1.本技术涉及情感识别与教育信息化技术领域,更具体地,涉及一种基于多 模态数据融合的学习投入状态监测方法及计算机设备。
背景技术:
2.随着教育环境的不断优化,教学环境由从前的黑板课桌逐步发展成多媒体 教室,这种良好的环境不仅可以让学生充分享受学习资源也可以帮助老师在授 学过程中得到许多便利。为响应国家教育部“以人为本,因材施教”的号召,越来 越多的高校将教学环境设置在多媒体教室,并增设了小组讨论环节,让学生们 积极发表自己的所想并在讨论中自主发现学习更多的知识。为了清楚不同学生 的学习情况,教师利用多媒体教室功能的多样性在学生讨论时通过捕获的语音 片段进行情绪识别进而判断学生学习状态。虽然在学生学习效果评判进行了语 音情绪识别,但是在学习效果评判系统中无论是准确性还是体系规范性难以取 得理想效果。
3.情感是学生对课堂内容投入程度的一个重要表现形式,通过分析学生在上 课的小组讨论中的情绪状态进而可以发现学生对教学内容的理解程度这一隐性 细节。在科技发展下,越来越多人佩戴运动手表,因此可以通过蓝牙数据传输 获得学生的生理信息这一内隐行为,学生在小组讨论时,学生可能会产生激动、 疑惑、中性与疲惫等情绪,在不同的情绪下,皮电、肌电信号会有不同的特点。 然而,目前的学习效果评判系统中,单纯的语音或表情识别可能存在隐匿情况 而导致分析准确性不高,这是亟需解决的问题。
技术实现要素:
4.针对现有技术的至少一个缺陷或改进需求,本发明提供了一种基于多模态 数据融合的学习投入状态监测方法及计算机设备,其目的在于提高情绪识别的 准确性,从而为学习投入状态分类提供准确依据。
5.为实现上述目的,按照本发明的第一个方面,提供了一种学习投入状态监 测方法,其包括:
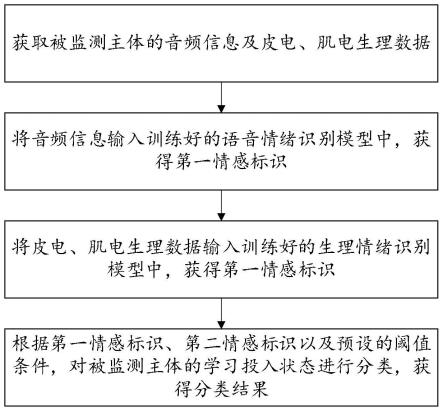
6.获取被监测主体的音频信息及皮电、肌电生理数据;
7.将所述音频信息输入训练好的语音情绪识别模型中,获得第一情感标识;
8.将所述皮电、肌电生理数据输入训练好的生理情绪识别模型中,获得第一 情感标识;
9.根据所述第一情感标识、第二情感标识以及预设的阈值条件,对被监测主 体的学习投入状态进行分类,获得分类结果。
10.进一步地,上述学习投入状态监测方法中,所述将音频信息输入训练好的 语音情绪识别模型中,获得第一情感标识;包括:
11.对所述音频信息进行转录并提取语言表示,对所述语言表示进行线性变换, 得到音频信息对应的语义嵌入;
12.将所述音频信息转换为频谱图并进行特征提取,获得有效特征向量;
13.对所述有效特征向量进行多维特征转换和聚合,得到声学特征序列;
14.将所述语义嵌入与声学特征序列进行融合,获得聚合特征;基于所述聚合 特征预测得到被监测主体的第一情感标识。
15.进一步地,上述学习投入状态监测方法中,采用sigmoid激活的简单门通机 制将语义嵌入与声学特征序列进行融合,获得聚合特征。
16.进一步地,上述学习投入状态监测方法中,所述将皮电、肌电生理数据输 入训练好的生理情绪识别模型中,获得第一情感标识,包括:
17.分别对皮电、肌电生理数据进行特征提取,获得各自对应的归一化表示;
18.将皮电、肌电生理数据对应的所述归一化表示进行加权求和,基于求和结 果以及皮电、肌电生理数据各自的重要性权重分别计算皮电、肌电生理数据对 应的全局特征表示;
19.将皮电、肌电生理数据对应的全局特征表示进行融合,得到融合向量;
20.基于所述融合向量预测得到被监测主体的第二情感标识。
21.进一步地,上述学习投入状态监测方法还包括:
22.将皮电、肌电生理数据对应的所述归一化表示转换为以时间帧和通道数表 征的二维数组;
23.将两个所述二维数组对齐并进行加权求和。
24.进一步地,上述学习投入状态监测方法中,所述将皮电、肌电生理数据对 应的全局特征表示进行融合,得到融合向量,包括:
25.获取一组投影矩阵,将每个所述投影矩阵分解为两个秩矩阵;
26.将每个所述秩矩阵表示为二维矩阵,并与皮电、肌电生理数据对应的全局 特征表示择一进行配对,生成两个融合矩阵;
27.将两个所述融合矩阵作向量相乘,经池化后得到最终的融合向量。
28.进一步地,上述学习投入状态监测方法中还包括:
29.将所述音频信息进行转录,生成文本数据;
30.对所述文本数据进行关键词提取,得到关键词标签;
31.将所述关键词标签与预置的标准语句进行比对,计算两者的重合率;
32.根据所述重合率、第一情感标识、第二情感标识以及预设的阈值条件,对 被监测主体的学习状态进行分类,获得分类结果。
33.进一步地,上述学习投入状态监测方法中,所述语音情绪识别模型包括文 本嵌入模块、特征提取模块、交叉激励模块、池化层和全连接层;
34.所述特征提取模块包括多个堆叠的cmt-s模块,每个所述cmt-s模块包 含一个局部感知单元、一个轻量级多头自注意模块和一个倒置残差前馈网络。
35.进一步地,上述学习投入状态监测方法中,所述生理情绪识别模型包括信 号编码器、注意力模块、融合模块和分类模块;
36.所述信号编码器包括若干卷积层与一个长形网络;所述卷积层的输出增加 relu激活函数和lrn函数进行响应归一化操作;
37.所述融合模块包括投影矩阵和双线性池化,用于将皮电特征、肌电特征进 行融
合;所述分类模块是由全连接层与softmax函数执行分类计算。
38.按照本发明的第二个方面,还提供了一种计算机设备,其包括至少一个处 理单元、以及至少一个存储单元,其中,所述存储单元存储有计算机程序,当 所述计算机程序被所述处理单元执行时,使得所述处理单元执行上述任一项所 述学习投入状态监测方法的步骤。
39.总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得 下列有益效果:
40.(1)本发明使用肌电、皮电等难以隐藏的生理信息,结合音频信息进行情 绪状态分类,使得最后的情感状态分析更加真实准确;并进一步将将语音转义 文本结合教学内容进行比对,更加精确判断学生的学习状态与情绪积极性,作 为衡量课堂中学生对教学内容的反馈以及积极性的重要依据,分类识别的结果 有利于开展因材施教的教学工作。
41.(2)在模型构造上,本发明使用了语音与皮电肌电数据融合的多模态模型; 在此基础上,语音情感模型的音频流使用了cnn与transformer的融合网络结构 cmt-s,使得特征提取更加全面且大幅度减少了计算效率并与语音文本进行特 征交叉融合,在情感分类时更加真实具体;生理情感模型使用肌电信号与同一 类聚的皮电信号,利用一维注意力进行特征信息提取,最后通过双线性池进行 有效特征融合,得到更为准确的情感分类。
附图说明
42.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例中所需使 用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术的一些 实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可 以根据这些附图获得其他的附图。
43.图1为本技术实施例提供的一种学习投入状态监测方法的流程示意图;
44.图2为本技术实施例提供的学习投入状态监测的执行步骤示意图;
45.图3为本技术实施例提供学生讨论式协作学习的数据获取场景图;
46.图4为本技术实施例提供的语音情绪识别模型的网络拓扑结构示意图;
47.图5是本技术实施例提供的生理情绪识别模型的网络拓扑结构示意图。
具体实施方式
48.为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实 施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅 仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实 施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
49.本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三
”ꢀ
等是用于区别不同对象,而不是用于描述特定顺序。此外,术语“包括”和“具有
”ꢀ
以及它们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单 元的过程、方法、系统、产品或设备没有限定于已列出的步骤或单元,而是可 选地还包括没有列出的步骤或单元,或可选地还包括对于这些过程、方法、产 品或设备固有的其他步骤或单元。
50.此外,为了避免使技术人员对本发明的理解模糊,可能不详细地描述或示 出公知
的或广泛使用的技术、元件、结构和处理。尽管附图表示本发明的示例 性实施例,但是附图不必按照比例绘制,并且特定的特征可被放大或省略,以 便更好地示出和解释本发明。
51.图1是本实施例提供的一种基于多模态数据融合的学习投入状态监测方法 的流程示意图,图2是本实施例提供的学习投入状态监测的执行步骤示意图, 请参阅图1、2,该方法包括以下步骤:
52.s1获取被监测主体的音频信息及皮电、肌电生理数据;
53.如图3所示,多个学生正在进行课堂讨论协作学习,在该场景下,利用麦 克风采集每位学生音频谱图,通过学生佩戴的腕表获取皮电肌电信号图;该场 景下获取到的音频谱图与皮电肌电信号图为语音情感识别模型与生理情感识别 模型提供了重要的数据来源。
54.对于音频信息,需要通过音频识别技术将每位学生的声音片段分割开来。
55.s2将所述音频信息输入训练好的语音情绪识别模型中,获得第一情感标识;
56.本实施例中,在获取每位学生在学习过程中的音频数据后进行分帧处理, 将每帧音频信息输入训练好的语音情绪识别模型中,通过模型预测获得第一情 感标识;具体包括:
57.s21对所述音频信息进行转录并提取语言表示,对语言表示进行线性变换, 得到音频信息对应的语义嵌入;
58.s22将音频信息转换为频谱图并进行特征提取,获得有效特征向量;
59.s23对有效特征向量进行多维特征转换和聚合,得到声学特征序列;
60.s24将语义嵌入与声学特征序列进行融合,获得聚合特征;在一个具体的示 例中,采用sigmoid激活的简单门通机制将语义嵌入与声学特征序列进行融合, 获得聚合特征;基于聚合特征预测得到被监测主体的第一情感标识。
61.在一个可选的实施方式中,语音情绪识别模型包括文本嵌入模块、特征提 取模块、交叉激励模块、池化层和全连接层;其中,特征提取模块包括多个堆 叠的cmt-s模块,每个cmt-s模块包含一个局部感知单元、一个轻量级多头 自注意模块和一个倒置残差前馈网络。交叉激励模块具有sigmoid激活的简单门 通机制,将融合后的特征进行平均池化,最后输入进前馈网络中。cmt-s模块 能够更好的提取学生讨论中音频信息的语音特征;交叉激励模块则是将语音特 征与转录的文本特征通过基于维度依赖的自门控机制学习每个嵌入维度自适应 校准时间和对齐声学与语义表示;池化层、全连接层用于识别最终的语音情感 分类。
62.图4是本实施例提供的语音情绪识别模型的网络拓扑结构示意图,下面结 合该语音情绪识别模型的拓扑结构对情感预测的过程作进一步详细说明。
63.(1)将学生的音频信息输入文本嵌入模块中,对于每一个话语,通过自动 语音识别(asr)服务获得它的转录。然后,通过预训练的glov e语言模型提取 语言表示qw∈r
l
×c,其中,c为asr转录的字数。
64.之后,在语言表示qw上应用线性变换vw∈r
p
×
l
,得到经过微调的语义嵌 入zw∈r
p
×c,即zw=v
wqw
,用于下游的情感识别任务;其中,l是分割出 语句的长度;p为语句的时长。
65.(2)将学生的音频信息转换为n帧将每个帧fi转为梅尔频谱图, 即语句为
66.(3)将输入进一个步幅为2的3
×
3卷积和一个32的输出 通道,以减少输入图像的大小,然后使用另外两个步幅为1的3
×
3卷积,以更 好地提取局部信息。输出通道提取到的有效特征向量依次输入 多个堆叠的cmt-s模块。
67.(4)如图4所示,在阶段1至阶段4的每个阶段中,几个cmt块被按顺 序堆叠以进行特征转换,在每个cmt块中,设置了局部感知单元(lpu)模块用 来提取局部信息:
68.lpu(x)=dwconv(x) x
ꢀꢀꢀ
(1)
69.为了减轻计算量则使用在轻量级多头自我注意力(lmhsa)模块,使用k
×
k 步幅k的深度卷积来减小k和v的空间大小,即的深度卷积来减小k和v的空间大小,即并在每个自我注意力模块增加一个相对位置偏差 [0070][0071]
(5)对于倒置残差前馈网络(irffn),将激活层和最后一个线性层进行批 归一化处理,对xa进行卷积处理,并对卷积处理后的x’a
再次进行深度卷积并 加上xa,计算其输出的声学特征序列为:
[0072]
irffn(x)=conv(h(conv(x)))
ꢀꢀꢀ
(3)
[0073]
h(x)=dwconv(x) x
ꢀꢀꢀ
(4)
[0074]
每个cmt块的逻辑相关公式为:
[0075]
wi=lpu(x
i-1
)
ꢀꢀꢀ
(5)
[0076]
ni=lmhsa(ln(wi)) wi(6)qi=irffn(ln(ni) niꢀꢀꢀ
(7)
[0077]
(6)阶段4中的最后一个cmt块输出的声学特征序列进入交叉激励模块 (cross excitation module,cem)中;通过sigmoid激活的简单门通机制,即 es=σ(s
szw
)∈rn×c和ew=σ(s
wzs
)∈r
p
×c,其中,σ(
·
)表示sigmoid函数 ss∈rn×
p
,sw∈r
p
×n分别表示声学表示和语义表示的线性投影算子;zs表示声 学特征序列irffn(x)的值;ss是声学(zs)线性投影表示;sw是语义(zw) 线性投影表示。
[0078]
(7)通过相应的激励矩阵ew、es自适应校准时间对齐的词级声学和语义表 示,计算交叉模态自适应表示,分别记为:
[0079]
和
[0080]
其中,符号
⊙
表示元素之间的乘积。
[0081]
(8)和表示每个词的语音与语义用将语音与语义进行连接;利用平均池化聚合信息得到
[0082]
(9)平均池化层与全连接层计算最终的识别结果:将融合特征依次输入平 均池化层与全连接层,池化的结果被计算为z=avgpool(y),avgpool表示平均 池化;全连接计算为其,中fc表示全连接层网络,k表示 情感类别数。随后对m进行softmax函数计算,最后得到的情感标识分为四类: 激动、疑惑、中性与疲惫(低沉/消极)。
[0083]
s3将所述皮电、肌电生理数据输入训练好的生理情绪识别模型中,获得第 一情感标识;
[0084]
本实施例中,在获取每位学生在学习过程中的皮电、肌电生理数据后,将 皮电、肌
电生理数据输入训练好的生理情绪识别模型中,通过模型预测获得第 二情感标识;具体包括:
[0085]
s31分别对皮电、肌电生理数据进行特征提取,获得各自对应的归一化表示。
[0086]
s32将皮电、肌电生理数据对应的所述归一化表示进行加权求和,基于求和 结果以及皮电、肌电生理数据各自的重要性权重分别计算皮电、肌电生理数据 对应的全局特征表示。
[0087]
更加优选的,将皮电、肌电生理数据对应的归一化表示转换为以时间帧和 通道数表征的二维数组,将两个二维数组对齐并进行加权求和。
[0088]
s33将皮电、肌电生理数据对应的全局特征表示进行融合,得到融合向量; 包括:
[0089]
获取一组投影矩阵,将每个所述投影矩阵分解为两个秩矩阵;
[0090]
将每个所述秩矩阵表示为二维矩阵,并与皮电、肌电生理数据对应的全局 特征表示择一进行配对,生成两个融合矩阵;
[0091]
将两个所述融合矩阵作向量相乘,经池化后得到最终的融合向量。
[0092]
s34基于所述融合向量预测得到被监测主体的第二情感标识。
[0093]
在一个可选的实施方式中,生理情绪识别模型包括信号编码器、注意力模 块、融合模块和分类模块;信号编码器用于将皮电信号图与肌电信号图通过局 部响应归一化转为高级表示;在一个具体示例中,信号编码器包括若干卷积层 与一个长形网络;卷积层的输出增加relu激活函数和lrn函数进行响应归一 化操作;融合模块包括投影矩阵和双线性池化,用于将皮电特征、肌电特征进 行融合;所述分类模块是由全连接层与softmax函数执行分类计算。图5是本实 施例提供的生理情绪识别模型的网络拓扑结构示意图,下面结合该生理情绪识 别模型的拓扑结构对情感预测的过程作进一步详细说明。
[0094]
(1)将皮电数据与肌电数据分别输入多个堆叠的卷积层,每层卷积层后设 置有relu激活函数和lrn函数,假设在位置(x,y)处用核i计算神经元的活动 用表示。然后应用relu非线性激活函数,则响应归一化活度表示为:
[0095][0096]
其中,size表示和在相同空间位置的size个相邻卷积核映射上表示,size为 卷积层中的核总数。常数k,size,α,β是超参数。
[0097]
(2)在得出归一化表示后为了及时对齐肌电信号与皮电信号,因此,将信 号编码器的输出设为一个二维数组w
×
c,其中,w和c分别表示时间帧和通道 数。可以把输出看作一个w元素的长型网络,每个元素都是一个c向量,对应 相应的肌电图与皮电图的一个区域,表示为ei,fi。因此,整个肌电、皮电现在 被表示为:e={ei,
…
,ew},ei∈rc和f={fi,
…
,fw},fi∈rc。
[0098]
(3)注意力模块用来从集合e、f中提取对生理情感重要的信息,通过计 算时间维度中的权重,集合e、f中的元素被加权和求和,其中,{q
e(f)
,b
e(f)
} 表示由数据集合e、f输入的一个具有参数的全连接层,并且加上一个tanh函 数,以获得新的表达式:
[0099]
(4)对得到的通过内部乘积ei的新表示与学习向量ue测量重要性权重, 之后
利用softmax计算归一化的重要权重其中用控制重要权重的均 匀性:
[0100][0101]
(5)最后,利用集合e、f的重要性权重计算将除以i,则表示 基于肌电与皮电情感的全局特征表示。
[0102]
(6)融合模块用于对所得肌电与皮电的全局表特征示进 行双线池化得到进一步输出的融合向量:
[0103][0104]
其中,φ
p
∈rc×d表示第p个投影矩阵,通过学习一组投影矩阵 {φ
p
|p=1,
…
u},最后可以得到u维的融合向量i={1,
…
,u}。具体的:
[0105]
将每个投影矩阵φ
p
分解为两个秩矩阵:
[0106][0107]
其中,l作为分解矩阵中的潜藏维度数,得到秩矩阵其中,l作为分解矩阵中的潜藏维度数,得到秩矩阵与符号
·
表示连接两个向量进行相乘,τ∈r
l
表示 为全1的向量,用此向量使矩阵mg与矩阵ng逼近φg,可以减少参数量从而得到 更加简洁的运算。
[0108]
为了得到最后的一个输出量,将把两个需要学习的三维向量m= {m1,
…
,mk}∈rc×
l
×k与n={n1,
…
,nk}∈rd×
l
×k进行重塑处理,重新表示为二 维矩阵形式与并用二维矩阵与此前通过全连接层得到的和进行两两结合,生成的两个融合矩阵再次进行向量相乘,最后与一系列不 重叠的窗口进行最大池化,得到所需的融合向量i:
[0109][0110]
(7)分类模块是将所得到的融合向量i通过全连接层与激励函数softmax计 算出不同的情感表示,最终的情感识别结果被计算为x:
[0111]
x=softmax(fc(i))∈rjꢀꢀꢀ
(14)
[0112]
其中,fc表示全连接层,softmax为激励函数用于分类情感,j代表表情识 别的类别。本实施例中,表情识别的类别分为三类:积极、中性、消极。
[0113]
本实施例中,生理情感识别模型的损耗主要是在信号提取与传播部分不够 准确,为了调整模型损耗,损失函数l为:
[0114][0115]
其中,p表示真实概率分布,表示预测概率分布。
[0116]
s4根据所述第一情感标识、第二情感标识以及预设的阈值条件,对被监测 主体的学习投入状态进行分类,获得分类结果。
[0117]
本实施例中,将语音情绪识别与生理情绪识别出的第一情感标识、第二情 感标识进行融合,不同的情感标识具有预先设置的标准指标值,将该标准指标 值与预设的阈值条件进行对比,即可获得学生的学习投入状态等级。
[0118]
在一个更加优选的实施例中,将语音情绪识别、生理情绪识别以及文本比 对情况三者进行融合,来对学习投入状态进行分类。基于该更加优选的实施例, 上述学习投入状态监测方法还包括:
[0119]
将所述音频信息进行转录,生成文本数据;
[0120]
具体的,对音频信息每个话语,可通过自动语音识别(asr)服务获得它的转 录。然后,通过预训练的语言模型提取语言表示m为asr转录的 字数。
[0121]
对所述文本数据进行关键词提取,得到关键词标签;
[0122]
具体的,将所获取到的语言表示与教学内容利用python的snownlp工具箱的textrank算法进行文本标签化,并将其关键词集合表示为 与
[0123]
将所述关键词标签与预置的标准语句进行比对,计算两者的重合率;
[0124]
具体的,将关键词集合与进行重合度比对,得到重合率l。
[0125]
最后,根据所述重合率、第一情感标识、第二情感标识以及预设的阈值条 件,对被监测主体的学习状态进行分类,获得分类结果。
[0126]
在该优选实施例中,将语音情绪识别与生理情绪识别出的第一情感标识、 第二情感标识进行融合,不同的情感标识具有预先设置的第一标准指标值;不 同的文本重合率具有预先设置的第二标准指标值,将第一标准指标值与第二标 准指标值进行融合(例如求和),得到第三标准指标值;然后将该第三标准指标 值与预设的阈值条件进行对比,即可获得学生的学习投入状态等级。
[0127]
下面给出一个具体的学习投入状态判级方法,作为一种可选示例,如表1 所示:
[0128]
表1基于文本重合率及第一、第二情感标识的学习投入状态判级
[0129]
[0130][0131]
应当注意,尽管在上述的实施例中,以特定顺序描述了本说明书实施例的 方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作, 或是必须执行全部所示的操作才能实现期望的结果。相反,流程图中描绘的步 骤可以改变执行顺序。附加地或备选地,可以省略某些步骤,将多个步骤合并 为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
[0132]
本实施例还提供了一种计算机设备,其包括至少一个处理器、以及至少一 个存储器,其中,存储器中存储有计算机程序,当计算机程序被处理器执行时, 使得处理器执行学习投入状态监测方法的步骤,具体步骤参见上文,此处不再 赘述;本实施例中,处理器和存储器的类型不作具体限制,例如:处理器可以 是微处理器、数字信息处理器、片上可编程逻辑系统等;存储器可以是易失性 存储器、非易失性存储器或者它们的组合等。
[0133]
该计算机设备也可以与一个或多个外部设备(如键盘、指向终端、显示器等) 通信,还可与一个或者多个使得用户能与该计算机设备交互的终端通信,和/或 与使得该计算机设备能与一个或多个其它计算终端进行通信的任何终端(例如网 卡,调制解调器等等)通信。这种通信可以通过输入/输出(i/o)接口进行。并且, 计算机设备还可以通过网络适配器与一个或者多个网络(例如局域网(local area network,lan),广域网(wide area network,wan)和/或公共网络,例如因特 网)通信。
[0134]
需要说明的是,对于前述的各方法实施例,为了简单描述,故将其都表述 为一系列的动作组合,但是本领域技术人员应该知悉,本技术并不受所描述的 动作顺序的限制,因为依据本技术,某些步骤可以采用其他顺序或者同时进行。 其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施 例,所涉及的动作和模块并不一定是本技术所必须的。
[0135]
在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详 述的部分,可以参见其他实施例的相关描述。
[0136]
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤 是可以通进程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存 储器中,存储器可以包括:闪存盘、只读存储器(read-only memory,rom)、 随机存取器(random access memory,ram)、磁盘或光盘等。
[0137]
以上所述者,仅为本公开的示例性实施例,不能以此限定本公开的范围。 即但凡依本公开教导所作的等效变化与修饰,皆仍属本公开涵盖的范围内。本 领域技术人员在考虑说明书及实践这里的公开后,将容易想到本公开的其实施 方案。本技术旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、 用途或者适应性变化遵循本公开的一般性原理并包括本公开未记载的本技术领 域中的公知常识或惯用技术手段。说明书和实施例
仅被视为示例性的,本公开 的范围和精神由权利要求限定。
[0138]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述 实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特 征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0139]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并 不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换 和改进等,均应包含在本发明的保护范围之内。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。