1.本发明涉及信息技术领域,具体涉及一种针对无标签表格数据的深度异常检测方法及电子设备。
背景技术:
2.异常检测是数据挖掘的一个重要子分支,在大数据时代人工处理数据的速度和效率远远赶不上机器,寻找更快的检测数据中的异常情况的方法是一个重要研究方向。在许多领域(包括网络安全、复杂系统管理、医疗诊断等)都有重要应用。尽管异常检测在过去几年中已经有了巨大的发展,但对多维或者高维的数据进行异常检测仍然是一项极具挑战的研究任务。
3.异常检测技术研究越来越受人关注,迄今为止已经有了大量的解决方法,典型策略有建立合群点模型,并从正样本训练数据中学习参数;为合群点设置判别规则,根据改规则识别和剔除异常点;利用离群点的几何分布特性对样本进行分离,主要有knn、lof。对于其中利用几何分布特性进行异常检测的方法存在以下问题:
4.一、没有利用到样本中的无标签数据,而实际工业界中往往存在大量的无标签数据,如果仅使用正样本训练数据可能导致模型对数据的过拟合问题;
5.二、缺乏可以训练的参数,需要人为设定阈值,导致在这些模式下常常依赖人的经验或者技巧,可能带来人为误差,并且阈值作为超参数,无法适应不同数据集,需要针对不同的数据集进行调整,增大了工作量与开销;
6.三、在处理高维数据时,对数据的各特征向量平等对待,容易出现误差,影响算法准确率。
技术实现要素:
7.针对现有技术中的上述不足,本发明提供的一种针对无标签表格数据的深度异常检测方法及电子设备解决了现有方法检测准确率低的问题。
8.为了达到上述发明目的,本发明采用的技术方案为:
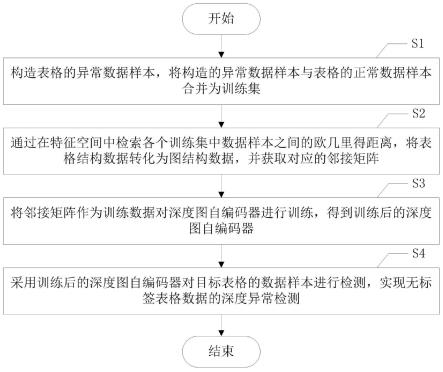
9.提供一种针对无标签表格数据的深度异常检测方法,其包括以下步骤:
10.s1、构造表格的异常数据样本,将构造的异常数据样本与表格的正常数据样本合并为训练集;
11.s2、通过在特征空间中检索各个训练集中数据样本之间的欧几里得距离,将表格结构数据转化为图结构数据,并获取对应的邻接矩阵;
12.s3、将邻接矩阵作为训练数据对深度图自编码器进行训练,得到训练后的深度图自编码器;
13.s4、采用训练后的深度图自编码器对目标表格的数据样本进行检测,实现无标签表格数据的深度异常检测。
14.进一步地,步骤s1中构造表格的异常数据样本的具体方法为:
15.通过特征子空间施加微小扰动和特征子空间均匀分布构造表格的异常数据样本。
16.进一步地,通过特征子空间施加微小扰动的具体方法为:
17.获取正常数据样本集x,并根据公式:
[0018][0019]
对正常数据样本集x中的样本x进行归一化,得到归一化后的样本x'及归一化后的样本集x';其中x
min
为正常数据样本集x中的最小值;x
max
为正常数据样本集x中的最大值;
[0020]
根据公式:
[0021]
x
negative
=x' m
·
εz
[0022]
对归一化后的样本集x'进行扰动,得到异常数据样本集x
negative
;其中m为一个由0和1组成的d维向量,当m中元素在某维度上取值为0时,表示不施加扰动,取值为1时表示施加扰动;z为概率密度服从标准正态分布的高斯白噪声;ε为常数。
[0023]
进一步地,步骤s2的具体方法包括以下子步骤:
[0024]
s2-1、将训练集中每一个数据样本看作图上的一个节点,检索各个节点之间的欧几里得距离;
[0025]
s2-2、将与每个节点距离最近的k个数据样本作为该节点的邻居;
[0026]
s2-3、利用节点与邻居以及对应的欧几里得距离建立邻接矩阵形式的图结构数据;其中数据样本为图结构数据中的节点,每个节点通过k条边连接至其k个邻居;
[0027]
s2-4、根据公式:
[0028][0029]
获取图结构数据的邻接矩阵e;其中e
ij
表示数据样本xi为节点时对应的边特征;xj为数据样本xi的邻居;ni为数据样本xi的邻居集合;dist(xi,xj)表示xi和xj之间的欧几里得距离。
[0030]
进一步地,步骤s3的具体方法为:
[0031]
构建深度图自编码器,定义损失函数,以最小化损失函数为目标,使用adam优化器进行优化,设置adam优化器的学习率为0.001,权重衰减为0.1,将图结构数据作为训练数据对深度图自编码器进行训练,得到训练后的深度图自编码器。
[0032]
进一步地,步骤s3中深度图自编码器包括消息传递模块、聚合模块、更新模块、属性解码器和标签解码器,其中:
[0033]
消息传递模块,用于将边特征e
ij
作为从源节点xj沿边(j,x)传递到节点xi的信息;
[0034]
聚合模块,用于通过深度神经网络产生在数据集上具备学习适应能力的聚合函数,具体过程为:
[0035]
根据公式:
[0036]
e(i)=[e
1,i
,e
2,i
,...,e
j,i
,...,e
k,i
]
[0037]
将节点xi的邻居传递给节点xi的信息拼接在一起形成k维输入向量e(i);e
j,i
为节点xi的邻居xj传递给节点xi的信息,即e
ij
;
[0038]
根据公式:
[0039][0040]
获取节点xi对应的低维嵌入表示其中θ表示深度神经网络f的权重参数;深度神经网络f的第l层神经元的输出表达式为:a
l
=σ(h
l
)=σ(w
lal-1
b
l
),a
l
为第l层神经元的输出,a
l-1
为第l-1层神经元的输出,a1=e(i);h
l
为第l层神经元的线性表示;σ(
·
)为第l层神经元的激活函数;w
l
为第l-1层神经元到第l层神经元的系数矩阵;b
l
为第l层神经元的偏置矩阵;
[0041]
更新模块,用于将聚合模块的输出结果更新当前节点的表示,表达式为:
[0042][0043]
其中h为更新模块的输出;为节点xn对应的低维嵌入表示;v为低维嵌入表示的维数;h
nv
表示中的第v维数据;
[0044]
属性解码器,用于根据更新模块的输出进行邻接矩阵重构,其解码表达式为:
[0045][0046]
其中为重构的邻接矩阵;(
·
)
t
表示矩阵的转置;
[0047]
标签解码器,用于重构出原始的节点标签,其解码表达式为:
[0048][0049]
其中为标签解码结果;w为系数矩阵;b为偏置矩阵;σ
*
(
·
)为激活函数。
[0050]
进一步地,损失函数的表达式为:
[0051][0052]
其中loss为深度图自编码器的损失值,α为加权系数;||
·
||2为矩阵二范数,表示属性重构误差;bceloss(
·
)为二分类交叉熵计算函数,表示采用二分类交叉熵计算的标签重构误差;l
*
为真实标签向量。
[0053]
进一步地,步骤s4的具体方法包括以下子步骤:
[0054]
s4-1、采用与步骤s1和步骤s2相同的方法获取目标表格的数据样本m对应的邻接矩阵e(m);
[0055]
s4-2、将目标表格的数据样本m对应的邻接矩阵e(m)作为训练后的深度图自编码器的输入,得到目标表格的数据样本m对应的重构的邻接矩阵和标签解码结果
[0056]
s4-3、根据公式:
[0057][0058]
获取目标表格的数据样本m的异常分数scorem,完成无标签表格数据的深度异常检测;其中β为加权系数;异常分数scorem越高表示目标表格的数据样本m异常的概率越大。
[0059]
提供一种电子设备,其包括:
[0060]
存储器,存储有可执行指令;以及
[0061]
处理器,被配置为执行存储器中可执行指令以实现一种针对无标签表格数据的深度异常检测方法。
[0062]
本发明的有益效果为:
[0063]
1、本发明识别精度高,通过将表格数据转化为网络数据模型,可以更好地识别表格中的数据异常。
[0064]
2、在特征子空间施加微小扰动产生异常这一方法可以使得无监督深度学习模型更容易确定正常和异常之间的分界,在特征子空间均匀分布产生异常样本可以使得人为产生的异常弥散在特征空间中,使得本方法具有更佳的异常检测性能。
[0065]
3、本发明通过人为构造异常数据实现了对于无标签表格数据的异常检测与评估。
[0066]
4、本发明使用了深度图自编码器,通过两套解码器的重构情况加权计算出了数据样本的异常分数,提高了检测准确率。
[0067]
5、本发明将数据节点之间的欧氏距离作为网络的输入,这比直接输入数据的特征向量具有更好的泛化能力。
附图说明
[0068]
图1为本方法的流程示意图;
[0069]
图2为本发明使用的节点嵌入编码器示意图;
[0070]
图3为本发明异常检测基本框架示意图;
[0071]
图4为本发明深度图自编码器模型在数据集speech上训练迭代的损失函数曲线图;
[0072]
图5为本发明深度图自编码器模型在数据集annthyroid上训练迭代的损失函数曲线图;
[0073]
图6为本发明深度图自编码器模型在数据集arrhythmia上训练迭代的损失函数曲线图。
具体实施方式
[0074]
下面对本发明的具体实施方式进行描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
[0075]
如图1所示,该针对无标签表格数据的深度异常检测方法包括以下步骤:
[0076]
s1、构造表格的异常数据样本,将构造的异常数据样本与表格的正常数据样本合并为训练集;
[0077]
s2、通过在特征空间中检索各个训练集中数据样本之间的欧几里得距离,将表格结构数据转化为图结构数据,并获取对应的邻接矩阵;
[0078]
s3、将邻接矩阵作为训练数据对深度图自编码器进行训练,得到训练后的深度图自编码器;
[0079]
s4、采用训练后的深度图自编码器对目标表格的数据样本进行检测,实现无标签表格数据的深度异常检测。
[0080]
步骤s1中构造表格的异常数据样本的具体方法为:通过特征子空间施加微小扰动和特征子空间均匀分布构造表格的异常数据样本。
[0081]
通过特征子空间施加微小扰动的具体方法为:获取正常数据样本集x,并根据公式:
[0082][0083]
对正常数据样本集x中的样本x进行归一化,得到归一化后的样本x'及归一化后的样本集x';其中x
min
为正常数据样本集x中的最小值;x
max
为正常数据样本集x中的最大值;
[0084]
根据公式:
[0085]
x
negative
=x' m
·
εz
[0086]
对归一化后的样本集x'进行扰动,得到异常数据样本集x
negative
;其中m为一个由0和1组成的d维向量,当m中元素在某维度上取值为0时,表示不施加扰动,取值为1时表示施加扰动;z为概率密度服从标准正态分布的高斯白噪声;ε为常数,可取值为0.1。m中元素可以以0.3概率取值为1进行生成。
[0087]
通过特征子空间均匀分布构造表格的异常数据样本的具体方法为:
[0088]
根据公式:
[0089]
x
negative
~μ(-ε,1 ε)
[0090]
从均匀分布中采样生成异常数据样本集x
negative
;其中μ(
·
)表示均匀分布。
[0091]
步骤s2的具体方法包括以下子步骤:
[0092]
s2-1、将训练集中每一个数据样本看作图上的一个节点,检索各个节点之间的欧几里得距离;
[0093]
s2-2、将与每个节点距离最近的k个数据样本作为该节点的邻居;
[0094]
s2-3、利用节点与邻居以及对应的欧几里得距离建立邻接矩阵形式的图结构数据;其中数据样本为图结构数据中的节点,每个节点通过k条边连接至其k个邻居;
[0095]
s2-4、根据公式:
[0096][0097]
获取图结构数据的邻接矩阵e;其中e
ij
表示数据样本xi为节点时对应的边特征;xj为数据样本xi的邻居;ni为数据样本xi的邻居集合;dist(xi,xj)表
示xi和xj之间的欧几里得距离。
[0098]
步骤s3的具体方法为:构建深度图自编码器,定义损失函数,以最小化损失函数为目标,使用adam优化器进行优化,设置adam优化器的学习率为0.001,权重衰减为0.1,将图结构数据作为训练数据对深度图自编码器进行训练,得到训练后的深度图自编码器。
[0099]
步骤s3中深度图自编码器包括消息传递模块、聚合模块、更新模块、属性解码器和标签解码器,其中:
[0100]
消息传递模块,用于将边特征e
ij
作为从源节点xj沿边(j,x)传递到节点xi的信息;
[0101]
聚合模块,用于通过深度神经网络产生在数据集上具备学习适应能力的聚合函数,具体过程为:
[0102]
根据公式:
[0103]
e(i)=[e
1,i
,e
2,i
,...,e
j,i
,...,e
k,i
]
[0104]
将节点xi的邻居传递给节点xi的信息拼接在一起形成k维输入向量e(i);e
j,i
为节点xi的邻居xj传递给节点xi的信息,即e
ij
;
[0105]
根据公式:
[0106][0107]
获取节点xi对应的低维嵌入表示其中θ表示深度神经网络f的权重参数;深度神经网络f的第l层神经元的输出表达式为:a
l
=σ(h
l
)=σ(w
lal-1
b
l
),a
l
为第l层神经元的输出,a
l-1
为第l-1层神经元的输出,a1=e(i);h
l
为第l层神经元的线性表示;σ(
·
)为第l层神经元的激活函数;w
l
为第l-1层神经元到第l层神经元的系数矩阵;b
l
为第l层神经元的偏置矩阵;低维嵌入所采用的编码器如图2所示;
[0108]
更新模块,用于将聚合模块的输出结果更新当前节点的表示,表达式为:
[0109][0110]
其中h为更新模块的输出;为节点xn对应的低维嵌入表示;v为低维嵌入表示的维数;h
nv
表示中的第v维数据;
[0111]
属性解码器,用于根据更新模块的输出进行邻接矩阵重构,其解码表达式为:
[0112][0113]
其中为重构的邻接矩阵;(
·
)
t
表示矩阵的转置;
[0114]
标签解码器,用于重构出原始的节点标签,其解码表达式为:
[0115][0116]
其中为标签解码结果;w为系数矩阵;b为偏置矩阵;σ
*
(
·
)为激活函数,该激活函数的表达式为
[0117]
损失函数的表达式为:
[0118][0119]
其中loss为深度图自编码器的损失值,α为加权系数;||
·
||2为矩阵二范数,表示属性重构误差;bceloss(
·
)为二分类交叉熵计算函数,表示采用二分类交叉熵计算的标签重构误差;l
*
为真实标签向量。
[0120]
聚合操作中的深度神经网络构建步骤如下:
[0121]
定义输入空间
[0122]
定义输入空间
[0123]
定义神经网络模型neural network:φ(x;w):x
→
f;
[0124]
定义神经网络模型权重w={w1,...,w
l
},l为隐藏层层数,具体实施中可以取值为4;
[0125]
输出层的节点数为。
[0126]
步骤s4的具体方法包括以下子步骤:
[0127]
s4-1、采用与步骤s1和步骤s2相同的方法获取目标表格的数据样本m对应的邻接矩阵e(m);
[0128]
s4-2、将目标表格的数据样本m对应的邻接矩阵e(m)作为训练后的深度图自编码器的输入,得到目标表格的数据样本m对应的重构的邻接矩阵和标签解码结果
[0129]
s4-3、根据公式:
[0130][0131]
获取目标表格的数据样本m的异常分数scorem,完成无标签表格数据的深度异常检测;其中β为加权系数;异常分数scorem越高表示目标表格的数据样本m异常的概率越大。整个异常检测的流程(基本框架)如图3所示。
[0132]
本发明还提供了一种电子设备,该电子设备包括:
[0133]
存储器,存储有可执行指令;以及
[0134]
处理器,被配置为执行存储器中可执行指令以实现一种针对无标签表格数据的深度异常检测方法。
[0135]
在本发明的一个实施例中,使用了常用的异常检测数据集网站odds
–
outlierdetection datasets(stonybrook.edu)中收集到的数据集,各数据集的大小,数据维度和异常占比信息如表1。
[0136]
表1:数据集基本信息
[0137][0138]
将这些数据集中的训练数据进行最大最小归一化,利用上述两种方法产生异常数据,随机抽取其中的一些异常数据与训练集中的原始异常数据进行合并。其中来自uci机器学习库中的原始甲状腺疾病(annthyroid)数据集是一个分类数据集,有3772个训练实例和3428个测试实例,经过上述处理,部分样本数据如表2。
[0139]
表2:部分样本数据实例
[0140]
realattr1realattr2realattr3realattr4realattr5realattr6label0.730.00060.0150.120.0820.14600.240.000250.030.1430.1330.10800.470.00190.0240.1020.1310.07800.640.00090.0170.0770.090.08500.230.000250.0260.1390.090.15300.690.000250.0160.0860.070.12300.850.000250.0230.1280.1040.12100.480.002080.020.0860.0780.1100.670.00130.0240.0870.1090.0800.760.00010.0290.1240.1280.09700.620.0110.0080.0730.0740.09810.180.00010.0230.0980.0850.11500.590.00080.0230.0940.0990.0947500.490.00060.0230.1130.1020.11100.530.00230.020.0630.0950.06600.390.00010.0180.090.0710.12600.390.00060.020.1140.10.11400.650.00160.0180.0780.0920.08500.640.0320.0140.0850.1160.07100.50.0610.00960.0130.1160.01110.760.00010.02080.0980.1010.0970
[0141]
表2中realattr表示属性,label表示标签,即前六列为用于描述患者甲状腺功能衰退程度的属性,最后一列为异常数据的标签,1表示异常数据,0表示正常数据。在本实施例中对于使用的每个数据集,超参数k设置了2、10、50、100、150和200六个值,通过设置不同的超参数,用以衡量本方法对不同邻居数量的鲁棒性。
[0142]
对于数据集annthyroid,搭建的神经网络在中间隐藏层的激活函数使用了tanh函
数,每层的隐藏层节点数取256,输出层的激活函数则使用sigmoid函数,输出层的节点数为v。本发明的深度图自编码器在本实施例中不同数据集上的训练迭代的损失函数曲线分别如图4、图5和图6所示。
[0143]
通过构建测试集(有正常数据也有异常数据)并获取测试集中各个数据样本相应的异常分数,计算假正类(false positive)率和真正类(true positive)率。利用得到的假正类率和真正类率绘制roc曲线,计算曲线下的面积得到auc分数,即可用以衡量训练的深度图自编码器对真实数据集的异常检测准确程度。
[0144]
对于本实施例选取的三个数据集,对比了两种传统的异常检测算法knn、lof、一种结合了深度学习的异常检测方法(lunar)和本发明的异常检测方法(dgae),得到各数据集不同方法对应的auc分数如表3、表4和表5。
[0145]
表3:不同算法对于数据集speech的auc分数
[0146][0147]
表4:不同算法对于数据集annthyroid的auc分数
[0148][0149]
表5:不同算法对于数据集arrhythmia的auc分数
[0150][0151]
从上述表格中可以发现:选取的三个数据集中,对于大部分设置的超参数k,本发明的异常检测方法的准确程度都较高。对于数据集annthyroid相较于传统异常检测算法,准确率都提高了6%左右,相较于新型的结合深度学习的异常检测方法lunar,准确率也提高了2%左右,提升较为明显。
[0152]
综上所述,本发明基于深度图自编码器的异常检测方法对于不同数据集的识别精
度高,能够较为准确地识别表格中的数据异常。本发明对不同数据集具有适用性高、识别精度高、充分利用数据信息的优点。本发明解决了传统异常检测方法对于不同数据集的适应性较差的问题,在实际使用中,减小了由于人为设定阈值等参数带来的人为误差,并且减小了工作量和开销。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
