种内存故障的修复方法、cpu、os、bios及服务器。
背景技术:
2.内存存储单元中存在一定的冗余空间,当内存中的存储单元中出现异常的时候,可以采用内存中冗余的单元替换,出现异常的存储单元,将异常的单元进行隔离和替换,从而确保服务器系统的正常运行。传统的出错单元的记录和替换的方法,会影响到业务的正常运行,在记录的错误地址时候造成业务的抖动;在下一次启动修复异常单元的时候,不可预期的加长服务器的启动时间。
技术实现要素:
3.本发明实施例提供一种克服上述问题或者至少部分地解决上述问题的内存故障的修复方法、cpu、os、bios及服务器。
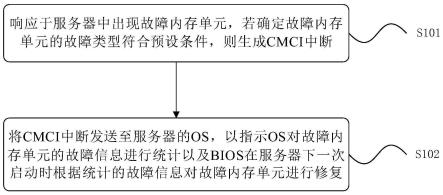
4.第一方面,提供了一种内存故障的修复方法,应用于cpu,该方法包括:
5.响应于服务器中出现故障内存单元,若确定故障内存单元的故障类型符合预设条件,则生成cmci中断;
6.将cmci中断发送至服务器的os,以指示os对故障内存单元的故障信息进行统计以及bios在服务器下一次启动时根据统计的故障信息对故障内存单元进行修复。
7.第二方面,提供了一种内存故障的修复方法,应用于bios,该方法包括:
8.在服务器启动后,获取预设的故障地址列表,故障地址列表中包括服务器在上一次启动期间的故障内存单元的故障信息;
9.对故障地址列表中包括的故障内存单元进行ppr修复,并对故障内存单元设置相应的smt执行信息,smt执行信息用于指示对相应的故障内存单元是否执行smt以及执行的smt的模式;
10.在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt;
11.其中,smt的不同模式对应执行的修复算法的个数不同;
12.故障地址列表中存在os响应于cpu发送的cmci中断统计的故障信息,cmci中断是cpu响应于服务器中出现故障内存单元,确定故障内存单元的故障类型符合预设条件生成的。
13.第三方面,提供一种内存故障的修复方法,应用于os,修复方法包括:
14.响应于接收到服务器中的cpu发送的cmci中断,确定cmci中断对应故障内存单元的目标故障信息;
15.获取预设的故障地址列表,故障地址列表中包括服务器在本次启动期间已出现的故障内存单元对应的故障信息以及故障次数;
16.根据目标故障信息对故障地址列表进行更新,以指示bios在服务器下一次启动时
根据更新后的故障地址列表对故障内存单元进行修复;
17.其中,cmci中断的类型是cpu根据故障内存单元的故障类型符合预设条件生成的。
18.第四方面,提供了一种服务器中的cpu,包括:
19.cmci中断生成模块,用于响应于服务器中出现故障内存单元,若确定故障内存单元的故障类型符合预设条件,则生成cmci中断;
20.cmci中断发送模块,用于将cmci中断发送至服务器的os,以指示os对故障内存单元的故障信息进行统计以及bios在服务器下一次启动时根据统计的故障信息对故障内存单元进行修复。
21.第五方面,提供了一种服务器中的bios,包括:
22.列表获取模块,用于在服务器启动后,获取预设的故障地址列表,故障地址列表中包括服务器在上一次启动期间的故障内存单元的故障信息;
23.ppr修复模块,用于对故障地址列表中包括的故障内存单元进行ppr修复,并对故障内存单元设置相应的smt执行信息,smt执行信息用于指示对相应的故障内存单元是否执行smt以及执行的smt的模式;
24.smt修复模块,用于在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt;
25.其中,smt的不同模式对应执行的修复算法的个数不同;
26.故障地址列表中存在os响应于cpu发送的cmci中断统计的故障信息,cmci中断是cpu响应于服务器中出现故障内存单元,确定故障内存单元的故障类型符合预设条件生成的。
27.第六方面,提供了一种服务器中的os,包括:
28.cmci中断响应模块,用于响应于接收到服务器中的cpu发送的cmci中断,确定cmci中断对应故障内存单元的目标故障信息;
29.第一故障列表获取模块,用于获取预设的故障地址列表,故障地址列表中包括服务器在本次启动期间已出现的故障内存单元对应的故障信息以及故障次数;
30.第一列表更新模块,用于根据目标故障信息对故障地址列表进行更新,以指示bios在服务器下一次启动时根据更新后的故障地址列表对故障内存单元进行修复;
31.其中,cmci中断的类型是cpu根据故障内存单元的故障类型符合预设条件生成的。
32.第七方面,本发明实施例提供一种服务器,包括如第四方面所提供的cpu、第五方面所提供的bios以及第六方面所提供的os。
33.第八方面,本发明实施例提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行程序时实现如第一、第二或第三方面所提供的方法的步骤。
34.第九方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一、第二或第三方面所提供的方法的步骤。
35.第十方面,本发明实施例提供一种计算机程序,该计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中,当计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行实现如第一、第二或第三方面所提供的方法的步骤。
36.本发明实施例提供的内存故障的修复方法、cpu、os、bios及服务器,在服务器中出现故障内存单元时,cpu若确定故障内存单元的故障类型符合预设条件,则生成cmci中断,由于cmci中断不会导致cpu的暂停,因此避免了现有技术中因生成smi中断导致的网络丢包的问题,在服务器下一次启动后bios运行阶段,bios获取预设的故障地址列表,首先对故障地址列表中的故障内存单元进行ppr修复,在修复的通知对故障内存单元是否执行smt以及执行的smt的模式进行标记,在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt,由于本技术实施例的smt的不同模式对应执行的修复算法的个数不同,不再向现有技术那样执行全量(即所有修复算法)的smt,提升了修复效率。
附图说明
37.为了更清楚地说明本技术实施例中的技术方案,下面将对本技术实施例描述中所需要使用的附图作简单地介绍。
38.图1为本技术实施例应用于cpu侧的内存故障的修复方法的流程示意图;
39.图2为本技术实施例的作为ce处理的故障类型的示意图;
40.图3为本技术实施例的内存故障的修复方法的流程示意图;
41.图4为本技术实施例的bios侧的内存故障的修复方法的流程示意图;
42.图5为本技术实施例的bios修复的逻辑示意图;
43.图6为本技术实施例的bios更新故障地址列表的流程示意图;
44.图7为本技术实施例os侧的内存故障的修复方法的流程示意图;
45.图8为本技术实施例的cpu和os侧的内存故障的修复方法的流程示意图;
46.图9为本技术实施例提供的一种cpu的结构示意图;
47.图10为本技术实施例提供的一种bios的结构示意图;
48.图11为本技术实施例提供的一种os的结构示意图;
49.图12为本技术实施例提供的一种电子设备的结构示意图。
具体实施方式
50.下面详细描述本技术的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本技术,而不能解释为对本发明的限制。
51.本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”和“该”也可包括复数形式。应该进一步理解的是,本技术的说明书中使用的措辞“包括”是指存在特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
52.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
53.首先对本技术涉及的几个名词进行介绍和解释:
54.1、管理控制器(baseboard management controller,bmc),它可以在机器未开机的状态下,对机器进行固件升级、查看机器设备等一些操作。
55.2、互联网数据中心(internet data center,idc)是指一种拥有完善的设备(包括高速互联网接入带宽、高性能局域网络、安全可靠的机房环境等)、专业化的管理、完善的应用的服务平台。
56.3、系统管理类型中断(system management interrupt,smi),为了让软硬件设计者们更容易设计出符合需求的中断程序,cpu多提供了smi系统管理中断。使用时cpu要进入系统管理模式system management mode(smm)中,cpu在进入smm前,会把寄存器的值存储smram中,再将程序跳转到smi entry point去执行,处理完后再利用rsm指令跳转回原来的地方继续执行,同时恢复cpu寄存器的值。
57.4、可矫正的错误(corrected error,ce),可以通过软件或者硬件等特定的技术能够纠正的错误。举个例子来说,当内存检查遇到了错误的时候,当检查到的错误是1bit的时候,可能就是因为校验码错误导致的,这时候cpu可以对其进行纠正,不会影响系统的任何进程,这种情况就是可矫正错误。
58.5、不可矫正的错误(uncorrected error,uce),硬件或者软件不能直接处理恢复的错误。同样按照上面的例子来讲,当发生多bit的错误时候,就会产生uncorrected error,系统硬件不能直接处理恢复,这种错误就是uncorrected error。发生这种错误,或多或少会对系统产生影响。
59.6、已修复的机器检查类型中断(corrected machine check interrupt,cmci)。
60.7、ucna:uncorrected no acti/on required不可修复的,也不需要额外的处理的事件。该类ucr不会通过mce(machine check error)进行通知,而是按照corrected machine check error的方式报告给系统软件。ucna意味着系统都的某些数据损坏了,但是这些坏数据还没有被使用,并且处理器的状态是有效的,所以可能继续正常执行本处理器的代码。ucna不需要系统软件做任何的动作,就可以继续执行。
61.8、os:operating system操作系统。
62.9、bios:basic input/output system基本的输入输出系统。
63.10、smt:smart test,在bios启动阶段,执行的一种内存异常扫描检测技术。
64.11、内存地址,可以表示为[socket:imc:rank:bg:ba:row:col]:
[0065]
socket,指内存单元所在的cpu的插槽的编号;
[0066]
imc:即integrated memory controller,是cpu上集成的内存控制器的编号;
[0067]
rank:是连接到同一个cs(chip select,片选)的所有内存颗粒,是一个内存颗粒组的编号;
[0068]
ba,bank address一个颗粒内部划分出了多个存储库,每一个存储库叫一个bank,访问的时候指定地址称之为bank address;
[0069]
bg,bank group,bank分成的组叫bankgroup;内存的数据是以位(bit)为单位写入一张大的矩阵中,每个内存单元格称为cell,只要指定一个行(row),再指定一个列(column),就可以准确地定位到某个内存单元。
[0070]
12、物理地址(physical address,pa),加载到内存地址寄存器中的地址,内存单元的真正地址,它在总线地址上以电子行驶存在,使得数据总线可以访问主存的某个特定
存储单元的内存地址。物理地址是明确的、最终用在总线上的编号,不必转换,不必分页,也没有特权级检查(no translati/on,no paging,no privilege checks)。
[0071]
13、智能平台管理接口(intelligent platform management interface,ipmi)原本是一种intel架构的企业系统的周边设备所采用的一种工业标准。ipmi亦是一个开放的免费标准。可以利用ipmi监视服务器的物理健康特征,如温度、电压、风扇工作状态、电源状态等。
[0072]
现有的内存故障的修复方法主要包括ppr技术和smt技术。
[0073]
对于ppr(post package repair,ppr)技术,每一次内存存储单元(简称内存单元)发生故障的时候,为了将故障内存单元的地址解析和存储下来,需要生成一个smi中断来处理这一笔错误。但是smi中断会将所有的cpu core停住,一个典型的smi中断的处理时间是100毫秒(milliseconds),按照100ms估算,在高性能场景中,会造成i/o抖动,网络大量丢包等业务受损的情况出现。
[0074]
ppr执行修复的时候,依照内存单元出错的阈值触发内存修复,但是ppr只能记录到最后一次故障的内存的地址,替换修复的也是最后一次内存出错的单元。如果在达到阈值以前,有多个内存单元出错,或者前几次是另外的内存单元出错,那么对最后一次出错的单元进行修复,没有达到内存修复的全部功能。
[0075]
对于smt技术,在每次启动的过程中,需要对内存进行扫描,执行一次full test完整测试的时间,大概需要10分钟时间,意味着每次启动的启动时间都需要加10分钟,在idc里面,如果遇到机房掉电,服务器再次拉起服务,所有的服务器加长10分钟的启动时间,业务不能快速恢复,现网不能接受。并且smt技术,是在服务器启动阶段对内存进行扫描,由于业务模型不一样,smt扫出来的内存地址和运行业务实际出错的内存单元可能不一致,进而造成在smt阶段替换的内存单元不是真正出错的内存单元。
[0076]
本技术提供的内存故障的修复方法、装置、电子设备和计算机可读存储介质,旨在解决现有技术的如上技术问题。
[0077]
下面以具体地实施例对本技术的技术方案以及本技术的技术方案如何解决上述技术问题进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例中不再赘述。下面将结合附图,对本技术的实施例进行描述。
[0078]
请参见图1,其实例性地示出了本技术实施例应用于cpu侧的内存故障的修复方法的流程示意图,如图所示,包括:
[0079]
s101、响应于服务器中出现故障内存单元,若确定故障内存单元的故障类型符合预设条件,则生成cmci中断;
[0080]
本技术实施例的服务器可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn(content delivery network,内容分发网络)、以及大数据和人工智能平台等基础云计算服务的云服务器,本技术实施例对此不作限定。
[0081]
区别于现有技术中cpu在确定服务器中出现故障内存单元后即生成smi中断的方式,本技术实施例的cpu在确定服务器中出现故障内存单元后,会确定故障内存单元的故障类型,若故障类型符合预设条件,则生成cmci中断,cmci类型的中断不会阻塞服务器中其他
的cpu,从而克服了现有技术中生成smi中断造成所有的cpu暂停的弊端。
[0082]
服务器运行时,内存主要的故障有内存巡检错误和读写错误两种,每种错误均可分为uce和ce。本技术实施例机遇内存巡检的uce由于不影响服务器的运行,因此可以将内存巡检的uce配置成ce,即当成ce进行处理,而内存读写的ce中,ucna类型的故障也不会影响服务器的运行,也可以当成ce进行处理。
[0083]
请参见图2,在本技术实施例中,若故障内存单元的故障类型为内存读写ce、内存巡检ce、内存巡检uce或者属于ucna类型的内存读写uce,则确定故障内存单元的故障类型符合预设条件。s102、将cmci中断发送至服务器的os,以指示os对故障内存单元的故障信息进行统计以及bios在服务器下一次启动时根据统计的故障信息对故障内存单元进行修复。
[0084]
本技术实施例将cmci中断发送至os,使得os能够对故障内存单元的故障信息进行统计,从而在服务器下一次启动时,由bios根据统计的故障信息对故障内存单元进行修复。
[0085]
本技术实施例的故障内存单元的故障信息包括故障内存单元的物理地址、内存地址以及故障类型中的至少一种。
[0086]
当os获知内存单元出现故障时,os首先获得的是故障内存单元的物理地址,由于物理地址和内存地址存在映射关系,且bios需要根据内存地址在内存中找寻故障内存单元,因此本技术实施例的os还需要基于物理地址确定内存地址,以使得bios在获得故障信息后直接根据内存地址确定并修复故障内存单元。
[0087]
为了本技术实施例的bios能够针对性地对故障内存单元进行修复时,os还可以在故障信息中还可以记录故障类型。例如bios可以根据故障内存单元出现的故障的故障类型,仅基于解决上述故障类型的修复算法对故障内存单元进行修复,避免采用全量的修复算法,可提高修复效率。因此,可选的,本技术实施例的故障信息为物理地址、内存地址以及故障类型构成的三元组。
[0088]
例如,某一故障信息表示为:[addr 1233440;05:04:03:06:03:01:02;内存巡检uce],其中:
[0089]
addr 1233440表示物理地址;
[0090]
05:04:03:06:03:01:02指示了故障内存单元的内存地址,由上述内存地址的概念可知,其:05表示故障内存单元所在的cpu的插槽的编号;04表示上述编号为05的cpu上集成的内存控制器的编号,03表示上述编号为04的内存控制器中内存颗粒组的编号;06表示上述编号为03的内存颗粒组的编号为06的存储库,03表示上述编号为06的存储库中组的编号,01和02表示上述编号为03的组中位于第一行和第二列的内存单元。
[0091]
内存巡检uce即表示该故障内存单元的故障类型为内存巡检uce,可选的,本技术实施例还可以对不同的错误进行编号,从而直接以编号来表示不同的错误,例如内存读写ce编号为a1、内存巡检ce编号为b1、内存巡检uce编号为b2,属于ucna类型的内存读写uce编号为c1,需要注意的是,本技术实施例对于具体的编号规则不作具体限定,可以是阿拉伯数字,也可以是阿拉伯数字和字母的组合,等等。
[0092]
本技术实施例的内存故障的修复方法,通过cpu在服务器中出现故障内存单元时,若确定故障内存单元的故障类型符合预设条件,也就意味这故障类型本身不会影响服务器的运行,因此生成cmci中断,进一步利用cmci中断不会导致cpu的暂停的特性,因此避免了现有技术中因生成smi中断导致的网络丢包的问题。
[0093]
在上述各实施例的基础上,作为一种可选实施例,根据服务器中出现故障内存单元,之后还包括:
[0094]
若确定故障内存单元的故障类型不符合预设条件,则生成smi中断;
[0095]
将smi中断发送至服务器的bios,以指示bios对故障内存单元的故障信息进行统计以及在服务器下一次启动时根据统计的故障信息对故障内存单元进行修复。
[0096]
当故障内存单元的故障类型为不属于ucna类型的内存读写uce,例如为软件可恢复操作可选(software recoverable action optional,srao)或者需要软件可恢复的操作(software recoverable action required,srar)的uce时,可确定故障内存单元的故障类型不符合预设条件。当故障类型不符合预设条件时,表示故障会影响服务器的运行,这个时候发送smi中断至os会导致cpu出现暂停,因此本技术实施例将smi发送至bios,能够保持cpu继续运行。
[0097]
请参见图3,其示例性地示出了本技术实施例的内存故障的修复方法的流程示意图,如图所示,包括:
[0098]
s201、cpu响应于服务器中出现故障内存单元,判断内存故障单元的故障类型,若确定故障内存单元的故障类型符合预设条件,则执行步骤s202,若确定故障内存单元的故障类型不符合预设条件,则执行步骤s202’。
[0099]
需要说明的是,内存管理器作为cpu的子部件,能够对内存单元进行管理,其中就包括对故障类型的确定,因此当内存单元出现故障时,cpu能够第一时间获知故障内存单元以及该故障内存单元的故障类型。
[0100]
当故障内存单元的故障类型为内存读写ce、内存巡检ce、内存巡检uce或者属于ucna类型的内存读写uce时,确定故障内存单元的故障类型符合预设条件,执行步骤s202,当故障内存单元的故障类型不为内存读写ce、内存巡检ce、内存巡检uce或者属于ucna类型的内存读写uce中的任意一种时,确定故障内存单元的故障类型不符合预设条件,执行步骤s202’。
[0101]
s202、cpu生成cmci中断,将cmci中断发送至服务器的os,执行s203;
[0102]
本技术实施例的cpu在确定故障内存单元的故障类型符合预设条件时,视作故障内存单元的故障不会对服务器的运行造成影响,利用cmci中断不会影响os正常运行的特性,生成cmci中断发送os,使得os能够在正常运行的同时对故障内存单元的故障信息进行记录。
[0103]
s202’、cpu生成smi中断,将smi中断发送至服务器的bios,执行s203’;
[0104]
服务器运行时,还有一些会影响os正常运行的内存uce,对于这一类型的uce,cpu会确定为故障类型不符合预设条件,并且会生成smi中断发送至bios,以避免对os的正常运行造成影响,bios接收到smi中断后,也会对故障内存单元的故障信息进行记录,以便在服务器下一次启动时对故障内存单元进行修复。
[0105]
s203、os将故障内存单元的故障信息统计至故障地址列表,执行s204;
[0106]
本技术实施例的os可以预先配置与中断对应的服务,当os接收到cmci中断,则执行该服务,该服务具体用于获取触发该中断产生的故障内存单元的地址(包括内存地址和物理地址)以及故障类型,并作为故障信息统计至故障地址列表中,也就是说,本技术实施例的故障地址列表是一个用于存在服务器在运行过程中各故障内存单元的故障信息的列
表,从而在服务器重启时,由bios根据故障地址列表确定各故障内存单元的内存地址以及故障类型,并针对性地进行修复。
[0107]
s203’、bios将故障内存单元的故障信息统计至故障地址列表,执行s204;
[0108]
与os侧类似的,bios也可以预先配置与中断对应的服务,当bios接收到smi中断,则执行该服务,该服务具体用于获取触发该中断产生的故障内存单元的故障信息以及故障类型,并作为故障信息统计至故障地址列表中,从而在服务器重启时,由bios根据故障地址列表确定各故障内存单元的内存地址以及故障类型,并针对性地进行修复。
[0109]
s204、bios在服务器下一次启动时根据故障地址列表中统计的故障信息对故障内存单元进行修复。
[0110]
故障内存单元的修复只能在bios启动的过程中进行,本技术实施例的bios在启动的时候,可以依照故障地址列表是否为空,确认是否执行ppr修复,以及依照既有的策略,确定是否执行smt内存修复以及执行何种模式的smt内存修复。具体的,当故障地址列表为空,表示服务器上一次启动过程中没有出现内存故障,因此不需要执行ppr修复,当故障地址列表为空,则先执行ppr修复,并对各故障内存单元标记是否执行smt内存修复以及何种模式的smt内存修复,在ppr修复后,对于标记不执行smt内存修复或者没有标记执行smt内存修复的故障内存单元则进行跳过,对于标记执行smt内存修复的故障内存单元,则进一步根据标记的具体模式执行smt内存修复。
[0111]
进一步地,本技术实施例提出了多种smt的执行模式,不同模式的smt对于服务器的启动时间的影响不一样:完整模式的smt(基于全量的修复算法)需要服务器的启动时间增加十分钟以上,一般模式的smt(基于少部分的修复算法)需要几分钟的额外启动时间,快速smt模式(基于极少部分的修复算法),只需要几十秒的额外启动时间,本技术实施例可以灵活调整不同的smt模式,使得服务器的启动时间相比现有技术进行缩短,提高修复效率,缩短服务器启动时间。
[0112]
请参见图4,其示例性地示出了本技术实施例的bios侧的内存故障的修复方法的流程示意图,如图所示,包括:
[0113]
s301、在服务器启动后,获取预设的故障地址列表,故障地址列表中包括服务器在上一次启动期间的故障内存单元的故障信息。
[0114]
请参见表1,其示例性地示出了本技术实施例的故障地址列表,表1中共示出了4个三元组信息以及对应的故障次数,其中第1、2和4的三元组信息的物理地址和内存地址一致,也即对应的是同一个故障内存单元,只不过3个三元组中的故障类型存在差异。从表1可以看出,当三元组信息中只要出现至少一元信息的差异,在故障地址列表中会被视为不同的三元组。
[0115]
物理地址内存地址故障类型故障次数addr 123344005:04:03:06:03:01:02内存巡检uce10addr 124164005:05:01:01:03:04:07内存读写ce6addr 123344005:04:03:06:03:01:02内存巡检ce3addr 123344005:04:03:06:03:01:02内存读写ce2
[0116]
表1故障地址列表
[0117]
需要说明的是,本技术实施例的故障地址列表中存在os响应于cpu发送的cmci中
断统计的故障信息。由上述实施例可知,cmci中断是cpu响应于服务器中出现故障内存单元,确定故障内存单元的故障类型符合预设条件生成的。
[0118]
本技术实施例的bios获取故障地址列表存在两种方式,当故障地址列表存储在bios的非易失性随机访问存储器(non-volatile random access memory,nvram)时,则bios从nvram读取,当故障地址存储在bmc时,可以通过ipmi方式从基板管理控制器(baseboard manager controller,bmc)读取。
[0119]
s302、对故障地址列表中包括的故障内存单元进行ppr修复,并对故障内存单元设置相应的smt执行信息,smt执行信息用于指示对相应的故障内存单元是否执行smt以及执行的smt的模式。
[0120]
本技术实施例的故障信息可以包括故障内存单元的物理地址和内存地址,从而可以根据故障内存单元的物理地址和内存地址进行ppr修复:使用内存的冗余区,进行最小粒度的替换(比如内存单元所在的行),并且检查和记录是否替代成功。
[0121]
本技术实施例在ppr以后执行smt的意义在于:ppr以及smt都是在bios运行阶段完成,而bios运行的时候,系统还不能跑业务,此时进行smt不会影响到业务处理,避免了在服务器启动后运行业务时再执行smt影响业务感知的弊端,并且smt也能够扫描和发现故障,所以对于内存而言,能够尽量修复有问题的存储单元。
[0122]
更重要的是,本技术实施例还可以进一步判断是否需要执行的smt,以及smt的模式,本技术实施例smt的不同模式对应执行的修复算法的个数不同,例如采用全量的修复算法进行修复,或者部分修复算法进行修复。
[0123]
s303、在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt。
[0124]
本技术实施例的内存故障的修复方法在服务器下一次启动后bios运行阶段,获取预设的故障地址列表,首先对故障地址列表中的故障内存单元进行ppr修复,在修复的通知对故障内存单元是否执行smt以及执行的smt的模式进行标记,在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt,由于本技术实施例的smt的不同模式对应执行的修复算法的个数不同,不再向现有技术那样执行全量(即所有修复算法)的smt。
[0125]
在上述各实施例的基础上,如果用户如果怀疑内存异常,需要执行修复,也可以手动指定执行smt以及smt的模式。指定马上下一次启动或者随下一次启动执行smt。
[0126]
在上述各实施例的基础上,作为一种可选实施例,故障信息中包括故障类型,故障地址列表中还包括故障内存单元的故障次数,从而本技术实施例的bios可以根据故障的类型以及次数判断执行smt的模式,具体的:
[0127]
若故障内存单元的故障类型为ce(包括读写ce和巡检ce),且故障次数小于第一阈值,则执行第一模式的smt;
[0128]
若故障内存单元的故障类型为ce,且故障次数位于第一阈值和第二阈值之间,则执行第二模式的smt,第二阈值大于第一阈值;
[0129]
若故障内存单元的故障类型为读写uce或者巡检uce,则执行第三模式的smt;
[0130]
其中,第一模式、第二模式、第三模型的smt对应执行的修复算法的数量依次增多,例如,本技术实施例的第三模式的smt可以是采用全量的修复算法进行修复;第二模式的smt可以采用全量50%的修复算法进行修复,第一模式的smt可以采用全量10%的修复算法
进行修复。
[0131]
本技术实施例还支持其他策略确定smt的模式,例如根据下一次启动的间隔时间以及下一次启动次数确定:
[0132]
若服务器下一次启动的间隔时间小于第一时间阈值,则执行第一模式的smt;
[0133]
若服务器下一次启动的间隔时间位于第一时间阈值和第二时间阈值之间,则执行第二模式的smt;
[0134]
若服务器下一次启动的间隔时间大于第二时间阈值,则执行第三模式的smt;其中,第一模式、第二模式、第三模型的smt对应执行的修复算法的数量依次增多。本技术实施例对于第一时间阈值和第二时间阈值不作具体的限定,例如,第一时间阈值为半年,第二时间阈值为一年。
[0135]
若服务器在预设时间段内的启动次数小于第一次数阈值,则执行第一模式的smt;
[0136]
若服务器在预设时间段内的启动次数位于第一次数阈值和第二次数阈值之间,则执行第二模式的smt;
[0137]
若服务器在预设时间段内的启动次数大于第二次数阈值,则执行第三模式的smt;其中,第一模式、第二模式、第三模型的smt对应执行的修复算法的数量依次增多。本技术实施例对应下一次启动次数不作具体的限定,例如第一次数阈值为5次,第二次数阈值为10次。
[0138]
为了保证在使用较少的修复算法也能够保证较高的修复成功率,本技术实施例可以通过统计多次修复的结果,确定对于各个内存单元的各个故障类型,最有效的若干种修复方法,从而对快速模式(也即第一模式)的smt仅设置数量较少的最有效的修复方法。具体地,本技术实施例可以对每一种故障类型,统计各修复算法统计修复的成功率,通过对成功率进行从大到小进行排序,将排名靠前的第一数量(例如前5%)的修复算法作为第一模式的smt的修复算法,将排名靠前的第二数量(例如前20%)的修复算法作为第二模式的smt的修复算法,将全部修复算法作为第三模式的smt的修复算法。
[0139]
在上述各实施例的基础上,作为一种可选实施例,内存故障的修复方法还包括:将smt执行信息存储在nvram或者bmc中。
[0140]
请参见图5,其示例性地示出了本技术实施例的bios修复的逻辑示意图,如图所示,一方面,可以在服务器启动后当bios运行时,bios从naram或者bmc中获取内存的故障地址列表,如果故障地址列表不为空,表示服务器在上一次启动期间出现了内存故障,依照内存的出错地址,对内存进行ppr修复,同时将smt执行的标志置上,例如当标志位设置为0时,表示不执行smt,设置为1时,表示执行第一模式的smt,设置为2时,表示执行第二模式的smt,等等。
[0141]
另一方面,当用户怀疑内存出现问题,可以通过用户接口,将smt需要执行的标记,以及需要执行的smt的模式配置上,存储在nvram中或者bmc管理控制器中,同时确定是否立即下一次启动,如果判定立即下一次启动,服务器立即下一次启动,再次启动的过程中依照配置执行smt。如果不需要立即下一次启动,smt在下一次服务器下一次启动的过程中,依照配置的模式执行smt。
[0142]
当服务器下一次启动时,bios根据上一次既定的测量,例如启动间隔时间,或者检测到smt的标记被置上,执行扫描,根据扫描出错的地址进行修复,smt执行后流程结束。
[0143]
服务器运行时,还有一些会影响os正常运行的内存uce,对于这一类型的uce,按照以下场景进行内存修复。由于影响os的内存错误,会造成os死机,所以对于影响os运行的uce错误,只能在smm模式中,由bios进行处理。
[0144]
在上述各实施例的基础上,作为一种可选实施例,当cpu发送smi中断时,本技术实施例的bios侧的内存故障的修复方法还包括:
[0145]
s401、响应于接收到服务器中的cpu发送的smi中断,确定smi中断对应故障内存单元的目标故障信息。
[0146]
由上述实施例可知,bios接收到的smi中断是cpu根据内存故障的类型确定的,当cpu确定出现影响os正常运行的内存uce时,就会向bios发送smi中断,bios响应于接收到smi中断,会确定smi中断对应故障内存单元的目标故障信息。
[0147]
bios可以通过扫描mca(machine check architecture)寄存器的方式获得目标故障信息,mca寄存器用于存储检测到的硬件(这里的machine表示的就是硬件)错误,比如系统总线错误、ecc错误。当cpu检测到不可纠正的mce(machine check error)时,就会触发#mc(machine check excepti/on),通常软件会注册相关的函数来处理#mc,在这个函数中会通过读取msr来收集mce的错误信息,然后重启系统。当然由于发生的mce可能是非常致命的,cpu直接重启了,没有办法完成mce处理函数;甚至有可能在mce处理函数中又触发了不可纠正的mce,也会导致系统直接重启。
[0148]
本技术实施例的bios通过mce寄存器可以确定故障内存单元的物理地址和故障类型,然后根据物理地址解析出对应的内存地址([socket:imc:rank:bg:ba:row:col])。
[0149]
s402、获取预设的故障地址列表,故障地址列表中包括服务器在本次启动期间已出现的故障内存单元对应的故障信息以及故障次数。
[0150]
bios获取目标故障信息后,还会获取故障地址列表,具体的,当通过以下两种方式获取:
[0151]
a、读取nvram中的存储的故障地址列表。
[0152]
b、通过ipmi的方式,读取bmc中存储的故障地址列表。
[0153]
应当理解的是,在方式a中,是由bios维护故障地址列表,即由bios创建、更新以及删除故障地址列表中的三元组信息以及相应的计数,而在方式b中,是由bmc维护故障地址列表,即由bmc创建、更新以及删除故障地址列表中的三元组信息以及相应的计数。
[0154]
s403、根据目标故障信息对故障地址列表进行更新;
[0155]
具体地,当故障地址列表中已经存在该目标故障信息时,则对该目标故障信息的计数加1,当故障地址列表中没有该目标故障信息时,则在故障地址列表中新增该目标故障信息,并将计数设置为1。
[0156]
请参见图6,其示例性地示出了本技术实施例bios更新故障地址列表的流程示意图,如图所示,包括:
[0157]
bios响应于smi中断,确定出现故障内存单元的目标故障信息;
[0158]
从存储区域获取预设的故障地址列表:当存储区域为nvram时,读取nvram中的存储的故障地址列表;当存储区域为bmc时,通过ipmi的方式,读取bmc中存储的故障地址列表
[0159]
将故障地址列表中的故障信息与目标故障信息进行对比,查看有无一样的故障信息,若有,则对目标故障信息的计数加1,若没有,则在故障地址列表中加入目标故障信息,
并将目标故障信息的计数更新为1;
[0160]
将更新后的故障地址列表写回存储区域:通过ipmi的方式,将更新后的故障地址列表写回至bmc;或者将更新后的故障地址列表写回至nvram。
[0161]
以表1为例,若目标故障信息为:addr 1233440
[0162]
05:04:03:06:03:01:02内存巡检uce,则表1中的故障次数将由10更新为11,当目标故障信息为addr 1231210 01:02:03:06:03:01:02内存巡检uce时,由于目前表1中并未记录该故障信息,因此故障地址列表将新增一个三元组,并且更新故障次数即为1。
[0163]
请查阅图7,示例性地示出了本技术实施例os侧的内存故障的修复方法的流程示意图,如图所示,包括:
[0164]
s501、响应于接收到服务器中的cpu发送的cmci中断,确定cmci中断对应故障内存单元的目标故障信息。
[0165]
由上述实施例可知,os接收到的cmci中断也是cpu根据内存故障的类型确定的,当cpu确定出现不影响os正常运行的ce或uce时,就会向os发送cmci中断,os响应于接收到cmci中断,会确定smi中断对应故障内存单元的目标故障信息。
[0166]
本技术实施例获取的目标故障信息的方式包括以下至少一种:
[0167]
a、响应于mce通知链上出现mce消息,从mce消息中获得故障内存单元的物理地址以及故障类型,依照内存地址配置的寄存器,计算得到内存地址。
[0168]
当服务器出现内存故障时,服务器会根据故障内存的相关信息生成mce消息,并将mce消息发送到mce通知链上。mce是一种用来报告系统错误的硬件方式。mce消息中一般记录了故障内存单元的物理地址以及故障类型。
[0169]
因此本技术实施例可以创建一个钩子函数挂载到mce的通知链中,从通知链上传入的mce消息的数据结构中,获取到出错的物理地址以及出错的错误类型。依照内存地址配置的寄存器,计算得到内存存储单元的地址信息,也即内存信息。
[0170]
b、周期性读取mce日志,当mce日志中存在新的mce消息,从mce消息中获得出现故障的故障内存单元的物理地址以及故障类型,依照内存地址配置的寄存器,计算得到内存地址。
[0171]
mce日志是记录mce的日志文件,当服务器出现内存故障时,服务器会根据故障内存的相关信息生成mce消息并记录在mce日志中,因此本技术实施例的os也可以周期性地访问mce日志,,获取到出错的物理地址以及出错的错误类型。依照内存地址配置的寄存器,计算得到内存存储单元的地址信息。
[0172]
c、周期性读取os日志中保留的内存故障信息,从内存故障信息中出现故障的故障内存单元的物理地址以及故障类型,依照内存地址配置的寄存器,计算得到内存地址。
[0173]
本技术实施例的os日志包括messages日志以及dmesg日志,messages日志就是系统的日志,记录了各种事件,一般运行所有应用都可以往里面写日志,os日志中会保存内存故障信息,内存故障信息中即包括了故障内存单元的物理地址以及故障类型。有时linux系统或者系统上内存、进程等等会发生一些莫名其妙的问题,比如突然挂掉了,比如突然重启等等。在软件上找不到问题所在,此时应该怀疑硬件或者内核的问题,而这些问题也会记录在dmesg日志中,所以本技术实施例可以从dmesg日志中获取到故障内存单元的物理地址以及故障类型。
[0174]
s502、获取预设的故障地址列表,故障地址列表中包括服务器在本次启动期间已出现的故障内存单元对应的故障信息以及故障次数;
[0175]
本技术实施例可以以两个方式获得故障地址列表,分别为从bios的nvram中获取以及从bmc中获取,具体的包括:
[0176]
通过ipmi的方式,读取bmc中存储的故障地址列表;或者
[0177]
通过输入输出(input/output,i/o)的方式,读取bios的nvram中存储的故障地址列表;
[0178]
通过内存映射的方式,读取bios的nvram中存储的故障地址列表。
[0179]
内存映射文件,是由一个文件到一块内存的映射。本技术实施例的服务器提供了允许应用程序把文件也即故障地址列表映射到一个进程的函数(createfilemapping)。通过调用该进程,即可获得故障地址列表。
[0180]
s503、根据目标故障信息对故障地址列表进行更新,以指示bios在服务器下一次启动时根据更新后的故障地址列表对故障内存单元进行修复。
[0181]
具体地,当故障地址列表中已经存在该目标故障信息时,则对该目标故障信息的计数加1,当故障地址列表中没有该目标故障信息时,则在故障地址列表中新增该目标故障信息,并将计数设置为1。
[0182]
本技术实施例的os侧的内存故障的修复方法,通过响应于cmci中断,能够在不影响cpu运行的情况下确定cmci中断对应故障内存单元的目标故障信息,进一步获取故障地址列表,将本次故障信息更新至故障地址列表中,为bios针对性执行ppr以及smt奠定基础。
[0183]
需要说明的是,根据目标故障信息对故障地址列表进行更新,还包括:
[0184]
通过ipmi的方式,将更新后的故障地址列表写回至bmc;或者
[0185]
通过i/o或内存映射的方式,将更新后的故障地址列表写回至bios的nvram。
[0186]
本技术实施例可以根据故障地址列表原本存储的地址,若原本存储于bmc,则通过ipmi的方式,将更新后的故障地址列表写回至bmc,若存储于bios的nvram,则通过i/o或内存映射的方式,将更新后的故障地址列表写回至bios的nvram。
[0187]
在上述各实施例的基础上,作为一种可选实施例,本技术实施例的cpu和os侧的内存故障的修复方法的流程示意图,如图8所示,包括:
[0188]
当服务器中出现的故障内存单元的故障类型为内存读写ce、内存巡检ce、内存巡检uce或者属于ucna类型的内存读写uce时,cpu均作为ce进行处理,生成cmci中断;
[0189]
os响应于接收到cmci中断,获取故障内存单元的内存地址和物理地址,并结合故障类型生成包含三元组的故障信息;
[0190]
os从bios的nvram或者bmc中读取故障地址列表,并将当前的故障信息写入至故障地址列表中,根据各内存单元的故障次数,对各故障内存的故障信息进行排序;
[0191]
os将更新后的故障地址列表写回到bios的nvram或者bmc中。
[0192]
本技术实施例提供了一种cpu,如图9所示,该装置可以包括:cmci中断生成模块101和cmci中断发送模块102,具体地:
[0193]
cmci中断生成模块101,用于响应于服务器中出现故障内存单元,若确定故障内存单元的故障类型符合预设条件,则生成cmci中断;
[0194]
cmci中断发送模块102,用于将cmci中断发送至服务器的os,以指示os对故障内存
单元的故障信息进行统计以及bios在服务器下一次启动时根据统计的故障信息对故障内存单元进行修复
[0195]
本发明实施例提供的cpu,具体执行上述方法实施例流程,具体请详见上述cpu侧的内存故障的修复方法实施例的内容,在此不再赘述。本发明实施例提供的cpu,通过在服务器中出现故障内存单元时,cpu若确定故障内存单元的故障类型符合预设条件,则生成cmci中断,由于cmci中断不会导致cpu的暂停,因此避免了现有技术中因生成smi中断导致的网络丢包的问题。
[0196]
在一个可能的实现方式中,cmci中断生成模块包括:
[0197]
若故障内存单元的故障类型为内存读写ce、内存巡检ce、内存巡检uce或者属于ucna类型的内存读写uce,则确定故障内存单元的故障类型符合预设条件。
[0198]
在一个可能的实现方式中,cpu还包括:
[0199]
smi中断生成模块,用于若确定故障内存单元的故障类型不符合预设条件,则生成smi中断;
[0200]
smi中断发送模块,用于将smi中断发送至服务器的bios,以指示bios对故障内存单元的故障信息进行统计以及在服务器下一次启动时根据统计的故障信息对故障内存单元进行修复。
[0201]
在一个可能的实现方式中,故障信息包括物理地址、内存地址以及故障类型中的至少一种。
[0202]
本技术实施例提供了一种bios,如图10所示,该装置可以包括:列表获取模块201、ppr修复模块202和smt修复模块203,具体地:
[0203]
列表获取模块201,用于在服务器启动后,获取预设的故障地址列表,故障地址列表中包括服务器在上一次启动期间的故障内存单元的故障信息;
[0204]
ppr修复模块202,用于对故障地址列表中包括的故障内存单元进行ppr修复,并对故障内存单元设置相应的smt执行信息,smt执行信息用于指示对相应的故障内存单元是否执行smt以及执行的smt的模式;
[0205]
smt修复模块203,用于在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt;
[0206]
其中,smt的不同模式对应执行的修复算法的个数不同;
[0207]
故障地址列表中存在os响应于cpu发送的cmci中断统计的故障信息,cmci中断是cpu响应于服务器中出现故障内存单元,确定故障内存单元的故障类型符合预设条件生成的。
[0208]
本发明实施例提供的bios,具体执行上述方法实施例流程,具体请详见上述bios侧的内存故障的修复方法实施例的内容,在此不再赘述。本发明实施例提供的bios,获取预设的故障地址列表,首先对故障地址列表中的故障内存单元进行ppr修复,在修复的通知对故障内存单元是否执行smt以及执行的smt的模式进行标记,在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt,由于本技术实施例的smt的不同模式对应执行的修复算法的个数不同,不再向现有技术那样执行全量(即所有修复算法)的smt,提升了修复效率。
[0209]
在一个可能的实现方式中,故障信息中包括故障类型,故障地址列表中还包括故
障内存单元的故障次数;
[0210]
smt修复模块具体用于:
[0211]
若故障内存单元的故障类型为ce,且故障次数小于第一阈值,则执行第一模式的smt;
[0212]
若故障内存单元的故障类型为ce,且故障次数位于第一阈值和第二阈值之间,则执行第二模式的smt,第二阈值大于第一阈值;
[0213]
若故障内存单元的故障类型为读写uce或者巡检uce,则执行第三模式的smt;
[0214]
其中,第一模式、第二模式、第三模型的smt对应执行的修复算法的数量依次增多。
[0215]
在一个可能的实现方式中,smt修复模块具体用于:
[0216]
若服务器下一次启动的间隔时间小于第一时间阈值,则执行第一模式的smt;
[0217]
若服务器下一次启动的间隔时间位于第一时间阈值和第二时间阈值之间,则执行第二模式的smt;
[0218]
若服务器下一次启动的间隔时间大于第二时间阈值,则执行第三模式的smt;
[0219]
其中,第一模式、第二模式、第三模型的smt对应执行的修复算法的数量依次增多。
[0220]
在一个可能的实现方式中,smt修复模块具体用于:
[0221]
若服务器在预设时间段内的启动次数小于第一次数阈值,则执行第一模式的smt;
[0222]
若服务器在预设时间段内的启动次数位于第一次数阈值和第二次数阈值之间,则执行第二模式的smt;
[0223]
若服务器在预设时间段内的启动次数大于第二次数阈值,则执行第三模式的smt;
[0224]
其中,第一模式、第二模式、第三模型的smt对应执行的修复算法的数量依次增多。
[0225]
在一个可能的实现方式中,bios还包括:
[0226]
smt存储模块,用于将smt执行信息存储在nvram或者bmc中。
[0227]
在一个可能的实现方式中,bios还包括:
[0228]
smi中断接收模块,用于响应于接收到服务器中的cpu发送的smi中断,确定smi中断对应故障内存单元的目标故障信息;
[0229]
第二故障列表获取模块,用于获取预设的故障地址列表,故障地址列表中包括服务器在本次启动期间已出现的故障内存单元对应的故障信息以及故障次数;
[0230]
第二列表更新模块,用于根据目标故障信息对故障地址列表进行更新;
[0231]
其中,中断的类型是cpu根据内存故障的类型确定的。
[0232]
在一个可能的实现方式中,smi中断接收模块具体用于扫描mca寄存器,确定故障内存单元的物理地址和故障类型,依照物理地址解析出对应的内存地址。
[0233]
在一个可能的实现方式中,第二故障列表获取模块具体用于:
[0234]
读取nvram中的存储的故障地址列表;或者
[0235]
通过ipmi的方式,读取bmc中存储的故障地址列表。
[0236]
在一个可能的实现方式中,第二列表更新模块还用于:
[0237]
通过ipmi的方式,将更新后的故障地址列表写回至bmc;或者
[0238]
将更新后的故障地址列表写回至nvram。
[0239]
本技术实施例提供了一种os,如图11所示,该装置可以包括:cmci中断响应模块301、第一故障列表获取模块302和第一列表更新模块303,具体地:
[0240]
cmci中断响应模块301,用于响应于接收到服务器中的cpu发送的cmci中断,确定cmci中断对应故障内存单元的目标故障信息;
[0241]
第一故障列表获取模块302,用于获取预设的故障地址列表,故障地址列表中包括服务器在本次启动期间已出现的故障内存单元对应的故障信息以及故障次数;
[0242]
第一列表更新模块303,用于根据目标故障信息对故障地址列表进行更新,以指示bios在服务器下一次启动时根据更新后的故障地址列表对故障内存单元进行修复;
[0243]
其中,cmci中断的类型是cpu根据故障内存单元的故障类型符合预设条件生成的。
[0244]
本发明实施例提供的os,具体执行上述方法实施例流程,具体请详见上述os侧的内存故障的修复方法实施例的内容,在此不再赘述。本发明实施例提供的os,通过响应于cmci中断,能够在不影响cpu运行的情况下确定cmci中断对应故障内存单元的目标故障信息,进一步获取故障地址列表,将本次故障信息更新至故障地址列表中,为bios针对性执行ppr以及smt奠定基础。。
[0245]
在一个可能的实现方式中,cmci中断响应模块包括:
[0246]
通知链跟踪模块,用于响应于mce通知链上出现mce消息,从mce消息中获得故障内存单元的物理地址以及故障类型,依照内存地址配置的寄存器,计算得到内存地址;
[0247]
mce日志跟踪模块,用于周期性读取mce日志,当mce日志中存在新的mce消息,从mce消息中获得出现故障的故障内存单元的物理地址以及故障类型,依照内存地址配置的寄存器,计算得到内存地址;
[0248]
os日志跟踪模块,用于周期性读取os日志中保留的内存故障信息,从内存故障信息中出现故障的故障内存单元的物理地址以及故障类型,依照内存地址配置的寄存器,计算得到内存地址。
[0249]
在一个可能的实现方式中,第一故障列表获取模块具体用于:
[0250]
通过ipmi的方式,读取bmc中存储的故障地址列表;或者
[0251]
通过i/o或内存映射的方式,读取bios的nvram中存储的故障地址列表
[0252]
在一个可能的实现方式中,第一列表更新模块具体用于:
[0253]
通过ipmi的方式,将更新后的故障地址列表写回至bmc;或者
[0254]
通过i/o或内存映射的方式,将更新后的故障地址列表写回至bios的nvram。
[0255]
本技术实施例提供了一种服务器,包括如上述实施例的cpu、os以及bios。本发明实施例提供的服务器,具体执行上述方法实施例流程,具体请详见上述cpu、bios以及os侧的内存故障的修复方法实施例的内容,在此不再赘述。本发明实施例提供的服务器,在服务器中出现故障内存单元时,cpu若确定故障内存单元的故障类型符合预设条件,则生成cmci中断,由于cmci中断不会导致cpu的暂停,因此避免了现有技术中因生成smi中断导致的网络丢包的问题,在服务器下一次启动后bios运行阶段,bios获取预设的故障地址列表,首先对故障地址列表中的故障内存单元进行ppr修复,在修复的通知对故障内存单元是否执行smt以及执行的smt的模式进行标记,在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt,由于本技术实施例的smt的不同模式对应执行的修复算法的个数不同,不再向现有技术那样执行全量(即所有修复算法)的smt,提升了修复效率。
[0256]
本技术实施例中提供了一种电子设备,该电子设备包括:存储器和处理器;至少一个程序,存储于存储器中,用于被处理器执行时,与现有技术相比可实现:在服务器中出现
故障内存单元时,cpu若确定故障内存单元的故障类型符合预设条件,则生成cmci中断,由于cmci中断不会导致cpu的暂停,因此避免了现有技术中因生成smi中断导致的网络丢包的问题,在服务器下一次启动后bios运行阶段,bios获取预设的故障地址列表,首先对故障地址列表中的故障内存单元进行ppr修复,在修复的通知对故障内存单元是否执行smt以及执行的smt的模式进行标记,在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt,由于本技术实施例的smt的不同模式对应执行的修复算法的个数不同,不再向现有技术那样执行全量(即所有修复算法)的smt,提升了修复效率。
[0257]
在一个可选实施例中提供了一种电子设备,如图12所示,图12所示的电子设备4000包括:处理器4001和存储器4003。其中,处理器4001和存储器4003相连,如通过总线4002相连。可选地,电子设备4000还可以包括收发器4004。需要说明的是,实际应用中收发器4004不限于一个,该电子设备4000的结构并不构成对本技术实施例的限定。
[0258]
处理器4001可以是cpu(central processing unit,中央处理器),通用处理器,dsp(digital signal processor,数据信号处理器),asic(applicati/on specific integrated circuit,专用集成电路),fpga(fieldprogrammable gate array,现场可编程门阵列)或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本技术公开内容所描述的各种示例性的逻辑方框,模块和电路。处理器4001也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,dsp和微处理器的组合等。
[0259]
总线4002可包括一通路,在上述组件之间传送信息。总线4002可以是pci(peripheral component interconnect,外设部件互连标准)总线或eisa(extended industry standard architecture,扩展工业标准结构)总线等。总线4002可以分为地址总线、数据总线、控制总线等。为便于表示,图12中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
[0260]
存储器4003可以是rom(read only memory,只读存储器)或可存储静态信息和指令的其他类型的静态存储设备,ram(random access memory,随机存取存储器)或者可存储信息和指令的其他类型的动态存储设备,也可以是eeprom(electrically erasable programmable read only memory,电可擦可编程只读存储器)、cd-rom(compact disc readonly memory,只读光盘)或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。
[0261]
存储器4003用于存储执行本技术方案的应用程序代码,并由处理器4001来控制执行。处理器4001用于执行存储器4003中存储的应用程序代码,以实现前述方法实施例所示的内容。
[0262]
本技术实施例提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,当其在计算机上运行时,使得计算机可以执行前述方法实施例中相应内容。与现有技术相比,在服务器中出现故障内存单元时,cpu若确定故障内存单元的故障类型符合预设条件,则生成cmci中断,由于cmci中断不会导致cpu的暂停,因此避免了现有技术中因生成smi中断导致的网络丢包的问题,在服务器下一次启动后bios运行阶段,bios获取预设
的故障地址列表,首先对故障地址列表中的故障内存单元进行ppr修复,在修复的通知对故障内存单元是否执行smt以及执行的smt的模式进行标记,在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt,由于本技术实施例的smt的不同模式对应执行的修复算法的个数不同,不再向现有技术那样执行全量(即所有修复算法)的smt,提升了修复效率。
[0263]
本技术实施例提供了一种计算机程序,该计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中,当计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行如前述方法实施例所示的内容。与现有技术相比,在服务器中出现故障内存单元时,cpu若确定故障内存单元的故障类型符合预设条件,则生成cmci中断,由于cmci中断不会导致cpu的暂停,因此避免了现有技术中因生成smi中断导致的网络丢包的问题,在服务器下一次启动后bios运行阶段,bios获取预设的故障地址列表,首先对故障地址列表中的故障内存单元进行ppr修复,在修复的通知对故障内存单元是否执行smt以及执行的smt的模式进行标记,在执行ppr后,根据各故障内存单元设置的smt执行信息,执行相应模式的smt,由于本技术实施例的smt的不同模式对应执行的修复算法的个数不同,不再向现有技术那样执行全量(即所有修复算法)的smt,提升了修复效率。
[0264]
应该理解的是,虽然附图的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,其可以以其他的顺序执行。而且,附图的流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,其执行顺序也不必然是依次进行,而是可以与其他步骤或者其他步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
[0265]
以上仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。