1.本发明属于人工智能中的深度学习和智能交通技术领域,更具体地,涉及一种使用细粒度填充图卷积循环神经网络(fine-grained completion graph convolution recurrent network,简称fcgcrn)实现的含缺失数据的交通流预测方法和系统。
背景技术:
2.近年来,随着传感器和监测系统对海量数据的收集,预测任务在气候、金融和交通等各个领域得到了广泛的研究。交通预测作为一种经典应用,是智能交通系统(intelligent transportation system,简称its)不可或缺的组成部分,对缓解交通堵塞、减少交通事故并提高城市交通服务质量具有重要作用。在给定历史交通流和现有道路信息的情况下,预测未来状态对于交通流预测至关重要。然而,每个未来的交通流数据不仅取决于该条交通流的历史值,还取决于其他条交通流。同时,由于网络抖动、设备故障等原因可能会造成传感器在收集交通流时出现交通数据丢失现象。因此,如何准确预测含缺失数据的交通流的未来状态是一个具有挑战性的问题。
3.现有的关于交通流预测的研究主要包括三类算法。第一种是基于统计方法,其假设每个交通流就是一个平稳序列并采用线性算法对交通数据进行拟合,如历史平均(historicalaverage,简称ha)、自回归求和移动平均模型(autoregressive integrated movingaverage,简称arima)和高斯过程(gaussian process,简称gp)等;第二种是基于单一神经网络方法,其采用循环神经网络(recurrentneural network,简称rnn)及其变体长短期记忆(long short term memory,简称lstm)和门控循环单元(gated recurrent unit,简称gru),该方法能够以较少的时间处理长范围的时间序列交通数据;第三种是基于混合神经网络方法,其融合卷积神经网络(convolution neural network,简称cnn)或图卷积神经网络(graph convolutionnetwork,简称gcn)和循环神经网络rnn,分别捕获交通流之间的复杂空间依赖关系和单条交通序列间的长时间依赖关系。
4.然而,上述现有的交通流预测方法均存在一些不可忽略的技术问题:第一,传统方法和单一神经网络方法仅考虑交通流数据在时间维度上的特征,并没有明确地建模不同时间序列之间的相互依赖关系,导致预测性能较低;第二,混合神经网络方法中的cnn将交通流之间的相互作用封装成一个全局隐藏状态,并仅限于处理规则的网格结构以捕获空间相关性,使其在处理非网格结构空间关系时表征能力弱,进一步影响预测准确度;第三,混合神经网络方法中的gcn依赖于预定义图,使得模型缺乏通用性;第四,混合方法缺乏合适的参数学习方式导致不能细粒度表征时空相关性,进而影响预测的精度;第五,上述三种方法对交通数据的缺失高度敏感,导致模型在学习特征时极易引入噪音,从而会降低预测性能。
技术实现要素:
5.针对现有技术的以上缺陷或改进需求,本发明提供了一种含缺失数据的交通流预测方法和系统,其目的在于,解决现有交通流预测方法由于不能捕获交通数据空间相关性,
导致不能如实反应交通流未来状态的技术问题;以及由于不能表征非欧式空间下的复杂空间相关性,导致空间表征局限于网格数据的技术问题;以及由于预定义图的限制影响空间表征,导致混合神经网络方法缺乏通用性;以及由于不能细粒度表征交通流并捕获流节点特定模式,导致影响交通流预测精度的技术问题;以及由于网络或设备故障引起数据缺失问题影响特征学习性能,导致影响特征学习模块学习时间和空间相关性的技术问题。
6.为实现上述目的,按照本发明的一个方面,提供了一种含缺失数据的交通流预测方法,包括如下步骤:
7.(1)获取某区域的交通数据集,该交通数据集包含缺失数据,将该交通数据集重建模为交通流数据矩阵;
8.(2)将步骤(1)得到的交通流数据矩阵x输入训练好的时空预测模型的正交非负矩阵分解onmf模块形成k个簇,并在各簇中利用时空预测模型的广义矩阵分解填充gmf模块填充数据,以得到填充数据后的交通流数据矩阵对填充后的交通流数据矩阵进行标准化处理,以得到标准化后的交通流数据矩阵并根据历史步长h和预测窗口w将标准化后的交通流数据矩阵建模为三维张量
9.(3)将步骤(2)建模得到的三维张量输入训练好的时空预测模型的图卷积循环神经网络gcrnn中,以得到预测数据y
′
。
10.优选地,交通数据为三维张量数据{时间,节点,交通特征},其中,时间指的是该节点采集到交通特征的时间,节点指的是单个传感器,而交通特征包括车速特征、交通流特征和人数特征;
11.优选地,步骤(1)中,交通数据集
12.其中其表示该区域中所有街道上设置的所有节点(即传感器)中的第n个节点在t个时刻的交通流数据矩阵,n∈[1,n],t∈[1,t],t为任意正整数,n为该区域中所有街道上布设的传感器的总数,且有正整数,n为该区域中所有街道上布设的传感器的总数,且有表明数据具有非负性;
[0013]
其中为第n个节点在第t时刻的第c个特征值,c∈[1,c],其中c表示交通特征种类。
[0014]
优选地,步骤(2)中将步骤(1)得到的交通流数据矩阵x输入onmf模块形成k个簇这一过程具体包括:
[0015]
(2-1)将交通流数据矩阵x的矩阵因子f和g初始化为(0,1)内的随机值;
[0016]
(2-2)根据步骤(2-1)初始化得到的矩阵因子f和g、并采用更新规则和更新矩阵中的可观测数据,当x-fg
t
的误差收敛时,则停止迭代,从而得到更新后的矩阵因子g;
[0017]
(2-3)根据步骤(2-2)得到的更新后的矩阵因子g,将交通流数据矩阵x聚类为k个簇;
[0018]
优选地,步骤(2)中在各簇中利用gmf模块填充交通流数据矩阵x,以得到填充数据后的交通流数据矩阵对填充后的交通流数据矩阵进行标准化处理,以得到标准化后的交通流数据矩阵并根据历史步长h和预测窗口w将标准化后的交通流数据矩阵建模为三维张量这一过程包括以下子步骤:
[0019]
(2-4)在步骤(2-3)得到的每个簇中将交通流数据矩阵x划分为可观测数据集和不可观测数据集,并将可观测数据集进行重构,以得到时间向量v
p
∈rm、节点向量vq∈rm和交通流向量vy∈rm,将不可观测数据集重构为时间向量v
′
p
∈rm′
和节点向量v
′q∈rm′
,其中m表示可观测数据集中可观测数据的总数,m
′
表示不可观测数据集中不可观测数据的总数;
[0020]
(2-5)将步骤(2-4)得到的v
p
和vq两个向量输入gmf模块的嵌入层,以得到嵌入层的输出,即时间矩阵因子p和节点矩阵因子q:
[0021]
p=e1(v
p
),
[0022]
q=e2(vq),
[0023]
其中,p∈rm×a和q∈rm×a分别为时间矩阵因子和节点矩阵因子,a=16为潜在因子,e1()和e2()表示嵌入函数,都是采用pytorch框架中的torch.nn.embedding()函数;
[0024]
(2-6)将步骤(2-5)得到的时间矩阵因子p和节点矩阵因子q输入gmf模块的分解层,以得到输出结果f(p,q):
[0025]
f(p,q)=p
⊙
q,
[0026]
其中,
⊙
表示元素积运算。
[0027]
(2-7)将步骤(2-6)得到的输出结果f(p,q)输入gmf模块的填充层,得到的输出即为填充结果g(p,q):
[0028]
g(p,q)=a
ott
(w
t
(p
⊙
q) b),
[0029]
其中,a
out
为relu激活函数,w和b分别表示gmf模块中可学习的权重和偏置参数;
[0030]
(2-8)对步骤(2-7)的填充结果采用均方误差mse进行度量,以得到步骤(2-4)的交通流向量vy和步骤(2-7)的填充结果g(p,q)二者之间的误差值mse,该步骤计算公式为:
[0031][0032]
(2-9)通过adam优化器对gmf模块中可学习的权重w和偏置参数b进行更新;
[0033]
(2-10)重复上述步骤(2-8)至(2-9),直到mse小于阈值或训练次数达到预设的轮次为止,从而得到训练好的gmf模块;
[0034]
(2-11)将步骤(2-4)得到的不可观测数据集输入步骤(2-10)训练好的gmf模块,以得到交通流向量v
′y∈rm′
;
[0035]
(2-12)根据步骤(2-4)得到的可观测数据集下的时间向量v
p
、节点向量vq、交通流向量vy和不可观测数据集下的时间向量v
′
p
、节点向量v
′q以及步骤(2-11)所得的交通流向量v
′y,获取填充数据后的交通流数据矩阵
[0036]
(2-13)对步骤(2-12)填充数据后的交通流数据矩阵进行标准化处理,以得到标准化后的交通流数据矩阵
[0037][0038]
其中,μ为交通流数据矩阵的均值,σ为的标准差;
[0039]
(2-14)根据历史步长h和预测窗口w将步骤(2-13)标准化后的交通流数据矩阵重构为三维张量和三维张量y∈r
(t-h-w 1)
×n×w。
[0040]
优选地,gcrnn网络是通过如下步骤训练得到的:
[0041]
(3-1)将步骤(2-14)得到的三维张量和y均以6:4比例划分为训练集和测试集;
[0042]
(3-2)通过参数e对gcrnn进行自适应图学习,以得到邻接矩阵
[0043]
本步骤的计算公式为:
[0044][0045]
其中,e∈rn×e是可学习的参数矩阵,参数e的初始化采用pytorch框架中的torch.floattensor()函数,参数e最优调参结果为2和10;
[0046]
(3-3)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据的训练集在时刻t下的数据和步骤(3-2)得到的邻接矩阵输入图卷积神经网络,以得到第k个簇的图卷积结果hk∈rn×h;
[0047]
本步骤的计算公式为:
[0048][0049]
其中,gk∈rn×n是第k个簇的拉普拉斯矩阵,θk∈rh×h和bk∈rh为第k个簇的可学习参数,h为图卷积循环神经网络中隐藏层的神经元数目;
[0050]
(3-4)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据输入循环神经网络,以得到时刻t下的表征结果h
t
;
[0051]
(3-5)将步骤(3-4-4)得到的输出h
t
输入到gcrnn网络的二维卷积层(如图3所示),以得到最终的交通流预测结果y
′
∈rn×w;
[0052]
本步骤的具体实现如下:
[0053]y′
=h
t
★
f1×h,
[0054]
其中,二维卷积层通道数channel为1,输出w=12,f1×h表示二维卷积层中的卷积核大小为(1,h),其中h=64;
[0055]
(3-6)使用l1损失函数计算步骤(3-5)得到的预测结果y
′
和步骤(2-14)得到的张量y之间的损失值o(y,y
′
);
[0056]
具体而言,本步骤使用的l1损失函数为:
[0057][0058]
(3-7)利用步骤(3-6)的损失函数和pytorch框架中的adam优化器对步骤(3-2)的可学习参数e和步骤(3-4-1)至(3-4-4)的可学习参数4)的可学习参数和进行迭代更新;
[0059]
(3-8)重复上述步骤(3-6)到步骤(3-7)的训练过程,直到步骤(3-7)的迭代次数
(本发明中为100)或步骤(3-6)的损失值o(y,y
′
)小于设定阈值时结束训练,从而得到初步训练好的gcrnn模型;
[0060]
(3-9)使用步骤(3-1)得到的测试集对步骤(3-8)初步训练好的gcrnn模型进行验证,直到预测误差达到最优为止,从而得到训练好的时空预测模型。
[0061]
优选地,步骤(3-4)包括以下子步骤:
[0062]
(3-4-1)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据步骤(3-2)得到的邻接矩阵和上一时刻t-1下的表征结果h
t-1
输入到gcrnn,以得到t时刻的更新门z
t
∈rn×h;
[0063]
具体而言,本步骤的计算公式为:
[0064][0065]
其中,h0∈rn×h表示初始状态,是一个全为0构成的矩阵,[,]表示拼接运算,和是第k个簇中t时刻更新门z
t
的可学习参数,σ(
·
)是sigmoid激活函数;
[0066]
(3-4-2)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据步骤(3-2)得到的邻接矩阵和上一时刻t-1下的表征结果h
t-1
输入gcrnn,以得到t时刻的重置门r
t
∈rn×h;
[0067]
本步骤的计算公式为:
[0068][0069]
其中,和是第k个簇中t时刻重置门r
t
的可学习参数;
[0070]
(3-4-3)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据步骤(3-4-2)得到的重置门r
t
、步骤(3-2)得到的邻接矩阵和上一时刻t-1下的表征结果h
t-1
输入到gcrnn,以得到t时刻下的传输状态
[0071]
本步骤的计算公式为:
[0072][0073]
其中,
⊙
表示元素积,和是第k个簇在t时刻下的传输状态的可学习参数;
[0074]
(3-4-4)将步骤(3-4-1)得到的更新门z
t
、上一时刻t-1下的表征结果和步骤(3-4-3)得到的传输状态输入gcrnn中,以得到当前时刻t下的表征结果h
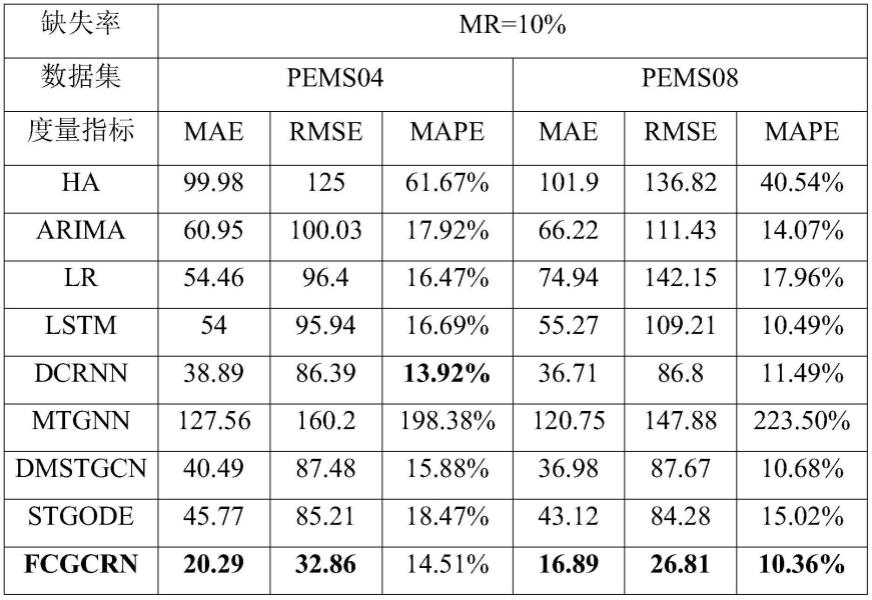
t
∈rn×h;
[0075]
本步骤的计算公式为:
[0076][0077]
其中,z
t
⊙ht-1
表示对上一时刻t-1的信息h
t-1
进行选择性遗忘,进行选择性遗忘,表示
对包含当前时刻t的信息进行选择性记忆。
[0078]
按照本发明的另一方面,提供了一种含缺失数据的交通流预测系统,包括:
[0079]
第一模块,用于获取某区域的交通数据集,该交通数据集包含缺失数据,将该交通数据集重建模为交通流数据矩阵;
[0080]
第二模块,用于将第一模块得到的交通流数据矩阵x输入训练好的时空预测模型的正交非负矩阵分解onmf模块形成k个簇,并在各簇中利用时空预测模型的广义矩阵分解填充gmf模块填充数据,以得到填充数据后的交通流数据矩阵对填充后的交通流数据矩阵进行标准化处理,以得到标准化后的交通流数据矩阵并根据历史步长h和预测窗口w将标准化后的交通流数据矩阵建模为三维张量
[0081]
第三模块,用于将第二模块建模得到的三维张量输入训练好的时空预测模型的图卷积循环神经网络gcrnn中,以得到预测数据y
′
。
[0082]
总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
[0083]
(1)由于本发明采用了步骤(3),其融合了gcn和gru构成图卷积循环神经网络(graph convolution recurrent neural network,简称gcrnn),该模块可以利用切比雪夫(chebyshev)多项式近似gcn捕获空间相关性,该方式能够提升计算性能;同时,采用gru模型使其选择性记忆关键的特征以学习长范围的时间特性。因此能够解决现有方法仅表征时间关系导致不能如实反应交通流未来状态的技术问题;
[0084]
(2)由于本发明采用了步骤(3),其在捕获空间相关性的时候,采用的gcn是依赖于图拉普拉斯分解来处理不规则图数据,因此能够解决空间表征局限于规则数据的技术问题;
[0085]
(3)由于本发明采用了步骤(3),其设计了图学习网络,能够以数据驱动的方式学习图结构而非依赖于预定义的图结构,因此解决了混合神经网络方法通用性差的技术问题;
[0086]
(4)由于本发明采用了步骤(2),其设计了基于正交非负矩阵分解(orthogonal nonnegative matrix factorization,简称onmf)的簇参数学习机制,联合步骤(3)学习簇内共享-簇间特定的参数并细粒度地捕获交通流序列时空依赖关系。该机制使来自同一个簇的交通流数据拥有一个共同的参数空间,而来自不同簇的交通流拥有独立的参数空间,因此解决了由于细粒度表征问题导致影响交通流预测精度的技术问题;
[0087]
(5)由于本发明采用了步骤(2),其设计了广义矩阵分解填充模块(generalized matrix factorization,简称gmf),一种简单且高效的深度学习方法,通过学习隐式交互相关性来填充丢失的交通流序列。该模块在每个交通流簇中通过元素积而非内积的方式来学习时间节点交互函数,不仅继承了矩阵分解的优点,而且充分挖掘了不同簇中交通流的非线性内在相关性,因此弥补了由于网络或设备故障引起数据缺失问题影响特征学习性能的技术问题。
[0088]
(6)由于本发明采用步骤(2)中的簇参数学习机制,其通过控制簇的个数使得该参数学习模式相较于节点特定的方式大大减少了参数量,即平衡细粒度表征学习和参数量之
簇间特定的参数学习机制细粒度表征交通数据中的时间和空间特性,最终用二维卷积层完成所有交通数据集的预测。
[0102]
如图9所示,本发明提供了一种含缺失数据的交通流预测方法,具体包括如下步骤:
[0103]
(1)获取某区域的交通数据集,该交通数据集包含缺失数据,将该交通数据集重建模为交通流数据矩阵;
[0104]
具体而言,本步骤是使用某区域中每条街道上布设的传感器来获取该街道的包含缺失数据的交通数据(其为三维张量数据),所有街道的包含缺失数据的交通数据构成交通数据集,然后对该交通数据集进行数据降维处理,以获取交通流数据矩阵。
[0105]
三维张量数据指的是{时间,节点,交通特征}。其中,时间指的是该节点采集到交通特征的时间,节点指的是单个传感器,而交通特征包括车速特征、交通流特征和人数特征。
[0106]
在本步骤中,交通数据集
[0107]
其中其表示该区域中所有街道上设置的所有节点(即传感器)中的第n个节点在t个时刻的交通流数据矩阵,n∈[1,n],t∈[1,t],t为任意正整数,n为该区域中所有街道上布设的传感器的总数,且有意正整数,n为该区域中所有街道上布设的传感器的总数,且有表明数据具有非负性;
[0108]
其中为第n个节点在第t时刻的第c个特征值,c∈[1,c],其中c表示交通特征种类,本发明有3个交通特征(车速特征、交通流特征和人数特征),因此c=3;
[0109]
在得到了交通数据集z以后,本发明将c设置为1,并通过python中numpy库的numpy.squeeze()函数实现数据降维,此时得到的交通流数据矩阵为
[0110]
(2)将步骤(1)得到的交通流数据矩阵x输入训练好的时空预测模型的正交非负矩阵分解(orthogonal nonnegative matrix factorization,简称onmf)模块形成k个簇(详见以下的步骤(2-1)至(2-3)),并在各簇中利用时空预测模型的广义矩阵分解填充(generalized matrix factorization,简称gmf)模块填充数据,以得到填充数据后的交通流数据矩阵(详见以下的步骤(2-4)至(2-12)),对填充后的交通流数据矩阵进行标准化处理,以得到标准化后的交通流数据矩阵(详见以下的步骤(2-13)),并根据历史步长h和预测窗口w将标准化后的交通流数据矩阵建模为三维张量(详见以下的步骤(2-14));
[0111]
具体而言,步骤(2)中所提及的onmf模块是图2所示的第一部分。该模块为聚类模块,将步骤(1)得到的交通流数据矩阵聚类为k个簇;onmf是在矩阵分解的基础上附加正交约束条件,形式化表达为:min
f≥0,g≥0
||x-fg
t
||2,s.t.g
t
g=i.其中,为交通流数据矩阵(r表示实数,这里表示x是t行n列的非负实数矩阵),和是交通流数据矩阵x的两个矩阵因子,为单位矩阵,k的取值范围是2到5,优选为2或3;
[0112]
gmf模块是图2所示的第二部分,即本发明的填充模块,包括嵌入层、分解层和填充
层。根据步骤(2-3)得到的聚类结果,在每个簇中利用gmf模块并根据可观测数据填充缺失部分的数据。
[0113]
本步骤(2)中将步骤(1)得到的交通流数据矩阵x输入onmf模块形成k个簇这一过程具体包括:
[0114]
(2-1)将交通流数据矩阵x的矩阵因子f和g初始化为(0,1)内的随机值;
[0115]
(2-2)根据步骤(2-1)初始化得到的矩阵因子f和g、并采用更新规则和更新矩阵中的可观测数据,当x-fg
t
的误差收敛时,则停止迭代,从而得到更新后的矩阵因子g;
[0116]
由于步骤(1)得到的交通流数据矩阵是有缺失的,因此onmf模块仅使用交通流数据矩阵中的可观测数据。
[0117]
本步骤的优点在于,仅使用交通流数据矩阵中的可观测数据可以避免缺失数据(即不可观测数据)影响聚类结果。同时,采用本步骤的更新规则所得的矩阵因子f和g具有解的唯一性,即在参数一致的情况下,每一次的聚类结果保持一致。
[0118]
(2-3)根据步骤(2-2)得到的更新后的矩阵因子g,将交通流数据矩阵x聚类为k个簇;
[0119]
本步骤的优点在于具有可解释性,即与k-means聚类算法之间存在等价性。具体表现为:某一节点的第k个概率最大,则表示该节点属于第k个簇;以此方式,将交通流数据矩阵聚类为k个簇。同时,本步骤所得的k个簇的数据量比例均衡,为后续更好地表征时空相关性提供有利条件。步骤(2-1)到(2-3)所述为onmf模块的聚类交通流数据矩阵的详细过程,后续通过不断调整参数k,使其融合gcrnn模块达到模型最优,即预测误差最小化;
[0120]
本步骤(2)中在各簇中利用gmf模块填充交通流数据矩阵x,以得到填充数据后的交通流数据矩阵对填充后的交通流数据矩阵进行标准化处理,以得到标准化后的交通流数据矩阵并根据历史步长h和预测窗口w将标准化后的交通流数据矩阵建模为三维张量这一过程包括以下子步骤:
[0121]
(2-4)在步骤(2-3)得到的每个簇中将交通流数据矩阵x划分为可观测数据集(即交通流数据矩阵x中非缺失数据组成的集合)和不可观测数据集(即交通流数据矩阵x中缺失数据组成的集合),并将可观测数据集进行重构,以得到时间向量v
p
∈rm、节点向量vq∈rm和交通流向量vy∈rm,将不可观测数据集重构为时间向量v
′
p
∈rm′
和节点向量v
′q∈rm′
,其中m表示可观测数据集中可观测数据的总数,m
′
表示不可观测数据集中不可观测数据的总数;
[0122]
(2-5)将步骤(2-4)得到的v
p
和vq两个向量输入gmf模块的嵌入层,以得到嵌入层的输出,即时间矩阵因子p和节点矩阵因子q(如图2所示):
[0123]
p=e1(v
p
),
[0124]
q=e2(vq),
[0125]
其中,p∈rm×a和q∈rm×a分别为时间矩阵因子和节点矩阵因子,a=16为潜在因子,e1()和e2()表示嵌入函数,都是采用pytorch框架中的torch.nn.embedding()函数,具体实现过程中两个嵌入函数的参数不同;
[0126]
(2-6)将步骤(2-5)得到的时间矩阵因子p和节点矩阵因子q输入gmf模块的分解
层,以得到输出结果f(p,q):
[0127]
f(p,q)=p
⊙
q,
[0128]
其中,
⊙
表示元素积运算。
[0129]
本步骤的优点在于,分解层中用元素积代替矩阵内积的方式既继承了矩阵分解的优点,又充分挖掘了不同簇中数据的非线性内在相关性。
[0130]
(2-7)将步骤(2-6)得到的输出结果f(p,q)输入gmf模块的填充层,得到的输出即为填充结果g(p,q):
[0131]
g(p,q)=a
out
(w
t
(p
⊙
q) b),
[0132]
其中,a
out
为relu激活函数,w和b分别表示gmf模块中可学习的权重和偏置参数;
[0133]
本步骤的优点在于,填充层为一层简单而高效的神经网络,可以利用该层可实现对缺失交通数据的填充。
[0134]
(2-8)对步骤(2-7)的填充结果采用均方误差(mean square error,简称mse)进行度量,以得到步骤(2-4)的交通流向量vy和步骤(2-7)的填充结果g(p,q)二者之间的误差值mse,该步骤计算公式为:
[0135][0136]
(2-9)通过adam优化器对gmf模块中可学习的权重w和偏置参数b进行更新;
[0137]
(2-10)重复上述步骤(2-8)至(2-9),直到mse小于阈值(本发明中为10-6
)或训练次数达到预设的轮次(本发明中为100)为止,从而得到训练好的gmf模块;
[0138]
(2-11)将步骤(2-4)得到的不可观测数据集输入步骤(2-10)训练好的gmf模块,以得到交通流向量v
′y∈rm′
;
[0139]
至此,数据填充工作完成。
[0140]
(2-12)根据步骤(2-4)得到的可观测数据集下的时间向量v
p
、节点向量vq、交通流向量vy和不可观测数据集下的时间向量v
′
p
、节点向量v
′q以及步骤(2-11)所得的交通流向量v
′y,获取填充数据后的交通流数据矩阵
[0141]
(2-13)对步骤(2-12)填充数据后的交通流数据矩阵进行标准化处理,以得到标准化后的交通流数据矩阵
[0142][0143]
其中,μ为交通流数据矩阵的均值,σ为的标准差;
[0144]
本步骤的优点在于第一:消除数据量纲以提升gcrnn模块的收敛速度以降低计算成本;第二,防止模块训练过程中出现梯度爆炸的情况。
[0145]
(2-14)根据历史步长h和预测窗口w将步骤(2-13)标准化后的交通流数据矩阵重构为三维张量和三维张量y∈r
(t-h-w 1)
×n×w;
[0146]
本发明的时空预测模型是细粒度填充图卷积循环神经网络(fine-grained completion graph convolution recurrent network,简称fcgcrn),包括onmf模块、gmf模块和gcrnn模块。
[0147]
(3)将步骤(2)建模得到的三维张量输入训练好的时空预测模型的图卷积循环神经网络(graph convolution recurrent neural network,简称gcrnn,如图2所示)中,以得到预测数据y
′
,其具有低误差率。
[0148]
如图3所示,本发明的gcrnn在簇参数学习机制下融合了图学习神经网络、图卷积神经网络和循环神经网络。
[0149]
本发明中gcrnn网络是通过如下步骤训练得到的:
[0150]
(3-1)将步骤(2-14)得到的三维张量和y均以6:4比例划分为训练集和测试集;
[0151]
(3-2)通过参数e对gcrnn进行自适应图学习,以得到邻接矩阵
[0152]
本步骤的计算公式为:
[0153][0154]
其中,e∈rn×e是可学习的参数矩阵,参数e的初始化采用pytorch框架中的torch.floattensor()函数;本发明中参数e最优调参结果为2和10;
[0155]
(3-3)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据的训练集在时刻t下的数据和步骤(3-2)得到的邻接矩阵输入图卷积神经网络,以得到第k个簇的图卷积结果hk∈rn×h;
[0156]
本步骤的计算公式为:
[0157][0158]
其中,gk∈rn×n是第k个簇的拉普拉斯矩阵,θk∈rh×h和bk∈rh为第k个簇的可学习参数,h为图卷积循环神经网络中隐藏层的神经元数目。
[0159]
进一步,本发明采用chebyshev多项式扩展近似拉普拉斯矩阵gk。其中,具体实现过程中,t0=1,在本发明中,经参数调整,最终确定在多项式参数d为2,簇参数k为2或3时,预测效果最佳。
[0160]
本步骤的优点在于第一:用chebyshev多项式近似拉普拉斯矩阵,能够以较低的计算成本来表征高维特征;第二:采用的图卷积神经网络能够强有力的表征对空间相关性(包括欧式空间和非欧式空间)。
[0161]
(3-4)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据输入循环神经网络(其用于表征时间相关性),以得到时刻t下的表征结果h
t
;
[0162]
具体而言,本发明是将图卷积神经网络融合在循环神经网络中构成gcrnn,以共同表征时间和空间相关性,表现为将循环神经网络gru中的多层感知机mlp替换为图卷积网络gcn。具体实现步骤如下:
[0163]
(3-4-1)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据步骤(3-2)得到的邻接矩阵和上一时刻t-1下的表征结果h
t-1
(详见以下的步骤(3-4-4))输入到gcrnn,以得到t时刻的更新门z
t
∈rn×h;
[0164]
具体而言,本步骤的计算公式为:
[0165][0166]
其中,h0∈rn×h表示初始状态,是一个全为0构成的矩阵,[,]表示拼接运算,和是第k个簇中t时刻更新门z
t
的可学习参数,σ(
·
)是sigmoid激活函数;
[0167]
(3-4-2)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据步骤(3-2)得到的邻接矩阵和上一时刻t-1下的表征结果h
t-1
(详见以下的步骤(3-4-4))输入gcrnn,以得到t时刻的重置门r
t
∈rn×h;
[0168]
本步骤的计算公式为:
[0169][0170]
其中,和是第k个簇中t时刻重置门r
t
的可学习参数;
[0171]
(3-4-3)将步骤(3-1)得到的三维张量的训练集在时刻t下的数据步骤(3-4-2)得到的重置门r
t
、步骤(3-2)得到的邻接矩阵和上一时刻t-1下的表征结果h
t-1
(详见以下的步骤(3-4-4))输入到gcrnn,以得到t时刻下的传输状态
[0172]
本步骤的计算公式为:
[0173][0174]
其中,
⊙
表示元素积,和是第k个簇在t时刻下的传输状态的可学习参数;
[0175]
(3-4-4)将步骤(3-4-1)得到的更新门z
t
、上一时刻t-1下的表征结果和步骤(3-4-3)得到的传输状态输入gcrnn中,以得到当前时刻t下的表征结果h
t
∈rn×h;
[0176]
本步骤的计算公式为:
[0177][0178]
其中,z
t
⊙ht-1
表示对上一时刻t-1的信息h
t-1
进行选择性遗忘,进行选择性遗忘,表示对包含当前时刻t的信息进行选择性记忆;
[0179]
步骤(3-4-1)至(3-4-4)所述均为在某一时刻t下的特征学习,在具体实现中,通过迭代t个时刻的信息以表征长时间的相关性,利用最后时刻的累计表征结果预测未来交通流。
[0180]
此外,由于图卷积神经网络的优异表征能力,使得本发明中的图神经网络层数只需2层即可达到较低的误差结果,即gcrnn的层数为2层。
[0181]
上述步骤(3-1)到(3-4)的优点在于第一:以细粒度方式捕获交通预测数据中的时间和空间相关性并实现高精度预测。现有技术实现中参数矩阵θ是被所有节点(即道路)所共享的,然而在交通预测中,并不是所有节点都采用同一种模式。如图1所示,道路1表现为早高峰模式,道路2和道路4表现为晚高峰模式,道路3表现为早晚高峰模式。因此本发明采
用簇内共享-簇间特定的参数学习模式来细粒度表征时空相关性,即上述gcrnn模块的实现均在k个簇中完成。第二:所采用的循环神经网络gru相较于其他循环神经网络,能够以较少的参数量和更低成本的计算量来学习长时间范围内的特性,且gru的学习能力同其他循环神经网络相当。
[0182]
(3-5)将步骤(3-4-4)得到的输出h
t
输入到gcrnn网络的二维卷积层(如图3所示),以得到最终的交通流预测结果y
′
∈rn×w;
[0183]
本步骤的具体实现如下:
[0184]y′
=h
t
★
f1×h,
[0185]
其中,二维卷积层通道数channel为1,输出w=12,f1×h表示二维卷积层中的卷积核大小为(1,h),本发明中h=64时预测效果最佳;
[0186]
(3-6)使用l1损失函数计算步骤(3-5)得到的预测结果y
′
和步骤(2-14)得到的张量y(指训练集)之间的损失值o(y,y
′
);
[0187]
具体而言,本步骤使用的l1损失函数为:
[0188][0189]
(3-7)利用步骤(3-6)的损失函数和pytorch框架中的adam优化器对步骤(3-2)的可学习参数e和步骤(3-4-1)至(3-4-4)的可学习参数4)的可学习参数和进行迭代更新;
[0190]
(3-8)重复上述步骤(3-6)到步骤(3-7)的训练过程,直到步骤(3-7)的迭代次数(本发明中为100)或步骤(3-6)的损失值o(y,,y
′
)小于设定阈值(本发明中为10-6
)时结束训练,从而得到初步训练好的gcrnn模型;
[0191]
(3-9)使用步骤(3-1)得到的测试集对步骤(3-8)初步训练好的gcrnn模型进行验证,直到预测误差达到最优为止,从而得到训练好的时空预测模型。
[0192]
总而言之,通过本发明的上述描述,本发明的主要优点包括:
[0193]
1、提出了一种含缺失数据的交通流预测方法,能够填充含缺失的交通流数据并细粒度表征历史交通流复杂且长范围的时空相关性,以实现高精度预测未来交通流状态。
[0194]
2、通过将交通流数据进行划分,使得gcrnn能够采用簇内共享-簇间特定的参数学习机制来提取交通流数据的特征。聚类采用受正交约束的非负矩阵分解算法onmf,该算法较好地适应缺失的交通流数据,只对可观测数据进行迭代。再者,在聚类结果中各簇的节点数分布均匀,为后续更好的表征时空关系提供有利条件。此外,在数据填充前实现聚类,使得聚类结构准确而可靠。
[0195]
3、采用广义矩阵分解模块gmf在各个簇内实现缺失填充,有效地利用簇的相关性高的特征,同时采用简单神经网络学习数据间的非线性关系。
[0196]
4、本发明采用图卷积神经网络来学习数据间的空间相关性,图结构不受限于欧式空间,能够较好表征空间关系。同时,该图卷积神经网络采用chebyshev多项式近似传统的图卷积,在保证表征效果的情况下减少计算开销。本发明在gcrnn模块中,用自适应图学习代替预定义图,使得图依赖于数据而非依赖于预定义的结构。
[0197]
5、将交通流量数据建模成为张量并进行标准化处理,能够有效消除数据规模之间的差异性,消除对表征的影响。
[0198]
实验结果
[0199]
本发明在pems04和pems08两个含10%和30%缺失率(missing rate,简称mr)的真实交通流数据集上进行实验。pems04数据集一共有307个节点,16992个时间步,总时长共计59天;pems08数据集共有170个节点,17856个时间步,总时长共计62天。两个数据集均以5分钟作为一个时间步长。
[0200]
通过在真实数据集上的对比实验验证了本发明提出的一种含缺失数据的交通流预测方法的有效性和准确性,如下表1和2、以及图4至7所示。将本发明的时空预测模型fcgcrn与其他八个基准方法(baselines)进行了对比,包含ha、arima、逻辑回归(logical regression,简称lr)、lstm、dcrnn、mtgnn、dmstgcn和stgode(这些方法在别人的论文中直接引用英文简写,没有中文),并且采用三种度量指标:平均绝对误差mae、均方根误差(root mean square error,简称rmse)和平均绝对百分比误差(mean absolute percentage error,简称mape)。误差度量指标越小,表明对缺失数据的预测性能越好。表1-2表示在两种缺失率和两个真实数据集下的实验结果,从表可以看出,时空预测模型fcgcrn的预测性能在mae和rmse指标下均优于其他baselines,在mape指标下优于大多基准方法(baselines)。其中,时空预测模型fcgcrn在高缺失率下的性能表现更为突出。从表1可见,深度学习方法(lr,lstm,dcrnn,dmstgcn和stgode)的预测性能优于传统统计方法(ha和arima)。进一步可见,自适应图学习模型(mtgnn和stgode)受数据缺失的影响较大,对比之下,本发明模型虽也为图学习模型,但在数据存在缺失且缺失率较大的情况下,性能更为稳定。
[0201]
图4至图7的消融实验表明本发明关键模块的有效性。广义矩阵分解模块gmf通过填充缺失数据保证其数据的完整性;簇参数学习机制通过簇内共享-簇间参数特定的方式来保证模型的细粒度性;gcrnn模块中数据驱动的图学习方式使得该模型在时空序列预测任务中更具通用性。图8表示对本发明的关键参数簇数k的分析,该参数决定gcrnn模块中参数的多样性并影响参数量。由图可见,k为2或3时模型效果最佳,表明gcrnn学习2至3类特定参数。该实验结果与交通序列早高峰、晚高峰以及早晚高峰模式相对应。综上可见,本发明在含缺失数据的时空预测任务上极具稳定性、细粒度性和通用性。
[0202]
表1本发明的时空预测模型fcgcrn与其他八个基准方法(baselines)在pems04和pems08(缺失率为10%)数据集上的对比实验结果
[0203][0204]
表2本发明的时空预测模型fcgcrn与其他八个基准方法(baselines)在pems04和pems08(缺失率为30%)数据集上的对比实验结果
[0205][0206]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。