1.本发明涉及计算机技术领域,具体涉及一种信息处理方法、装置、电子设备和可读存储介质。
背景技术:
2.关键词是一段文本中最具代表性的文字。关键词提取又称主题词提取,是自然语言处理中的一个重要领域。
3.现有的关键词提取方法主要包括监有监督方法和无监督方法。在有监督方法中,通常根据已经标注好的预料训练关键词提取模型,并通过训练之后的关键词提取模型进行关键词提取。而在无监督方法中,通常是基于词频和图方法来实现关键词提取。然而,由于同一个词在不同场景中的词性和代表实体不同,或者关键词所在标题存在噪音信息或者词汇排布方式随意性较强时,对于同一标题中关键词的提取结果之间差异性大,提取的准确度仍有待提高。
技术实现要素:
4.有鉴于此,本发明实施例提供一种信息处理方法、装置、电子设备和可读存储介质,以提高关键词提取的准确度。
5.第一方面,本发明实施例提供一种信息处理方法,所述方法包括:
6.获取目标对象的对象信息,所述对象信息包括对象标题信息、类别信息和描述信息;
7.对所述对象标题信息进行关键词识别,以确定初始识别结果;
8.根据所述初始识别结果、类别信息和描述信息对所述初始识别结果进行识别,以确定所述对象标题信息中的关键词。
9.进一步地,所述对所述对象标题信息进行关键词识别,以确定初始识别结果包括:
10.根据所述对象标题信息、类别信息和描述信息对所述对象标题信息进行关键词识别,以确定初始识别结果。
11.进一步地,所述根据所述对象标题信息、类别信息和描述信息对对象标题信息进行关键词识别,以确定初始识别结果包括:
12.获取对象标题信息、类别信息和描述信息中每个词对应的特征向量;
13.通过预设的第一神经网络对各所述特征向量进行处理,确定每个词被标注为各标签的概率;
14.根据所述概率标注所述对象标题信息中每个词的标签;
15.根据各词的标签和词属性确定所述初始识别结果,所述词属性用于表征所述词与所述对象标题信息、类别信息或描述信息相对应。
16.进一步地,所述根据所述初始识别结果、类别信息和描述信息对所述初始识别结果进行识别,以确定所述对象标题信息中的关键词包括:
17.将所述初始识别结果、类别信息和描述信息输入至预设的第二神经网络,确定各词与各分类类别的映射关系;
18.根据所述映射关系确定各词对应的目标标签;
19.将各目标标签对应的词确定为所述对象标题信息中的关键词。
20.进一步地,所述获取目标对象的对象信息包括:
21.获取目标对象的初始标题信息;
22.对所述初始标题信息进行预处理,以确定所述对象标题信息。
23.进一步地,所述对所述初始标题信息进行预处理,以确定所述对象标题信息包括:
24.对所述初始标题信息进行纠错处理,以确定第一预处理结果;
25.对所述第一预处理结果中的无用信息进行消除,以确定所述对象标题信息。
26.进一步地,所述获取目标对象的对象信息包括:
27.基于预设的分类方法确定所述目标对象的类别信息。
28.进一步地,所述获取目标对象的对象信息包括:
29.基于预设的信息检索方法确定所述目标对象的描述信息。
30.第二方面,本发明实施例提供一种信息处理装置,所述装置包括:
31.获取模块,用于获取目标对象的对象标题信息;
32.第一识别模块,用于对所述对象标题信息进行关键词识别,以确定初始识别结果;
33.第二识别模块,用于根据所述初始识别结果、类别信息和描述信息对所述初始识别结果进行识别,以确定所述对象标题信息中的关键词。
34.进一步地,所述第一识别模块包括:
35.初始识别子模块,用于根据所述对象标题信息、类别信息和描述信息对所述对象标题信息进行关键词识别,以确定初始识别结果。
36.进一步地,所述初始识别子模块包括:
37.特征单元,用于获取对象标题信息、类别信息和描述信息中每个词对应的特征向量;
38.概率单元,用于通过预设的第一神经网络对各所述特征向量进行处理,确定每个词被标注为各标签的概率;
39.标签单元,用于根据所述概率标注所述对象标题信息中每个词的标签;
40.初始确定单元,用于根据各词的标签和词属性确定所述初始识别结果,所述词属性用于表征所述词与所述对象标题信息、类别信息或描述信息的对应关系。
41.进一步地,所述第二识别模块包括:
42.映射子模块,用于将所述初始识别结果、类别信息和描述信息输入至预设的第二神经网络,确定各词与各分类类别的映射关系;
43.第二确定子模块,用于根据所述映射关系确定各词对应的目标标签,将各目标标签对应的词确定为所述对象标题信息中的关键词。
44.进一步地,所述获取模块包括:
45.获取子模块,用于获取目标对象的初始标题信息;
46.预处理子模块,用于对所述初始标题信息进行预处理,以确定所述对象标题信息。
47.进一步地,所述预处理子模块包括:
48.第一处理单元,用于对所述初始标题信息进行纠错处理,以确定第一预处理结果;
49.第二处理单元,用于对所述第一预处理结果中的无用信息进行消除,以确定所述对象标题信息。
50.进一步地,所述获取子模块包括:
51.类别获取单元,用于基于预设的分类方法确定所述目标对象的类别信息。
52.进一步地,所述获取子模块包括:
53.描述获取单元,用于基于预设的信息检索方法确定所述目标对象的描述信息。
54.第三方面,本发明实施例提供一种计算机程序产品,包括计算机程序/指令,所述计算机程序/指令被处理器执行时实现如上任一项所述的方法。
55.第四方面,本发明实施例提供一种电子设备,包括存储器和处理器,所述存储器用于存储一条或多条计算机程序指令,其中,所述一条或多条计算机程序指令被所述处理器执行以实现如上所述的方法。
56.第五方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的方法步骤。
57.本发明实施例的技术方案通过执行初次识别过程确定初始识别结果,并根据初始识别结果、类别信息和描述信息对初始识别结果进行识别,确定对象标题信息中的关键词。由此,通过初次识别过程和二次识别过程确定出对象标题信息中的关键词,提高关键词提取的准确度。同时,在识别关键词时,通过结合目标对象的类别信息和描述信息进行识别,能够进一步提高对象信息中关键词提取的准确度。
附图说明
58.通过以下参照附图对本发明实施例的描述,本发明的上述以及其它目的、特征和优点将更为清楚,在附图中:
59.图1是本实施例的信息处理方法的流程图;
60.图2是本实施例的信息处理方法实施时的流程图;
61.图3是本实施例的获取对象标题信息的流程图;
62.图4是本实施例的确定初始识别结果的流程图;
63.图5是本实施例的模型训练的流程图;
64.图6是本实施例的确定对象标题信息中关键词的流程图;
65.图7是本实施例的信息处理装置的示意图;
66.图8是本实施例的信息处理装置的另一示意图;
67.图9是本实施例的电子设备的示意图。
具体实施方式
68.以下基于实施例对本发明进行描述,但是本发明并不仅仅限于这些实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。为了避免混淆本发明的实质,公知的方法、过程、流程、元件和电路并没有详细叙述。
69.此外,本领域普通技术人员应当理解,在此提供的附图都是为了说明的目的,并且
附图不一定是按比例绘制的。
70.除非上下文明确要求,否则在说明书的“包括”、“包含”等类似词语应当解释为包含的含义而不是排他或穷举的含义;也就是说,是“包括但不限于”的含义。
71.在本发明的描述中,需要理解的是,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,在本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
72.关键词提取技术对于快速了解和掌握目标对象具有重要意义。现有的关键词提取过程常采用单一算法模型对标题内容进行单次识别,进而确定标题中的关键词,但识别的准确度仍有待提高。有鉴于此,本发明实施例旨在提供一种信息处理方法,以提高关键词提取的准确度。
73.在电商领域中,由于商品标题中通常包括商品的实体、修饰属性、产地、品牌、品级和规格等多种信息,通过对商品标题中的关键词进行提取,能够便于用户了解和比较不同商品,并通过提取到的商品信息指导下一步决策。基于此,本实施例以商品标题中关键词的识别为例对信息处理方法进行说明。同时,应理解,本实施例中的方法能够应用于各种需要提取关键词的场景,此处并不对此进行限制。
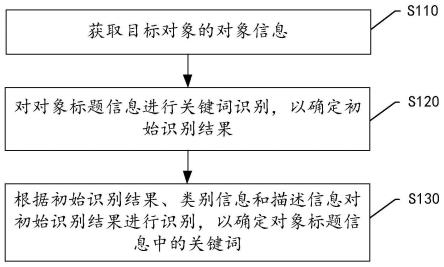
74.图1是本实施例的信息处理方法的流程图。如图1所示,本实施例的信息处理方法包括以下步骤:
75.在步骤s110,获取目标对象的对象信息。其中,对象信息包括对象标题信息、类别信息和描述信息。
76.在步骤s120,对对象标题信息进行关键词识别,以确定初始识别结果。
77.可选地,本实施例中在确定初始识别结果时,可以直接对对象标题信息进行关键词识别确定初始识别结果,也可以结合类别信息和描述信息对对象标题信息进行关键词识别,进而确定初始识别结果。
78.本实施例中,为了进一步提高关键词提取的准确度,本实施例中的对所述对象标题信息进行关键词识别,以确定初始识别结果包括:根据所述对象标题信息、类别信息和描述信息对所述对象标题信息进行关键词识别,以确定初始识别结果。
79.在步骤s130,根据初始识别结果、类别信息和描述信息对初始识别结果进行识别,以确定对象标题信息中的关键词。
80.本发明实施例的技术方案通过执行初次识别过程确定初始识别结果,并根据初始识别结果、类别信息和描述信息对初始识别结果进行识别,确定对象标题信息中的关键词。由此,通过初次识别过程和二次识别过程确定出对象标题信息中的关键词,提高关键词提取的准确度。同时,在识别关键词时,通过结合目标对象的类别信息和描述信息进行识别,能够进一步提高对象信息中关键词提取的准确度。
81.图2是本实施例的信息处理方法实施时的流程图。如图2所示,本实施例的信息处理方法包括以下步骤。
82.在步骤s210,获取目标对象的对象信息。
83.本实施例中,目标对象的对象信息包括对象标题信息、分类信息和描述信息。在获取目标对象的对象信息时,包括获取目标对象的对象标题信息,获取目标对象的分类信息以及获取目标对象的描述信息。其中,对象标题信息、分类信息和描述信息可以存储于同一
位置,并在使用时同时获取;或者对象标题信息、分类信息和描述信息可以分别存储在不同位置,并在使用时分别调用,以获取对应信息。并且,为了便于区分信息内容,各目标对象的对象标题信息、分类信息和描述信息分别具有唯一标识,通过各信息的唯一标识能够确定使用的是对象标题信息、分类信息或描述信息。
84.可选地,如图3所示,本实施例在获取对象标题信息时,基于以下步骤实现。
85.在步骤s310,获取目标对象的初始标题信息。
86.可选地,本实施例中的初始标题信息可以根据orc识别方法获取。其中,orc(optical character recognition,光学字符识别)是指电子设备检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
87.在步骤s320,对初始标题信息进行预处理,以确定对象标题信息。
88.为提高目标对象标题信息中关键词提取进程顺利进行,本实施例中在获取到目标对象的初始标题信息之后,会对初始标题信息进行预处理,以提高后续关键词识别的准确度。
89.可选地,本实施例中对初始标题信息进行预处理时,具体包括下面的步骤。
90.在步骤s321,对初始标题信息进行纠错处理,以确定第一预处理结果。
91.本实施例中,在获取到目标对象的初始标题信息之后,会对初始标题信息进行纠错处理,通过对比标题信息中的词与预设纠错词库中的词确定识别错误的词,并对识别错误的词进行纠正,进而确定出第一预处理结果。
92.例如,标题信息【aa酸酸乳原味250ml/盒】中的【250ml/盒】(这里是英文“l”)容易被识别成【250m1/盒】(这里是数字“1”)。在对获取到的初始标题信息为【aa酸酸乳原味250ml/盒】进行纠错处理时,首先将标题信息中的词与预设纠错词库中的词进行对比,确定初始标题信息中的【250ml/盒】(这里是英文“l”)被识别成了【250m1/盒】(这里是数字“1”),并通过自动纠正方法对【250m1/盒】进行纠正,进而确定初始标题信息对应的第一预处理结果为【aa酸酸乳原味250ml/盒】。
93.在步骤s322,对第一预处理结果中的无用信息进行消除,以确定对象标题信息。
94.本步骤中,无用信息包括噪音信息和无关信息。其中,噪音信息包括标题信息中的会对关键词识别产生干扰的附加信息,例如标题信息【aa(xxxx)酸酸乳250ml*24包/箱】中的“xxxx”(如:品牌aa对应的拼音)。无关信息包括标题信息中对关键词识别不存在帮助的附加信息,例如标题信息【(补充蛋白质!)4-5月aa酸酸乳草莓250ml*24盒】中的“补充蛋白质!”。
95.可选地,本实施例在对第一预处理结果中的无用信息进行消除时,依次消除第一预处理结果中的噪音信息和无用信息。应理解,为了便于标题信息的处理,本实施例中的噪音信息和无关信息在标题信息中均会以特殊的形式表达(例如,加()表示)。
96.可选地,本实施例中在消除无用信息时,首先通过将标题信息与噪音词库进行对比确定噪音信息,并在确定噪音信息后采取相应策略消除噪音信息,确定第二预处理结果。噪音信息消除后,对消除噪音信息后的标题信息中的无用信息进行消除,并将消除噪音信息和无用信息之后的标题信息确定为对象标题信息。
97.本实施例的技术方案在获取目标对象的初始标题信息之后,通过对初始标题信息中识别错误的词进行纠错处理确定出第一预处理结果,在确定出第一预处理结果中的噪音
信息后,对噪音信息进行消除,确定第二预处理结果,并在获取到第二预处理结果之后对其中的消除信息进行消除,从而确定出目标对象的对象标题信息。
98.可选地,本实施例在获取目标对象的类别信息时,基于预设的分类方法确定所述目标对象的类别信息。
99.进一步地,本实施例中的预设的分类方法可以采用knn算法(k-nearestneighbor,邻近算法)来计算对应目标商品的类别信息。knn算法是一种用于分类和回归的监督学习算法,通过目标对象最邻近的多个样本的类别来确定目标对象所属类别,具体计算过程为首先计算目标对象与已知类别的对象之间的距离,按照距离递增次序排序,选取与目标对象距离最小的k(k为大于1的自然数)个点,确定前k个点所在类别的出现次数,并将出现次数最高的类别确定为目标对象的预测分类,最后将所述预测分类确定为目标对象的分类信息。由此,本实施例通过上述过程实现目标对象分类信息的获取。
100.可选地,本实施例在获取目标对象的描述信息时基于预设的信息检索方法确定所述目标对象的描述信息。
101.进一步地,本实施例中的预设的信息检索方法采用tf-idf(term frequency,词频-逆向文件频率)算法来提取目标对象的描述信息。tf-idf算法是一种用于信息检索与文本挖掘的常用加权技术,根据字词在文件集或语料库中出现的频率确定字词的重要程度。由此,本实施例通过tf-idf算法确定目标对象相关字词的重要程度,并根据重要程度确定出目标对象的描述信息。
102.在步骤s220,根据对象标题信息、分类信息和描述信息对对象标题信息进行关键词识别,以确定初始识别结果。
103.图4是本实施例的确定初始识别结果的流程图。如图4所示,本实施例在确定初始识别结果时,包括以下步骤:
104.在步骤s410,获取对象标题信息、类别信息和描述信息中每个词对应的特征向量。
105.本实施例中,为了提高对象标题信息中关键词提取的准确度,在获获取目标对象的初始标题信息时,会同时获取目标对象的类别信息和描述信息,并将类别信息和描述信息作为初始标题信息的上下文信息,以辅助目标对象的对象标题信息中关键词的提取,进而通过采用更加全面的相关信息提高关键词提取的准确度和提取效率。
106.可选地,在获取到对象标题信息、类别信息和描述信息之后,再获取对象信息、类别信息和描述信息中每个词对应的特征向量,每个特征向量具有与信息来源相对应的标识信息,通过特征向量的标识信息可以确定出特征向量对应的是对象标题信息、分类信息或者描述信息,从而便于确定信息来源。
107.在步骤s420,通过预设的第一神经网络对各特征向量进行处理,确定每个词被标注为各标签的概率。
108.可选地,本实施例中的标签类型包括实体(n)、修饰属性(a),产地(l),品牌(b),品级(g)和规格(s)。例如:对象标题信息【bb亲肤手帕纸10包】中的bb“bb”对应标签为品牌,“亲肤”对应标签为修饰属性,“手帕纸”对应标签为实体,“10包”对应标签为规格。对象标题信息【海南妃子笑荔枝500g/份】中“海南”对应标签为产地,“妃子笑”对应标签为品牌,“荔枝”对应标签为实体,“500g/份”对应标签为规格。
109.本实施例中,在将对象信息输入至预设的第一神经网络模型后,通过模型处理确
定出每个词被标注为各标签的概率。以对象标题信息【bb亲肤手帕纸10包】中的“手帕纸”为例,通过将标题信息输入至预设的第一网络模型,从而确定“手帕纸”分别被标注为实体、修饰属性、产地、品牌、品级和规格的概率。
110.可选地,本实施例中的预设的第一神经网络采用bi-lstm-crf模型。bi-lstm-crf模型是一种序列标注模型,所述模型的网络结果包括表示层、bilstm层和crf层。其中,表示层将每个句子表示为词向量和字向量,bilstm层对词向量或字向量进行处理,并输出句子中国每个词的所有标签的各自得分。crf层使用bilstm层的输出(每个词的所有标签的各自得分),即(发射概率矩阵)以及转移概率矩阵,作为原始crf模型的参数,并获得标签序列的概率。
111.本实施例中,bi-lstm-crf模型为预先训练得到的模型。如图5所示,本实施例在进行模型训练时,包括以下步骤:
112.在步骤s510,获取训练数据中目标对象的对象信息,对象信息包括初始标题信息、类别信息和描述信息。
113.在步骤s520,对初始标题信息进行纠错处理,以确定第一预处理结果。
114.在步骤s530,对第一预处理结果中的无用信息进行消除,以确定对象标题信息。
115.本实施例中,步骤s410-s430中的内容与前文中获取目标对象的对象信息、确定第一预处理结果和确定对象标题信息的方法一致,此处不再赘述。
116.在步骤s540,对对象标题信息中不同标签的关键词进行标注。
117.可选地,本实施例中基于bio标注(一种序列标注方法)根据不同的标签类型对训练数据中的对象标题信息进行标注。例如,对象标题信息【bb亲肤手帕纸10包】中的“bb”标注为品牌,“亲肤”标注为修饰属性,“手帕纸”标注为实体,“10包”标注为规格。对象标题信息【海南妃子笑荔枝500g/份】中“海南”标注为产地,“妃子笑”标注为品牌,“荔枝”标注为实体,“500g/份”标注为规格。
118.可选地,本实施例中还可以根据词性(包括名词、形容词和感叹词等)对对象标题信息中的词进行标注,以解决一词多词性下关键词对目标对象的对象标题信息中关键词提取的影响。
119.在步骤s550,将训练数据中目标对象对应的分类信息、描述信息和标注后的对象信息输入至待训练模型中进行训练,以确定预设的第一神经网络。
120.由此,通过以上步骤对预设的第一神经网络模型进行训练,并将训练得到的模型用于本实施例中的关键词识别过程。
121.在步骤s430,根据概率标注对象标题信息中每个词的标签。
122.本实施例中,根据对象标题信息中各词分别被标注为不同标签的概率值确定各词分别对应的标签。可选地,将各词被标注概率最大的标签确定为对应的标签。例如,对象标题信息【bb亲肤手帕纸10包】中的“手帕纸”被标注为实体、修饰属性、产地、品牌、品级和规格的概率分别为1、0.2、0、0.3、0.4和0,也即“手帕纸”被标注为实体的概率最大,则“手帕纸”对应的标签为实体。采用同样的方法,可以确定出“bb”为品牌,“亲肤”为修饰属性,“10包”为规格。
123.在步骤s440,根据各词的标签和词属性确定初始识别结果。其中,词属性用于表征所述词与所述对象标题信息、类别信息或描述信息的对应关系。
124.本实施例中,由于输入至预设的神经网络的数据包括对象标题信息、分类信息和描述信息,在确定各词标签时,也会确定出分类信息和描述信息中各词对应的标签。可选地,本实施例中的词属性可以采用前文所述的对象标题信息、分类信息和描述信息分别对应的唯一标识,也可以采用各信息对应特征向量采用的标识信息。基于此,本实施例中通过词属性对确定标签之后的各词进行统一整理,进而确定出对象标题信息对应的初始识别结果。
125.可选地,沿用上面的例子,本实施例中能够快速确定出对象标题信息【bb亲肤手帕纸10包】中的实体为“手帕纸”、修饰属性为“亲肤”、品牌为“bb”以及规格为“10包”。
126.本实施例的技术方案通过获取目标对象的对象标题信息、分类信息和描述信息中每个词对应的特征向量,通过预设的第一神经网络对特征向量进行处理,确定每个词被标注为各标签的概率,选取各词被标注为各标签的概率标注对象标题信息中每个词的标签,并根据各词的标签和词属性确定初始识别结果。
127.在步骤s230,根据初始识别结果、类别信息和描述信息对初始识别结果进行识别,以确定对象标题信息中的关键词。
128.本实施例中,为了验证初始识别结果的准确性或者初始识别结果中同一标签对应有多个词时,会根据初始识别结果、类别信息和描述信息对初始识别结果继续进行识别,以根据实际场景需要确定出更加准确的关键词,提高对象标题信息中关键词提取的准确度。
129.例如,对于对象标题信息【鎏金鱼子精华护肤套装1套洗面奶 精华水 精华乳 补水喷雾 精华原液】,经过首次关键词识别过程后,确定的初始识别结果中实体标签对应的关键词有“护肤套装”、“洗面奶”、“精华水”、“精华乳”、“补水喷雾”和“精华原液”,并且这些实体对应的关键词均是符合预期的结果。而对于对象标题信息【cc小小汤圆组合装黑芝麻花生草莓】,对应的初始识别结果中的实体关键词有“汤圆”、“黑芝麻”、“花生”和“草莓”。由于黑芝麻、花生和草莓在本对象标题信息中是修饰属性,而不是实体,也即初始识别结果与预期识别结果存在较大差别,需要对初始识别结果继续进行识别,以使最终获取到的实体为“汤圆”。
130.下面以初始识别结果中存在多个不符合预期实体的情况为例对二次识别过程进行说明。
131.图6是本实施例的确定对象标题信息中关键词的流程图。如图6所示,本实施例通过以下步骤确定对象标题信息中的关键词。
132.在步骤s610,将初始识别结果、类别信息和描述信息输入至预设的第二神经网络,确定各词与各分类类别的映射关系。
133.本实施例中的预设的第二神经网络采用贝叶斯模型。其中,贝叶斯模型是一种常用的分类模型,对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,概率最大的类别即为待分类项对应的类别
134.以对象标题信息【cc小小汤圆组合装黑芝麻花生草莓】为例,其类别信息和摘要信息均是以冷冻食品和汤圆为主题,通过将初始识别结果、类别信息和描述信息输入至预设的第二神经网络可以确定初始识别结果中实体对应的各关键词与冷冻食品类别的映射关系。
135.在步骤s620,根据所述映射关系确定各词对应的目标标签。
136.在步骤s630,将各目标标签对应的词确定为对象标题信息中的关键词。
137.本实施例中,在确定初始识别结果中各词对应的映射关系后,通过映射关系确定各词对应的目标标签,并将各目标标签对应的词确定为对象标题信息中的关键词。沿用上面的示例,通过预设的第二神经网络,可以确定“黑芝麻”、“花生”和“草莓”对应的标签为修饰属性,而“汤圆”对应的标签为实体,由此确定对象标题信息【cc小小汤圆组合装黑芝麻花生草莓】中的实际实体为“汤圆”。
138.可选地,当对象标题信息中的实体为组合词时,还可以通过在预设的第二神经网络中增加词库信息的方式对初始识别结果进行识别,进而确定目标标签对应的关键词。例如,对象标题信息【安徽酥脆苹果梨500g/份】对应的初始识别结果中,实体标签对应的词为“苹果”,和“梨”,然而这里面的实体既不是苹果,也不是梨,而是苹果梨,对于这类特殊的实体,只在模型中添加一些词库信息,即可使得模型最终输出的实体是苹果梨。
139.本发明实施例的技术方案通过将初始识别结果、类别信息和描述信息输入至预设的第二神经网络,确定各词与各分类类别的映射关系,根据所述映射关系确定各词对应的目标标签,并将各目标标签对应的词确定为对象标题信息中的关键词,使得最终提取到的关键词更加符合实际进而提高关键词提取的准确度。同时,由于上述过程中对初始识别结果进行识别,能够减少预设的第二神经网络对对象标题信息进行再次识别的流程,以及模型识别过程中的模型计算量,从而加快关键词提取的整体流程,提高关键词提取效率。另外,当对象标题信息中的词排布位置随意性大时,通过结合分类信息和描述信息能够补充足够的上下文信息,并结合初始识别结果和上下文信息进行识别,能够加快关键词提取的进程,提高关键词提取效率。
140.图7是本实施例的信息处理装置的示意图。如图7所示,本实施例的信息处理装置包括获取模块1、第一识别模块2和第二识别模块3。其中,获取模块1用于获取目标对象的对象标题信息。第一识别模块2用于对对象标题信息进行关键词识别,以确定初始识别结果。第二识别模块3用于根据初始识别结果、类别信息和描述信息对初始识别结果进行识别,以确定所述对象标题信息中的关键词。
141.本实施例的技术方案通过获取模块获取目标对象的对象标题信息,第一识别模块对对象标题信息进行关键词识别,确定初始识别结果,第二识别模块根据初始识别结果、类别信息和描述信息对初始识别结果进行识别,进而确定所述对象标题信息中的关键词。由此,通过对对象标题信息进行两次关键词识别过程,有利于提高目标对象的对象标题信息中关键字提取的准确度。
142.可选地,如图8所示,本实施例的获取模块1包括获取子模块11和预处理子模块12。获取子模块11用于获取目标对象的初始标题信息。预处理子模块12用于对初始标题信息进行预处理,以确定所述对象标题信息。
143.进一步地,本实施例的获取子模块11包括标题获取单元111、类别获取单元112和描述获取单元113。标题获取单元111用于获取目标对象的对象标题信息。类别获取单元112用于基于预设的分类方法确定所述目标对象的类别信息。描述获取单元113用于基于预设的信息检索方法确定所述目标对象的描述信息。
144.预处理子模块12包括第一处理单元121和第二处理单元122。第一处理单元121用于对所述初始标题信息进行纠错处理,以确定第一预处理结果。第二处理单元122用于对所
述第一预处理结果中的无用信息进行消除,以确定所述对象标题信息。
145.本实施例中,本实施例的第一识别模块2包括初始识别子模块21,初始识别子模块21用于根据对象标题信息、类别信息和描述信息对所述对象标题信息进行关键词识别,以确定初始识别结果。
146.可选地,本实施例中的初始识别子模块21包括特征单元211、概率单元212、标签单元213和初始确定单元214。其中特征单元211用于获取对象标题信息、类别信息和描述信息中每个词对应的特征向量。概率单元212用于通过预设的第一神经网络对所述特征向量进行处理,确定每个词被标注为各标签的概率。标签单元213用于根据所述概率标注所述对象标题信息中每个词的标签。初始确定单元214用于根据各词的标签和词属性确定所述初始识别结果,所述词属性用于表征所述词与所述标题信息相对应。
147.本实施例中,第二识别模块3包括映射子模块31和第二确定子模块32。其中,映射子模块31用于将初始识别结果、类别信息和描述信息输入至预设的第二神经网络,确定各词与各分类类别的映射关系。第二确定子模块32用于根据映射关系确定各词对应的目标标签,并将各目标标签对应的词确定为所述对象标题信息中的关键词。
148.图9是本实施例的电子设备的示意图。如图9所示,本实施例的电子设备为通用的数据处理装置,包括通用的计算机硬件结构,其至少包括处理器91和存储器92。处理器91和存储器92通过总线93连接。存储器92适于存储处理器91可执行的指令或程序。处理器91可以是独立的微处理器,也可以是一个或者多个微处理器集合。由此,处理器91通过执行存储器92所存储的指令,从而执行如上所述的本发明实施例的方法流程实现对于数据的处理和对于其它装置的控制。总线93将上述多个组件连接在一起,同时将上述组件连接到显示控制器94、显示装置以及输入/输出(i/o)装置95。输入/输出(i/o)装置95可以是鼠标、键盘、调制解调器、网络接口、触控输入装置、体感输入装置、打印机以及本领域公知的其他装置。典型地,输入/输出装置95通过输入/输出(i/o)控制器96与系统相连。
149.其中,存储器92可以存储软件组件,例如操作系统、通信模块、交互模块以及应用程序。以上所述的每个模块和应用程序都对应于完成一个或多个功能和在发明实施例中描述的方法的一组可执行程序指令。
150.本领域的技术人员应明白,本技术的实施例可提供为方法、装置(设备)或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可读存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品。
151.本技术是参照根据本技术实施例的方法、装置(设备)和计算机程序产品的流程图来描述的。应理解可由计算机程序指令实现流程图中的每一流程。
152.本发明的另一实施例涉及一种计算机程序产品,包括计算机程序/指令,计算机程序程序/指令用于在被处理器执行时实现上述部分或全部的方法实施例中的部分或全部步骤。这些计算机程序/指令可以存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的程序/指令产生包括指令装置的制造品,该指令装置实现流程图一个流程或多个流程中指定的功能。也可提供这些计算机程序/指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设
备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程中指定的功能的装置。
153.本发明的另一实施例涉及一种计算机可读存储介质,可以是非易失性存储介质,用于存储计算机可读程序,所述计算机可读程序用于供计算机执行上述部分或全部的方法实施例。
154.即,本领域技术人员可以理解,实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本技术各实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-only memory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
155.本发明实施例公开了ts1、一种信息处理方法,所述方法包括:
156.获取目标对象的对象信息,所述对象信息包括对象标题信息、类别信息和描述信息;
157.对所述对象标题信息进行关键词识别,以确定初始识别结果;
158.根据所述初始识别结果、类别信息和描述信息对所述初始识别结果进行识别,以确定所述对象标题信息中的关键词。
159.ts2、根据ts1所述的方法,所述对所述对象标题信息进行关键词识别,以确定初始识别结果包括:
160.根据所述对象标题信息、类别信息和描述信息对所述对象标题信息进行关键词识别,以确定初始识别结果。
161.ts3、根据ts2所述的方法,所述根据所述对象标题信息、类别信息和描述信息对对象标题信息进行关键词识别,以确定初始识别结果包括:
162.获取对象标题信息、类别信息和描述信息中每个词对应的特征向量;
163.通过预设的第一神经网络对各所述特征向量进行处理,确定每个词被标注为各标签的概率;
164.根据所述概率标注所述对象标题信息中每个词的标签;
165.根据各词的标签和词属性确定所述初始识别结果,所述词属性用于表征所述词与所述对象标题信息、类别信息或描述信息的对应关系。
166.ts4、根据ts1所述的方法,所述根据所述初始识别结果、类别信息和描述信息对所述初始识别结果进行识别,以确定所述对象标题信息中的关键词包括:
167.将所述初始识别结果、类别信息和描述信息输入至预设的第二神经网络,确定各词与各分类类别的映射关系;
168.根据所述映射关系确定各词对应的目标标签;
169.将各目标标签对应的词确定为所述对象标题信息中的关键词。
170.ts5、根据ts1所述的方法,所述获取目标对象的对象信息包括:
171.获取目标对象的初始标题信息;
172.对所述初始标题信息进行预处理,以确定所述对象标题信息。
173.ts6、根据ts5所述的方法,所述对所述初始标题信息进行预处理,以确定所述对象
标题信息包括:
174.对所述初始标题信息进行纠错处理,以确定第一预处理结果;
175.对所述第一预处理结果中的无用信息进行消除,以确定所述对象标题信息。
176.ts7、根据ts5所述的方法,所述获取目标对象的对象信息包括:
177.基于预设的分类方法确定所述目标对象的类别信息。
178.ts8、根据ts5所述的方法,所述获取目标对象的对象信息包括:
179.基于预设的信息检索方法确定所述目标对象的描述信息。
180.本发明实施例还公开了ts9、一种信息处理装置,所述装置包括:
181.获取模块,用于获取目标对象的对象标题信息;
182.第一识别模块,用于对所述对象标题信息进行关键词识别,以确定初始识别结果;
183.第二识别模块,用于根据所述初始识别结果、类别信息和描述信息对所述初始识别结果进行识别,以确定所述对象标题信息中的关键词。
184.ts10、根据ts9所述的装置,所述第一识别模块包括:
185.初始识别子模块,用于根据所述对象标题信息、类别信息和描述信息对所述对象标题信息进行关键词识别,以确定初始识别结果。
186.ts11、根据ts10所述的装置,所述初始识别子模块包括:
187.特征单元,用于获取对象标题信息、类别信息和描述信息中每个词对应的特征向量;
188.概率单元,用于通过预设的第一神经网络对各所述特征向量进行处理,确定每个词被标注为各标签的概率;
189.标签单元,用于根据所述概率标注所述对象标题信息中每个词的标签;
190.初始确定单元,用于根据各词的标签和词属性确定所述初始识别结果,所述词属性用于表征所述词与所述对象标题信息、类别信息或描述信息的对应关系。
191.ts12、根据ts9所述的装置,所述第二识别模块包括:
192.映射子模块,用于将所述初始识别结果、类别信息和描述信息输入至预设的第二神经网络,确定各词与各分类类别的映射关系;
193.第二确定子模块,用于根据所述映射关系确定各词对应的目标标签,将各目标标签对应的词确定为所述对象标题信息中的关键词。
194.ts13、根据ts9所述的装置,所述获取模块包括:
195.获取子模块,用于获取目标对象的初始标题信息;
196.预处理子模块,用于对所述初始标题信息进行预处理,以确定所述对象标题信息。
197.ts14、根据ts13所述的装置,所述预处理子模块包括:
198.第一处理单元,用于对所述初始标题信息进行纠错处理,以确定第一预处理结果;
199.第二处理单元,用于对所述第一预处理结果中的无用信息进行消除,以确定所述对象标题信息。
200.ts15、根据ts13所述的装置,所述获取子模块包括:
201.类别获取单元,用于基于预设的分类方法确定所述目标对象的类别信息。
202.ts16、根据ts13所述的装置,所述获取子模块包括:
203.描述获取单元,用于基于预设的信息检索方法确定所述目标对象的描述信息。
204.本发明实施例还公开了ts17、一种计算机程序产品,所述计算机程序产品包括计算机程序/指令,所述计算机程序/指令被处理器执行时实现ts1-8中任一项所述的方法。
205.本发明实施例还公开了ts18、一种电子设备,包括存储器和处理器,所述存储器用于存储一条或多条计算机程序指令,其中,所述一条或多条计算机程序指令被所述处理器执行以实现ts1-8中任一项所述的方法。
206.本发明实施例还公开了ts19、一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现ts1-8中任一项所述的方法步骤。
207.以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。