deepfake伪造区域可定位的鉴伪取证方法
技术领域
1.本发明涉及deepfake鉴伪技术领域,特别是涉及一种deepfake伪造区域可定位的鉴伪取证方法。
背景技术:
2.基于深度学习分类模式的deepfake鉴伪方法通过关注像素层面上的篡改痕迹并建立判别模型来进行真伪媒体数据的区分,这类通过深度学习方法直接提取的高维特征是人类无法直观理解的,基于此建立的鉴别模型的取证过程并不符合人类的认知,因此很难对其结果进行可解释性分析。
技术实现要素:
3.本发明的目的是针对现有技术中存在的技术缺陷,而提供一种deepfake伪造区域可定位的鉴伪取证方法。
4.为实现本发明的目的所采用的技术方案是:
5.一种deepfake伪造区域可定位的鉴伪取证方法,包括
6.采用训练好的面部伪造区域定位与鉴别模型对输入图像进行鉴别,该面部伪造区域定位与鉴别模型包括面部伪造区域定位模块以及面部真伪判别模块:
7.所述面部伪造区域定位模块,通过编码操作将获得的输入图像的特征图逐步减小,然后再解码操作,将得到的最终减小的特征图逐步放大到与输入图像相同的分辨率;对放大后的特征图用softmax进行像素分类,得到输入图像的分类结果,实现对输入图像的伪造区域定位;
8.所述面部真伪判别模块,将面部伪造区域定位模块得到的伪造区域定位结果作为输入,通过编码操作降低特征图分辨率,当特征图的分辨率降低为[1,1]时,输入到softmax进行分类,得到输入图像的真伪判别结果,然后将伪造区域在图像中进行可视化展示。
[0009]
进一步的,所述的训练好的面部伪造区域定位与鉴别模型对输入图像进行鉴别之前,还包括以下步骤:
[0010]
对输入数据类型判别:
[0011]
若输入数据为序列数据,则对序列数据进行人脸检测、跟踪、关键点检测、识别操作,将识别出的人脸按照id分别存储为人脸序列;将人脸序列逐帧送入训练好的面部伪造区域定位与鉴别模型中前向传播,得到每帧图像的伪造区域定位与真伪鉴别,并可视化显示;
[0012]
若输入数据为图像,则对图像数据进行人脸检测,将检测出的人脸存储;将裁剪好的人脸图像送入训练好的面部伪造区域定位与鉴别模型中进行前向传播,对输入图像的伪造区域进行定位与真伪判别,并可视化显示;
[0013]
进一步的,对于人脸序列,将同一id的人脸序列中的评分结果进行均值融合,输出每个id的评分结果,同时保存各个id的人脸序列中的伪造区域。
[0014]
其中,所述面部伪造区域定位模块,在编码操作中的每一步中得到的特征图通过pooling indices放大后,拼接到解码操作对应大小的特征图中,以使编码与解码过程中的信息交互,
[0015]
进一步的,当输入为视频时,对得到的判别序列求取均值,得到最终判别结果,若判别结果为fake,则将输入视频每帧对应的伪造区域在输入视频中可视化展示;输入为图像时,若定位到伪造区域,则将伪造区域在图像中进行可视化展示。
[0016]
进一步的,所述面部伪造区域定位与鉴别模型采有图像分割网络训练生成,在训练图像分割网络时,通过以下步骤构建训练用的伪造图像的真伪区域标签:
[0017]
将伪造图像与对应的真实图像做差,获三通道彩色图像;
[0018]
将所述三通道彩色图像灰度化,得到灰度图;
[0019]
对灰度图进行归一化处理,然后再进行二值化操作,对二值化图进行高斯滤波,得到清晰无噪点的标签图,即伪造图像的真伪区域标签。
[0020]
其中,所述图像分割网络采用fcn分割模型、u-net分割模型、segnet分割模型、mask-rcnn分割模型以及deeplab-v2分割模型的一种。
[0021]
其中,训练图像分割网络时,所述真实图像的输入分辨率112*112或224*224,高斯滤波用的高斯滤波器的高斯核大小为5或11。
[0022]
本发明的deepfake伪造区域可定位的鉴伪取证方法,通过利用深度神经网络模型可视化技术,实现模型决策过程的可视化,为预测结果的可解释依据,实现取证结论有据和结果可视。
附图说明
[0023]
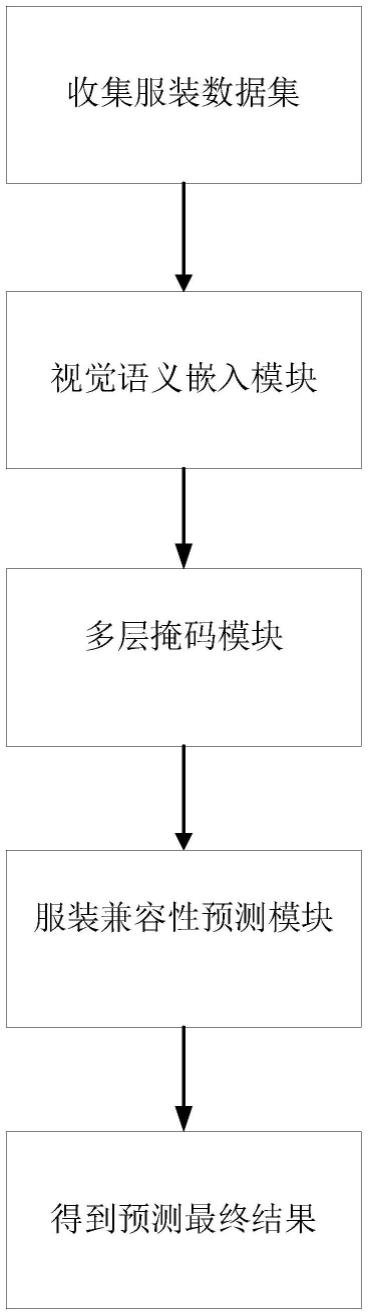
图1是本发明的deepfake伪造区域可定位的鉴伪取证方法检测示意图。
[0024]
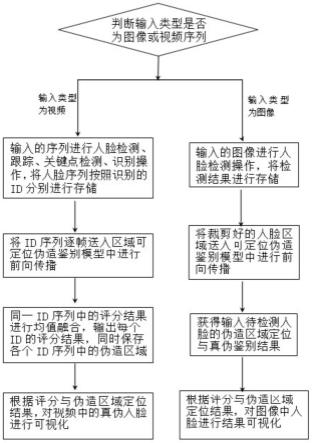
图2为本发明的面部伪造区域定位与鉴别模型检测过程示意图。
[0025]
图3为pooling indices操作的示意图。
[0026]
图4为本发明的构建伪造图像的真伪区域标签的过程示意图。
[0027]
图5为在不同分辨率的图像中使用不同大小高斯核得到的滤波结果图。
[0028]
图6为采用不同的分割网络进行训练,得到的真伪定位结果图。
具体实施方式
[0029]
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0030]
如图1-图2所示,本发明实施例的基于多时序注意力网络对人脸伪造视频检测方法,采用以下步骤实现:
[0031]
判断输入的数据类型,即判断输入的数据为视频,还是图像;
[0032]
当输入为视频时,首先利用解码方法对视频进行解码,得到图像序列,然后利用人脸检测方法在图像序列中检测人脸位置,在人脸检测中加入面部跟踪方法进行跟踪,并通过人脸识别,将视频中的人物按照id进行存储,从而得到每个id对应的人脸序列;
[0033]
将人脸序列逐帧送入训练好的面部伪造区域定位与鉴别模型中前向传播,得到每帧图像的伪造区域定位与真伪鉴别,并可视化显示;
[0034]
通过人脸跟踪技术,可以提升人脸检测的精度与效率,通过人脸识别,可能解决视频中存在多人且有人物遮挡的情况。
[0035]
当输入为图像时,直接利用人脸检测方法检测人脸位置即可。然后。将检测出的人脸存储;将裁剪好的人脸图像送入训练好的面部伪造区域定位与鉴别模型中进行前向传播,对输入图像的伪造区域进行定位与真伪判别,并可视化显示。
[0036]
上述的实施例中,所涉及的人脸检测方法,人脸跟踪以及人脸识别技术以及解码方法均为现有技术,不再说明。
[0037]
其中,对于人脸序列,将同一id的人脸序列中的评分结果进行均值融合,输出每个id的评分结果,同时保存各个id的人脸序列中的伪造区域。
[0038]
本发明实施例中,所述面部伪造区域定位与鉴别模型,包括面部伪造区域定位模块以及面部真伪判别模块,其可以通过以下的步骤实现面部伪造区域定位与鉴别,参见图2所示:
[0039]
所述的面部伪造区域定位模块,通过编码操作将获得的输入图像的特征图逐步减小,然后再解码操作,将得到的最终减小的特征图逐步放大到与输入图像相同的分辨率;对放大后的特征图用softmax进行像素分类,得到输入图像的分类结果,实现对输入图像的伪造区域定位;
[0040]
所述的面部真伪判别模块,将面部伪造区域定位模块得到的伪造区域定位结果作为输入,通过编码操作降低特征图分辨率,当特征图的分辨率降低为[1,1]时,输入到softmax进行分类,得到输入图像的真伪判别结果,然后将伪造区域在图像中进行可视化展示。
[0041]
图2所示为训练好的面部伪造区域定位与鉴别模型对deepfake伪造区域定位、鉴别的过程图,为显示简洁,图示未展示从输入视频通过人脸裁剪得到人脸序列的过程,只显示从人脸序列输入到伪造区域定位、真伪鉴别的过程。包含三个模块,分别为图像序列输入模块、面部伪造区域定位模块,面部真伪判别模块,不同的模块用不同的线框进行区分。
[0042]
图像序列输入模块中,可以接受视频与图像两种模式的输入,当输入为图像序列时,将图像按照序列顺序输入面部伪造区域定位模块,上图中,图像序列输入模块中白框所在的图像,为待输入面部伪造区域定位模块的图像。当输入为单张图像时,将图像直接输入面部伪造区域定位模块即可。
[0043]
面部伪造区域定位模块中,对于输入的图像,先采用encoder操作,即通过交替采用conv pooling,将特征图逐步减小,从而达到聚合输入图像中的信息的目的,然后采用decoder操作,通过交替采用deconv upsampling将decoder得到的特征图逐步放大到与输入图像相同的分辨率,对特征图用softmax做像素分类,趋近0代表real,趋近1代表fake,使特征图中的每个像素值就代表对输入图像的分类结果,从而达到对输入图像中伪造区域定位的目的。
[0044]
在图中不同的特征图运算采用不同的颜色区分,需要注意的是,为保留encoder与decoder过程中的信息交互,encoder每一步中得到的特征图通过pooling indices放大后,拼接到decoder对应大小的特征图中。
[0045]
在面部真伪判别模块,将面部伪造区域定位模块得到的伪造区域定位结果作为输入,通过交替采用conv pooling降低特征图分辨率,当特征图分辨率降低为[1,1]时,将其
输入softmax做分类,从而得到输入图像的真伪判别结果。
[0046]
从图2可以看到,在模型进行伪造区域定位、面部真伪鉴别的过程是针对视频中的帧单独进行的,并不涉及帧间信息,因此本发明的方法既适用于输入为视频的取证任务,也适用于输入为图像的取证任务。
[0047]
相应的,当输入为视频时,需要对鉴别模块得到的判别序列求取均值,进而得到最终判别结果,若判别结果为fake,则将输入视频每帧对应的伪造区域在输入视频中进行可视化展示。输入为图像时,若定位到伪造区域,则直接将伪造区域在图像中进行可视化展示。
[0048]
图3所示为pooling indices过程,假设图3左侧第一幅图为encoder中需要放大的特征图,为了在放大后的特征图中保留位置信息,先将图3中左侧第一幅图的参数置于放到后的图3中的中间的第二幅图的左上角的位置,然后剩余位置补0即可得到图3中右侧的图中所示放大后的特征图。
[0049]
相比于其他upsampling操作,pooling indices在保留参数数值与位置信息的同时,不需要其他额外的运算,可以有效节省内存与运行时间,更有利于后续工程部署。
[0050]
本发明实施例中,所述面部伪造区域定位与鉴别模型采有图像分割网络训练生成,在训练图像分割网络时,需要先构建训练用的伪造图像的真伪区域标签。
[0051]
图4所示为构建伪造图像的真伪区域标签的过程。
[0052]
目前的deepfake数据库中,真实数据与伪造数据往往存在对应关系,本发明实施例以kaggle竞赛中dfdc数据集为例,图4中第一列为伪造图像,第二列为伪造图像对应的真实图像,subtarct列为伪造图像与真实图像做差后取绝对值的结果,从图4中可以看到,该列为三通道彩色图像,为了方便后续操作,将其进行灰度化,得到第四列所示的gray图像。gray图像由于是直接做差的结果,所以灰度值比较集中,对比度不高,为了更好的区分真实区域与伪造区域,对灰度图进行归一化处理,得到了norm列所示的图像,该列图像相比gray较为清晰,但真伪区分性依然不足,进一步的对norm.列图像进行二值化操作,得到图示binary列所示的图像,该列图像真实与伪造区域区分性明显,但由于图像压缩、位移等问题,在binary列中的图像在边缘处有很多噪点。
[0053]
为处理早点问题,对binary列的图像进行高斯滤波,尝试多种高斯核,最终得到清晰无噪点的标签图,即图4所示的gaussian列所示图像,图4所示的gaussian列所示图像即为伪造图像的真伪区域标签,将该列图像用于分割模型的训练,完成了分割模型或分割网络的训练,最终形成了本发明的面部伪造区域定位与鉴别模型。值得注意的是,对于真实图像,因为图像中没有伪造区域,因此真实图像的定位标签为纯黑图像。
[0054]
图5所示为在不同分辨率的图像中使用不同大小高斯核得到的滤波结果。
[0055]
为了选取最优的高斯核,本发明实施例选取目前主流网络的输入分辨率(112,112)与(224.224),同时将[1,15]范围内的高斯核在待平滑图像上进行遍历(高斯核大小只能为奇数)。
[0056]
从上图可以看到,当高斯核大小为1时,代表对待平滑图像不做任何操作,此时图像中的噪点较多,随着高斯核的增大,图像中的噪点逐步减少,当高斯核选取合适时,可以得到清晰无噪点的真伪定位标签(白色区域为伪造,黑色区域为真实),当高斯核继续增大,标签中有效信息逐步减少,错误标签增多,此时的错误标签主要是将输入图像中的伪造区
域标注为真实区域。
[0057]
通过实验比对,当输入人脸图像的大小为(112,112)时,高斯滤波器的大小为5可以得到最优的真伪定位标签,当输入人脸的大小为(224,224)时,高斯滤波器的大小为11可以得到最优的真伪定位标签。
[0058]
因此,本发明实施例中,在训练图像分割网络时,所述真实图像的输入分辨率112*112或224*224,高斯滤波用的高斯滤波器的高斯核大小为5或11。
[0059]
其中,所述图像分割网络采用fcn分割模型、u-net分割模型、segnet分割模型、mask-rcnn分割模型以及deeplab-v2分割模型的一种。
[0060]
为了验证上述的不同的分割网络或模型的分割效果,对多个分割模型进行了训练,图6所示为采用不同的分割网络进行训练,得到的真伪定位结果。
[0061]
图6中第一列为真实图像,第二列为真实图像生成的伪造图像;
[0062]
第三列为伪造图像中真伪区域的标签,其中,白色部分代表伪造区域,黑色部分代表真实区域。
[0063]
第四列代表面部伪造区域定位模块选用现有fcn分割模型进行真伪区域定位的结果,从结果中可以看到,定位到的伪造区域较为模糊。
[0064]
第五列代表面部伪造区域定位模块选用现有u-net分割模型进行真伪区域定位的结果,对于第四行图像的定位较为模糊,部分真实区域被判别为伪造区域。
[0065]
第六列代表面部伪造区域定位模块选用现有segnet分割模型进行真伪区域定位的结果,从图中可以看到,segnet方法精度较高,得到的真伪区域与ground truth接近。
[0066]
第七列代表面部伪造区域定位模块选用现有mask-rcnn分割模型进行真伪区域定位的结果,从图中可以看到,真伪定位区域模糊且轮廓不清晰。
[0067]
第八列代表面部伪造区域定位模块选用现有deeplab-v2分割模型进行真伪区域定位的结果,该方法对于第一行图像的定位误差偏大,真实区域误判为伪造区域的情况较多。
[0068]
通过实验比对可知,segnet用于面部伪造区域定位模块,伪造区域定位的精度更高。
[0069]
为更好的评价区域定位带来的精度提升与不同分割方法在精度上的差异,将kaggle竞赛中的dfdc数据集作为训练集合,celeb-df作为测试集。dfdc数据集共包含19154个真实视频,99992个伪造视频,真实视频与伪造视频间存在对应关系。
[0070]
celeb-df包含590个真实视频与5639个伪造视频,为了保证实验的充分,我们将dfdc数据集按照任务id将其均匀的分为五份,分别为dfdc-1,dfdc-2,dfdc-3,dfdc-4,dfdc-5,然后分别独立训练,再用celeb-df数据集进行测试,具体的测试结果如下:
[0071] dfdc-1dfdc-2dfdc-3dfdc-4dfdc-5only-classfication94.193.993.694.393.8fcn classfication96.897.296.597.496.5u-net classfication97.097.696.998.197.8segnet classfication98.698.598.298.998.3maskrcnn classfication98.298.398.698.497.9deeplab classfication97.997.797.897.698.0
[0072]
表1
[0073]
上表中only-classfication代表只有分类网络,没有区域定位网络,其他方法代表面部伪造区域定位模块选用不同分割方法。从上表中可以看到segnet用于区域真伪定位精度最高,且再多个子数据集中,精度稳定。
[0074]
以上所述仅是本发明的优选实施方式,应当指出的是,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。