1.本发明属于信息与通信技术领域,具体涉及一种基于k近邻(knn)算法的人工噪声消除(ane)方法。
背景技术:
2.人工噪声(artificial noise,an)因其利用信道信息生成正交噪声的能力而成为无线通信的一项物理层安全技术。现有研究表明,窃听方如果已知合法方信道信息的条件,可以使用迫零消除(zfe)或零空间消除(nse)以消除人工噪声带来的影响。
3.然而在实际情况下,窃听方可能无法获得合法方的信道信息。因此,该条件下的人工噪声消除技术略显困难,并未得到充分研究。事实上,人工噪声方案中的信道反馈技术要求慢变的衰落信道,而在慢变衰落信道的条件下,窃听方可以仅通过多个接收信号来实现人工噪声消除。
技术实现要素:
4.本发明的目的是提出一种在未知合法方信道信息条件下以及部分接收向量未知分类情况的人工噪声消除方法。本发明的技术方案是基于人工噪声下的多输入多输出(multiple-input multiple-output,mimo)模型,提出一种基于k近邻算法的人工噪声消除方法。
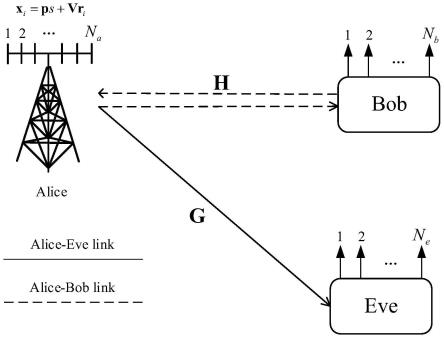
5.考虑如图1所示的an辅助的mimo无线通信系统,其中发送方(alice)有na根发射天线,接收方(bob)有nb根接收天线,窃听方(eve)有ne根接收天线。bob首先采用信道估计技术得到alice-bob链路的信道信息h,并将其反馈给alice以生成波束赋形向量和人工噪声前者用于提升信号传输性能,后者用于保证传输安全,表示复数域。alice发送的基带信号s满足shs=es,es表示信号功率。
6.基于以上模型,an-mimo的发射信号可以表示为:
7.x=ps vr
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
8.式中p可以使用hhh最大特征值对应的特征向量,是h的零空间,满足hv=0,是一个所有元素满足独立同分布的均值为0,方差为的复高斯分布(i.i.d)的随机向量,其中v可以由h的奇异值分解获得
9.h=u[d 0][v
1 v]h.
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0010]
设发射信号x的总发射功率为p,用于传输有效信号s的比例为θ,那么人工噪声vr所占比例为1-θ。根据功率限制公式
[0011]
||ps||2=es=θp,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0012]
e[||vr||2]=(1-θ)p,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0013]
可以得到如下限制
[0014]es
=θp,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0015][0016]
发射信号通过信道h传输至bob,并同时通过窃听信道传输至eve,两者的接收信号可以表示为
[0017]
y=hps u,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0018]
z=gps gvr v,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0019]
式中和均表示复高斯噪声,其中的每个元素都满足独立同分布的均值为0,方差分别为和的复高斯分布(i.i.d.和)。
[0020]
传统的人工噪声消除方案需要h的信息,如迫零消除方案
[0021]
w=h(ghg)-1gh
.
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0022]
该方案可以构建出与h相同的信道
[0023][0024]
又比如迫零消除方案
[0025][0026]
其中的是v
hgh
的零空间,同样可由奇异值分解技术得到。但由于v是h的零空间,因此该方案依旧需要h的信息。将上式左乘与接收信号,同样可以得到消除人工噪声的效果
[0027][0028]
针对h不可获得的情况,由于人工噪声技术要求衰落信道慢变,因此eve可以获得多个观测信号,以提取出额外信息以消除人工噪声。基于主成分分析(pca)方法的解决方案在已知所有的接收向量的分类情况时,可以消除人工噪声的影响,首先介绍pca方法。
[0029]
在alice发送二分类符号s1和s2时,eve接收到的两类观测向量分别可以表示
[0030][0031]
其中zi是第i个整体观测向量,ri和vi分别代表第i个采样点对应的人工噪声向量和高斯白噪声向量,i的值为第一类采样点的下标,可以从1取至m1,对应第一类观测向量的数量为m1。同理,zj是第j个整体观测向量,rj和vj分别代表第j个采样点对应的人工噪声向量和高斯白噪声向量,j的值为第二类采样点的下标,可以从m1 1取至m1 m2,对应第二类观测向量的数量为m2。
[0032]
通过计算矩阵
[0033]
sb=(m
1-m2)(m
1-m2)hꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(14)
[0034]
和
[0035][0036]
并求解矩阵(sb,si)最大广义特征值对应的广义特征向量,即可获得最优解。其中和分别代表第一类样本点和第二类样本点未经投影的平均向量。
[0037]
然而需要注意的是传统的基于主成分分析(pca)方法的解决方案需要已知所有的接收向量的分类情况,对于未知分类情况的样本点目前还没有方案能够解决。因此传统方法无法利用未分类点的信息提升消除效果,因此本发明引入k近邻算法(knn)解决此问题。knn算法的示意图如图2所示。一些分类的观察向量可以存储为训练样本,而在分类阶段,未标记向量通过其训练集中k个最近训练邻居中的多数标记进行分类。
[0038]
在knn算法中,采用下式的欧式距离来度量未标记向量和训练样本之间的差异
[0039]
d(z
p
,zq)=|wh(z
p-zq)|,
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0040]
其中z
p
,p=1,2,
…
,p和zq,q=1,2,
…
,q分别代表未标记向量和训练样本,p为未标记向量的总个数,q为训练样本的总个数,在pca方法中,q=m1 m2。此外,分配给未标记向量的分类标签由其最接近的k个训练样本的投票决定,票数最多的那一类为未标记向量的分类,数学表达为
[0041][0042]
其中y(z,ck)意味着z是否属于样本ck,如果属于,值为1,如果不属于,值为0。本质上,上式表达的含义为未标记向量的最终分类,是拥有其k个最近的邻点中最多点数的那一类。k的常规取值有3,5,7,9等等。对每一个未分类向量,均可找到其欧式距离最近的k个训练样本,对这k个训练样本计数,含有这k个训练样本最多的那个分类即为判定的未分类向量的最终分类;
[0043]
最终,基于重新分类的z
p
和zq,重新根据公式计算sb,si,对重新计算的矩阵组(sb,si),重新使用广义特征值分解,并选择对应最大广义特征值的广义特征值向量作为最优解wh。
[0044]
knn算法计算复杂度分析:
[0045]
具体来说,knn算法的计算过程主要包括三个部分。第一部分是基于训练样本计算最佳投影w所需要的复杂度为第二部分是计算未分类向量与训练样本的欧式距离所需要的复杂度为第三部分是基于总体样本计算wh所需要的复杂度为因此,该算法的整体复杂度为
[0046]
本发明的有益效果为,在未知生成an所使用的信道信息h同时均在部分未分类接收向量的条件下,可以实现未分类向量的有效分类,并用以提升人工噪声消除的效果。
附图说明
[0047]
图1是an辅助的mimo无线通信示意图。
[0048]
图2是knn算法示意图。
[0049]
图3是knn算法随未分类向量数p的性能变化仿真图。
[0050]
图4是knn算法与一些传统算法的性能对比仿真图。
具体实施方式
[0051]
下面结合附图和仿真实例,对本发明的实用性进行说明。
[0052]
图1是本发明应用的一般性系统示意图。图2是本发明中的knn算法示意图。该通信系统的目的是使eve在未知h同时均在部分未分类接收向量的情况下,利用未分类向量的信息,提升人工噪声消除的效果。在该模型下,本发明的具体实施步骤如下所示:
[0053]
a)输入训练样本zq(第一类m1个观测向量的样本zi,i=1,2,
…
m1,第二类m2个观测向量的样本zj,j=m1 1,m1 2,
…
m1 m2),未分类向量z
p
,窃听信道衰落系数矩阵g,k值;
[0054]
b)根据公式(14)和(15),分别计算sb,si;
[0055]
c)对矩阵组(sb,si)使用广义特征值分解并选择对应最大广义特征值的广义特征值向量;
[0056]
d)对每一个未分类向量,找到其欧式距离最近的k个训练样本;
[0057]
e)根据公式(17),对这k个训练样本计数,未分类向量的最终分类是含有这k个训练样本最多的那类;
[0058]
f)基于重新分类的z
p
和zq,重新根据公式(14)和(15),分别计算sb,si;
[0059]
g)对重新计算的矩阵组(sb,si),重新使用广义特征值分解,并选择对应最大广义特征值的广义特征值向量;
[0060]
h)输出w。
[0061]
图3描述了knn算法中,当pca中的训练样本设置为m1=20和m2=20时,knn辅助ane带来的ansr增益与测试样本p的数量之间的关系。如图3所示,由于从原始未分类样本中提取了额外信息,因此随着p的增加,可以获得轻微的ansr增益。从绿色虚线的观察中,我们注意到ansr=0始终适用于高斯白噪声功率为0的情况,从而验证了所提出的knn方案的鲁棒性能。
[0062]
图4比较了在snr=30db下mca、pca和knn分别带来的增益,与具有完美csi和不了解csi的传统基准方案相比。具体而言,不同类型的观测向量的数量设置为m1=20、m2=10和p=30。如所观察到的,对于没有csi的情况,接收到的ansr保持在高水平,这意味着an对eve的检测产生了严重影响。相比之下,mca算法在m=20时减少了ansr的值,因为第一个分类具有更多的观察向量,并且可以为mca带来更好的性能。此外,与mca相比,pca算法通过利用第二类样本的信息提供了更低的ansr。此外,由于未分类观测向量的附加值,knn方案实现了更小的ansr。从绿色虚线曲线的观察中,我们注意到零ansr从传统ane方案中的完美csi中受益。。
再多了解一些
本文用于创业者技术爱好者查询,仅供学习研究,如用于商业用途,请联系技术所有人。
